初探深度學習
Deep Learning Intro

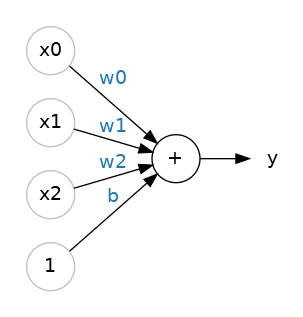
神經元
Neuron

x 是輸入(input)
w是權重(weight)
b是偏差(bias)
這個線性單位(linear unit)的表示方法就是
線性單位
這個線性單位(linear unit)的表示方法就是
更多輸入的線性單位
怎麼用程式來表示

Keras裡的線性單元
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(units=1, input_shape=[3])
])神經網路
Deep Neural Network
什麼是神經網路
訓練神經網路
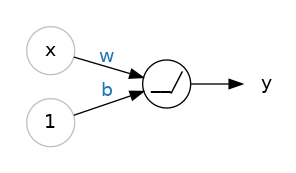
激勵函數
Activation Function
為什麼需要激勵函數
讓神經網路可以不再只有線性關係
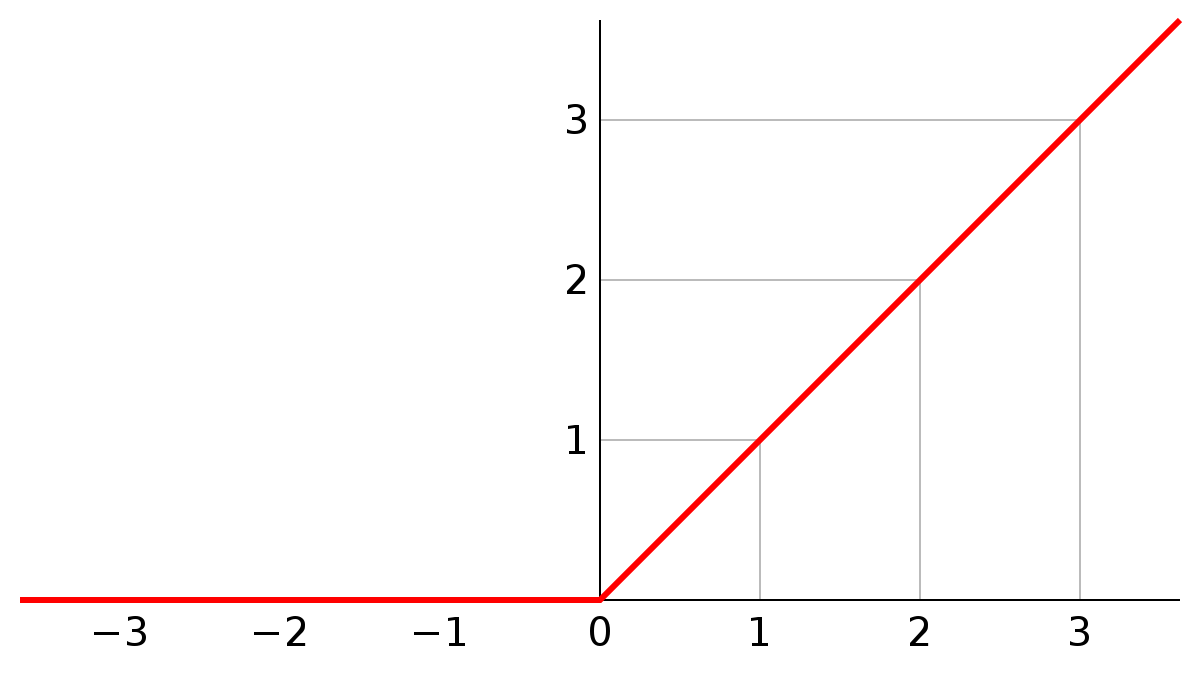
激勵函數 - Relu
激勵函數要用在哪
激勵函數 - sigmoid
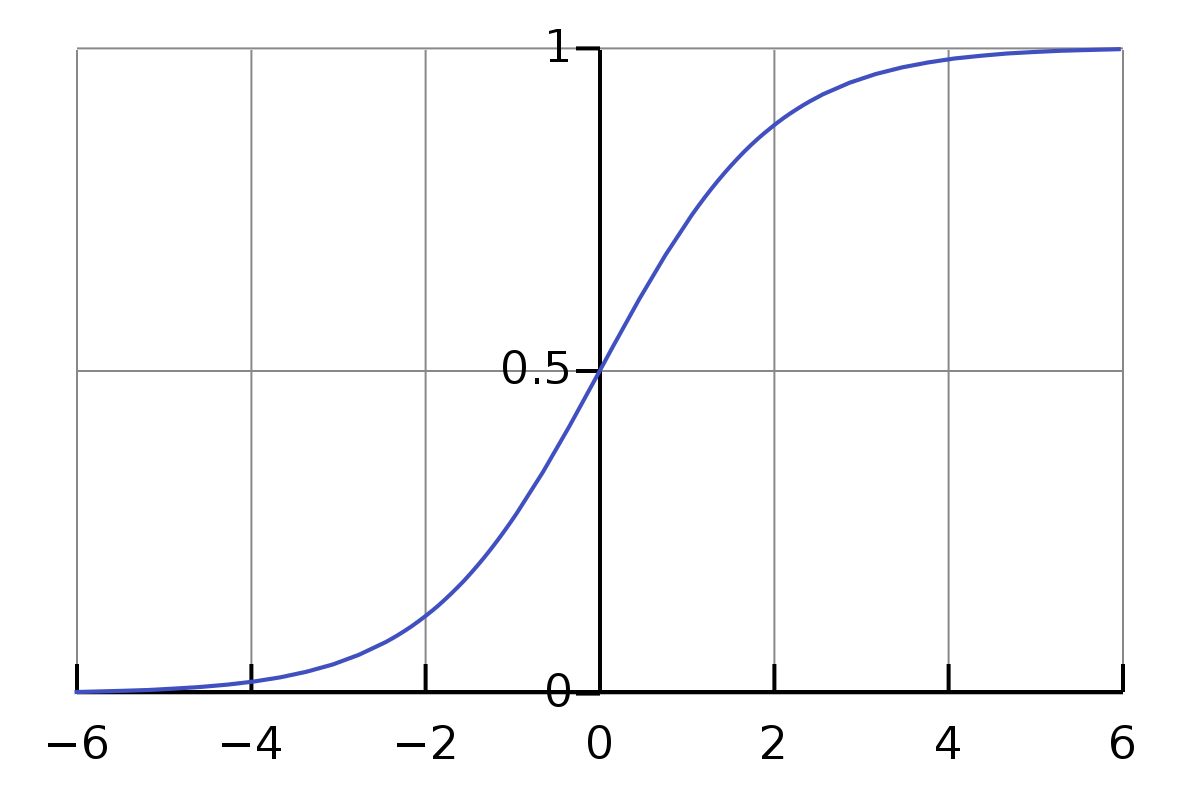
