Further Problem in
Xross Mutual Learning
Another Dataset
Tiny ImageNet
- Image size 64x64x3
- 200 classes
- Each class: 500 train / 50 test
- Use @1 Accuracy as evaluation metrics
Experiment
Net1 up-half networks
Net2 up-half networks
Net2 down-half networks
Net1 down-half networks
675,392
1,340,224
19,988,068
10,544,740
ResNet18
(w/o pretrained)
ResNet34
(w/o
pretrained)
2 residual block
2 residual block + FC
2 residual block
2 residual block + FC
Adam, 1e-4
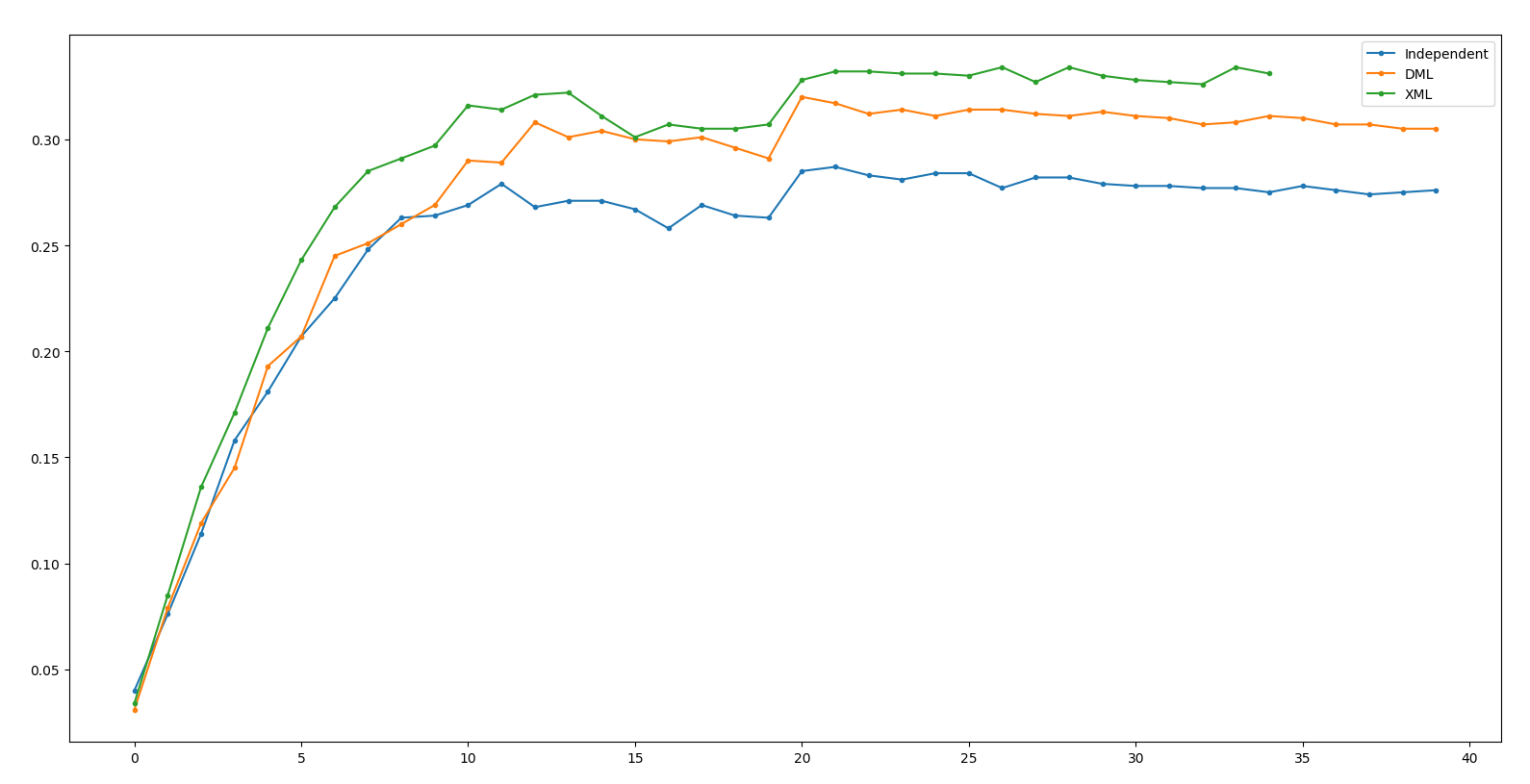
Result - ResNet34
Independent: 31.1 DML: 35.5(+4.4) XML: 37.2(+1.7)
(Net 1: ResNet34, Net 2: ResNet18)
Result - ResNet18
Independent: 30.4 DML: 34.1(+3.7) XML: 36.8(+2.7)
(Net 1: ResNet34, Net 2: ResNet18)
Conclusion
- 在Cifar100 / Tiny Imagenet都顯現出XML比DML還要強。
- 直接train大model會發現其極容易overfit,且DML拯救不回來,但XML卻可以。
- 仔細看看會發現: ResNet34在Tiny容易overfit到比ResNet18更差,但XML不會。
Xross can be good in this case
| Up Half | Down Half | Accuracy |
|---|---|---|
| ResNet34 | ResNet34 | 0.37177 |
| ResNet34 | ResNet18 | 0.37089 |
| ResNet18 | ResNet34 | 0.37604 |
| ResNet18 | ResNet18 | 0.36835 |
Xross maybe good.
XML Ensemble: 39.3 (+2.2)
DML Ensemble: 37.3 (+2.2)
Independent Ensemble: 32.2 (+1.9)
Cohort Learning
DML & XML loss
# DML
kl_loss = [ KL(teacher_pred, student_pred) for teacher_pred in teachers_pred]
kl_loss = sum(kl_loss) / len(kl_loss)
loss = 0.5 * criterion(student_logits, labels) + 0.5 * kl_loss
# ========
# DML part: logits loss & KL-loss (mimic others K-1 model)
original_loss = [criterion(student_logits, labels)]
kl_loss_self = [ KL(teacher_pred, student_pred) for teacher_pred in teachers_pred ]
kl_loss_self = [sum(kl_loss_self) / len(kl_loss_self)]
# XML part: up mimic + logits (K-1), down mimic + logits (K-1)
kl_up_mimic = [ KL(teacher_pred, up_mimic) for up_mimic, teacher_pred in zip(cat_teacher_down_pred, teachers_pred)]
kl_down_mimic = [ KL(teacher_pred, down_mimic) for down_mimic, teacher_pred in zip(cat_teacher_up_pred, teachers_pred)]
loss_up_mimic = [ criterion(up_mimic_logits, labels) for up_mimic_logits in cat_teacher_down_logits]
loss_down_mimic = [ criterion(down_mimic_logits, labels) for down_mimic_logits in cat_teacher_up_logits]
loss = sum(original_loss + kl_loss_self + kl_up_mimic + kl_down_mimic + loss_up_mimic + loss_down_mimic) / (2 * len(teachers))
DML: 0.5 logits + 0.5 sum(KL) / (K - 1)
XML: (DML loss + up-mimic + down-mimic) / (2K)
Experiment
Net1 up-half networks
Net2 up-half networks
Net2 down-half networks
Net1 down-half networks
4,126,528
1,444,928
22,472,904
63,117,512
ResNeXt50
(no
pretrained)
ResNet50
(no
pretrained)
Net3 up-half networks
Net3 down-half networks
1,412,416
21,977,288
WRN50
(no
pretrained)
Optimizer: Adam 1e-4
Result - WRN50
Independent: 34.4 DML: 36.9(+2.5) XML: 36.0(-0.9)
(Net 1: WRN50, Net 2: ResNet18, Net 3: ResNeXt50)
Result - ResNet50
Independent: 28.7 DML: 32.5(+3.8) XML: 33.4(+0.9)
