ESIR 2020 Mongo
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
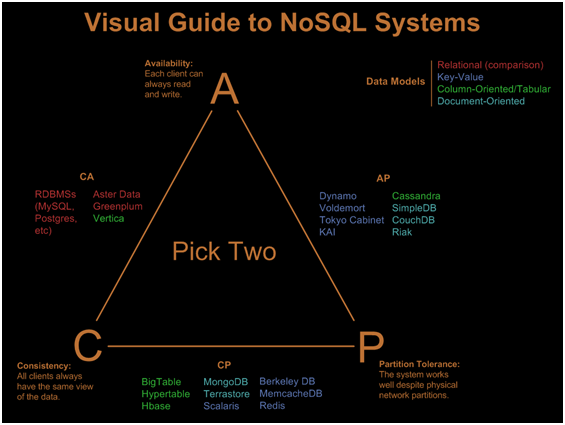
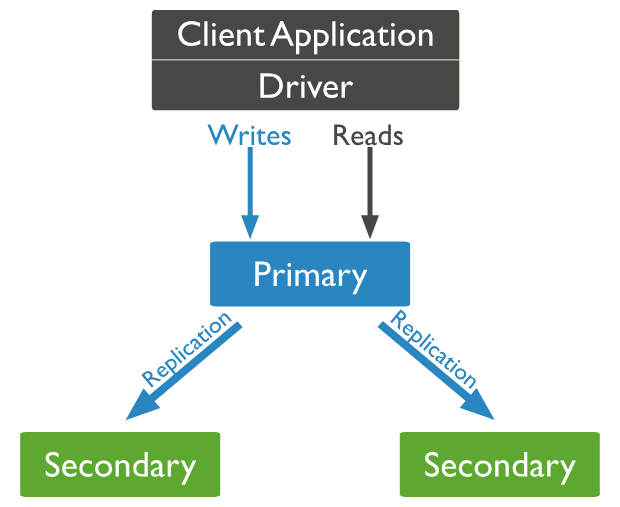
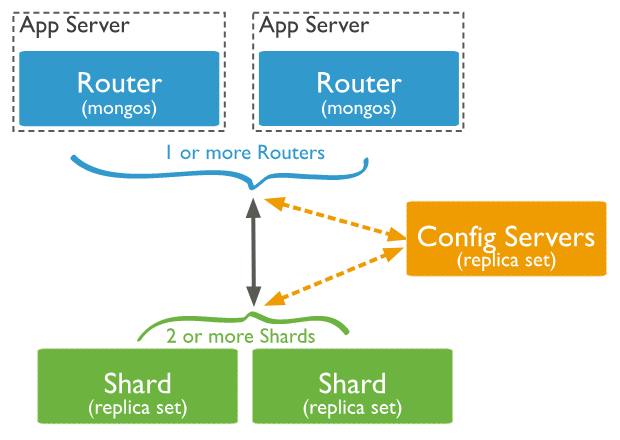
Base de données
En cas de panne de l'un des nœuds
la redondance assure la disponibilité des données
Répartition des documents
selon une de leur caractéristique
Document <=> objet JSON avec un champ "_id"
{
"_id" : ObjectId("5811bac48b0cf22ea39e16ec"),
...
}{
"_id" : "toto",
...
}{
"_id" : 42,
...
}Un UUID est
Un UUID est constitué de :
Version du générateur
503d6158-aa6d-490f-91dc-6659ea126fb2
time low
time med
time high
clock
node
Bibliothèque npm uuid
https://www.npmjs.com/package/uuid
$ npm install uuidSQL vs Mongo
{
_id: ObjectId("000280000000000000000042"),
...