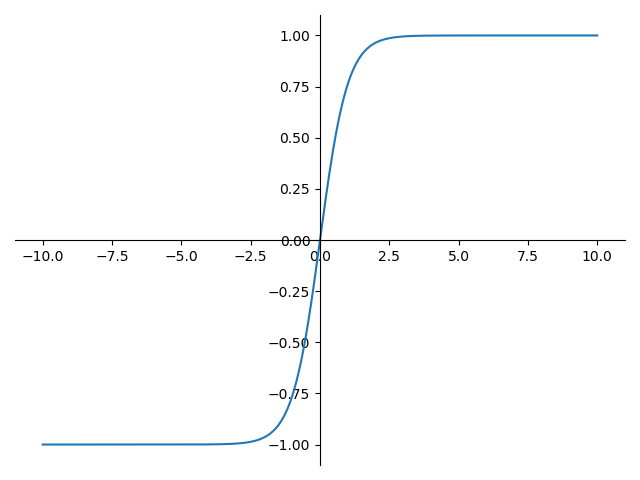
激勵函數 - tanh
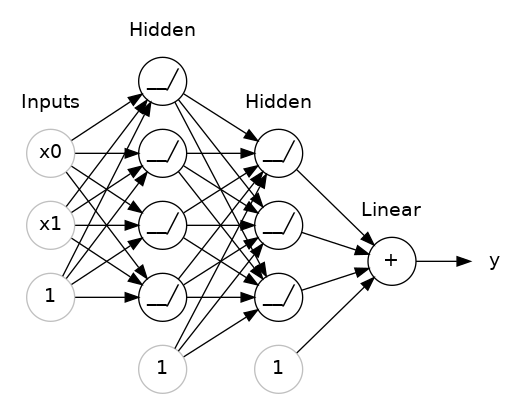
多層神經網路
可以進行複雜的數據轉換
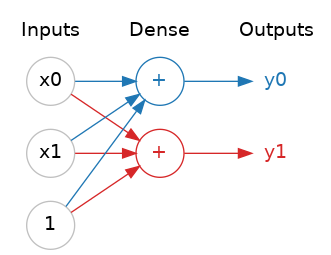
順序式模型
Sequential Models
定義
簡單的模型,單一輸入、單一輸出,按順序一層(Dense)一層的由上往下執行。
建立順序式模型
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(units=4, activation='relu', input_shape=[2]),
layers.Dense(units=3, activation='relu'),
layers.Dense(units=1),
])訓練深度學習模型
Training Deep Learning Model
需要做的事情
- 損失函數 (loss function) 測量模型準確程度
- 優化器 (optimizer) 修正模型
損失函數
Loss Function
平均絕對誤差(MAE)
將預測值跟實際值的差取平均
