Intro to KD
Arvin Liu - MiRA Training course
Knowledge Distillation
Please use the link: slides.com/arvinliu/kd
Outlines
-
Missing info in data
-
Before KD:
-
Entropy Regularization
-
Label Refinery
-
-
What is Knowledge Distillation?
-
Baseline Knowledge Distillation
-
-
Does teacher model have to be larger?
-
Teacher-free KD
-
Other KD's techniques
Missing info in data
Logits Regularization

Where's the problem in the following image if you are training an @1 image classification?
Logits Regularization
Where's the problem in the following image if you are training an @1 image classification?
- Exist "cat" & "ball" at the one image.
- -> Incompleteness.
- Problem after cropping.
- -> Inconsistency.
Taxonomy Dependency
- What one-hot label might hurt your model?
-
GT will give a large penalty to your model and make it overfit.
-

GT
Human
Model
P(y=5) = 0.5 \\
P(y=3) = 0.5
P(y=5) = 0.4 \\
P(y=3) = 0.6
P(y=5) = 1.0 \\
P(y=3) = 0.3
Loss
What data
looks like
How to solve these problem?
- Incompleteness: multiple labels in one image.
- Inconsistency: wrong label after cropping.
- Taxonomy Dependency: there's similar class.
Blindly trust GT, will let your model overfit.
And, to solve overfitting, the naive method is ....
So far, we introduce three problems:
Regularization
Before KD
Entropy Regularization

-
Entropy ( Logits( Your model after long time training ) ) ~= 0.
- Does your model really need suck a high level of high confidence ?🤔
- What's the tradeoff?
- Make your entropy( logits ) more higher!
Entropy Regularization
- Make your entropy( logits ) more higher!
Class A
Data
Class A
Class B
Class C
CE
CE
CE
CE
Loss = CE(y',y)
+ \frac{\lambda}{CNum} \sum_{c}^{CNum} CE(y', c)
Can't we make regularization more informative?
Label Refinery (2018)
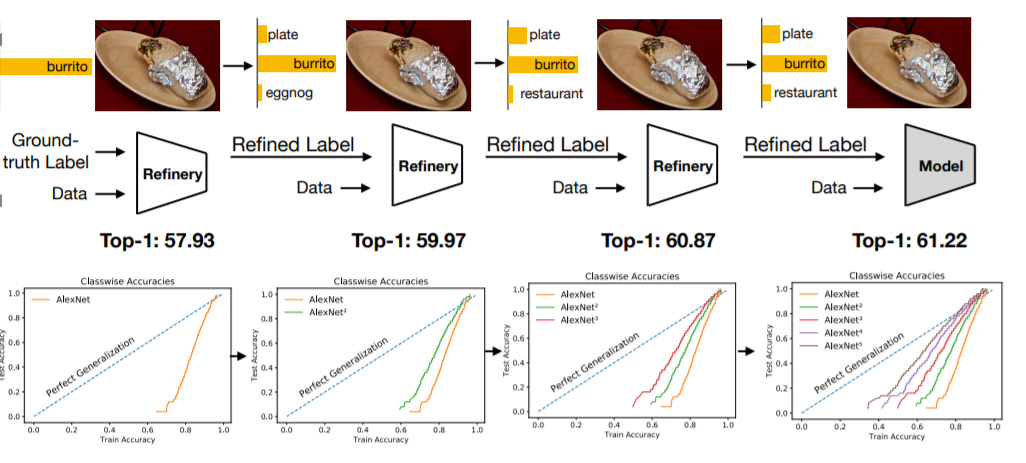
-
Use Ground Truth Label to train your first model.
-
Use the first model’s logits to train your second model.
-
Continue train models until the accuracy converges.
Like noisy student, huh?
Label Refinery (2018)
- Incompleteness: multiple labels in one image.
- Inconsistency: wrong label after cropping.
- Taxonomy Dependency: there's similar class.
- Does label refinery help solving these three problem?
Now, that's go back to KD
What is KD?
What is Network Compression?
-
Make small models work like large models. i.e. accuracy.
-
Why? Apply your models on resource-limited device.
-
common methods:
-
Network Pruning
-
Low Rank Approximation
-
Quantization (ex: float16 -> int8)
- Knowledge Distillation
-
Large
Model
Small
Model
Magic
What is Knowledge Distillation?
Pre-trained
Large
Model
Untrained
Little
Model
-trained
Little
Model
Guide
-
Let pre-trained model guide small model by some "knowledge". For example,
-
Taxonomy Dependency
-
Feature Transformation, ...
-
Good
Baseline KD
-
Recap Label Refinery:
Model 1
GT
Model 2
Model 3
CE
CE
CE
-
What about Baseline KD?
Teacher
GT
Student
KL_{div} \text{ with temperature}
Loss = \alpha T^2 \times KL(softmax(\frac{\text{Teacher's Logits}}{T})|| softmax(\frac{\text{Studente's Logtis}}{T})) + \\ (1-\alpha) (\text{Original Loss})
Baseline KD - Temperature
-
Why we need temperature?
-
Well-trained model has very low entropy -> like one-hot.
-
Loss = \alpha T^2 \times KL(softmax(\frac{\text{Teacher's Logits}}{T})|| softmax(\frac{\text{Studente's Logtis}}{T})) + \\ (1-\alpha) (\text{Original Loss})
logits_{T} = [100, 10, 1]
softmax(logits_{T}) = [1, \simeq0, \simeq0]
softmax(\frac{logits_{T}}{100}) = [0.56, 0.23, 0.21]
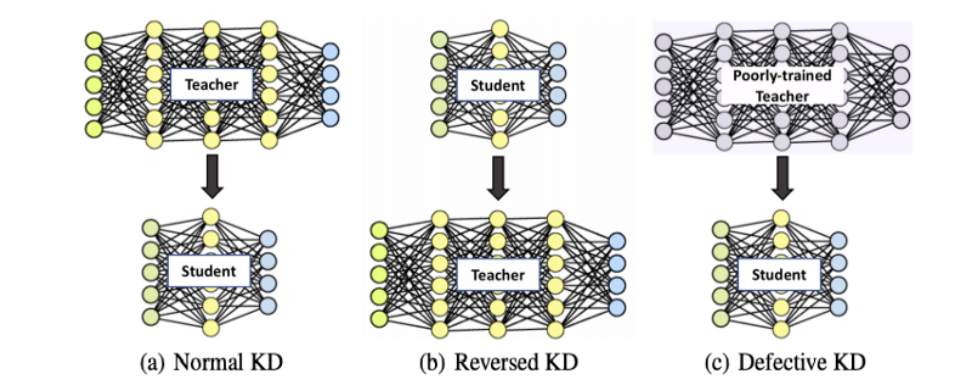
Does teacher model have to be larger?
Result of Re-KD
-
You may sense that distill from same model still improve...
-
Think about label refinery!
-
Model 1
GT
Model 2
Model 3
CE
CE
CE
-
What if the teacher model is far smaller than student? (Re-KD)
-
Still works! (Better than training independently)
-
Result of Re-KD

