The Hitchhiker's Guide to
FASTER BUILDS
by Viktor Kirilov (2019 edition)
Me, myself and I
- my name is Viktor Kirilov - from Bulgaria
- 7+ years of professional C++ in the games / VFX / DB industries
- worked only on open source for 3 years (2016-2019)
- creator of doctest - the fastest C++ testing framework
- !!! not wasting time !!!
Passionate about
C++ is known for...
- ▲ performance
- ▲ expressiveness
- ▲ being multi-paradigm
- ▼ complexity
- ▼ metaprogramming could be much more powerful and simple
- ▼ no standard build system and package management
- ▼ L0oo0oOoNG COMPILE TIMES
Major C++ issue - compile times

This presentation
Introduction: WHAT and WHY
precompiled headers
unity builds
hardware
build systems
caching
distributed builds
diagnostics
static vs dynamic linking
linkers
PIMPL
forward declarations
includes
templates
binary bloat
annotations
modules
parallel builds
toolchains
tooling
symbol visibility
compilers
memes
HOW
Reality
- some projects take (tens of) hours to compile - WebKit: a big offender
- both minimal and full rebuilds suffer more and more in time
- all projects start small - build times increase inevitably
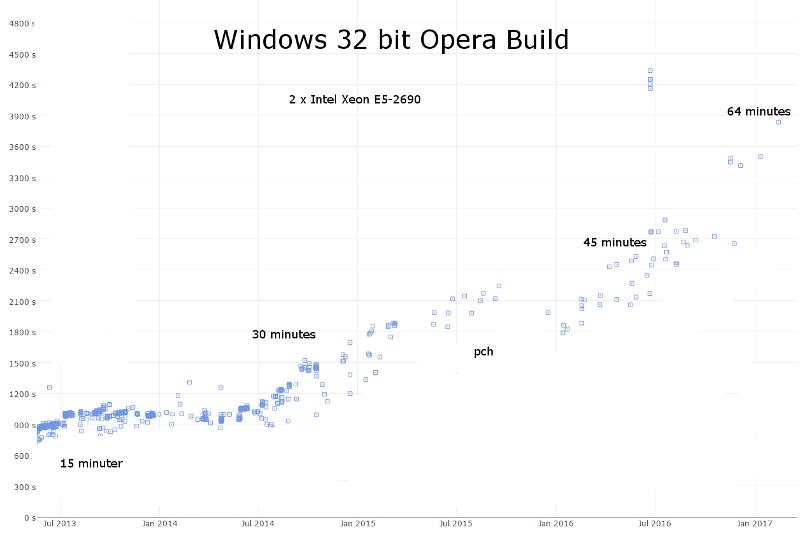
Opera 32 bit on Windows
in 3 years 6 months:
- 15 minutes to 64+
- + incorporated PCH !!!
A unique problem to C++

Actually the folks at Rust sympathize with us :D
Why reduce build times
- idle time is costly - lets do the math:
- assuming a 80k $ annual salary
- 1 hour daily for waiting (out of 8 hours: 12.5%)
- 10k $ per developer annually
- value to company > at least x3 the salary
- 100 developers ==> 3 million $ annually
- the unquantifiable effects of long build times
- discourage refactoring and experimentation
- lead to mental context switches (expensive)
- thinking != other work
- any time spent reducing build times is worthwhile !!!
The steps in building C++ code
- preprocessor: source file => translation unit
- includes
- macros, conditional compilation (ifdef)
- compiler: translation unit => object file
- parsing, tokens, AST
- optimizations
- code generation
- linker: object files & libraries => executable
- Absolutely fantastic explanation:
Why C++ compilation takes so long
- backwards compatibility with C: a killer feature ==> adoption!!!
- inherits the archaic textual include approach
- originally for sharing just declarations & structs between TUs
- inherits the archaic textual include approach
- language is complex (ADL, overloads, templates, etc.)