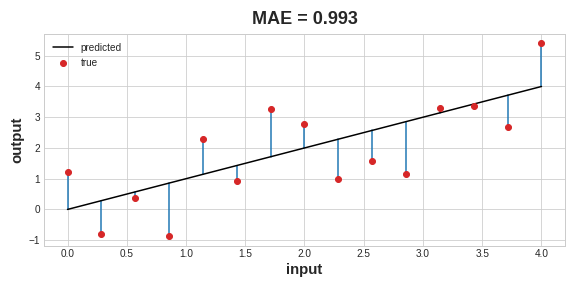
均方誤差(MSE)
將預測值跟實際值的差平方再取平均
反向傳播
Backpropagation
計算梯度
我們只知道結果,並不知道中間的隱藏層(hidden layer)的權重(weight)對Loss的梯度,所以才要利用反向傳播搭配損失函數(loss function)來計算梯度(gradient)
運作方式
不斷地連鎖律、不斷地偏微分
要講微積分要講太久了
我們先著重在如何使用上
優化器
Optimizer
優化器做的事情
調整權重來讓損失(Loss)最小
隨機梯度下降
Stochastic Gradient Descent
每次選出其中的一些樣本(minibatch)來計算梯度並更新權重(weight)
使用方式
model.compile(
optimizer="adam",
loss="mae",
)梯度下降演算法
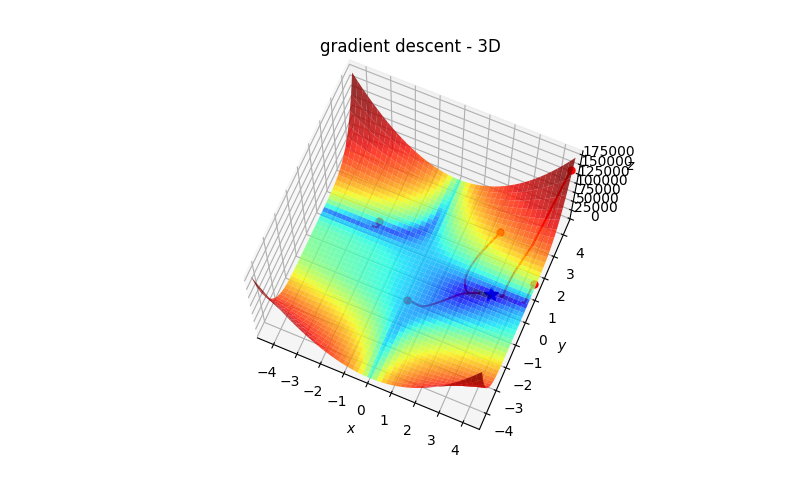
Gradient Descent
原理
梯度的方向是走向局部最大的方向,所以在梯度下降法中是往梯度的反方向走,就可以走到局部最小值。
梯度算法-微分
微分
梯度下降
Gradient Descent