(Net 1: WRN50, Net 2: ResNet18, Net 3: ResNeXt50)
Result - ResNeXt50
Independent: 28.7 DML: 32.0(+3.3) XML: 33.4(+1.4)
(Net 1: WRN50, Net 2: ResNet18, Net 3: ResNeXt50)
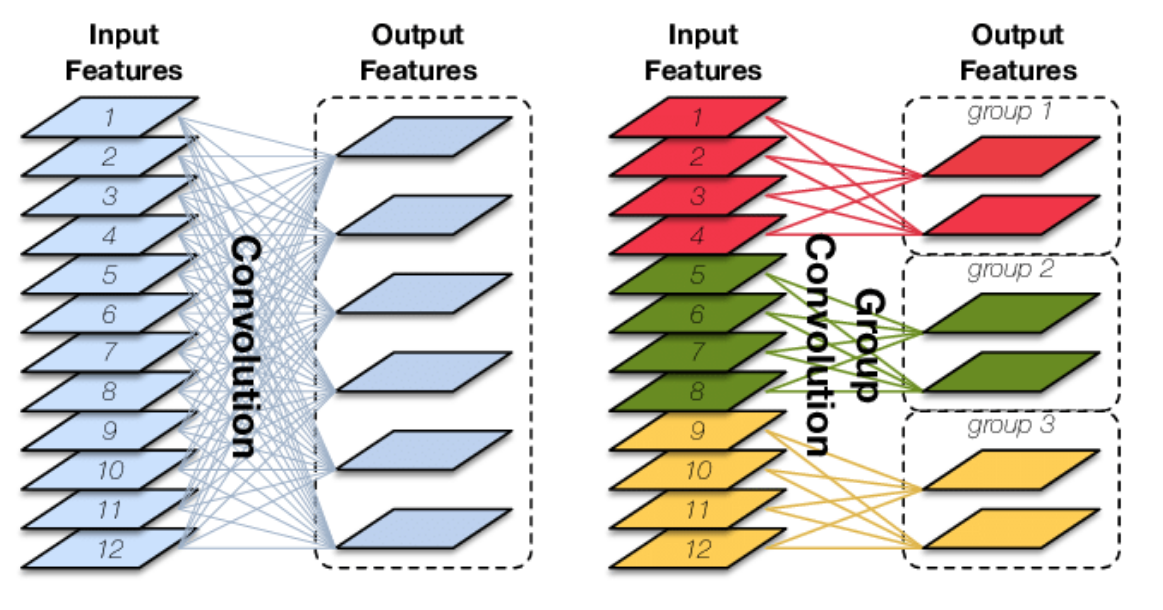
Note - Group Conv
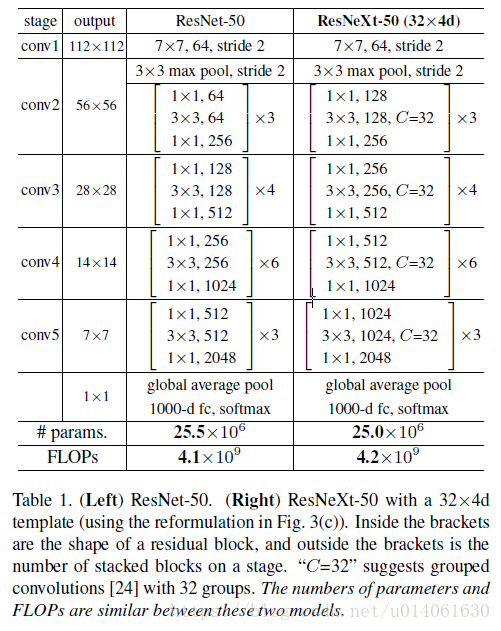
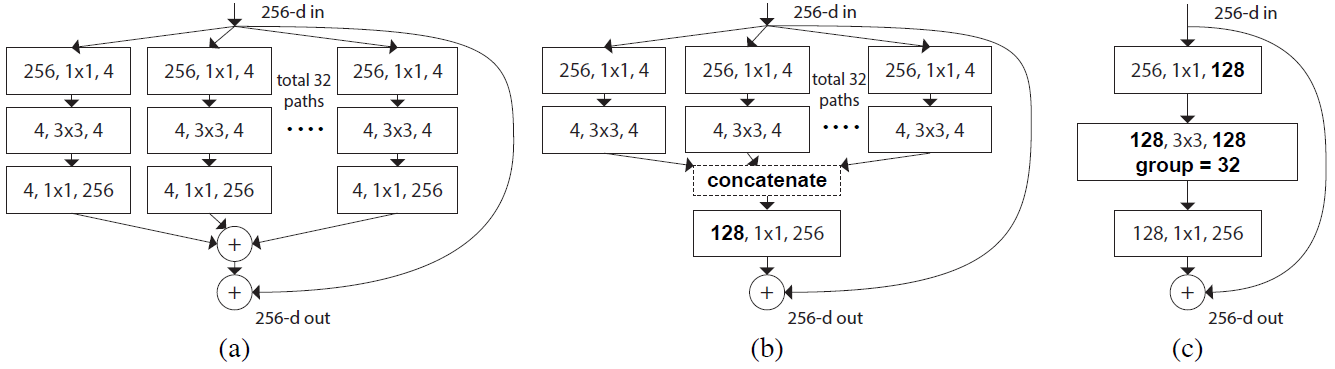
Note - ResNet50 ns ResNeXt
Conv 4 的neuron數加多,
而用Group Conv的neuron數少
Conclusion
- Cohorts Learning XML也比DML更為優秀。
- ResNeXt-50 在少參數下還比較好的原因: Group Conv
Now Loss
Net1 up-half networks
Net2 up-half networks
Net2 down-half networks
Net1 down-half networks
Net3 up-half networks
Net3 down-half networks
Mimic 2
Mimic 3
Mimic 2 & 3
Mimic 2
Mimic 3
XML in pretrained
Experiment
Net1 up-half networks
Net2 up-half networks
Net2 down-half networks
Net1 down-half networks
4,126,528
1,444,928
22,472,904
63,117,512
ResNeXt50
(pretrained)
ResNet50
(pretrained)
Net3 up-half networks
Net3 down-half networks
1,412,416
21,977,288
WRN50
(pretrained)
Optimizer: Adam 1e-4
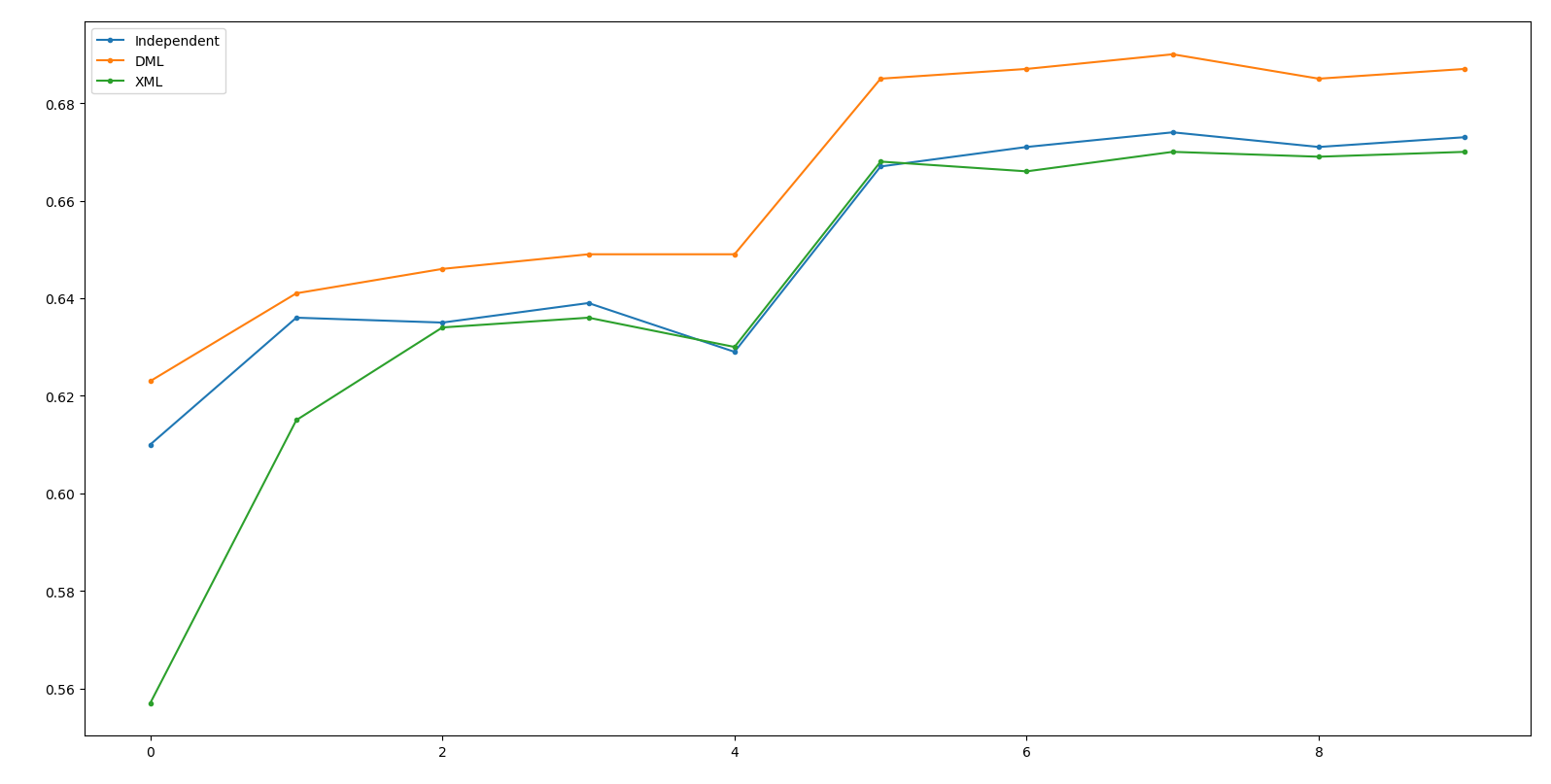
Result - WRN50
Independent: 67.4 DML: 69.0(+1.6) XML: 67.0(-2.0)
(Net 1: WRN50, Net 2: ResNet50, Net 3: ResNeXt50)
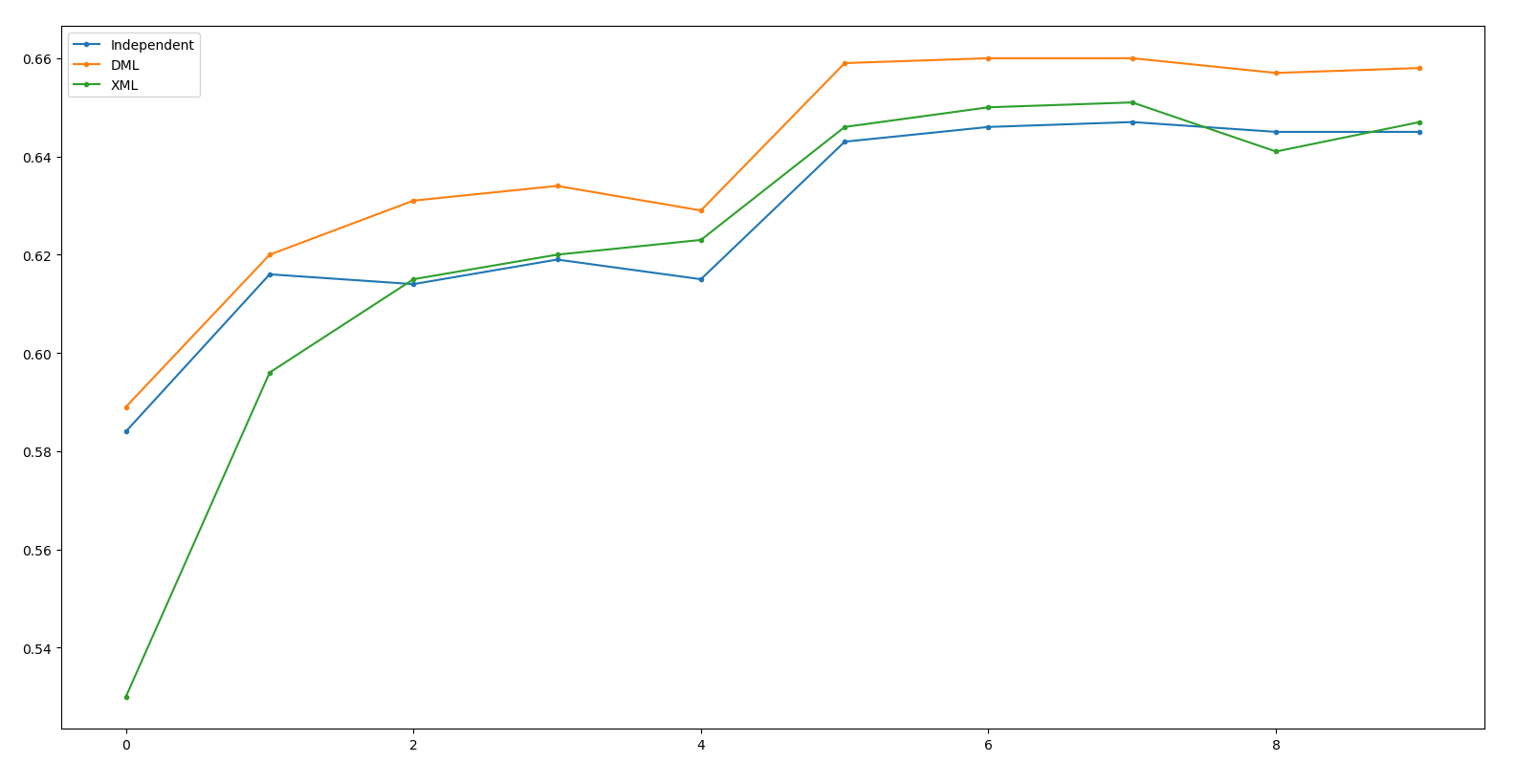
Result - ResNet50
Independent: 64.7 DML: 66.0(+1.3) XML: 65.1(-0.9)
(Net 1: WRN50, Net 2: ResNet50, Net 3: ResNeXt50)
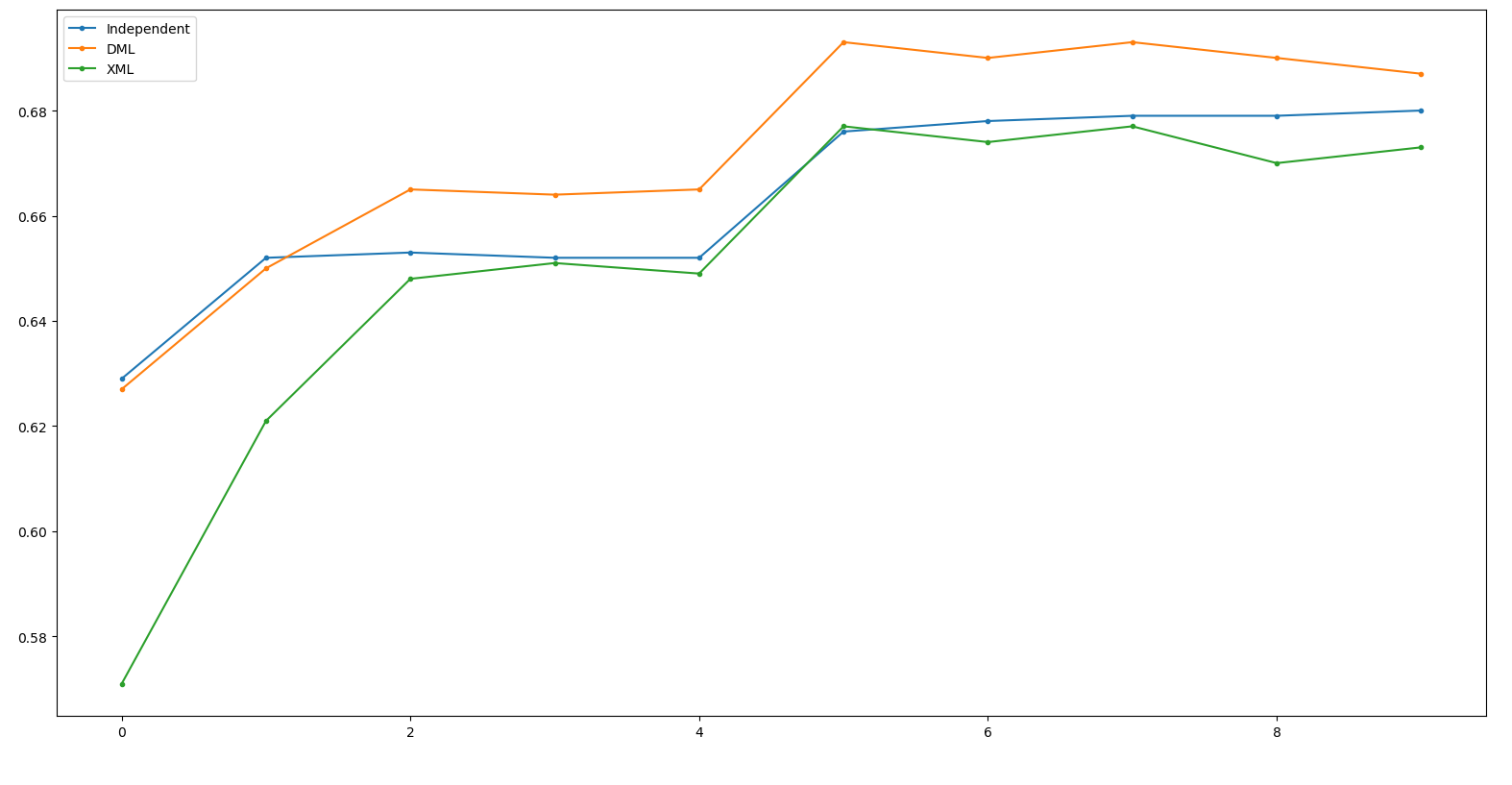
Result - ResNeXt50
Independent: 68.0 DML: 69.3(+1.3) XML: 67.7(-1.6)
(Net 1: WRN50, Net 2: ResNet50, Net 3: ResNeXt50)
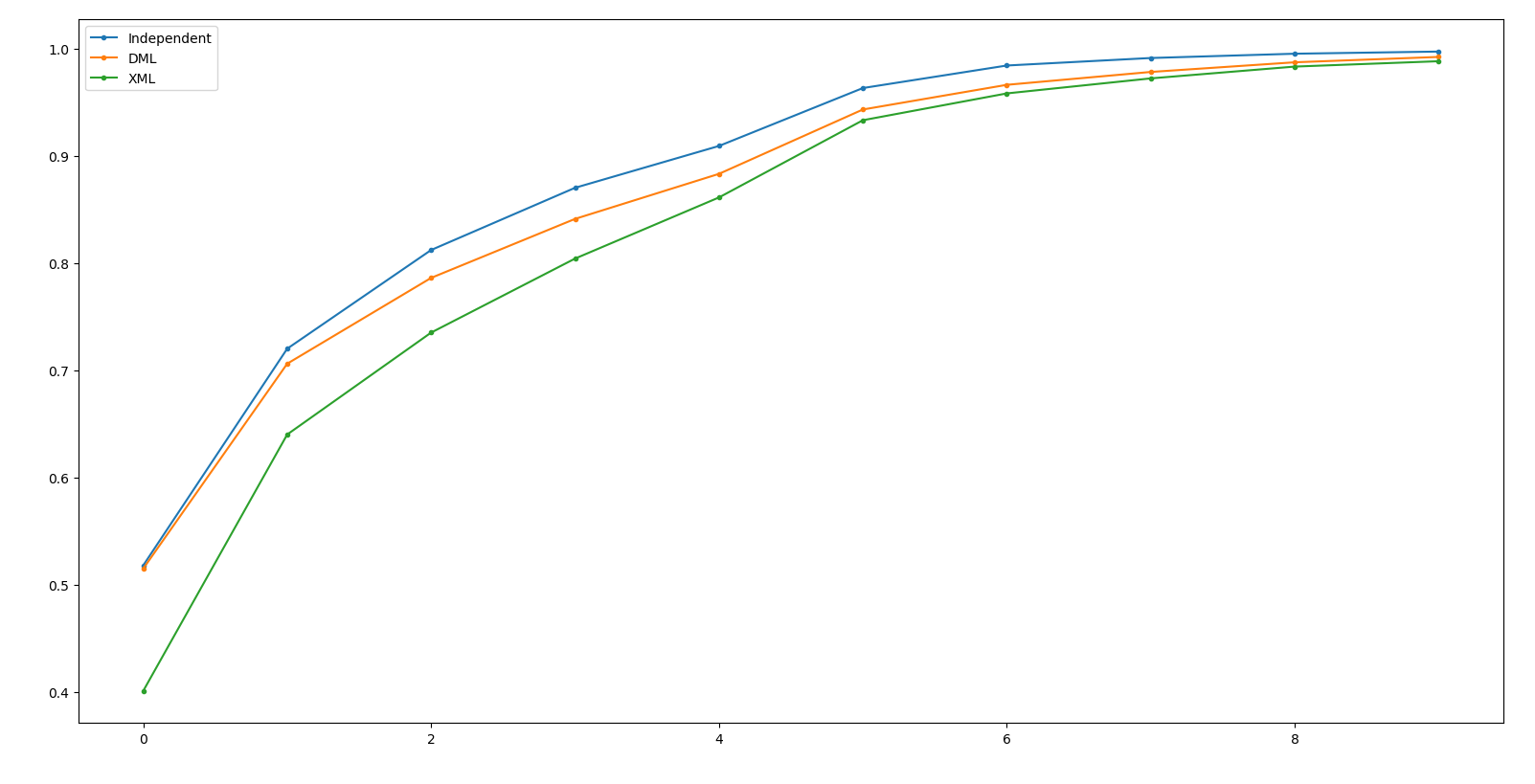
Result - ResNeXt50 @ train
XML 比較難train起來, 但對於相同的train acc, val並沒比較高。
Deep Look in Cohorts
Xross can't be good in this case (pretrained)
| Up Half | Down Half | Accuracy |
|---|---|---|
| WRN50 | WRN50 | 0.66757 |
| WRN50 | ResNet50 | 0.64931 |
| WRN50 | ResNeXt50 | 0.66142 |
| ResNet50 | WRN50 | 0.64130 |
| ResNet50 | ResNet50 | 0.64638 |
| ResNet50 | ResNeXt50 | 0.64599 |
| ResNeXt50 | WRN50 | 0.65185 |
| ResNeXt50 | ResNet50 | 0.64423 |
| ResNeXt50 | ResNeXt50 | 0.67744 |
But Maybe only pretrained??
Ensemble
| Acc | WRN50 | ResNet18 | ResNeXt50 |
|---|---|---|---|
| Independent | 67.2 | 64.4 | 68.0 |
| DML | 68.2 | 65.8 | 69.3 |
| XML | 66.7 | 64.6 | 67.7 |
Recall
| Acc | Ensemble 3 |
|---|---|
| Independent | 71.8 |
| DML | 72.0 |
| XML | 69.8 |
Xross without pretrained
| Up Half | Down Half | Accuracy | #params |
|---|---|---|---|
| WRN50 | WRN50 | 0.35507 | 67,244,040 |
| WRN50 | ResNet50 | 0.33203 | 26,599,432 |
| WRN50 | ResNeXt50 | 0.33281 | 26,103,816 |
| ResNet50 | WRN50 | 0.35390 | 64,562,440 |
| ResNet50 | ResNet50 | 0.32939 | 23,917,832 |
| ResNet50 | ResNeXt50 | 0.33203 | 23,422,216 |
| ResNeXt50 | WRN50 | 0.35458 | 65,529,928 |
| ResNeXt50 | ResNet50 | 0.33095 | 23,885,320 |
| ResNeXt50 | ResNeXt50 | 0.33447 | 23,389,704 |
Xross Works!
More about
pre-trained?
Use XML in pre-trained, may solve this problem.