- multiple phases of translation - each depending on the previous
- not context independent
- new standards complicate things further
- complex zero-cost abstractions end up in headers
- even the preprocessor can become a bottleneck
- sub-optimal tools and build system setups
- bad project structure - component and header dependencies
- touch a header - rebuild everything
C vs C++ and different standards
| compiled as | time | increase |
|---|---|---|
| C | 5 sec | baseline |
| C++98 | 5.6 sec | +12% |
| C++11 | 5.6 sec | +12% |
| C++17 | 5.8 sec | +14% |
| compiled as | time | increase |
|---|---|---|
| C++98 | 8.4 sec | baseline |
| C++11 | 9.8 sec | +17% |
| C++17 | 10.8 sec | +29% |
C codebase (impl)
C++ codebase (impl + tests) (ver 1.2.8)
- Environment: GCC 7.2 on Windows, only compilation: "-c", in Debug: "-O0"
- optimizer doesn't care about language/standard: -O2 ==> same diff in seconds
- front-end and optimizer speed varies a lot, but linkers keep getting faster
-
newer standards might be even heavier depending on the code
- more constexpr, metaclasses, concepts - further pressure on compilers
- constexpr - more complex compiler, but faster compile time algorithms
That meme again...
Why includes suck
- textual - not symbolic
- parsed results cannot be cached - macros...
- implementation dependencies are leaked/dragged
- privately used types by value need the definition
- the same code gets compiled many times
- the same headers end up used in many sources
- M headers with N source files ==> M x N build cost
- templates
- re-instantiated for the same types
- require more code to be in headers
- inline functions in headers (this includes templates)
- more work for the compiler/linker
Standard includes - after the preprocessor
| Header | GCC 7 - size | lines of code | MSVC 2017 - size | lines of code |
|---|---|---|---|---|
| cstdlib | 43 kb | 1k | 158 kb | 11k |
| cstdio | 60 kb | 1k | 251 kb | 12k |
| iosfwd | 80 kb | 1.7k | 482 kb | 23k |
| chrono | 190 kb | 6.6k | 841 kb | 31k |
| variant | 282 kb | 10k | 1.1 mb | 43k |
| vector | 320 kb | 13k | 950 kb | 45k |
| algorithm | 446 kb | 16k | 880 kb | 41k |
| string | 500 kb | 17k | 1.1 mb | 52k |
| optional | 660 kb | 22k | 967 kb | 37k |
| tuple | 700 kb | 23k | 857 kb | 33k |
| map | 700 kb | 24k | 980 kb | 46k |
| iostream | 750 kb | 26k | 1.1 mb | 52k |
| memory | 852 kb | 29k | 1.0 mb | 40k |
| random | 1.1 mb | 37k | 1.4 mb | 67k |
| functional | 1.2 mb | 42k | 1.4 mb | 58k |
| regex | 1.7 mb | 64k | 1.5 mb | 71k |
| ALL OF THEM | 2.6mb | 95k | 2.3mb | 98k |
Standard includes - time
measurements of compile time for different headers:
"C++ Headers are Expensive!"
| future | 1.12 s |
|---|---|
| experimental/filesystem | 0.612 s |
| filesystem | 0.594 s |
| regex | 0.426 s |
| string | 0.4 s |
| future | 1.57 s |
|---|---|
| filesystem | 0.92 s |
| atomic | 0.702 s |
| regex | 0.698 s |
| locale | 0.641 s |
MSVC
Clang
Boost includes - after the preprocessor
| Header | GCC 7 - size | lines of code | MSVC 2017 - size | lines of code |
|---|---|---|---|---|
| hana | 857 kb | 24k | 1.5 mb | 69k |
| optional | 1.6 mb | 50k | 2.2 mb | 90k |
| variant | 2 mb | 65k | 2.5 mb | 124k |
| function | 2 mb | 68k | 2.6 mb | 118k |
| format | 2.3 mb | 75k | 3.2 mb | 158k |
| signals2 | 3.7 mb | 120k | 4.7 mb | 250k |
| thread | 5.8 mb | 188k | 4.8 mb | 304k |
| asio | 5.9 mb | 194k | 7.6 mb | 513k |
| wave | 6.5 mb | 213k | 6.7 mb | 454k |
| spirit | 6.6 mb | 207k | 7.8 mb | 563k |
| geometry | 9.6 mb | 295k | 9.8 mb | 448k |
| ALL OF THEM | 18 mb | 560k | 16 mb | 975k |
- environment: C++17, GCC 7, VS 2017, Boost version: 1.66
- 100 .cpp files including geometry ==> 1 GB of source code!
