KD & Mutual
Arvin Liu
Target
Model Compression
Method
Teacher (usually pretrained) - Student Architectue
Baseline KD
Distilling the Knowledge in a Neural Network (NIPS 2014)
Abstract
透過 soft label讓小model可以學到class之間的關係。

Soft Labels + Hard Labels
Soft Labels & Temperature

Teacher model too mean ->
needs temperature (hyper-parameters)
Work Flow

\lambda = 0.5 \text{ in paper}
Mutual Learning
Deep Mutual Learning
(CVPR 2018)
Work Flow - Mutual

* train from scratch
* needs train iteratively
Net1 Loss = D_KL(y2||y1)
Algorithm - Step 1
Logits
y_{1,t}
y_{2,t}
x_t
Networks2
Networks1
Step 1: Update Net1
y
True Label
CE
D_{KL}(y_{2,t}||y_{1,t})
Loss_1 = D_{KL}(y_{2,t}||y_{1,t})+ \text{CrossEntropy}(y,y_{1,t})
Algorithm - Step 2
Logits
y_{1,t}
y_{2,t}
x_t
Networks2
Networks1
Step 2: Update Net2
y
True Label
CE
D_{KL}(y_{1,t}||y_{2,t})
Loss_2 = D_{KL}(y_{1,t}||y_{2,t})+ \text{CrossEntropy}(y,y_{2,t})
Algorithm - (Paper)

Experiments (CIFAR100)

WRN(Wide-Residual-Networks)
- 由ResNet-32 / ResNet-32 以及MobileNet / MobileNet的實驗結果:即使用兩個相同網路架構去做mutual都會比Independent的更好。
- 由WRN-28-10 / MobileNet的實驗結果得知:即使讓大Model去學小Model的logits,做起來也會更好。
Acc Curve (ImageNet)
總之就是DML的Acc Curve幾乎從頭開始就會大於Independent。

Semi-Supervised Ver.
就是將原本的hard-target關掉給0。

(Labelled data)
(All data)
Cross-Modal ver.
CROSS-MODAL KNOWLEDGE DISTILLATION FOR ACTION RECOGNITION (10/10), ICIP 2019

Cohorts Learning
Cohorts Strategy 1
\Theta_{1,1}
\Theta_{2,1}
\Theta_{3,1}
\Theta_{4,1}
\Theta_{1,2}
\Theta_{2,2}
\Theta_{3,2}
\Theta_{4,2}
\Theta_{1,3}
\Theta_{2,3}
\Theta_{3,3}
\Theta_{4,3}
D_{KL} (2||1)
D_{KL} (3||1)
D_{KL} (4||1)
\Theta_{1,1}
\Theta_{2,1}
\Theta_{3,1}
\Theta_{4,1}
\Theta_{1,2}
\Theta_{2,2}
\Theta_{3,2}
\Theta_{4,2}
\Theta_{1,3}
\Theta_{2,3}
\Theta_{3,3}
\Theta_{4,3}
D_{KL} (\frac{(2+3+4)}{3}||1)
Cohorts Strategy 2
Result - Strategy 1 works better.
Because Strategy2 leads less entropy.
Cohorts Experiments

單Model Accuracy
所有Model Ensemble
Accuracy
Why works?
1. Generalization Problem
All model's training accuracy will goes to 1.000
However, the validation accuracy is not.
One of Generalization Evaluation - Flatness

BIASINGGRADIENTDESCENTINTOWIDEVALLEYS ICLR 2017
Examples of Flatness Evaluation
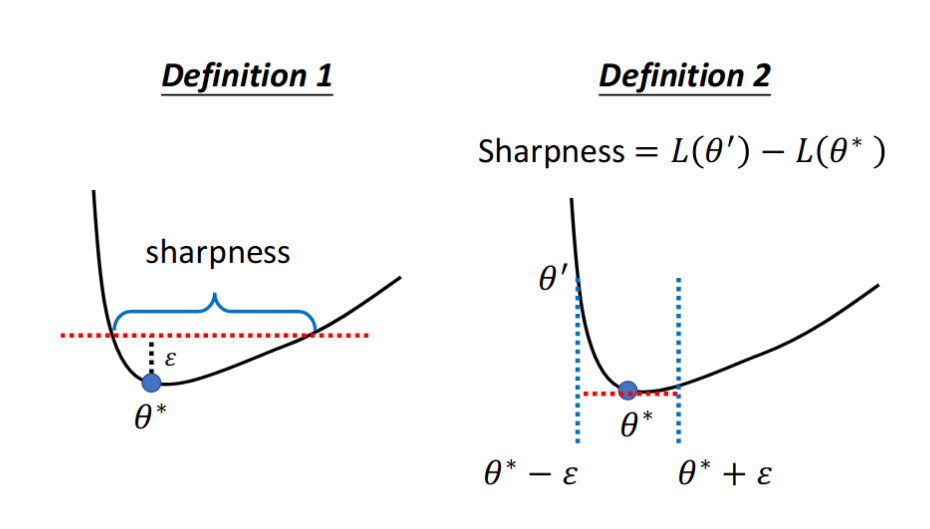
Flatness Evaluation @ DML
x
Networks1
\Theta
+ \sigma(0,\alpha)
y
'
Gaussian Noise
看看最後acc掉多少
Gaussian Noise -> Model

不管gaussian noise多強,DML下降的loss明顯較少
Why works?
2. Entropy Regularization
Logit Entropy

ResNet32 / CIFAR100 -
Mean Entropy ind vs dml = 1.7099 and 0.2602
Entropy is regularized
Entropy Regularization 可以找到比較wide的minima。
詳細數學於Flatness的paper有提及。
Experiments on Entropy Regularization vs DML
Entropy : 有做Entropy Regularization
Why works?
3. My viewpoint - Adaptive Temperature
In Baseline KD
We need temperature to increase entropy
In mutual learning
Entropy 一定是越來越低 ->
他是一種Adaptive Temperature的Knowledge Distillation,而且更有意義。
(如果只用一個model在學的觀點來看)
Feature Similarity & Why Cohorts works
Feature t-sne

In this: we know they learned different feature
-> cohort learning let single model learned more feature.
Diverse Feature Proof
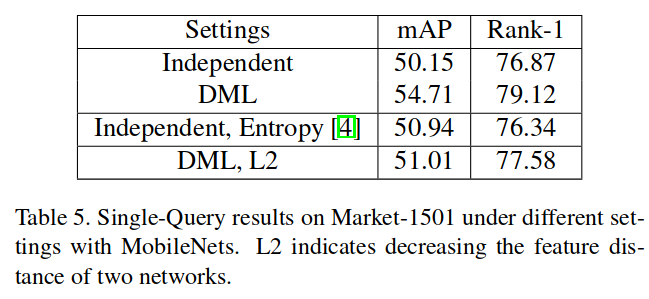
DML + L2 makes accuracy lower. -> prove the thought?
Really?
[Neuron switch problem]
Neuron Switch Problem
ResNet[::-1]
x
Flatten
W
Logits
a
c
b
d
c
b
d
a
W'
Feature
But obviously,
the features are different after t-sne clustering
Actually...
Independent < DML + L2 in mid < DML
However, I have some magic disprove it.
Q&A?
KD & Mutual
By Arvin Liu