Conclusion
- 要讓pretrained model去做XML果然還是不太可能的。
- 因為本來pretrained model中間就沒有要去fit 其他model的輸出。
- 它甚至會做的比原本Independent的更爛。
- 因為它會大幅破壞pretrained後的parameters。
Next Steps
- 因為pretrained model是用imagenet -> classification 去做pretrained的,那麼如果在pretrained的時候直接使用XML會不會比較好?
- 有沒有一種mapping方法讓neuron可以轉換?
- Gram Matrix
Channel Mapping Problem
~ Try to fix the failure of XML in pre-trained situation~
Channel Mapping
Net1
Net2
1
2
3
1
2
3
Mapping
Table
1 -> 3
2 -> 1
3 -> 2
Why Channel Mapping is Needed?
If it can be done appropriately, Explainable AI
Stable Marriage Problem
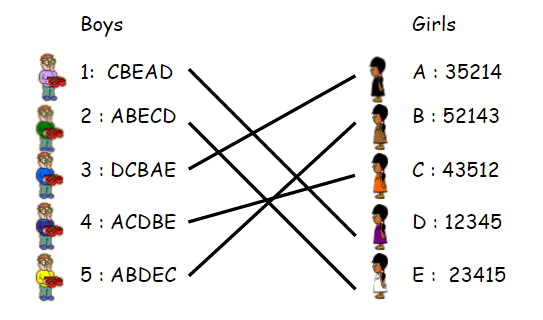
Gale-Shapley Algorithm
1. Match boys max(girl)
2. Match it, if conflict, hold on.
3. Do it until all pairs be matched.
Why not max the sum of relations?
在NN的channel中,也許優先批配比較重要?
Experiment
Net1 up-half networks
Net2 up-half networks
Net2 down-half networks
Net1 down-half networks
675,392
1,340,224
19,988,068
10,544,740
ResNet18
(pretrained)
ResNet34
(pretrained)
2 residual block
2 residual block + FC
2 residual block
2 residual block + FC
Adam, 1e-4
Measure Weight - 1
(128, 8, 8) -> (128, 64, 64)
A * B^T
對0做std
原始Matching分數:-0.0005
Random Mapping : -0.04
Gale Mapping : 1.77
Gale round: 92/18/12/4/1/1/1
Result - ResNet34
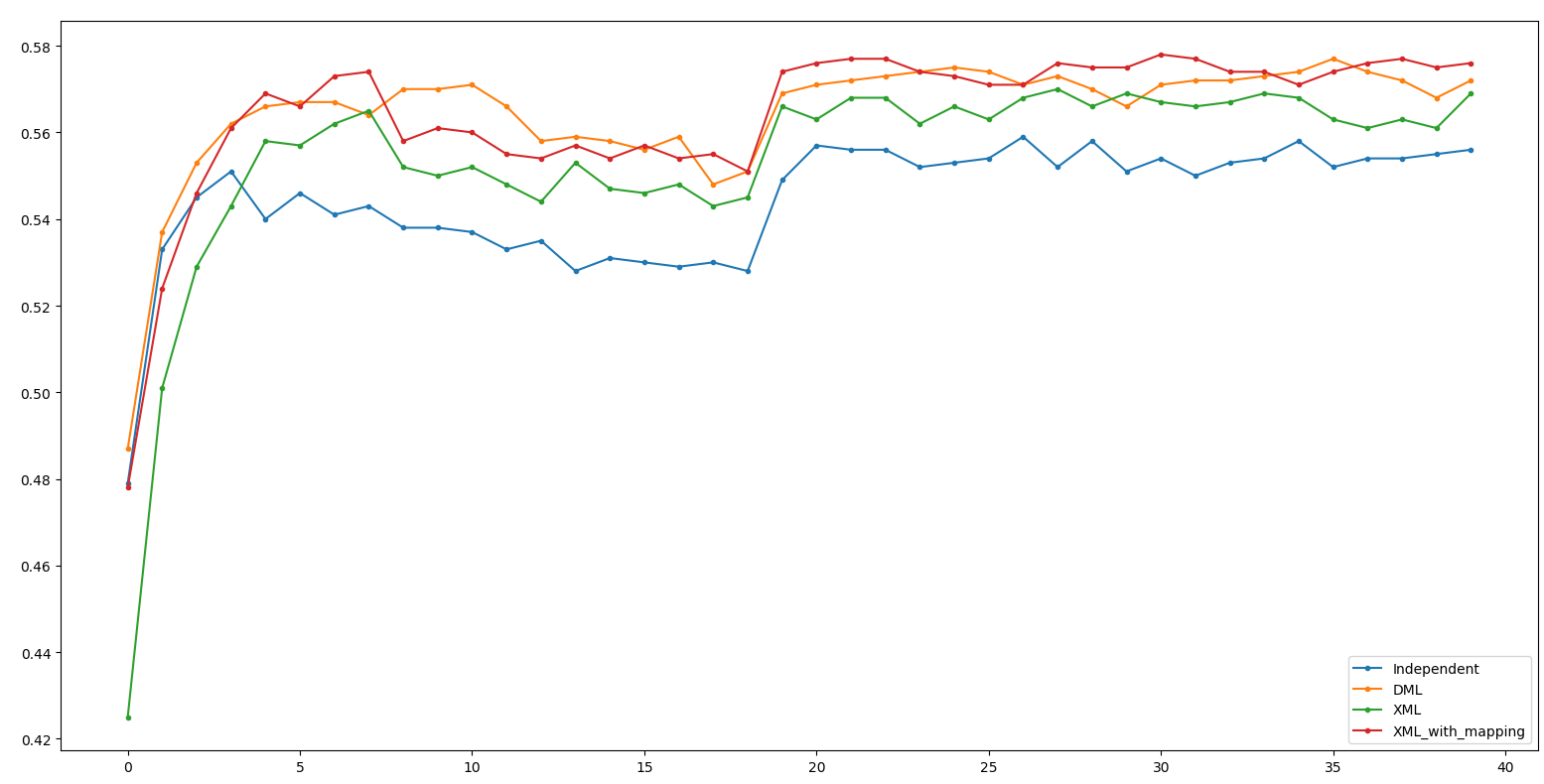
Independent: 59.6 DML: 61.0(+1.4)
XML: 60.0(-1.0) XML_m: 60.6(-0.4)
(Net 1: ResNet34, Net 2: ResNet18)
Result - ResNet18
Independent: 55.9 DML: 57.7(+1.8)
XML: 57.0(-0.7) XML_m: 57.8(+0.1)
(Net 1: ResNet34, Net 2: ResNet18)
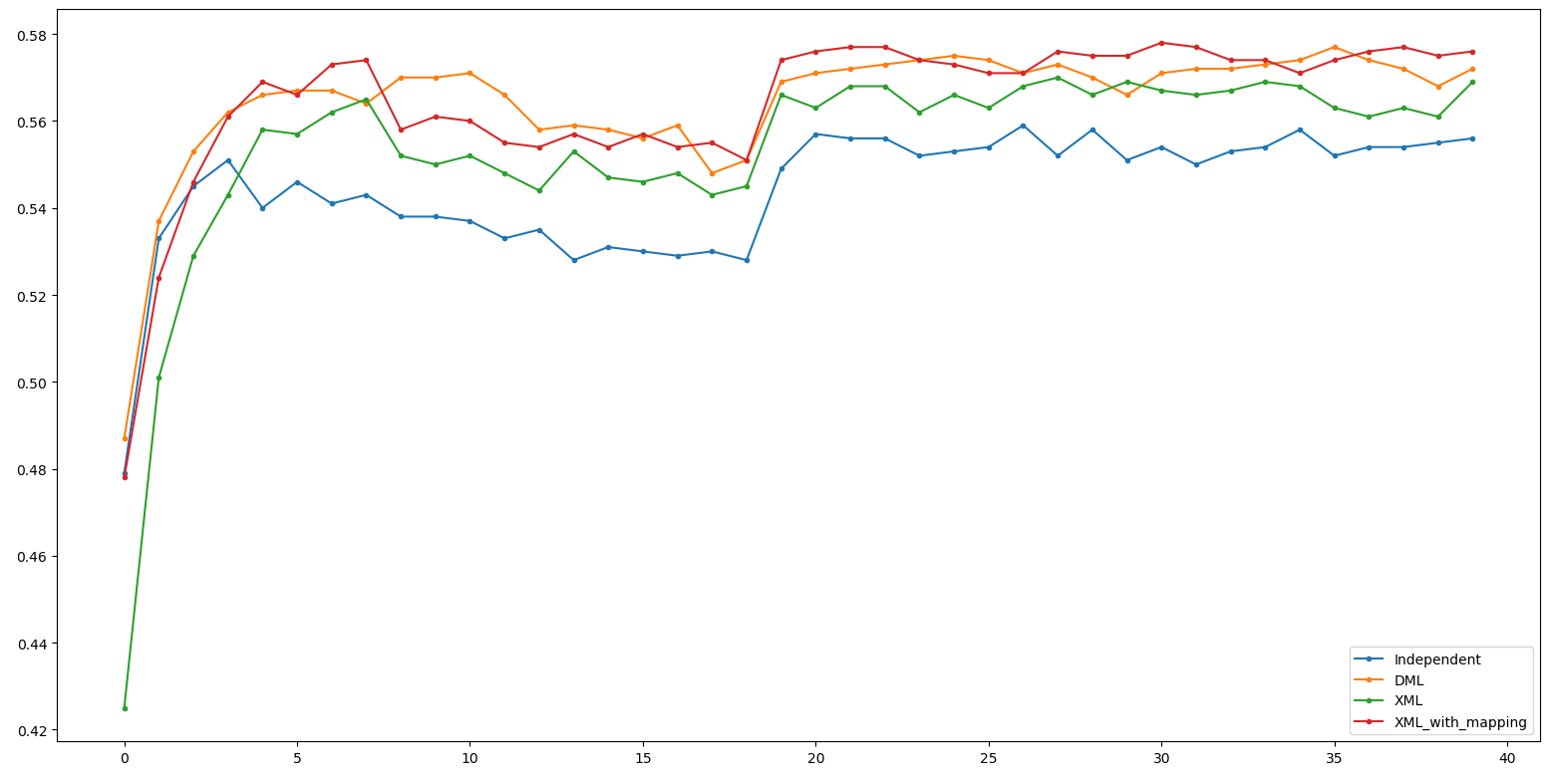
Xross Result
| Up Half | Down Half | Accuracy |
|---|---|---|
| ResNet34 | ResNet34 | 0.58798 |
| ResNet34 | ResNet18 | 0.57802 |
| ResNet18 | ResNet34 | 0.56269 |
| ResNet18 | ResNet18 | 0.56845 |
| Up Half | Down Half | Accuracy |
|---|---|---|
| ResNet34 | ResNet34 | 0.59843 |
| ResNet34 | ResNet18 | 0.59277 |
| ResNet18 | ResNet34 | 0.57695 |
| ResNet18 | ResNet18 | 0.57763 |
經過Mapping - 比較能做到Dynamic Computation
沒經過Mapping
1.Better evaluation method, or measure it with importance.
maybe like bipartite-mahalanobis?
2. Can we use this trick to evaluate what feature does networks learned?
this may need to take a look in pruning.
Next Steps
More about
Mapping Result
Measure Weight - 2
(128, 8, 8) -> (128, 64, 64)
A * B^T /|A||B|
while(對0做std -> 1std)
原始Matching分數:-0.0329
Random Mapping : 0.1133
Gale Mapping : 4.07
Gale round: 95/22/9/1/1
Measure Weight - 3
Just L2 loss
原始Matching分數:?
Random Mapping : ?
Gale Mapping : ?
Gale round: very long
Measure Weight - 4
Just L2 loss + stdandize
原始Matching分數:-0.04
Random Mapping : 0.04
Gale Mapping : 4.09
Gale round: 96/26/7/3/1
Result Table
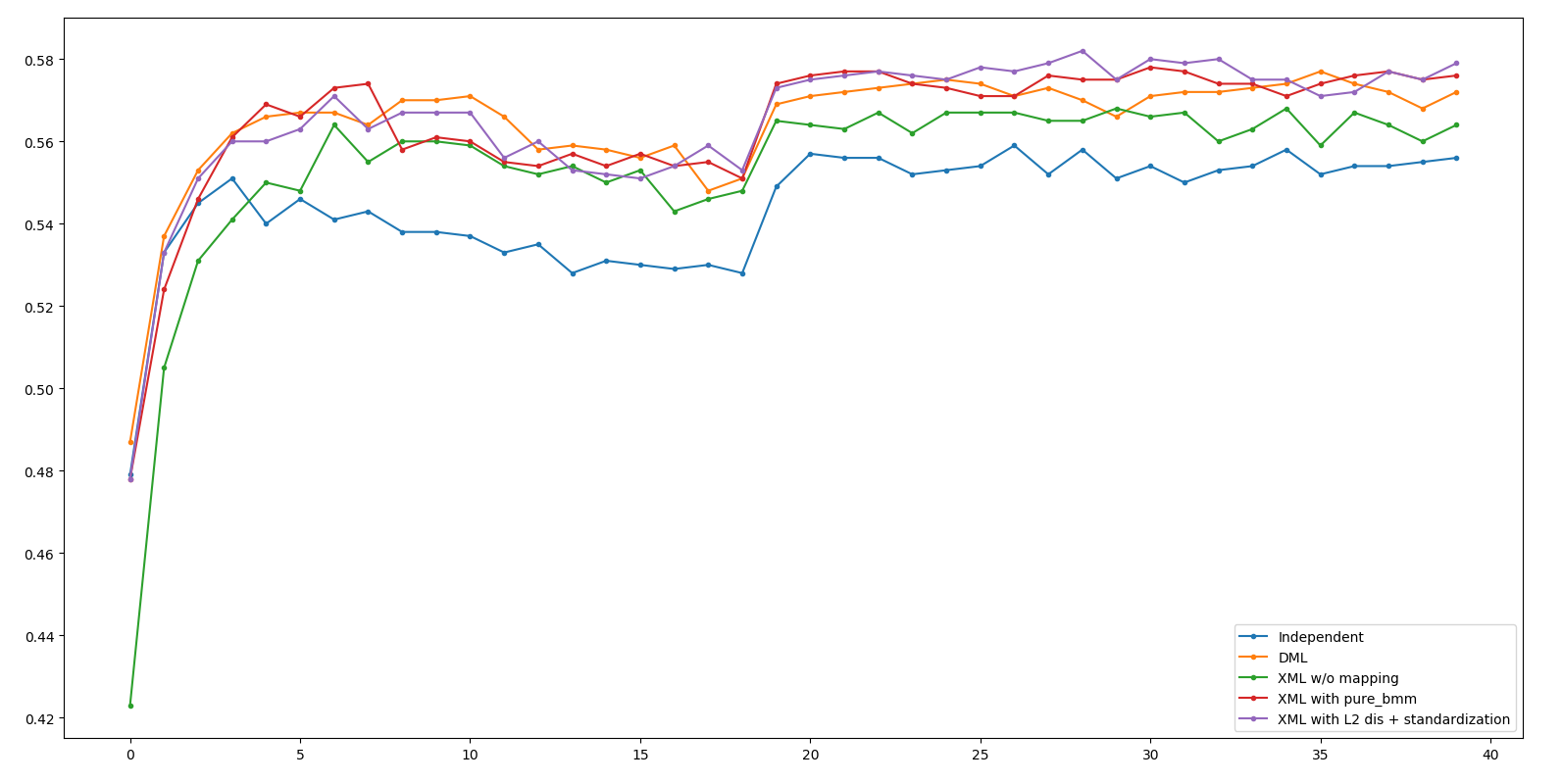
| Method | ResNet34 | ResNet18 |
|---|---|---|
| DML (baseline) | 61.0 | 57.7 |
| XML no mapping | 59.7 | 56.8 |
| XML + bmm + std | 60.6 / 60.3 | 57.8 / 58.0 |
| XML + cos + std | 60.1 | 57.7 |
| XML + L2 | 60.3 | 58.2 |
| XML + L2 + std | 60.3 | 58.1 |
Deep Look - ResNet34
ResNet34 - DML Seems good, or maybe it's failure of gale-shapley algorithm
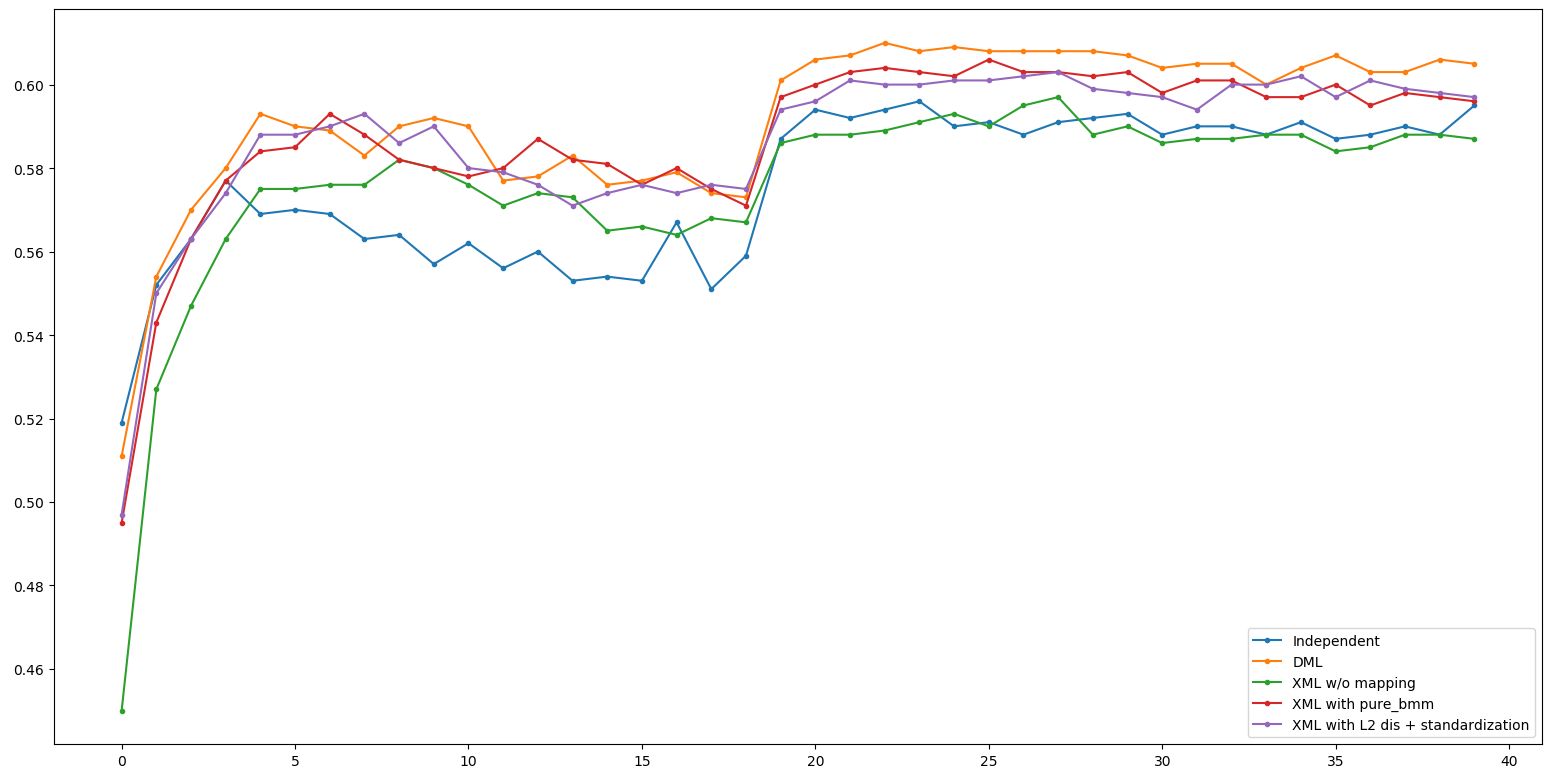
Deep Look - ResNet18
Channel Mapping
without pre-training
We know the importance about initialization.