}| Id | ... |
|---|---|
| 42 | ... |
table #28
mongo
on peut trouver une équivalence entre SQL et mongo
sql
INSERT INTO Tiers (First_Name, Last_Name)
VALUES ('John','Doe'); db.Tiers.insert(
{
First_Name: "John",
Last_Name : "Doe"
}
) SELECT *
FROM Tiers
WHERE First_Name = 'John'; db.Tiers.find(
{ First_Name: "John" }
){
"_id": ObjectId("58776b8643ab721e65d744ba"),
"First_Name": "John",
"Last_Name": "Doe"
} SELECT *
FROM Tiers
WHERE First_Name = 'John'; db.Tiers.findone(
{ First_Name: "John" }
){
"_id": ObjectId("58776b8643ab721e65d744ba"),
"First_Name": "John",
"Last_Name": "Doe"
} SELECT Last_Name
FROM Tiers
WHERE First_Name = 'John'; db.Tiers.find(
{ First_Name: "John" },
{ Last_Name: 1 }
){
"_id": ObjectId("58776b8643ab721e65d744ba"),
"Last_Name": "Doe"
} SELECT Tiers.Name
FROM Tiers
LEFT JOIN Address
ON Address.OwnerId = Tiers.ID
WHERE City REGEXP 'Saint.*'; db.Tiers.find(
{ "address.city": { $regex: /Saint.*/g } },
{ name: 1 }
){
"_id": ObjectId("58776b8643ab721e65d744ba"),
"name": "Tactilia"
}db.Tiers.find(
{ First_Name: { $in: ["John", "Jane"] } }
)
db.Equipments.find(
{ $or: [ { nextControlDate: "none" }, { nextControlDate: { $gt: new Date() } } ] }
)
db.Equipments.find(
{ nbSeats: { $exists: true } }
) UPDATE Tiers
SET First_Name = 'Jane'
WHERE Last_Name = 'Doe'; db.Tiers.update(
{ Last_Name: "Doe" },
{ $set: { First_Name: "Jane" } }
) db.Tiers.update(
{ Last_Name: "Doe" },
{ First_Name: "Jane" }
)db.Tiers.update(
{},
{ $rename: { First_Name: "firstName", Last_Name: "lastName" } },
{ multi: true }
)
db.Tiers.update(
{ "_id": ObjectId("58776b8643ab721e65d744ba") },
{ $push: { products: "configurateur" } },
{ upsert: true }
)
db.Scores.update(
{ "_id": ObjectId("55d744ba76b864387ab721e6") },
{
$push: { score: 42, game: "slot" },
$currentDate: { "last.play": true },
$set: { "last.result": "win" },
$inc: { credits: -1 }
}
) DELETE FROM Tiers
WHERE Last_Name = 'Doe'; db.Tiers.delete(
{ Last_Name: "Doe" }
){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468db.formData_582b2b5ae4b0a55f3d0f436f.aggregate( [
{ $match: {
mod_id: ObjectId("5840597be4b07592382acc4c"),
modVersion: 1,
submitDate: { $exists: 1 }
} } ] ){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468{
"result" : [
{
"_id" : ObjectId("58418252741d85f3df914805"),
"mod_id" : ObjectId("5840597be4b07592382acc4c"),
"modVersion" : 1,
"startDate" : ISODate("2016-12-02T14:06:49.758Z"),
"submitDate" : ISODate("2016-12-02T14:07:47.871Z"),
"data" : {
...
"CITY" : {
"date" : NumberLong(1480687625106),
"value" : {
"zip" : "35000",
"city" : "Rennes"
}
},
...
},
},
... x 1655
],
"ok" : 1
}db.formData_582b2b5ae4b0a55f3d0f436f.aggregate( [
{ $match: { ... } },
{ $project: { "data.CITY": 1 } }
] ){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468{
"result" : [
{
"_id" : ObjectId("58418252741d85f3df914805"),
"data" : {
"CITY" : {
"date" : NumberLong(1480687625106),
"value" : {
"zip" : "35000",
"city" : "Rennes"
}
}
}
},
... x 1655
],
"ok" : 1
}db.formData_582b2b5ae4b0a55f3d0f436f.aggregate( [
{ $match: { ... } },
{ $project: { "data.CITY": 1 } },
{ $group: { _id: "$data.CITY.value.city", count: { $sum:1 } } }
] ){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468{
"result" : [
{
"_id" : "Bourges",
"count" : 12
},
{
"_id" : "Angers",
"count" : 2
},
... x 1655
],
"ok" : 1
}db.formData_582b2b5ae4b0a55f3d0f436f.aggregate( [
{ $match: { ... } },
{ $project: { "data.CITY": 1 } },
{ $group: { _id: "$data.CITY.value.city", count: { $sum:1 } } },
{ $sort: { "count" : -1 } }
] ){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468{
"result" : [
{
"_id" : "Vannes",
"count" : 707
},
{
"_id" : "Theix",
"count" : 89
},
... x 1655
],
"ok" : 1
}
db.formData_582b2b5ae4b0a55f3d0f436f.aggregate( [
{ $match: { ... } },
{ $project: { "data.CITY": 1 } },
{ $group: { _id: "$data.CITY.value.city", count: { $sum:1 } } },
{ $sort: { "count" : -1 } },
{ $limit: 3 }
] ){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468{
"result" : [
{
"_id" : "Vannes",
"count" : 707
},
{
"_id" : "Theix",
"count" : 89
},
{
"_id" : "Saint-Avé",
"count" : 67
}
],
"ok" : 1
}On peut y mettre n'importe quel JSON (max 16Mo)
=> mongo n'impose aucun schéma
=> c'est à l'utilisateur (programme appelant) de gérer
Du coup on peut avoir plusieurs types d'objets qui cohabitent dans la même collection !