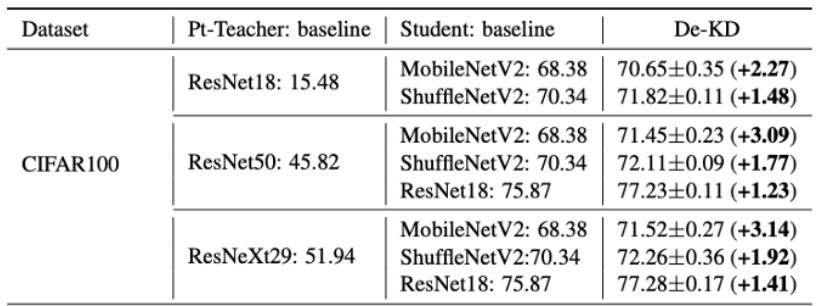
Teacher-free KD
Teacher-free KD
-
We know about label refinery...
Model 1
GT
Model 2
Model 3
CE
CE
CE
-
What if we merge label refinery & KD (distill to smaller one?)...
Teacher 1
GT
Student 1
CE
CE
CE
Student 2
-
Born again neural networks. (ICLR 2018)
Born again NN (BAN)
-
Teacher only teach the first student.
-
Usually ensemble after training.
Teacher 1
GT
Student 1
CE
CE
CE
Student 2
Teacher-free KD
-
We know about label refinery...
Model 1
GT
Model 2
Model 3
CE
CE
CE
- Born again neural networks. (ICLR 2018)
-
What if we let the student guide the teacher?
Teacher 1
GT
Student 1
CE
CE
CE
Student 2
Teacher 1
GT
Student 1
Teacher 1
Deep Mutual Learning
Logits
y_{1,t}
y_{2,t}
x
Step 1: Update Net1
y
CE
D_{KL}(y_{2,t}||y_{1,t})
Loss_1 = D_{KL}(y_{2,t}||y_{1,t})+ \text{CrossEntropy}(y_{1,t},y)
Network 1
Network 2
GT
Deep Mutual Learning
Logits
y_{1,t}
y_{2,t}
x
Step 2: Update Net2
D_{KL}(y_{1,t}||y_{2,t})
Loss_2 = D_{KL}(y_{1,t}||y_{2,t})+ \text{CrossEntropy}(y_{2,t},y)
Network 1
Network 2
y
CE
GT
Loss_1 = D_{KL}(y_{2,t}||y_{1,t})+ \text{CrossEntropy}(y_{1,t},y)
Deep Mutual Learning
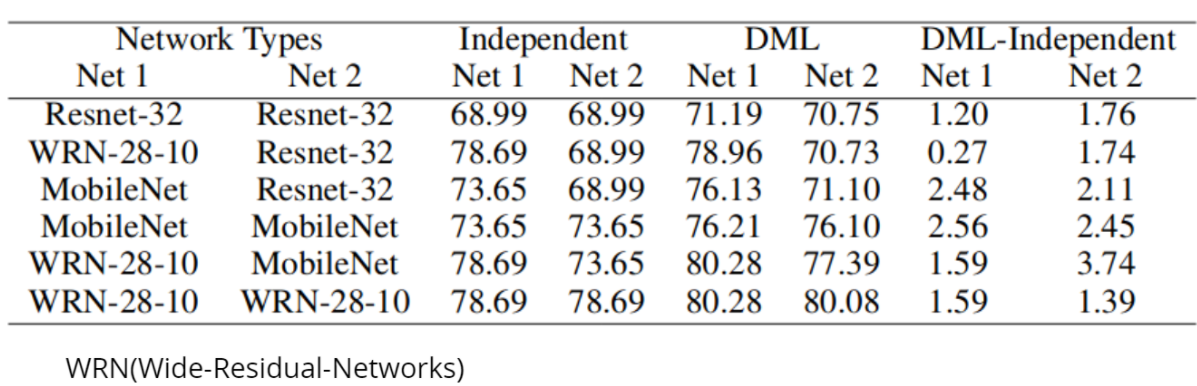
-
Experimental statistics are very satisfactory :).
Teacher-free KD
-
We know about label refinery...
Model 1
GT
Model 2
Model 3
CE
CE
CE
- Born again neural networks. (ICLR 2018)
-
Two models teach each other in one generation. (CVPR 2018)
Teacher 1
GT
Student 1
CE
CE
CE
Student 2
-
What if ... learn by myself in one generation? (???)
Model A
GT
Model A
Model A
GT
Model A1
Model B1
Model A2
Self-distillation