And, XML's mid neuron maybe can deem to be "Initialization"?
Mapping Result
No-pretrained
原始Matching分數: 0.111
Random Mapping: -0.17
Gale Mapping : 1.718
pretrained:
原始Matching分數:-0.04
Random Mapping : 0.04
Gale Mapping : 4.09
看來是想太多 - ResNet34
看來是想太多 - ResNet18
Cohorts Learning Revenge by Channel Mapping
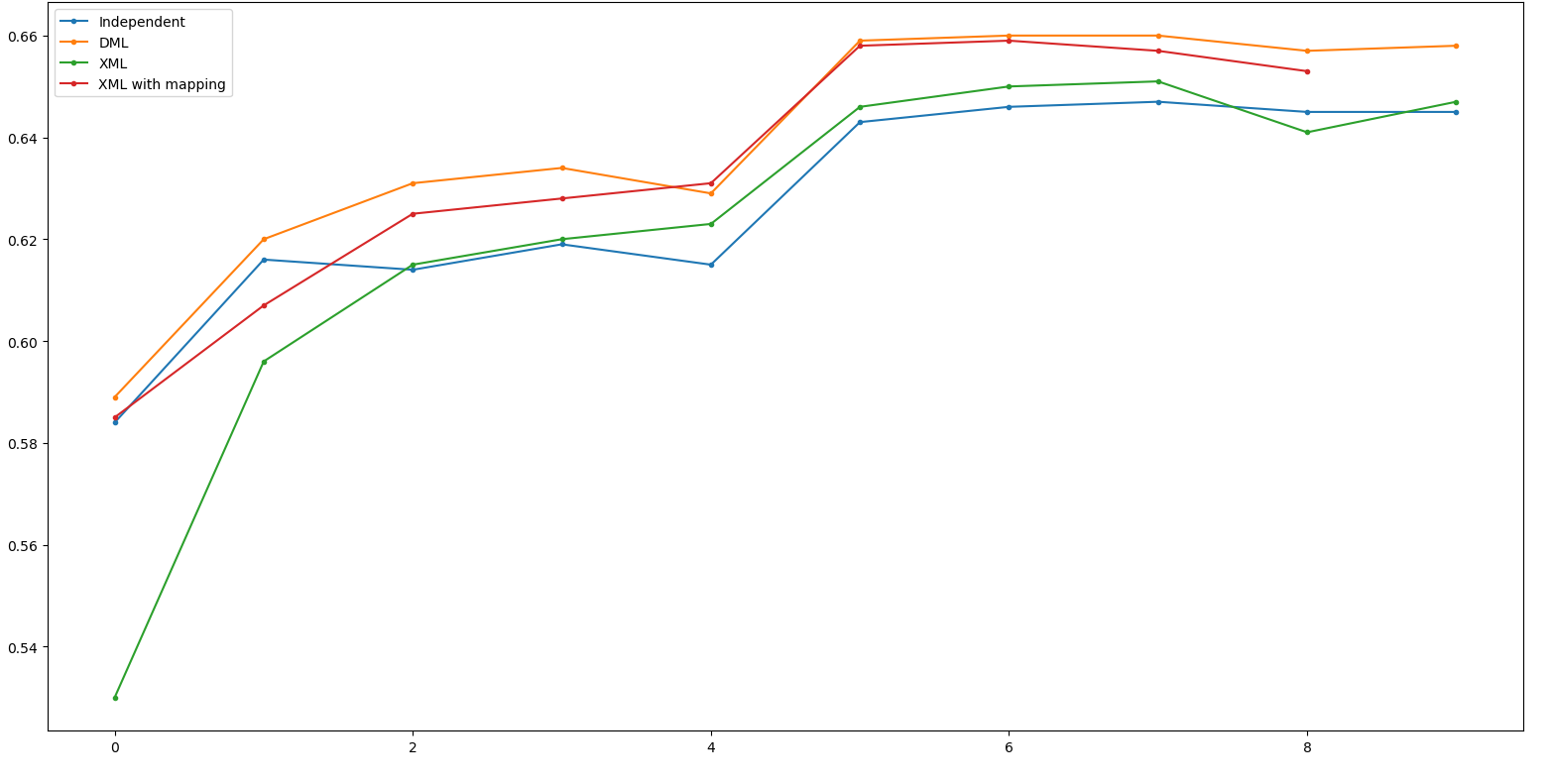
Result - WRN50
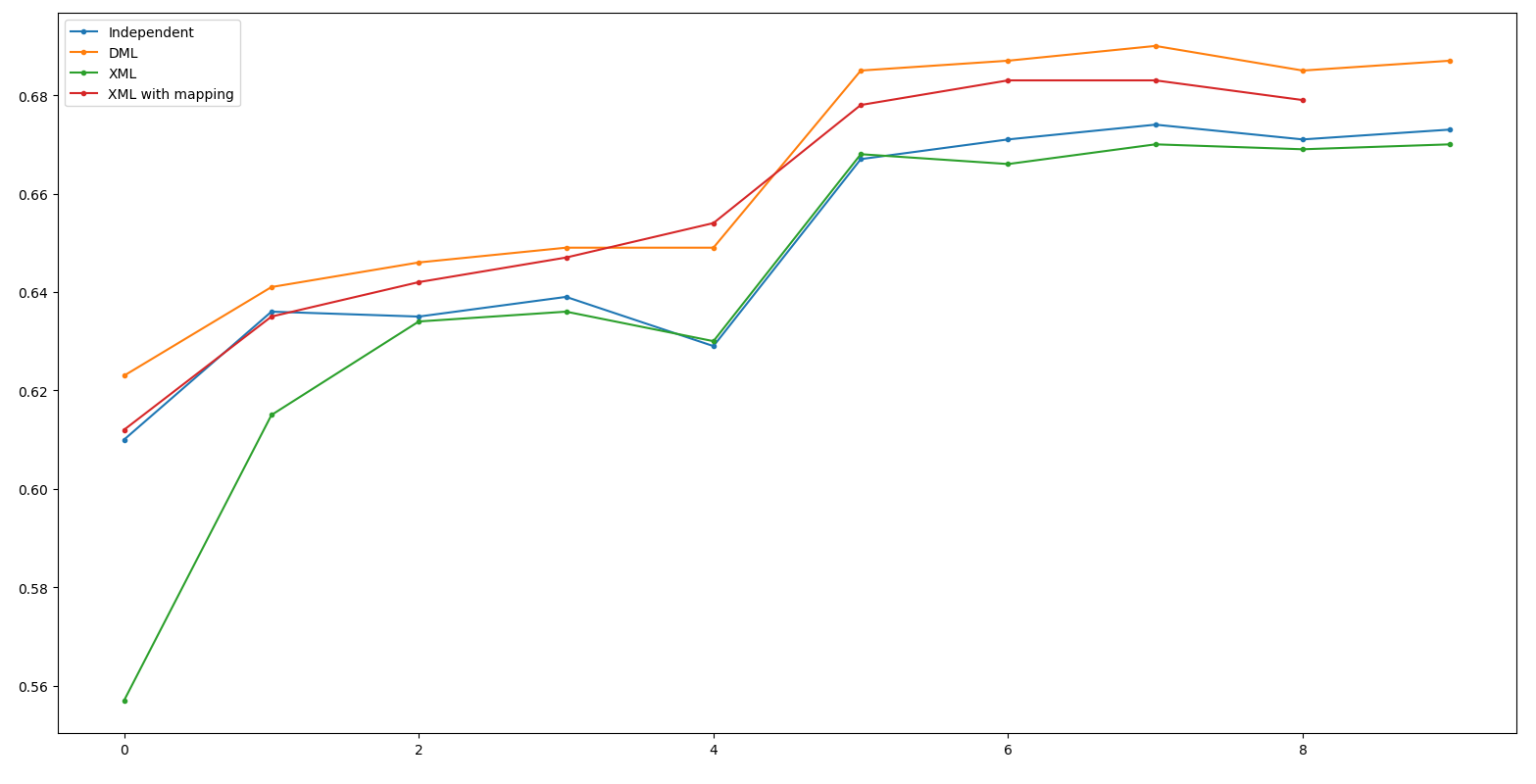
Independent: 67.4 DML: 69.0(+1.6)
XML: 67.0(-2.0) XML_m: 68.3(-0.7)
(Net 1: WRN50, Net 2: ResNet50 Net 3: RexNeXt50)
Result - ResNet50
Independent: 64.7 DML: 66.0(+1.3)
XML: 65.1(-0.9) XML_m: 65.9(-0.1)
(Net 1: WRN50, Net 2: ResNet50 Net 3: RexNeXt50)
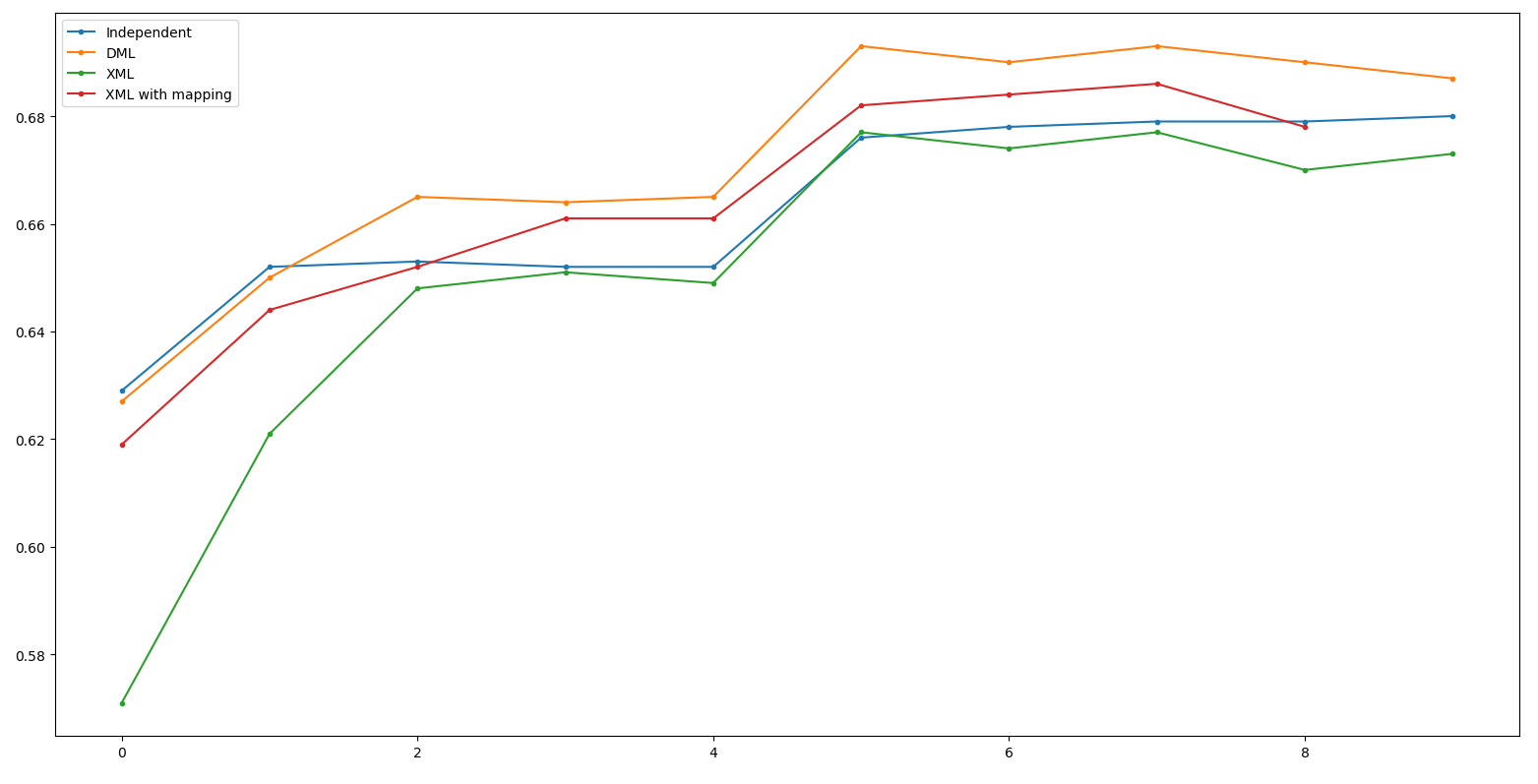
Result - ResNeXt50
Independent: 68.0 DML: 69.3(+1.3)
XML: 67.7(-1.6) XML_m: 68.6(-0.7)
(Net 1: WRN50, Net 2: ResNet50 Net 3: RexNeXt50)
Result - Xross Table
| Up Half | Down Half | Accuracy | #params |
|---|---|---|---|
| WRN50 | WRN50 | 0.65371 | 67,244,040 |
| WRN50 | ResNet50 | 0.64550 | 26,599,432 |
| WRN50 | ResNeXt50 | 0.65859 | 26,103,816 |
| ResNet50 | WRN50 | 0.64941 | 64,562,440 |
| ResNet50 | ResNet50 | 0.64316 | 23,917,832 |
| ResNet50 | ResNeXt50 | 0.65332 | 23,422,216 |
| ResNeXt50 | WRN50 | 0.65390 | 65,529,928 |
| ResNeXt50 | ResNet50 | 0.64462 | 23,885,320 |
| ResNeXt50 | ResNeXt50 | 0.66562 | 23,389,704 |
Learning Order
Why Learning Order Diff?

