Transformers Lunch & Learn
Part 1: Background and The Transformer
Hamish Dickson - Oct 2024
Over the next 3 weeks
Some code
Basically theory
Prompts n shit
Question: How would you Approach translation?
What's the German for cake?
Was heißt auf Deutsch Kuchen?
???
Question: How would you Approach translation?
What's the German for cake?
Was heißt auf Deutsch Kuchen?
???
First attempts were ngram-to-ngram translations
What's the German for cake?
Was heißt auf Deutsch Kuchen?
This doesn't work well for lots of reasons, even if you could build these mappings you lack context
Question: How would you Approach translation?
What's the German for cake?
Was heißt auf Deutsch Kuchen?
???
Google Translate famously used seq2seq in 2014
Idea is
- have a model "roll over" the input text in order
- build up a representation of the text as we go
- "unroll" using a second model to a new language
- new output model for each language
i.e. GenAI
Question: How would you Approach translation?
inputs
outputs
Encoder
Decoder
This thing is really useful
Question: How would you Approach translation?
Missing piece: encoding/decoding text
Question: how do we go from words to something a ML model can use?
Our models use tensors, how do we turn words into tensors?
Until 2017 we mostly used w2v and glove, idea is:
- train a model so that when words are similar they are close in a vector space, different either perpendicular or in the opposite direction from the origin
- use this as a lookup at the beginning
- lots of preprocessing to crowbar our sentence into a pretrained model
Missing piece: encoding/decoding text
So does it work?
YES! Very well
This is how Google Translate worked for about 4 years (although with tricks, bidirectional models and stacking)
But there are some issues
- note we have encoded this sequential bias into how we teach the model
- this bias helps us learn fast (we have told the model part the answer) but also it's not quite how language works
- this is very very hard to scale up
- w2v is similar, but worse, it's a whole other network
important modelling trick
So does it work?
Note, if you have a problem where:
- You have some sequential problem
- You don't have BUCKETS of similar data to pretrain with
- You want something fast (these go as O(N))
An RNN can still easily beat a transformer
Why do we care about all of this?
There is a huge problem with this design, it doesn't scale
- Remember we roll over each word, one at a time
- it's hard to imagine scaling this over multiple machines
- one machine means it takes a very long time to train a model
This isn't completely true, there are tricks around this
Question: why would we want "to scale"?
Pretraining for fine tuning
Attention is all you Need
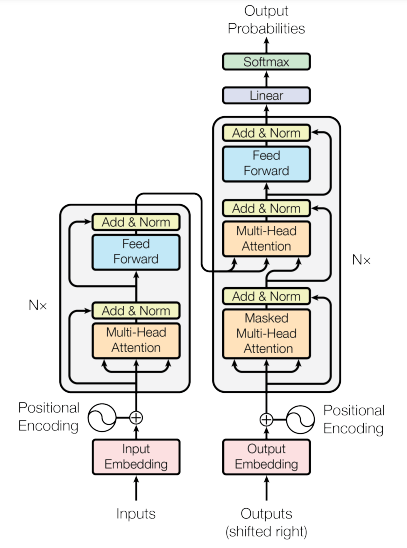
- Google Brain paper from 2017
- Honestly, the paper is underwhelming
- Paper was an obscure translation paper (English to German)
- Cool fact: they did this diagram in Google Slides
Attention is all you Need
Introduced lots of ideas
- Ditch w2v, instead "tokenise" the input text (basically an ordinal encoding)
- At the same time as training the rest of the model train the token -> vector encoding
- Ditch the sequential encoding (ie the "rolling over/out")
- Instead we provide the whole sequence at once, this is super important
So how does this work?
Part 1: Embeddings
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("bert-base-uncased")
tokenizer.convert_ids_to_tokens(tokenizer("let's talk about bpe")['input_ids'])
['[CLS]', 'let', "'", 's', 'talk', 'about', 'bp', '##e', '[SEP]']
Notice we split words out into sub-parts
This lets us have huge coverage with less tokens
| Token | Vector |
|---|---|
| "let" | [0.1, -0.8, ...] |
| "the" | [0.9, 0.85,...] |
Model then learns vectors in a lookup table during training
These are called "embeddings"
So how does this work?
Part 1: Embeddings
Some tips:
- On open source models you can normally add or remove tokens
- This encoding scheme can cause real issues with numbers, the transformer probably won't understand "123" is close to "12" and "4"
- (maybe in part 2: you can force some tokens to be generated)
So how does this work?
Part 2: Attention
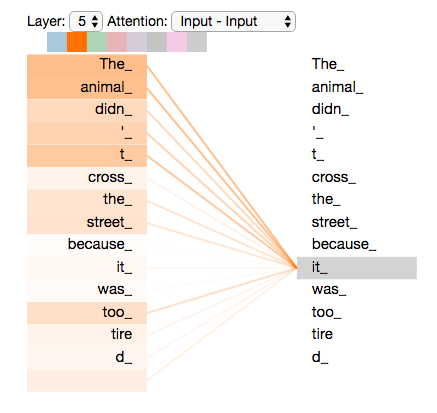
Idea behind attention is each token keeps a mapping of the "important" tokens around it
So in this example the attention mechanism learns "it" has a strong connection with "The animal"
So how does this work?
Part 2: Attention
For each token in the sequence we create:
- A Query vector
- A Key vector
- A Value vector
This is a sort of scaling factor for our task - eg is the token a noun or not
This is a learnable representation of asking "what other tokens are important?"
A learnable way of describing the token for other tokens to use
So how does this work?
Part 2: Attention
Dot product between Q and K to
norm factor, mostly to do with how we start training the model
our value scaling
So how does this work?
Part 2.5: The transformer block
We then do this several times (heads) and layer this with an FC layer
note this thing
So how does this work?
Part 3: Encoder (BERT et al)
We're nearly done, don't worry
What's the German for cake?
tokenize
embed
N layers of attention + FC networks
Get an embedding for the sequence
time is always up
So how does this work?
Part 4: Decoder (GPT et al)
[start token]
embedded context
tokenize
embed
attention block
do this for N layers
FC layer the size of the vocab
Pick the most likely next token from here
nb we drop this in GPT
So how does this work?
Part 4: Decoder (GPT et al)
[start token]Was
embedded context
tokenize
embed
attention block
do this for N layers
FC layer the size of the vocab
Pick the most likely next token from here
we literally loop - add "Was"
Text
So how does this work?
Part 4: Decoder (GPT et al)
[start token]Was heißt
embedded context
tokenize
embed
attention block
do this for N layers
FC layer the size of the vocab
Pick the most likely next token from here
heißt
Note this is trained using masks/without the loop
I guess downsides of this Architecture?
- Each token attends to all others, that's O(N^2) RNNs are O(N)
- You need a lot of compute and data to get this to train well. Realistically not possible before GPUs + AlexNet
- Very difficult to train from scratch, we know much more now about how to do this, but jeepers it's still hard
- Before this SOTA models could be trained on commercial desktops, now you need 60k H100s (meta-ai has two of these clusters)
- Tokenization + positional embeddings a weak point
Final Last thoughts
Idea behind the original paper was to:
- build a seq2seq model without the sequential bias
- got scaling up for free
Next time:
- Show you how to use the encoder and decoder on their own
- Some code
- Talk about pretraining and fine tuning