Dataset
Network
Block 1
Block 2
Block 3
y'
...
Bottleneck 2
feature 2
Logits 2
FC 2
L2-loss
KD Loss
y
CE Loss
Bottleneck 1
feature 1
Logits 1
FC 1
Bottleneck 3
feature 3
Logits 3
FC 3
Distilling from Features
Problems in logits matching
-
When the gap between two models is too large, student net may learn bad.
-
Model capacities are different.
-
Large
Model (i.e.
ResNet101)
Small
Model
Cannot distill well
TAKD - Improved KD via Teacher Assistant
-
Use a mid model to bridge the gap between teacher & student.
-
Or, maybe we should try distill from feature space?
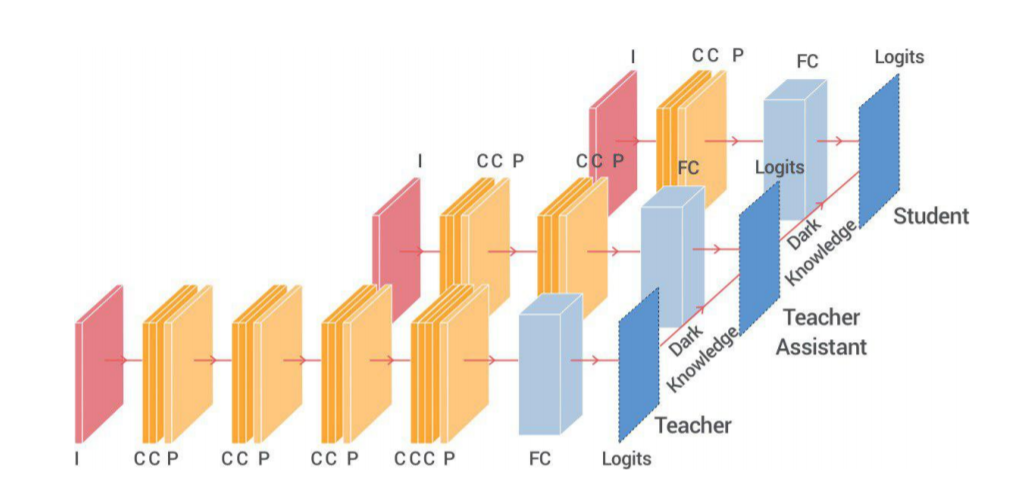
Problems in logits matching
-
When the gap between two models is too large, student net may learn bad.
-
Model capacities are different.
-
The path between X & Y is too far.
-
Large
Model (i.e.
ResNet101)
Small
Model
Cannot distill well