Net 2 所要學習的對象,
是Net 1已經看過x的model。
所以理論上來說Net 2 會學的比較好。
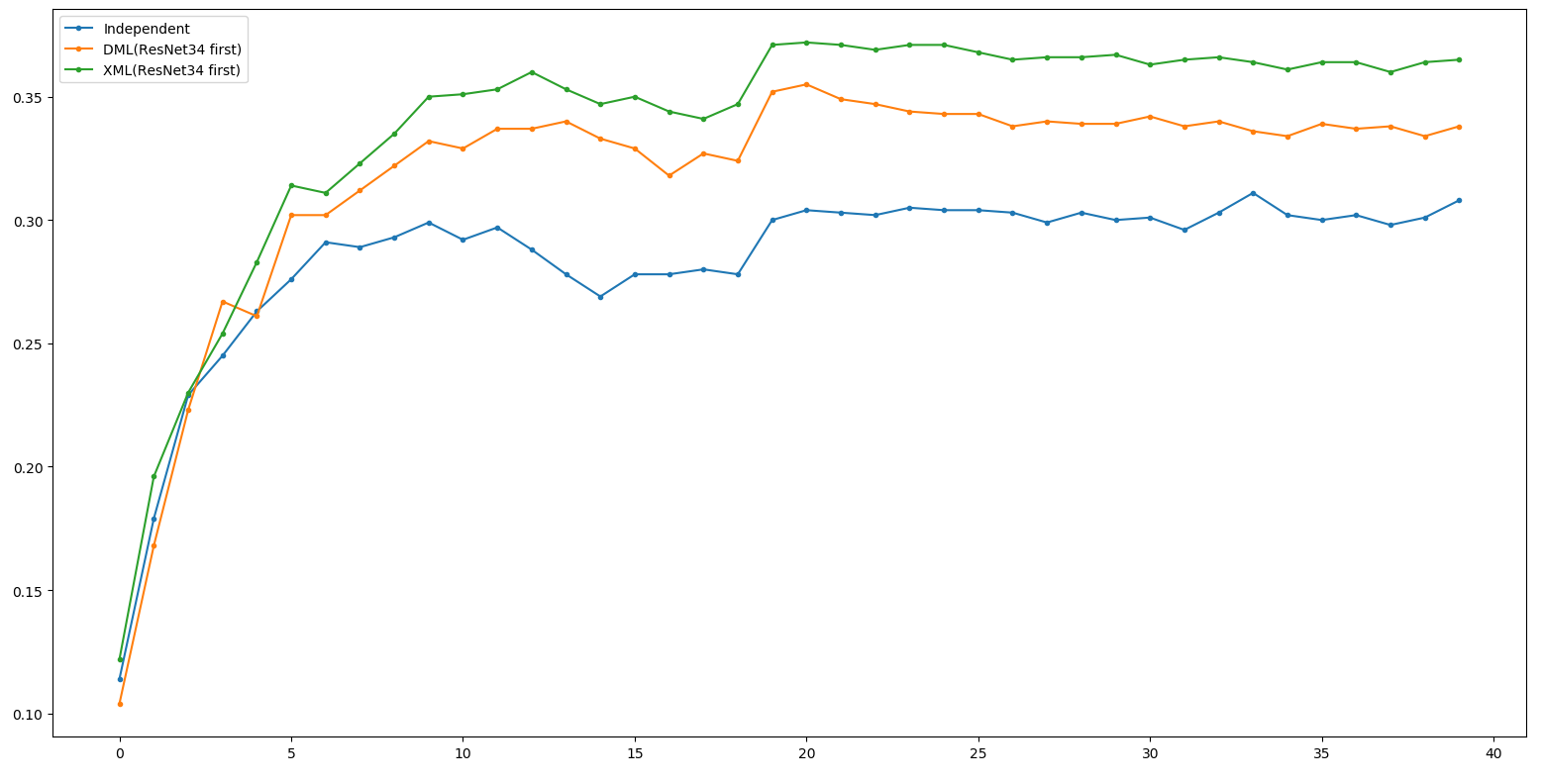
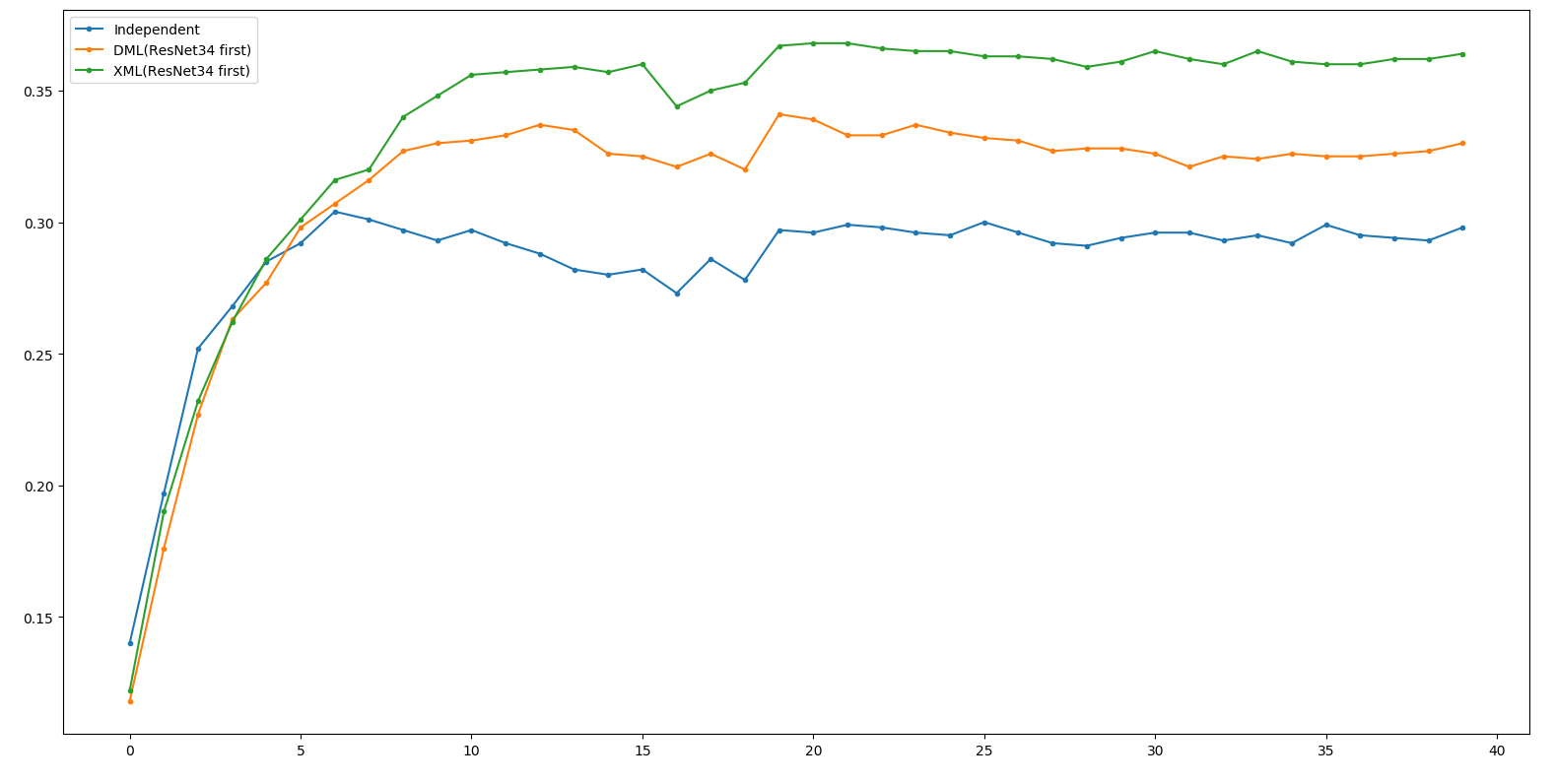
Little Result - ResNet18
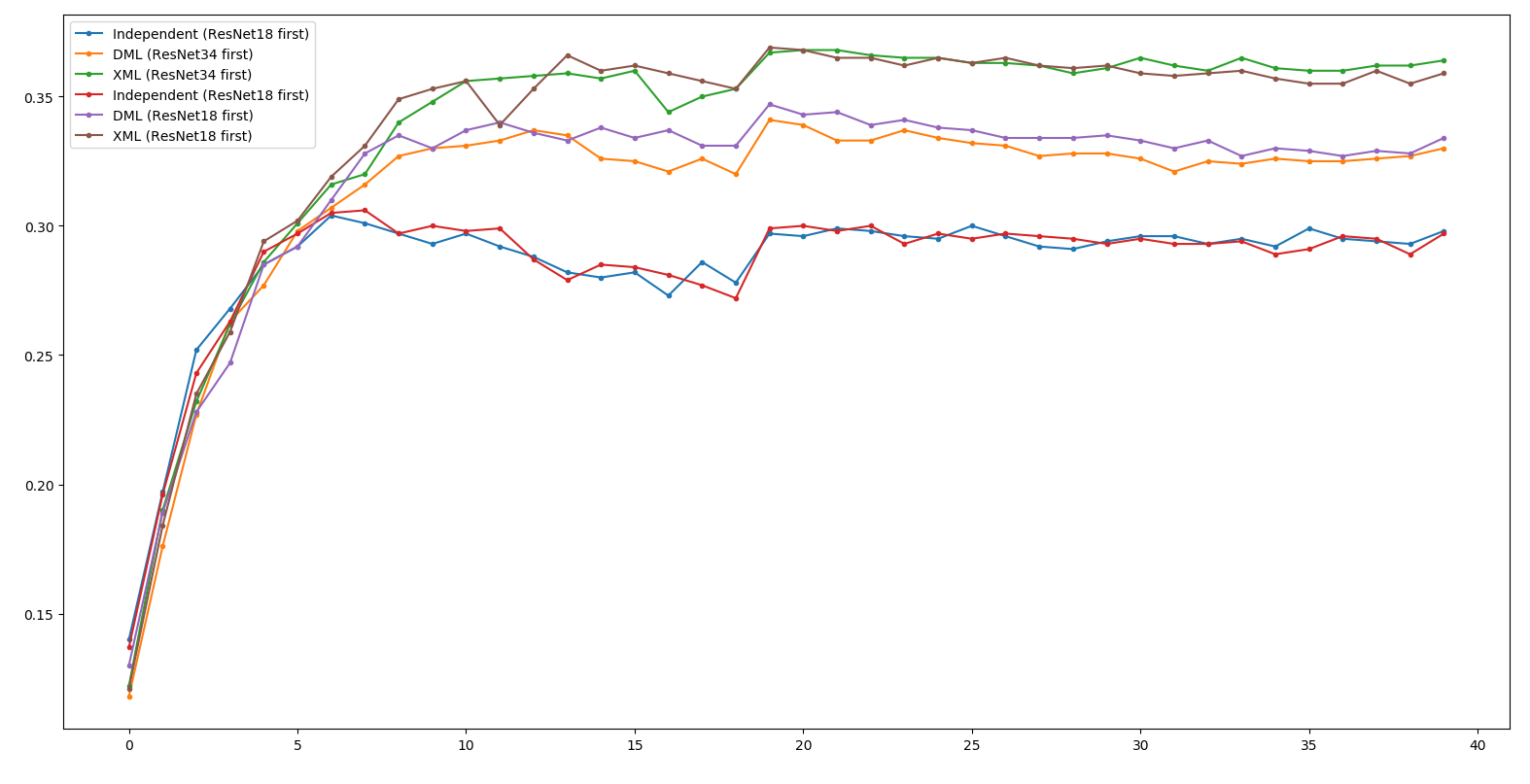
XML 18 first ~= XML 34 first >> DML 18 first > DML 34 first
>> Independent
Little Result - ResNet34
XML 18 first ~= XML 34 first >> DML 34 first > DML 18 first
>> Independent
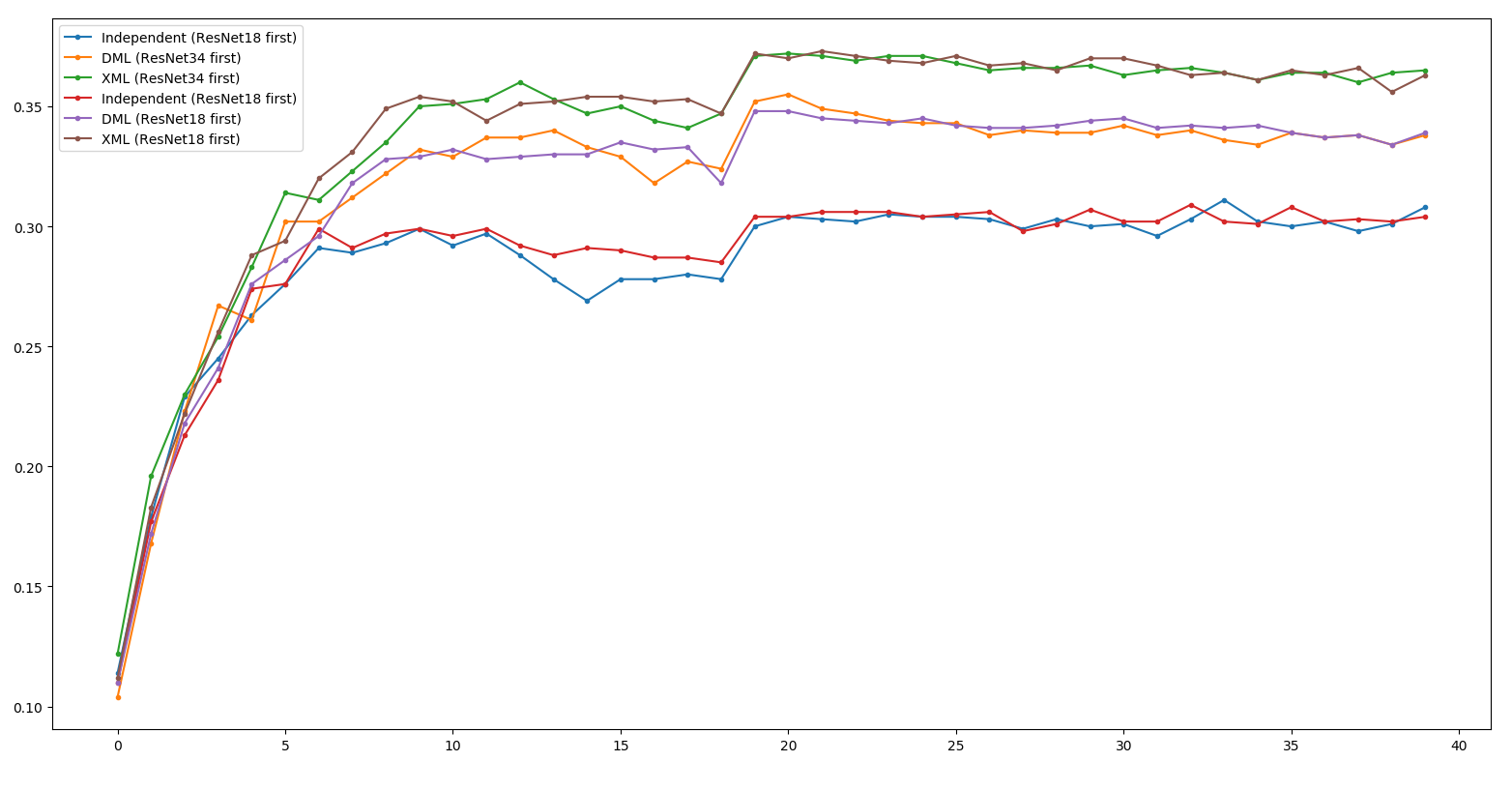
Appendix - ResNet34 @ Train
> More Generalized Minima.