{
"name": "Voiture",
"plate": "AR-456-YI",
"nextControlDate": ISODate("2017-10-01T00:00:00.000Z"),
"nbSeats": 5
}
{
"name": "Camion",
"plate": "AD-123-PS",
"nextControlDate": "none",
"capacity": 20
}
on ajoute un champ "_type" ou "_class"
=> on sait quel type on manipule
=> si absent = type générique de la collection
{
"_type": "car",
"name": "Voiture",
"plate": "AR-456-YI",
"nextControlDate": ISODate("2017-10-01T...Z"),
"nbSeats": 5
}
{
"_type": "truck",
"name": "Camion",
"plate": "AD-123-PS",
"nextControlDate": "none",
"capacity": 20
}
Pourtant l’agrégation et l'association sont des concepts de base des relations entre objets
Mais on peut avoir des objets composés
{
_id: "564f36c87dcbd96cf6f3e2ea",
name: "Tactilia",
address: {
city: "Saint Grégoire"
...
},
products: [
"fidbe", ...
],
...
}
Mais on peut mettre des références vers un objet
{
_id: "564f36c87dcbd96cf6f3e2ea",
name: "Tactilia",
employees: [
"/employees/564f36c87dcbd07cf6f3e2ea",
...
],
logo: "564f36c87dcbd97cf6f3e2ea",
...
}
L'aggrégation est à
gérer à la main
{
_id: "5b50f8968656472a58970167",
password: "xxx",
userId: "bchanclo",
??? lien vers le tiers ???
}{
_id: "5b50f8968656472a58970167",
firstname: "Benoît",
lastname: "Chanclou",
birthdate: ...
}Account
Tiers
Exemple un compte d'accès en lien avec un tiers
{
_id: "5b50f8968656472a58970167",
password: "xxx",
userId: "bchanclo",
user: "564f36c87dcbd97cf6f3e2ea",
}
GET http://api.myapp.com/tiers/1/contacts/564f36c87dcbd97cf6f3e2eadb.tiers.findOne({_id: "564f36c87dcbd97cf6f3e2ea"}){
user: "http://api.myapp.com/tiers/1/contacts/564f36c87dcbd97cf6f3e2ea",
}
{
user: {
type: "Tiers",
id: "564f36c87dcbd97cf6f3e2ea"
},
}
Trouver des livraisons dont le livreur est prénommé "John"
{
...
"deliveryMan": xxx,
...
}{
"_id": xxx,
"firstname": "John",
"lastname": "Doe",
"phone": "+33123456789",
...
}db.Deliveries.find(
{ deliveryMan: xxx }
)db.Tiers.find(
{ firstname: "John" }
)Tiers
Deliveries
{
...
"deliveryMan": xxx,
...
}{
"_id": xxx,
"firstname": "John",
"lastname": "Doe",
"phone": "+33123456789",
...
}{
...,
"deliveryMan": {
"_id": xxx,
"firstname": "John",
"lastname": "Doe",
"phone": "+33123456789"
},
...
}db.Deliveries.find(
{ deliveryMan.firstname: "John" }
)Tiers
Deliveries
Deliveries
{
"contact": {
"_id": xxx,
"firstname": "John",
"lastname": "Doe",
"phone": "+33123456789"
},
}
+ Accès rapide
+ Recherches possible sur les champs mis en cache
+ Lazy loading de la ressource référencée
- Gérer le cycle de vie du cache :
- Invalidation
- Mise à jour
ou
=>Ajout d'un champ _archive: true
find({
...,
$or: [ { _archive: { $exists: false } }, { _archive: false } ]
})find({
...,
_archive: true
})ou
ou
ou
ou
ou
ou
ou
ou
{
"addressStreet": "rue d'Alembert",
"addressZipCode": "35000",
"addressCityName": "Rennes",
...
}{
"_version": 1
"address": {
"street": "rue de Gauss",
"zipCode": "56230",
"cityName": "Questembert"
},
...
}{
"_version": 2
"address": {
"street": "rue du Rennes",
"city" : {
"zipCode": "35700",
"name": "Saint Malo"
}
},
...