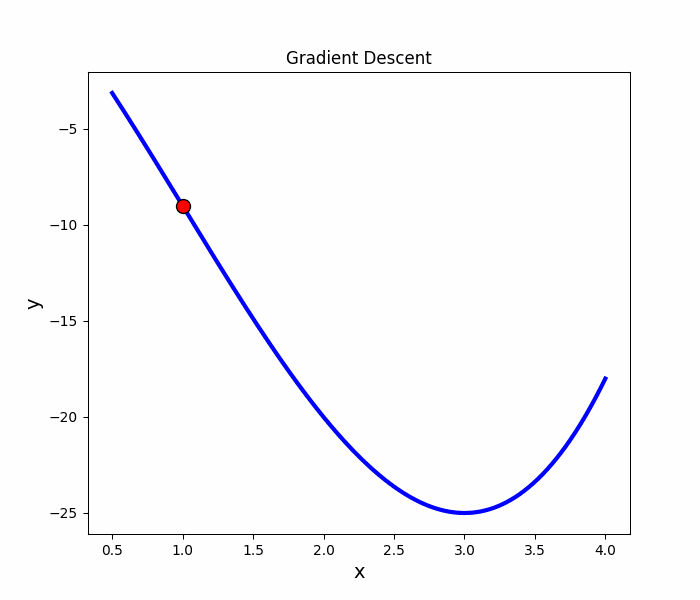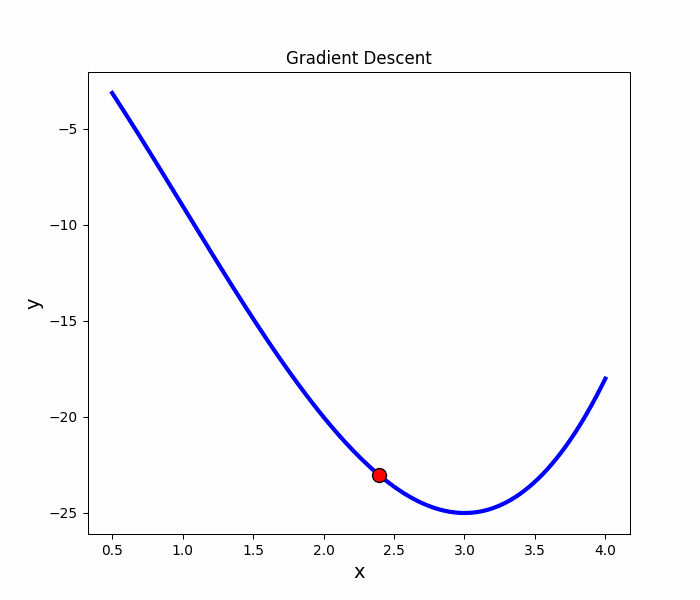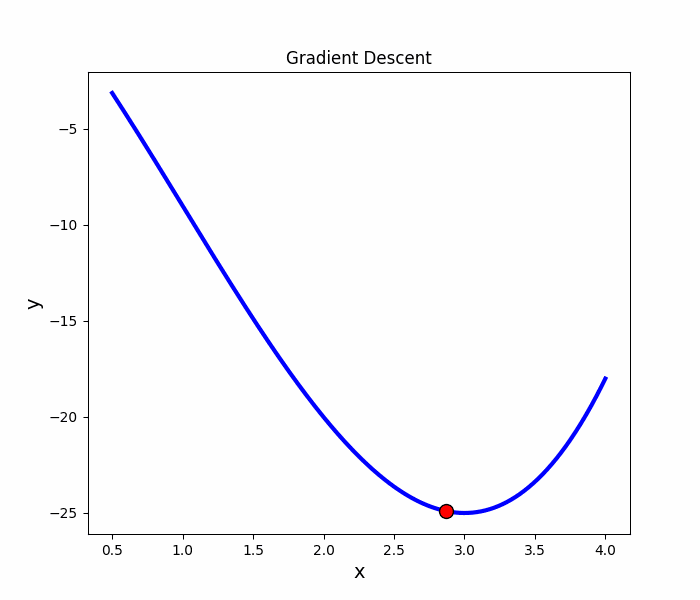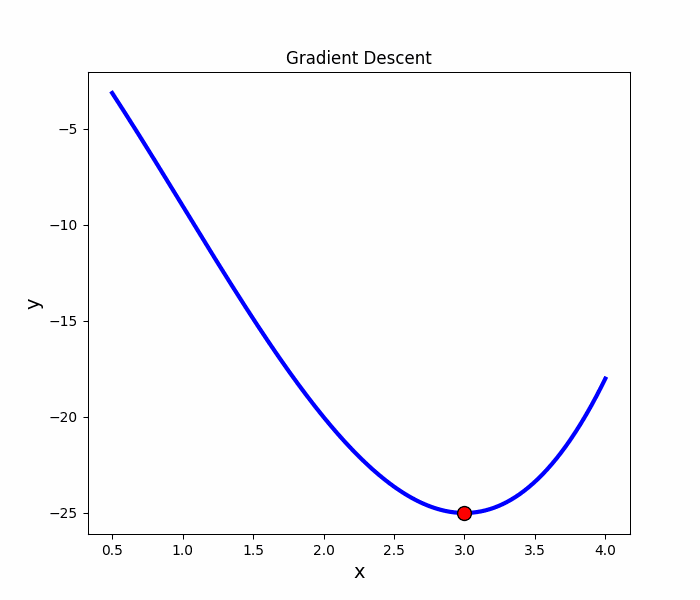
梯度下降
Gradient Descent
Momentum
就像是丟一顆球到碗裡,球會在碗內左右振盪,隨著阻力的慢慢趨向最低點
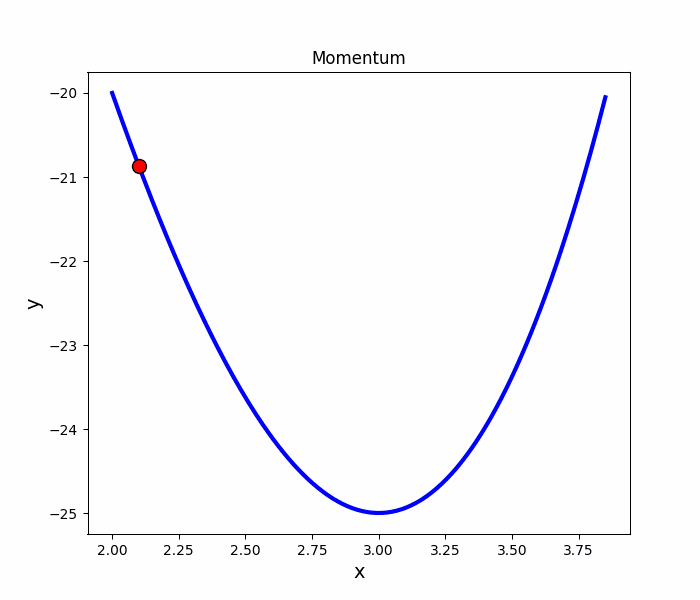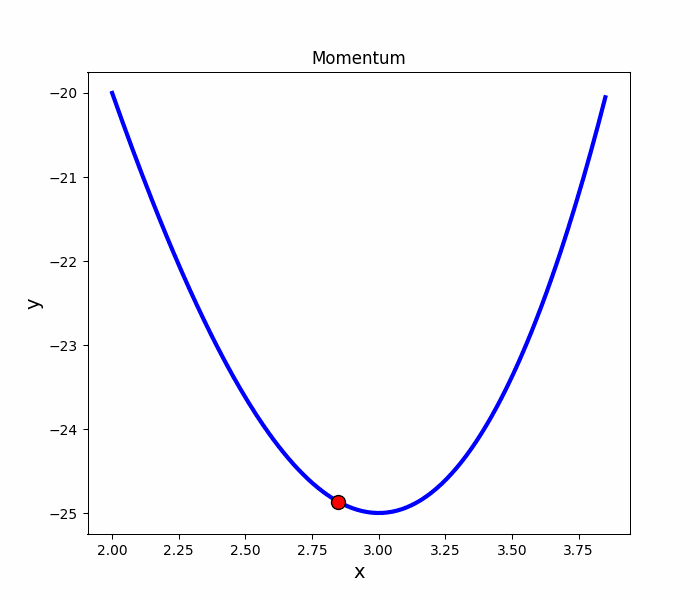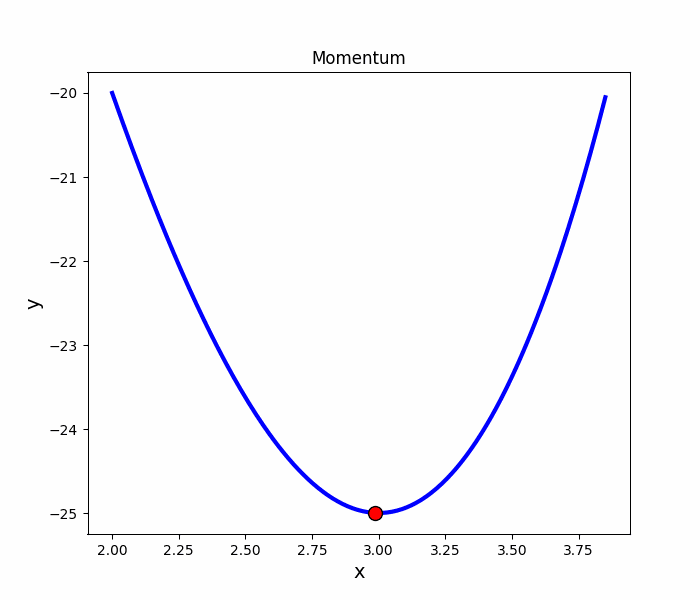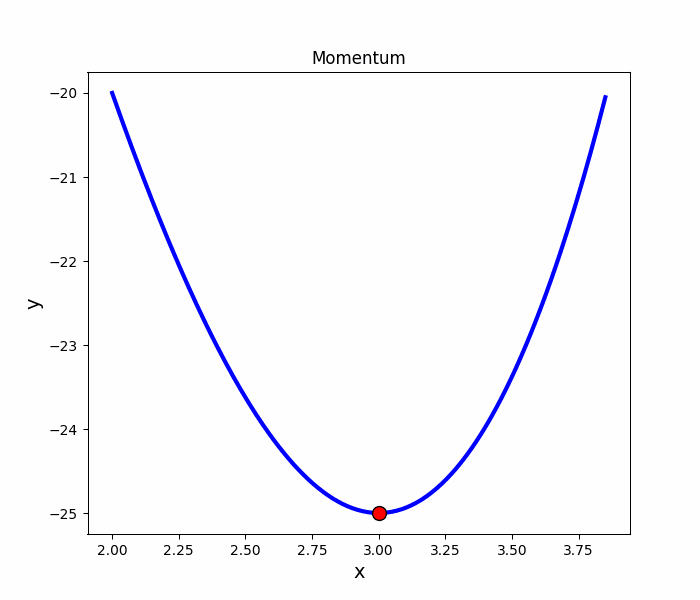
跟SGD比較
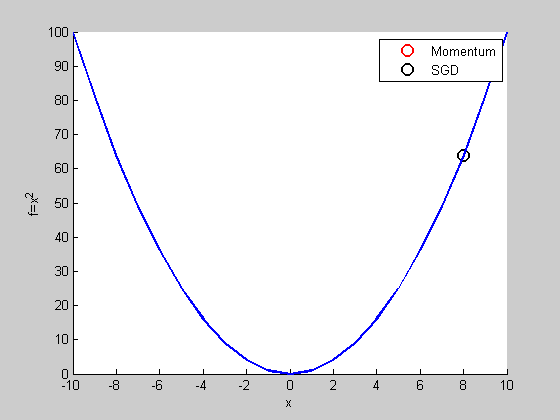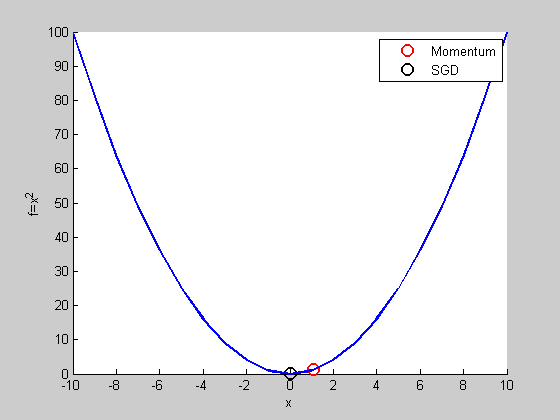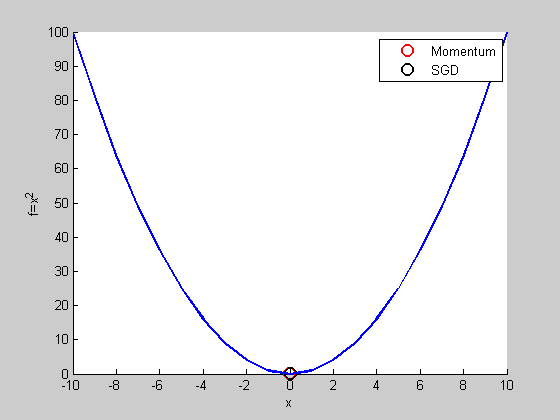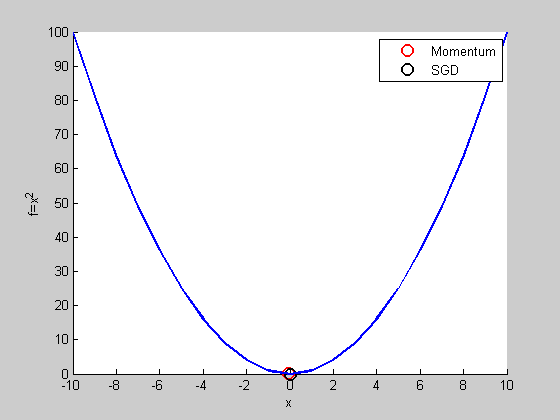
看起來Momentum比較慢?