Overfit / Train Curve 接近一致。
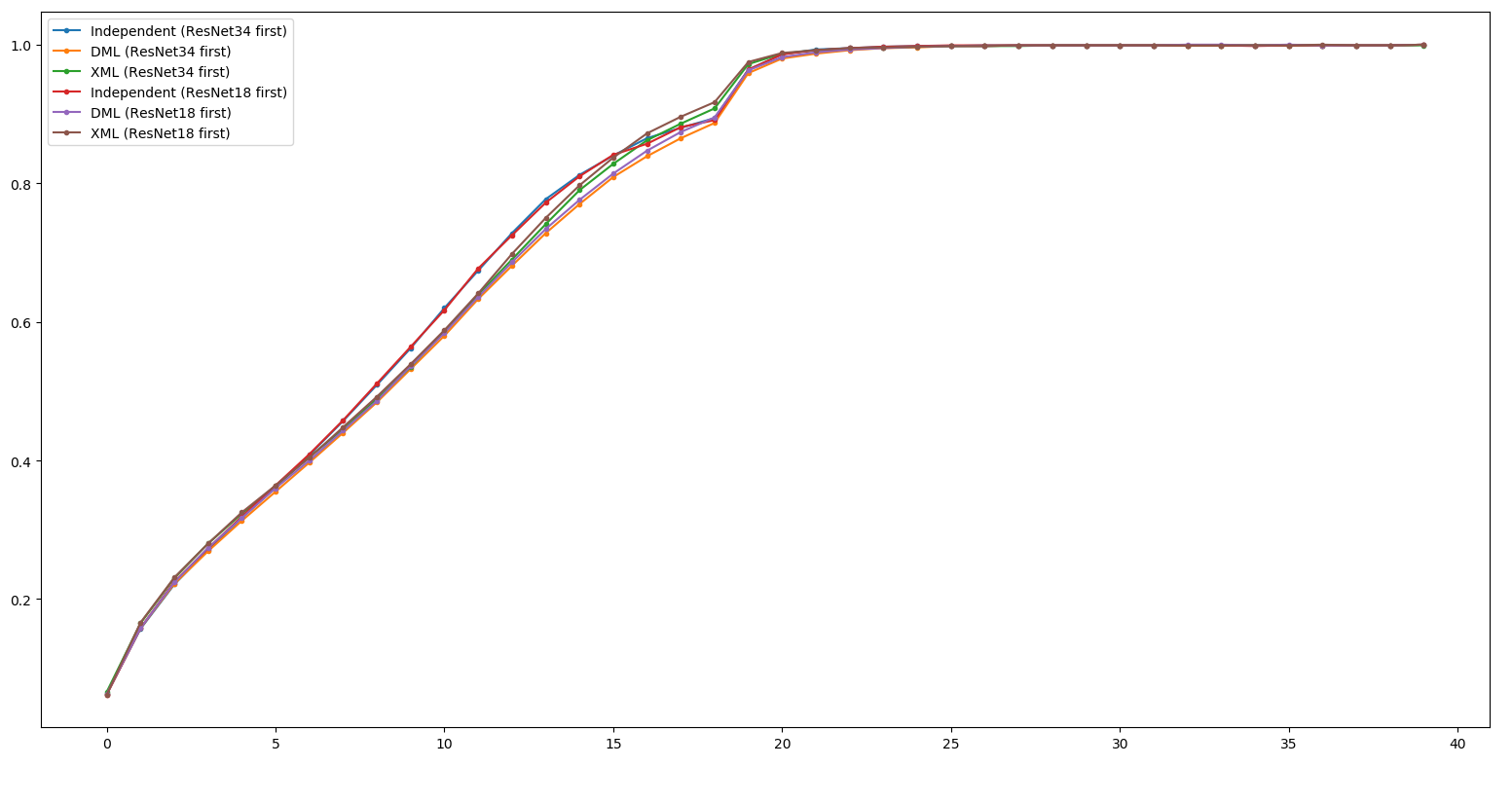
Conclusion
- XML比DML強大,即使DML順序比較好也一樣。
- XML 比較沒有需要去做順序的排列。
Next Step?
Shape Link up
Results Above are same shape in the middle.
Then, we use 1 by 1 convolution layer to connect different shape.
Overall Experiment
Net1 up-half networks
Net2 up-half networks
Net2 down-half networks
Net1 down-half networks
683,072
1,412,416
21,977,288
10,596,040
ResNet18
ResNeXt50
(512,8,8)
1x1 conv + relu
(128,8,8)
Experiment 1 (train 1)
Net1 up-half networks
Net2 down-half networks
Net1 down-half networks
1x1 conv + relu
(128, 512)
(128,8,8)
(512,8,8)
train Net1
fixed (train Net 2)
Net2 down-half networks
1x1 conv + relu
(512, 128)
Net2 down-half networks
(512,8,8)
(128,8,8)
Net1 down-half networks
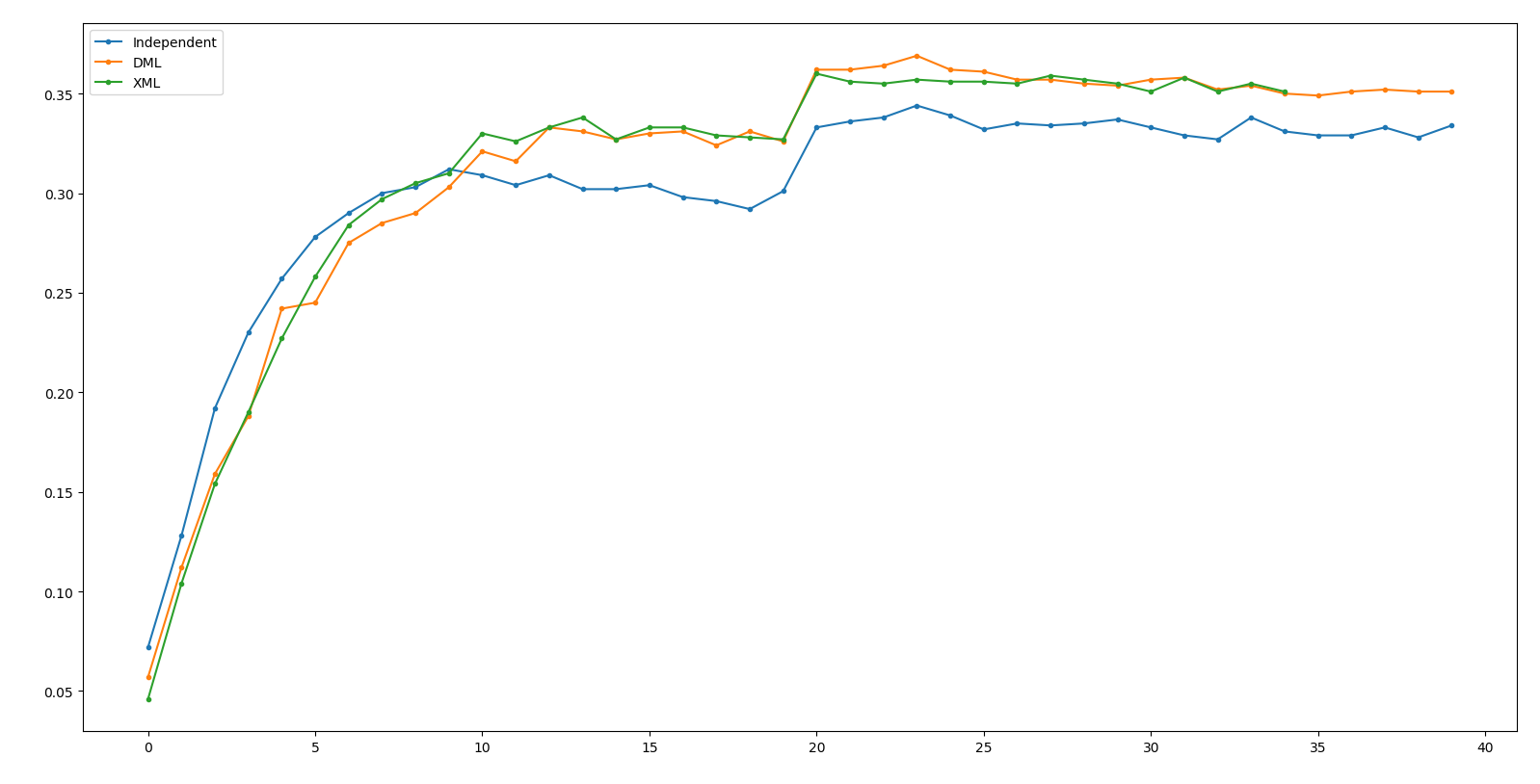
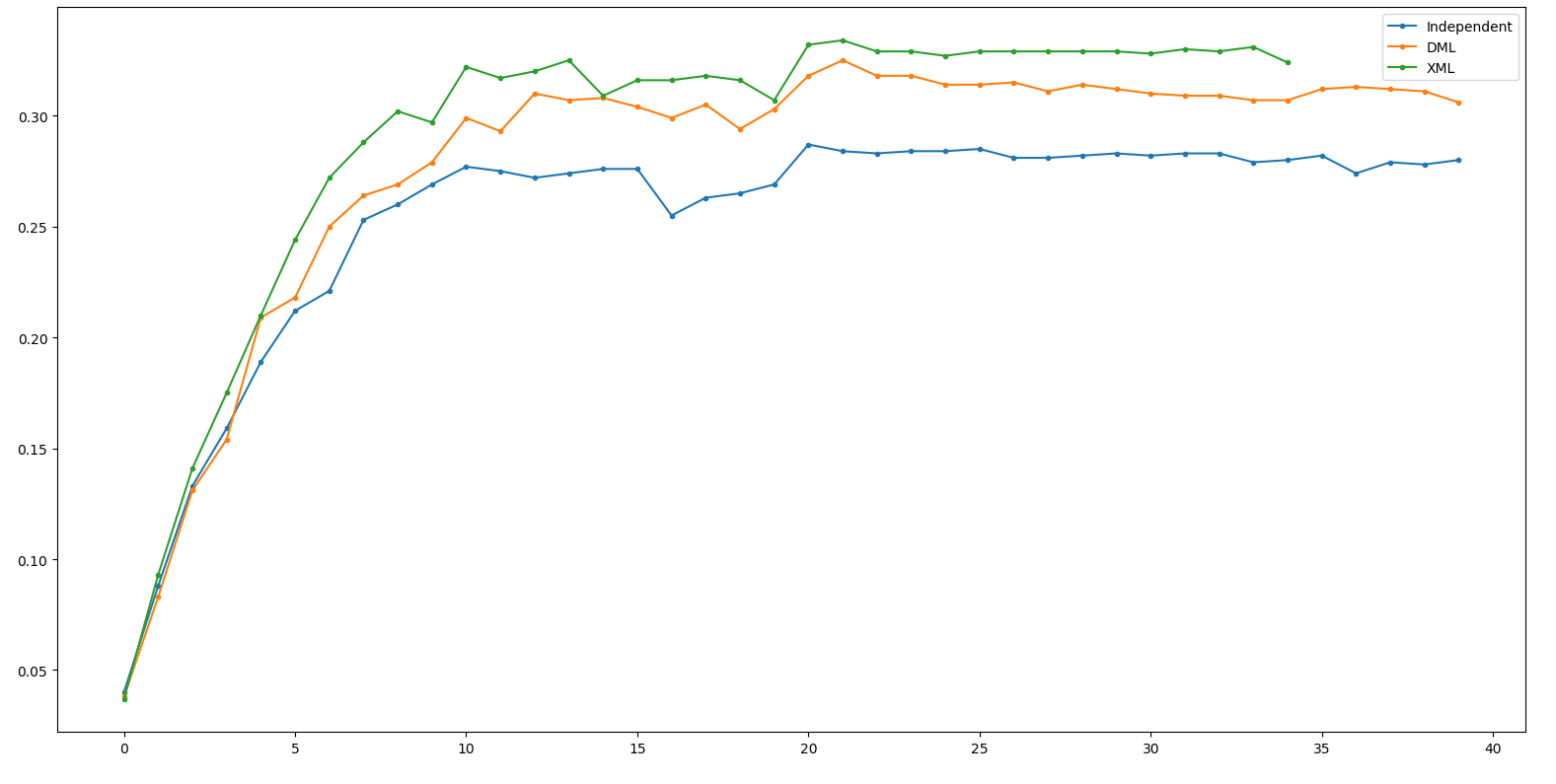
Result - ResNeXt50
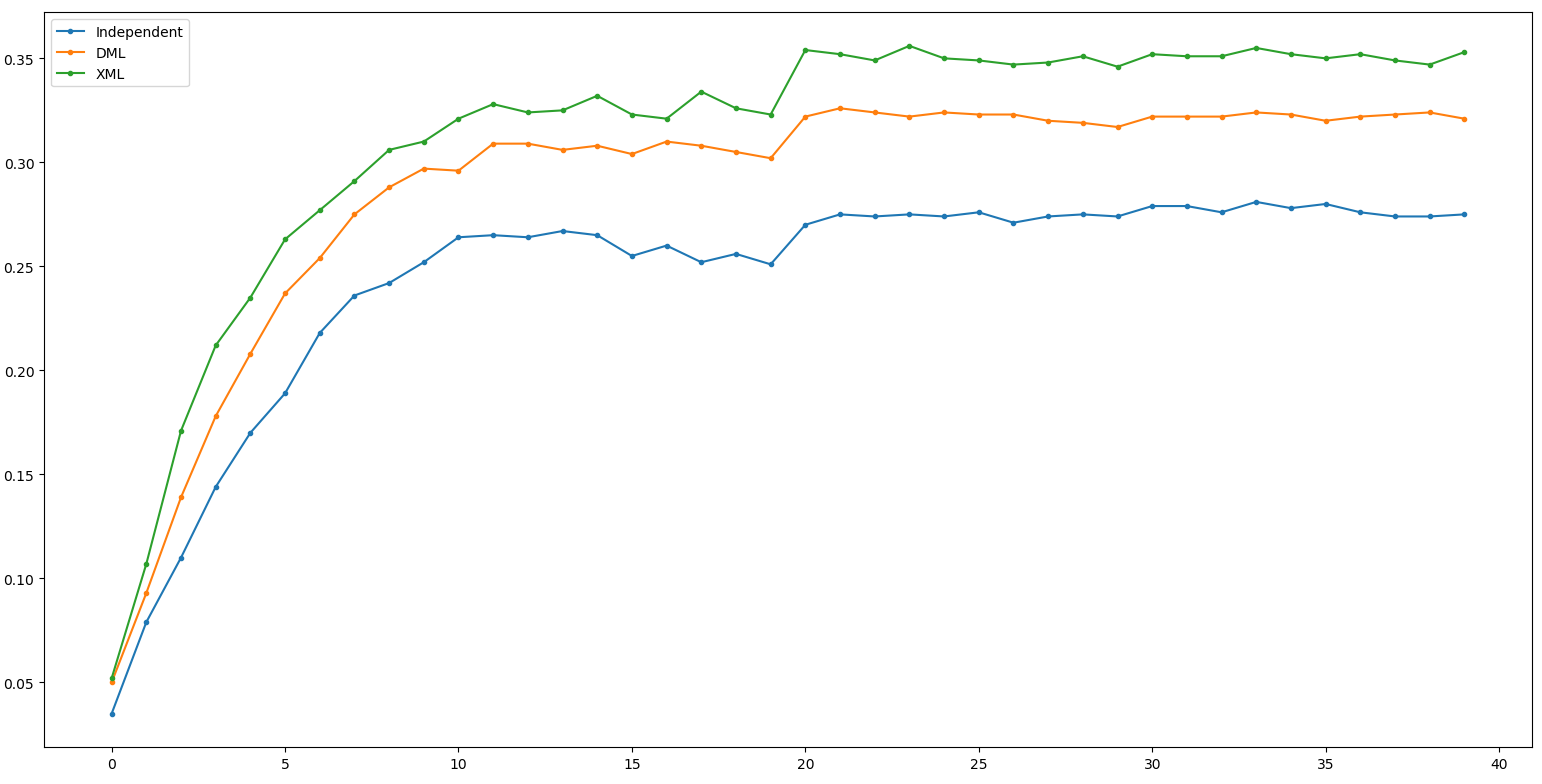
Independent: 28.1 DML: 32.6(+4.5) XML: 35.6(+3.0)
(Net 1: ResNeXt50, Net 2: ResNet18)
Result - ResNet18
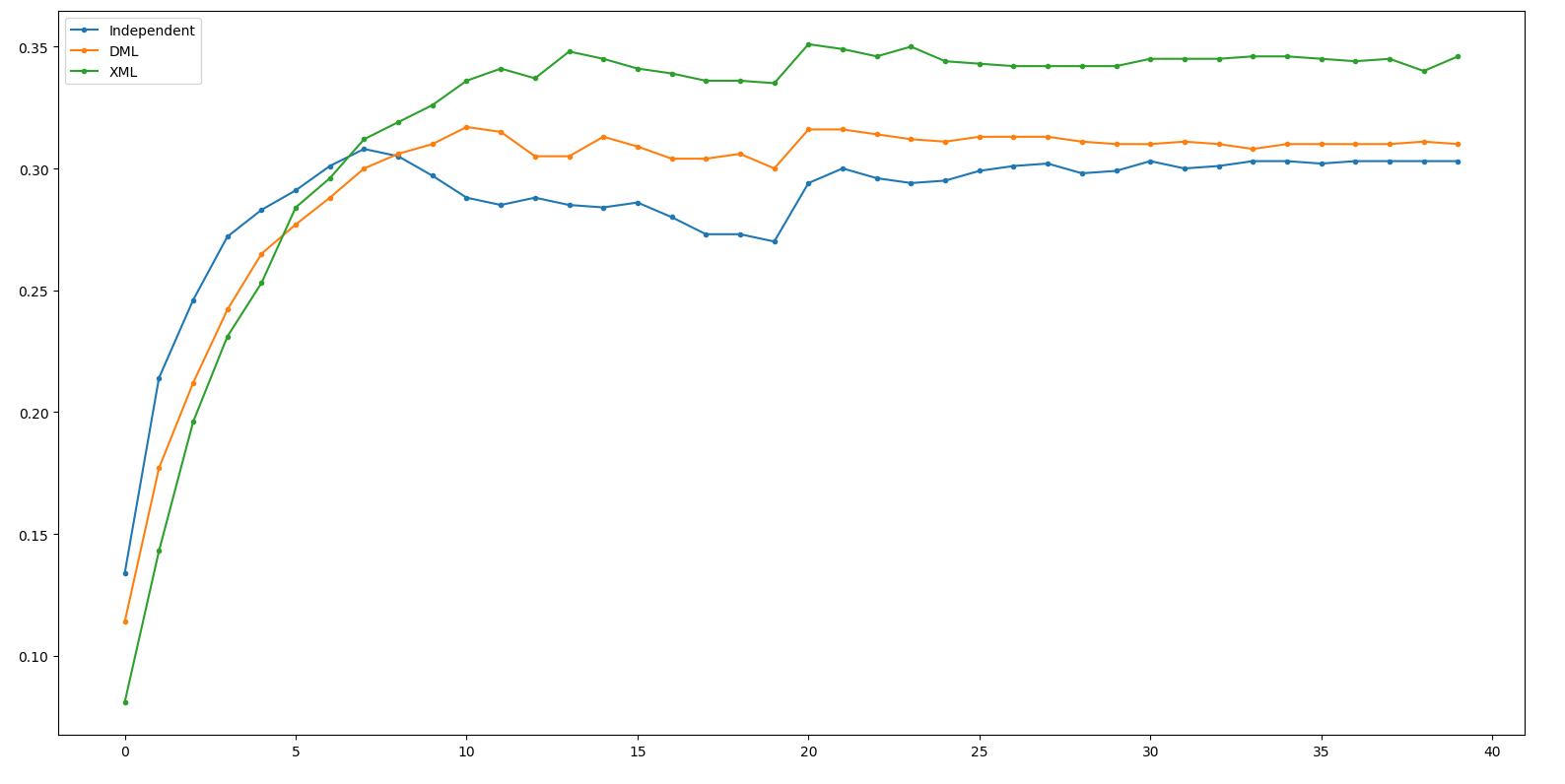
Independent: 30.8 DML: 31.7(+0.9) XML: 35.1(+3.4)
(Net 1: ResNeXt50, Net 2: ResNet18)
其實它根本就train的起來啊XD
Experiment 2 (train 1)
Net1 up-half networks
Net2 down-half networks
Net1 down-half networks
(128,8,8)
(512,8,8)
train Net1
fixed (train Net 2)
Net2 down-half networks
Net2 down-half networks
(512,8,8)
(128,8,8)
Net1 down-half networks
1x1 conv + relu
(128, 512)
1x1 conv + relu
(512, 128)
double train
Experiment 3 (Independent)
Net1 up-half networks
Net1 down-half networks
1x1 conv + relu
(128, 512)
(128,8,8)
(512,8,8)
1x1 conv + relu
(512, 128)
Experiment 4 (Not yet)
Net1 up-half networks
Net2 up-half networks
683,072
1,412,416
ResNet18
ResNeXt50
(128,8,8)
(512,8,8)
(374,8,8)
(128,8,8)
Net2 down-half networks
Net1 down-half networks
21,977,288
10,596,040
Experiment 5 (Not yet)
Net1 up-half networks