Teacher
ans: 0
next ans: 8


Only 1 loop
No end point
Student Model
FitNet - Distill from features
- FitNet is two-stages algorithm:
- Stage 1: pretrain the upper part of student net.
- Stage 2: Act like original KD (Baseline KD)
-
Problems: T's feat may too many trash.
- Knowledge should be compacted.
Teacher Net (U)
Dataset
Student Net (U)
Regressor


T's feat
S's feat
S's feat transform
L2
Loss
At - Distill from Attention
- Compress the feature to attention map.
Upper Model
Dataset
T's feat
Knowledge
Compression
(H, W, C)
(H, W, 1)

Distilling from distribution
Relational KD
-
Can we learn something among the batch?
-
Relational KD: Learn the structures from a batch of logits.
-
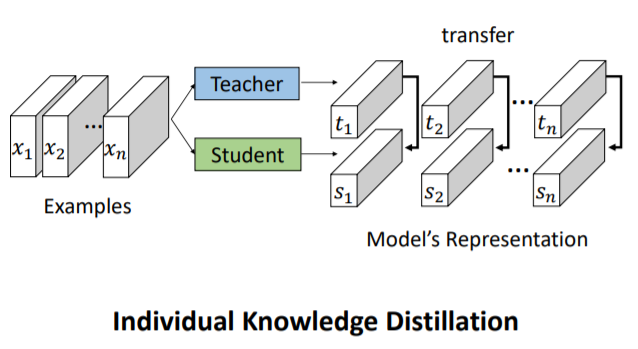
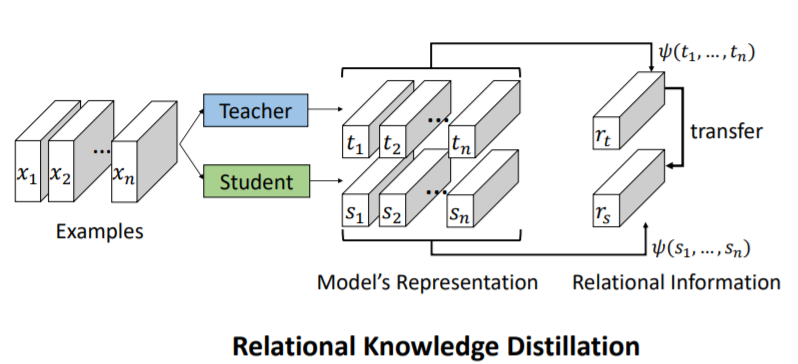
Individual KD:
Student learn Teacher's output
Relational KD:
Student learn model's representation
Relational KD
Distance-wise KD
t_1
t_2
t_3
t : teacher's logits
s : student's logits
s_1
s_2
s_3
~=
~=
Angle-wise KD
t_1
t_2
t_3
s_1
s_2
s_3
~=
Merge two types of loss.
Missing information
in KD
Cross-modal Distillation
-
Now you learned that KD is very helpful -- even you distill some little informative trash (?)
-
Cross-modal distillation can help!
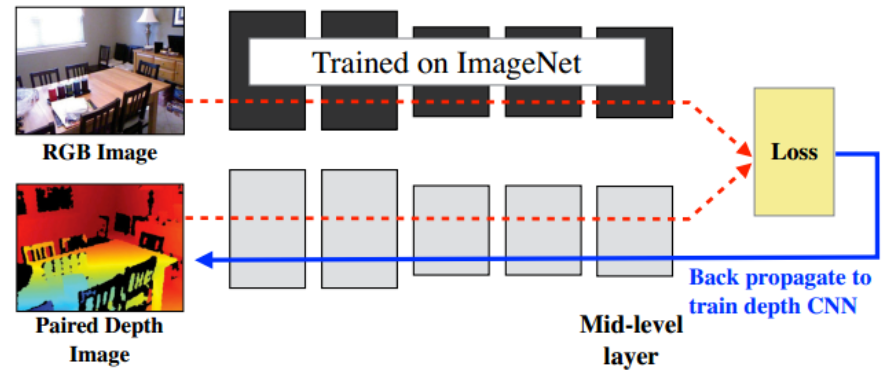
Problems in cross-modal
-
Student shouldn't blindly follow the teacher because teacher may also make some mistakes.
Video

NLP
Models
CV
Models
popcorn
cat
Distill what ???

images
*pop*
voices
Inheritance & Exploration KD
Teacher Net
Student Net
Student Net
(inheritance part)
SHOULD
similar
- Make student net split into two parts.
- inheritance loss: inheritance part should generate the feature that similar to teacher.
- exploration loss: exploration part should generate the feature that different to teacher.
Student Net
(exploration part)
SHOULD NOT
similar
Ending
Now S-T learning

Training Course - Knowledge Distillation
By Arvin Liu