用比較複雜的函數
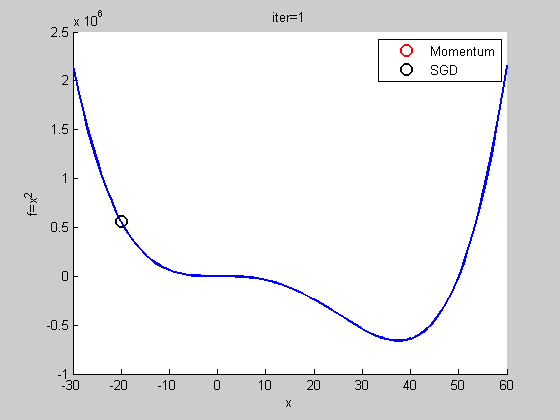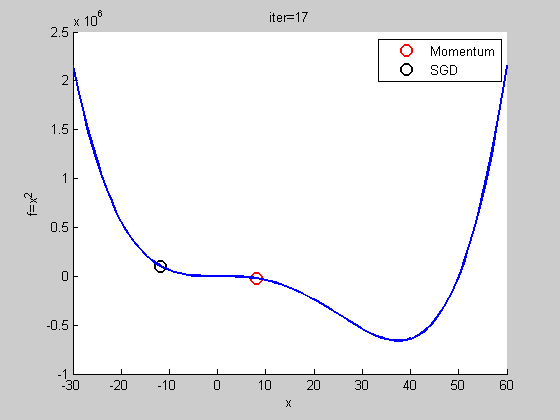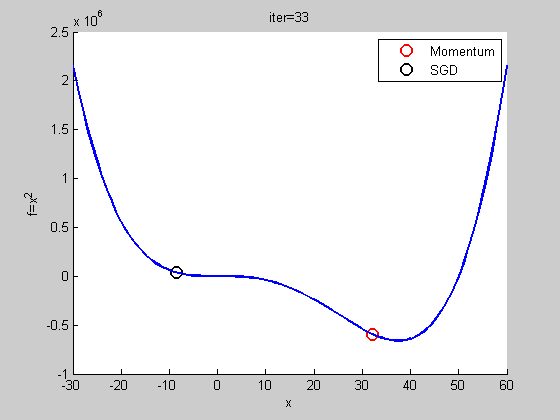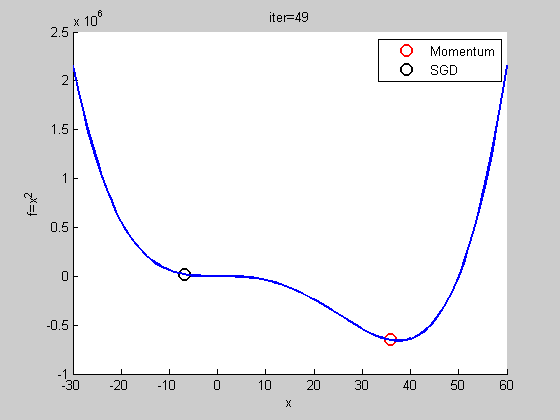
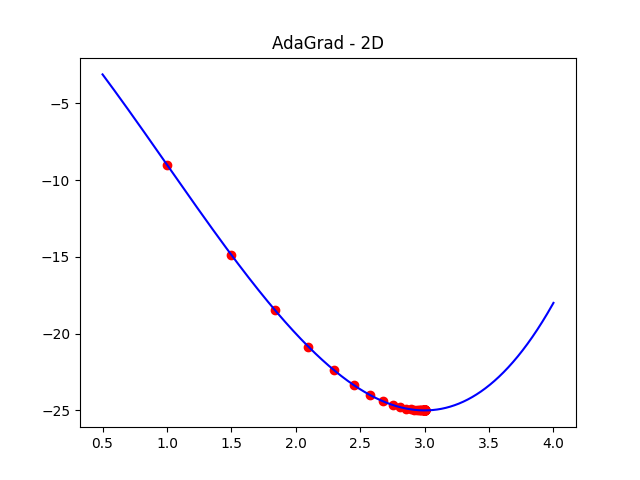
自我調整梯度
對每個梯度分量除以該梯度的歷史累加值
AdaGrad
Adam 法
跟Momentum很像,但多了摩擦力
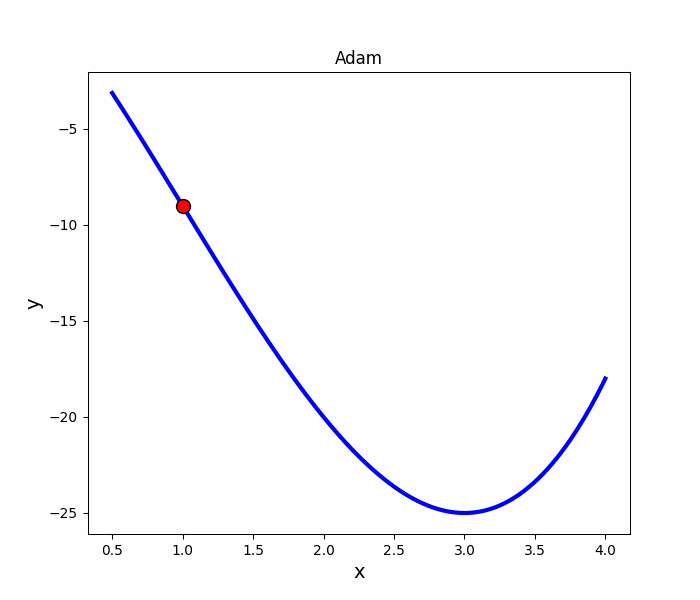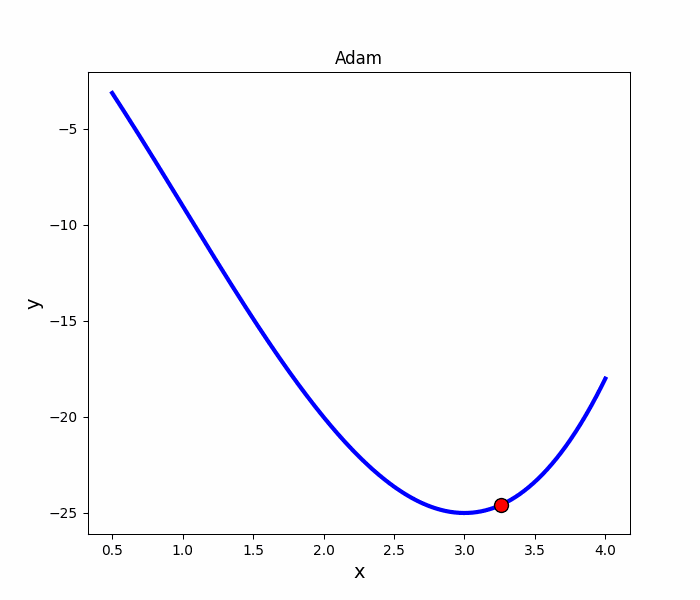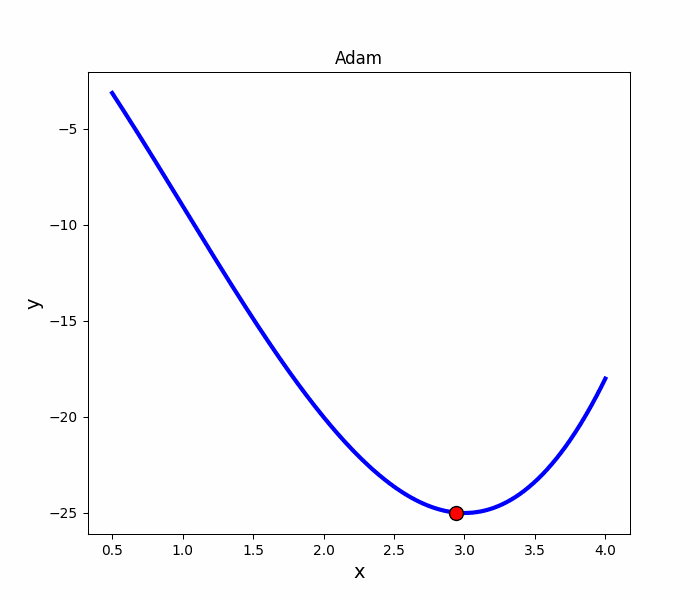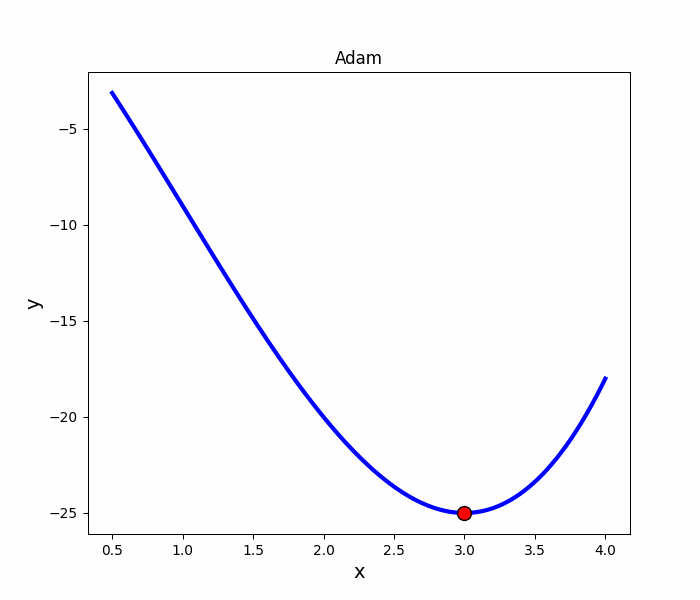
其他梯度下降演算法
- AdaDelta
- RMSprop
實作 - 紅酒品質
Implement - Red Wine Quality
讀取資料
import pandas as pd
red_wine = pd.read_csv('winequality-red.csv')分割驗證資料
import pandas as pd
red_wine = pd.read_csv('winequality-red.csv')
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)標準化
Normalization
標準化
Normalization
import pandas as pd