Net2 up-half networks
683,072
1,412,416
ResNet18 * 4
ResNeXt50
(128,8,8) * 4
(512,8,8)
Net2 down-half networks
Net1 down-half networks
21,977,288
10,596,040
Multiple Xross
Experiment
Net1
Part1
first + layer1
ResNet18
(w/o pretrained)
ResNet34
(w/o
pretrained)
Adam, 1e-4
Net2
Part1
first + layer1
Net2
Part2
layer 2
Net2
Part3
layer 3,4
Net1
Part2
layer 2
Net1
Part3
layer 3,4
157,504
231,488
19,988,068
10,544,740
1,106,036
517,888
Experiment
Net1
Part1
first + layer1
ResNet18
(w/o pretrained)
ResNet34
(w/o
pretrained)
Adam, 1e-4
Net2
Part1
first + layer1
Net2
Part2
layer 2
Net2
Part3
layer 3,4
Net1
Part2
layer 2
Net1
Part3
layer 3,4
157,504
231,488
19,988,068
10,544,740
1,106,036
517,888
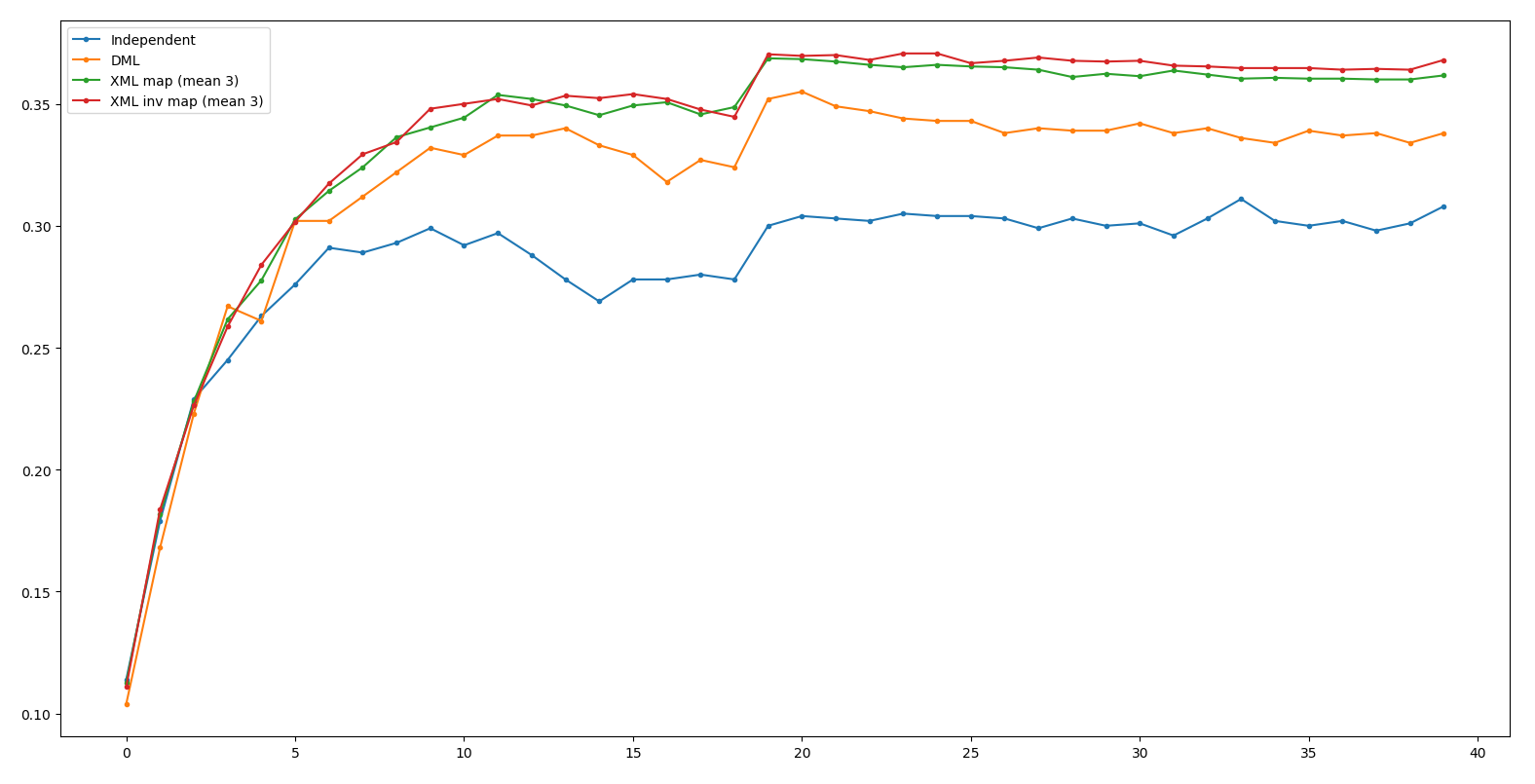
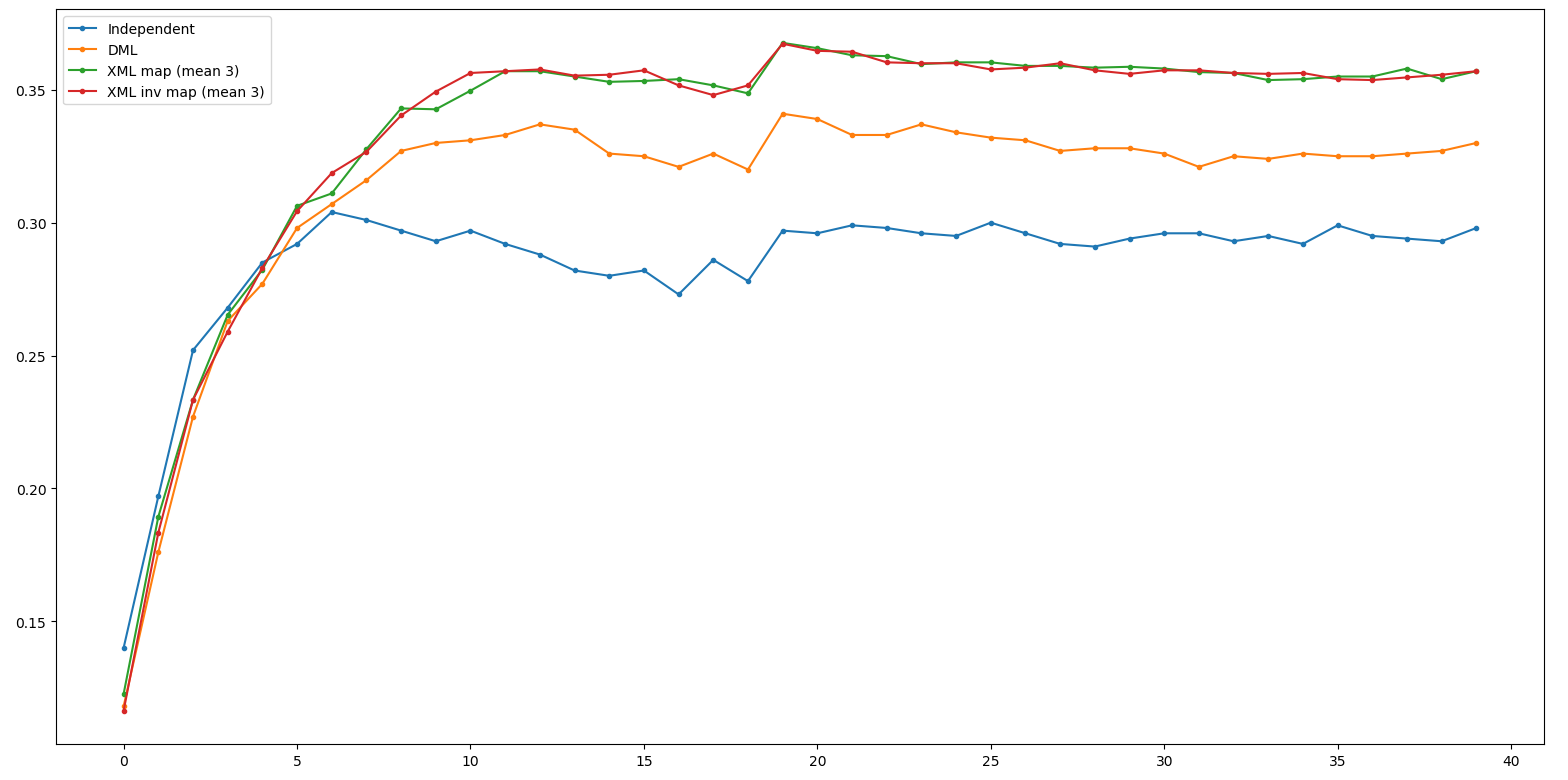
Result - ResNet34
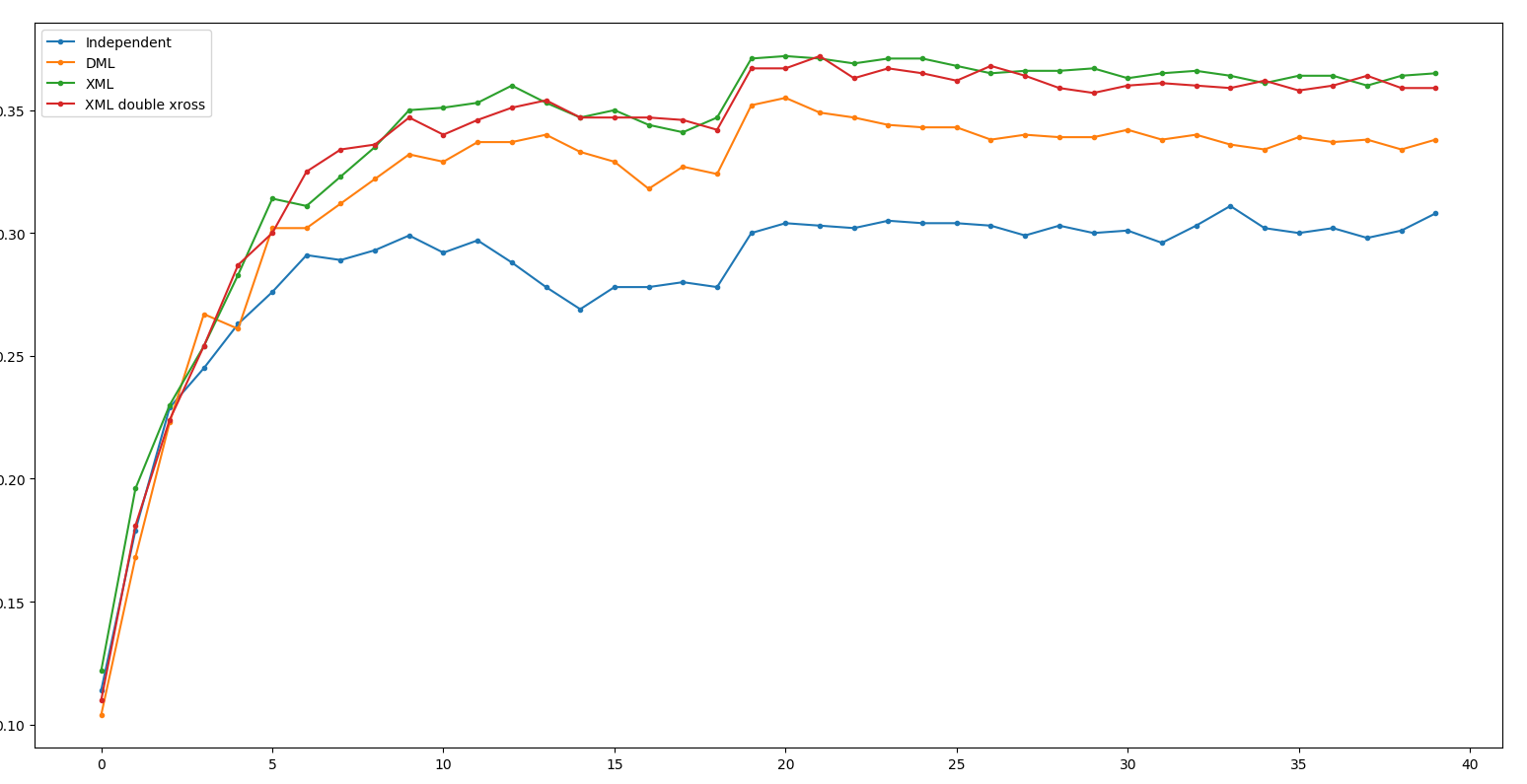
Independent: 0.311 DML: 0.355
XML: 0.372 XML double xross: 0.372 (+0.0)
Result - ResNet18
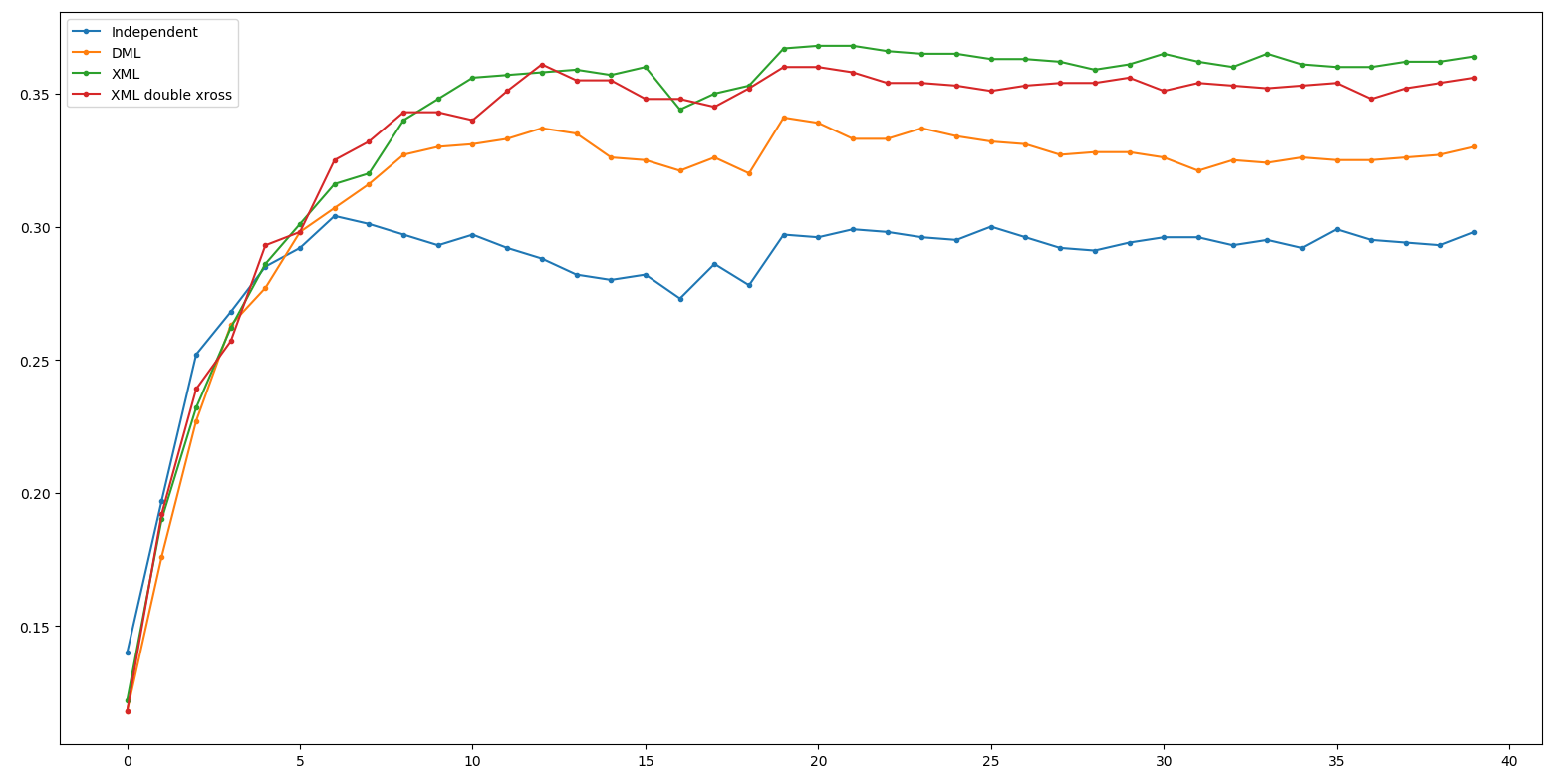
Independent: 0.304 DML: 0.341
XML: 0.368 XML double xross: 0.361 (-0.7)
Result Table
| Part1 | Part2 | Part3 | Accuracy | #Params |
|---|---|---|---|---|
| ResNet34 | ResNet34 | ResNet34 | 36.572 | 21.32m |
| ResNet34 | ResNet34 | ResNet18 | 36.044 | 11.88m |
| ResNet34 | ResNet18 | ResNet34 | 36.181 | 20.73m |
| ResNet34 | ResNet18 | ResNet18 | 35.986 | 11.29m |
| ResNet18 | ResNet34 | ResNet34 | 35.654 | 21.25m |
| ResNet18 | ResNet34 | ResNet18 | 36.201 | 11.80m |
| ResNet18 | ResNet18 | ResNet34 | 35.820 | 20.66m |
| ResNet18 | ResNet18 | ResNet18 | 35.966 | 11.22m |
Param - Acc
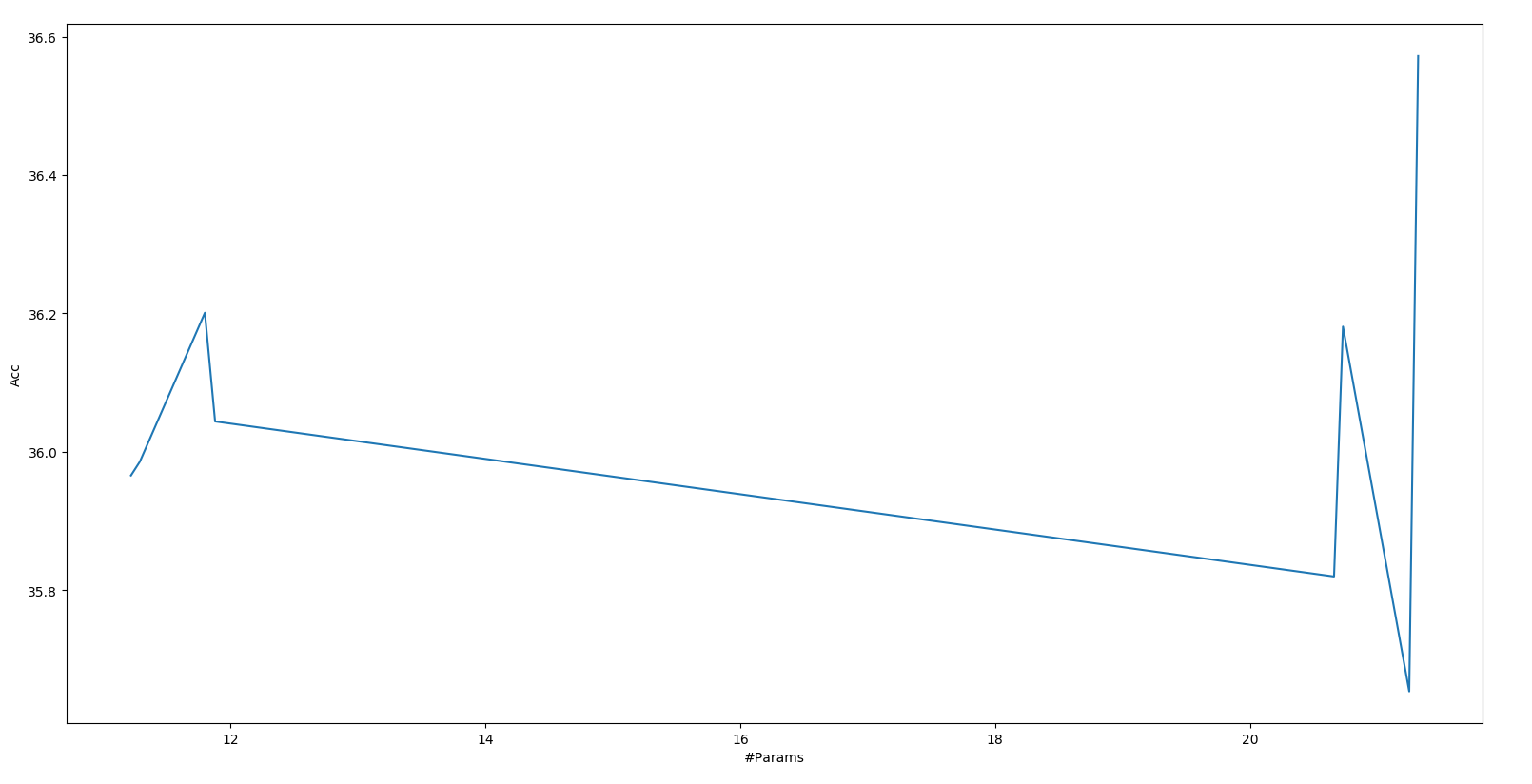
需要更多實驗來找到如何 切 以及如何 取
(Maybe) Next Steps
Next Steps
- What About KD?
- More Survey of Dynamic Computation
- Issue: When to store and can it Xross?
- Issue: When to split and how to find it?
Mutual Learning But One Pretrained
對於KD來說,
其中一個是pretrained。