}var CONVERTERS = [
obj => {
obj.address = {
street: obj.addressStreet,
zipCode: obj.addressZipCode,
cityName: obj.addressCityName
};
delete obj.addressStreet;
delete obj.addressZipCode;
delete obj.addressCityName;
obj._version = 1;
},
obj => {
obj.address.city = {
zipCode: obj.address.zipCode,
name: obj.address.cityName
};
delete obj.address.zipCode;
delete obj.address.cityName;
obj._version = 2;
}
];
while (obj._version < CONVERTERS.length) {
CONVERTERS[obj._version](obj);
}+ on ne manipule que des objets au dernier format
+ on n'est pas obligé de mettre toute la collection à jour
+ pas de migration =
- recherche complexifiées
- il faut rechercher dans toutes les versions
utile dans une grosse base où peu d'objets sont utilisés
(ex.: liste de commandes clients, au quotidien on ne manipule que les plus récentes)
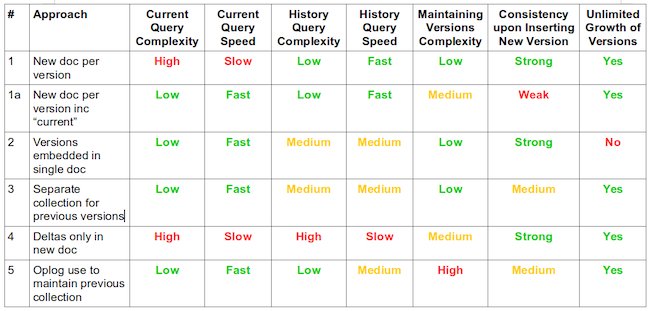
Un document par version
{ "docId" : 174, "rev" : 1, "attr1": 165 } /* version 1 */
{ "docId" : 174, "rev" : 2, "attr1": 165, "attr2": "A-1" }
{ "docId" : 174, "rev" : 3, "attr1": 184, "attr2": "A-1" }db.docs.find({ "docId": 174 }).sort({ "rev": -1 }).limit(-1);findone
db.docs.aggregate( [
{ "$sort": { "docId" : 1, "rev" : -1 } },
{ "$group" : { "_id" : "$docId",
"doc": { "$first" : "$$ROOT" }
} },
{ "$match": { "doc.attr1": 184 } }
] );find
Un document par version avec current
{ "docId" : 174, "v" : 1, "attr1": 165 }
{ "docId" : 174, "v" : 2, "attr1": 165, "attr2": "A-1" }
{ "docId" : 174, "v" : 3, "attr1": 184, "attr2": "A-1", "current": true }db.docs.findOne({ "docId": 174, "current": true }));findone
db.docs.find({ "doc.attr1": 184, "current": true }));find
un seul document contenant toutes les versions
{
"docId" : 174,
"current" : { "attr1": 184, "attr2": "A-1" },
"prev": [ { "attr1": 165 }, { "attr1": 165, "attr2": "A-1" } ]
}db.CurrentCollection.findone({ "docId": 174 }, { current: 1 });findone
db.CurrentCollection.find(
{ "current.attr1": 184 },
{ current: 1 }
);find
Deux collections
CurrentCollection:
{ "docId" : 174, "rev": 3, "attr1": 184, "attr2": "A-1" }
PreviousCollection:
{ "docId" : 174, "rev": 1, "attr1": 165 }
{ "docId" : 174, "rev": 2, "attr1": 165, "attr2": "A-1" }
{ "docId" : 174, "rev": 3, "attr1": 184, "attr2": "A-1" }db.CurrentCollection.findone({ "docId": 174 });findone
db.CurrentCollection.find({ "attr1": 184 });find
Un document par version mais on stocke les deltas
sous forme de JSONPatch
{ "_id": ..., "id": 174, "userId": "xxx", "date": ISODate(...), patch: [
{ "op": "add", "path": "/attr1", "value": 165 }
] }
{ "_id": ..., "id": 174, "userId": "yyy", "date": ISODate(...), patch: [
{"op": "add", "path": "/attr2", "value": "A-1" }
] }
{ "_id": ..., "id": 174, "userId": "zzz", "date": ISODate(...), patch: [
{ "op": "replace", "path": "/attr1", "value": 184 }
] }find
Compliqué on doit procéder en deux étapes
db.docs.aggregate( [
{ $match: { id: "174" } }, // recherche tous les patches sur l'entité
{ $sort: { "date" : 1 } }, // trie les résultats par date
{ $unwind : "$patch" }, // aplati tous les patchs
{ $group: { _id: "$id", patch: { $push:"$patch" } } }
// regroupe tous les patchs en un tableau
] );findone
Deux collections
SnapshotCollection:
{ "id" : 174, "v": 3, "attr1": 184, "attr2": "A-1" }
PatchCollection:
{ "_id": ..., "id": 174, "userId": "xxx", "date": ISODate(...), patch: [...] }
{ "_id": ..., "id": 174, "userId": "yyy", "date": ISODate(...), patch: [...] }
{ "_id": ..., "id": 174, "userId": "zzz", "date": ISODate(...), patch: [...] }db.SnapshotCollection.findone({ "docId": 174 });findone
db.SnapshotCollection.find({ "attr1": 184 });find
oplog
Le but est d'utiliser les logs de mongo pour gérer l'historique des versions du document (voir ce blog)
Une structure de recherche
db.xxx.createIndex( <key & index type specification>, <options> )db.data_564f36c87dcbd97cf6f3e2ea.find()db.data.find({ownerId: "564f36c87dcbd97cf6f3e2ea"}){
...,
ownerId: "564f36c87dcbd97cf6f3e2ea",
...
}certains frameworks savent gérer ce type de références
(au sein d'une même application, même db)