red_wine = pd.read_csv('winequality-red.csv')
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)分割特徵和結果
import pandas as pd
red_wine = pd.read_csv('winequality-red.csv')
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']建立模型
from tensorflow import keras
from keras import layers
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])損失函數跟優化器
from tensorflow import keras
from keras import layers
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)訓練模型
from tensorflow import keras
from keras import layers
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=10,
)把loss畫成折線圖
import matplotlib.pyplot as plt
history_df = pd.DataFrame(history.history)
plt.plot(history_df['loss'])
plt.show()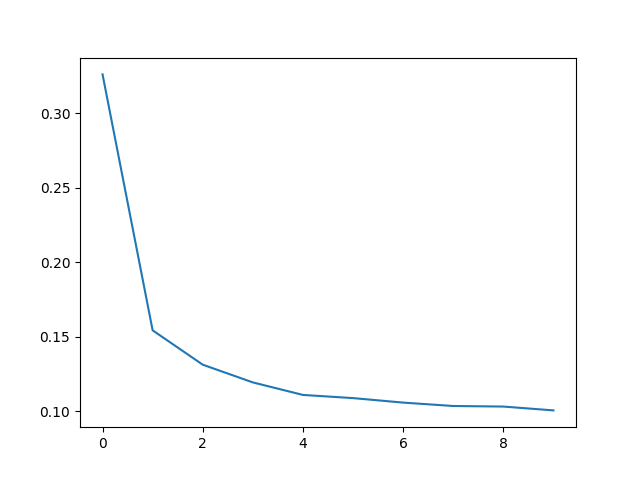
過適&乏適
Overfitting & Underfitting
學習曲線