既然使用pretrained的model做XML是有用的,那麼會不會對其中一個已經pretrained好的model做Mutual Learning也會比原本好呢?
Experiment
Dynamic Computation
MSDNet (ICLR '18)
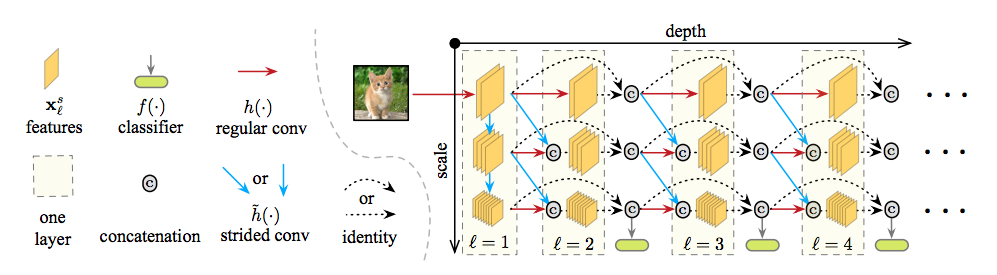
大致上就是做出一個二維個Blocks。
縱軸表示複雜度,橫軸表示作到第幾個。
如果作到一半需要quit,就直接接classifier
提出兩點重要的Dynamic Computation依據:
1. 限時內要跑完。 2. 限定資源跑完。
Dynamic Computation
Net1 part1 networks
Net2 part1 networks
Net3 part1
networks
Net1 part2 networks
Net2 part2 networks
Net3 part2
networks
Net1 part3 networks
Net2 part3 networks
Net3 part3
networks
Time Cost
Not easy -
Ensemble Combination
Net1 part1
networks
Net1 part2 networks
Net2 part2 networks
Ensemble
Ensemble maybe good - Experiment
Net1 part1
networks
Net1 part2 networks
Net2 part2 networks
Ensemble
When to store?
When to store?
Net1 epoch1
Acc: 0.30
Net2 epoch1
Acc: 0.56
Net1 epoch2
Acc: 0.56
Net2 epoch2
Acc: 0.50
Net1 epoch3
Acc: 0.54
Net2 epoch3
Acc: 0.54
Net1 epoch4
Acc: 0.53
Net2 epoch4
Acc: 0.70
Can be cross?
Net1 epoch2
half Acc: 0.56
Net2 epoch4
half Acc: 0.70
Net1 epoch2
half Acc: 0.56
Net2 epoch4
half Acc: 0.70
?
Where to Split?
Conclusion
Conclusion
- Xross Learning can be applied in different dataset.
- Pretrained model not works, we can
- Use XML to Pre-trained .
- Apply Channel Mapping -> ~DML but can dynamic
- Cohorts Learning maybe not improve model by some case.
- Maybe we need to more KL divergence / mimic loss.
- Different #Chs does not matter. (if output feature sizes are the same)
- Multiple Xross Learning may worse than Single Xross, but still better than DML, and can be dynamic.
- More flexible than MSD-net?
Further Question or Next Step?
Pretrain - Warmup
Net1 up-half networks
Net2 up-half networks
683,072
1,412,416
ResNet18
ResNet34
1x1 conv + relu
1x1 conv + relu
L2-loss
L2-loss
Experiment 2 (warm-up)
Net1 up-half networks
Net2 down-half networks
1x1 conv + relu
train Net1
train Net 2
Net2 up-half networks
Net1 down-half networks
1x1 conv + relu