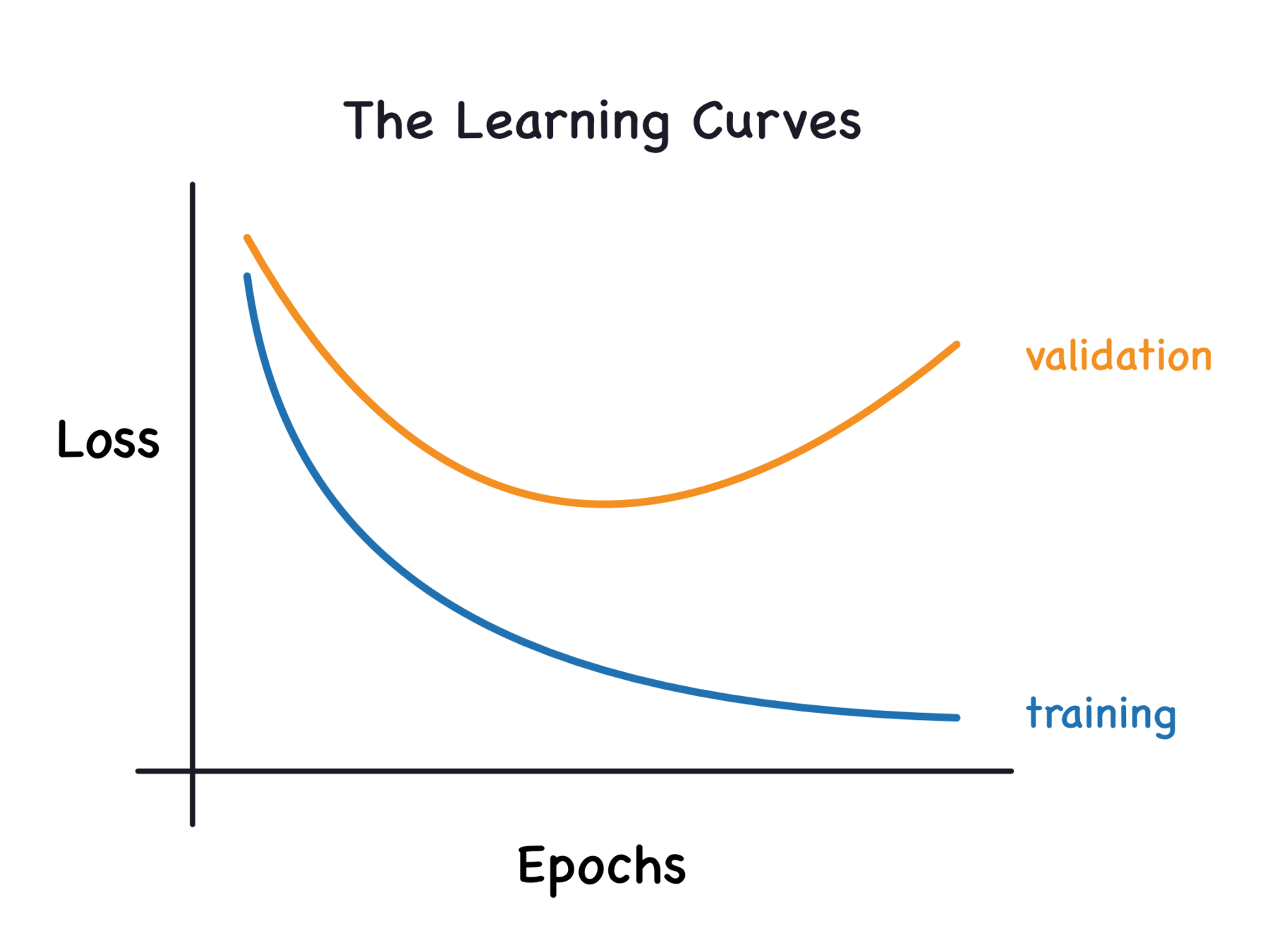
用函數來類比
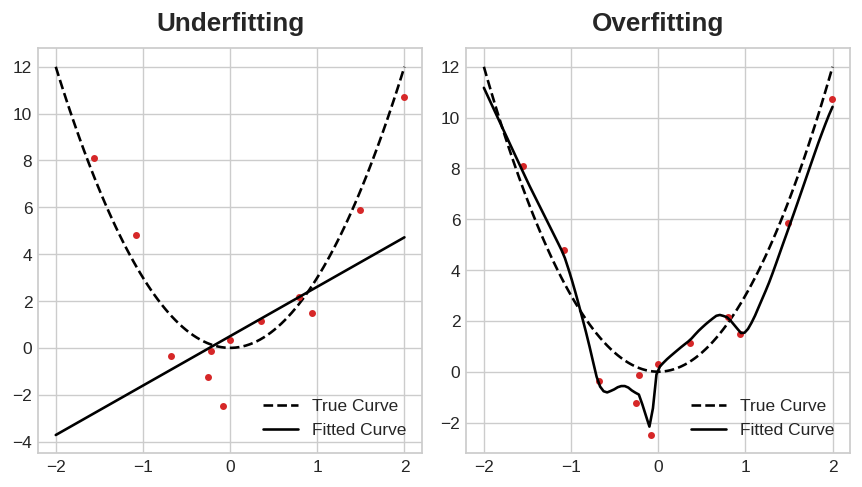
解決辦法
- 改變模型容量(Model Capacity)
- 提前停止(Early Stopping)
- Dropout
- Batch Normalization
改變模型容量
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(1),
])怎麼改變?
把模型變更寬
增加每層中神經元的數量
wider = keras.Sequential([
layers.Dense(32, activation='relu'),
layers.Dense(1),
])把模型變更深
更多層
deeper = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1),
])提前停止
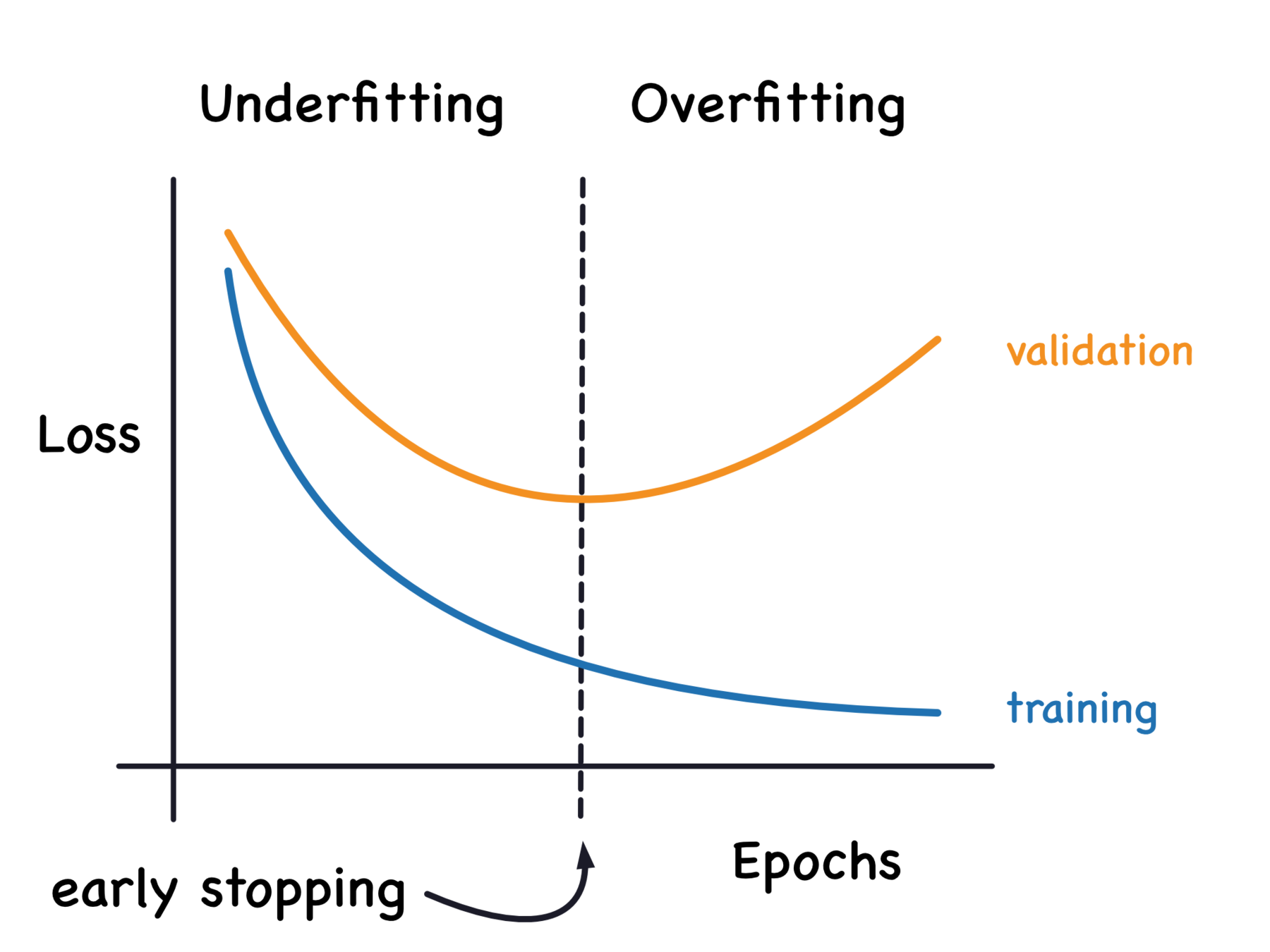
當損失(loss)開始回升時,就停止並往前找最小值
實作方式
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
min_delta=0.001,
patience=20,
restore_best_weights=True,
)在訓練模型時使用
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=500,
callbacks=[early_stopping],
)Dropout
在每一個 epoch 都隨機選擇一批單元,不讓他們進行前向推理和後向傳播
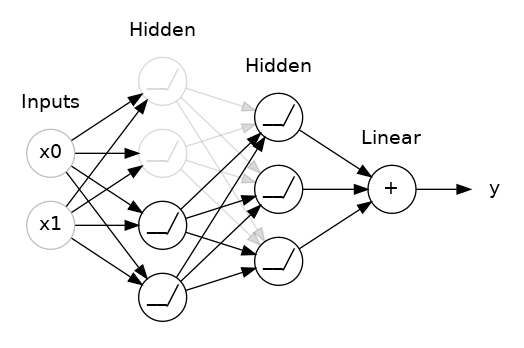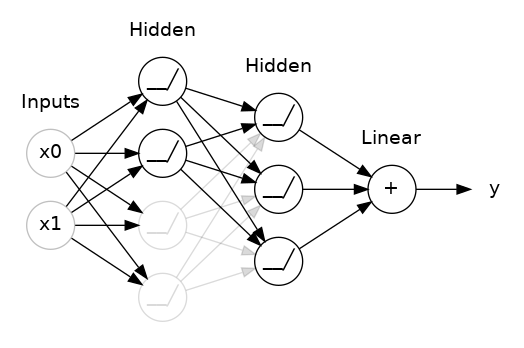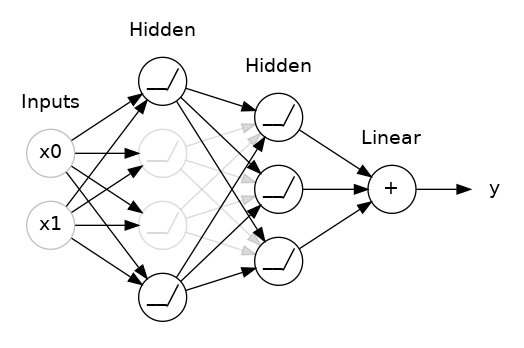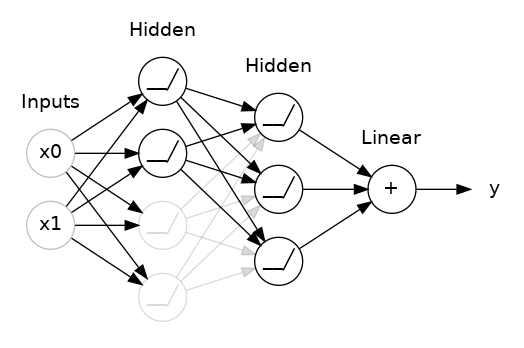
為甚麼要用dropout
每次訓練迭代時,隨機選擇一批單元不參與訓練,這使得每個單元不會依賴於特定的單元,因此具有一定的獨立性,可以防止過適
在模型加入dropout
keras.Sequential([
# ...
layers.Dropout(rate=0.3),
layers.Dense(16),
# ...
])Batch Normalization
以 mini-batch 為單位,依照各個 mini-batch 來進行正規化
可以放在一層後
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),也可以放在一層中間
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),二元分類器
Binary Classification
二元分類
只有兩種答案
ex.是或否, 狗或貓, True或False
loss function
我們希望得到機率之間的距離,因此選用
交叉熵(Cross-Entropy)
交叉熵
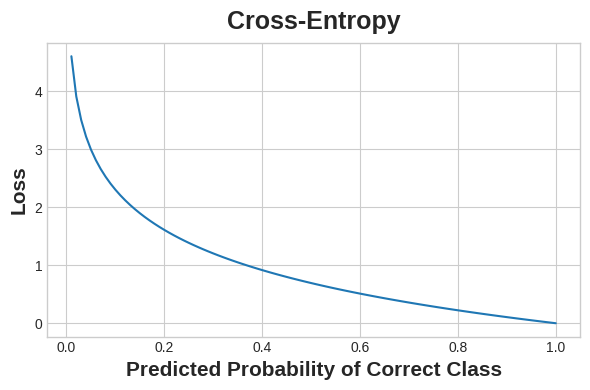
把數值轉換為機率
用Sigmoid把數據轉換為零到一之間的數字
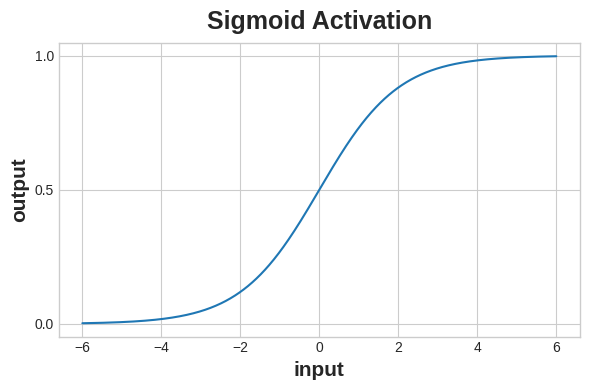
使用方法
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)