- not meant to discredit Boost - this is a C++ issue
- LOC for MSVC is big because #ifdef-ed parts take up lines
The evolution of C++
- hot debate - mainly sparked by people in the gamedev industry
-
"Modern" C++ Lamentations - reddit thread 1, thread 2
- Example using ranges VS plain C++
- 2.92 seconds vs 0.07 seconds of compile time
- debug performance terrible
- some spot-on comments
- Example using ranges VS plain C++
- zero-cost abstractions in headers aren't "zero-cost" in debug
- debug builds end up too slow in practice
- build speed is important - even in Release
-
"Modern" C++ Lamentations - reddit thread 1, thread 2
- library features VS language features - no simple answer
Insert title of slide
What can we do about all of this...
Any great talk starts with... Disclaimers!
- not really...
- haven't personally tested all of these tools/techniques
- sometimes defer to other more specialized resources
- no exact measurements for most of tips/techniques
- hard to reflect the real world or other projects
- some techniques are in conflict with each other
- reason yourself what to try and measure
- also too much work :D
- many tools use compile_commands.json
- can be generated by CMake, ninja, Build EAR (BEAR)
Debug vs Release - the most obvious
- compilers do a lot less in debug
- differences can be huge (2-3 ... 20 times)
- -O0, -O1, -O2, -O3, -Os - different results!
- a runtime compromise: enable *some* optimizations
- example - inlining: /Ob1 for MSVC
- might improve link times
- some game studios use it
- example - inlining: /Ob1 for MSVC
- GCC/Clang warning: -Wunused, -Wunused-function
- -ffunction/data-sections -Wl,--gc-sections,--print-gc-sections
- cppcheck --enable=unusedFunction
- Coverity - DEADCODE/UNREACHABLE
- Understand by scitools
- CppDepend
- PVS Studio
- OCLint
- Parasoft C/C++ Test
- Polyspace
- oovcde - static and dynamic dead code detection
- others... also runtime coverage (gcov (& lcov for GUI), others)
Unreachable (dead) code
The C++ philosophy: "don't pay for what you don't use"
might also uncover bugs
& improve runtime!
- unused sources/libraries
- look for such after dead code removal
- often a problem with makefiles and old cruft
- MSVC warning LNK4221: This object file does not define any previously undefined public symbols
-
compile each source file just once
- scan the build logs for such instances
- commonly used sources => static libraries
Other low hanging fruit
- strive for loose coupling
- specific includes is better than #include "everything.h"
- more granular rebuilds when touching headers
-
https://include-what-you-use.org/ - the most popular (Clang-based)
- Doxygen + Graphviz
- https://github.com/myint/cppclean
- Header Hero (or the fork) - article
- https://github.com/tomtom-international/cpp-dependencies
- ReSharper C++ Includes Analyzer << also has a test runner for doctest!
- Includator - plugin for Eclipse CDT (or the Cevelop IDE)
- https://gitlab.com/esr/deheader
- ProFactor IncludeManager - https://www.profactor.co.uk/
- MSVC: /showIncludes GCC: -H
Finding unnecessary includes
find_program(iwyu_path NAMES include-what-you-use iwyu)
set_property(TARGET hello PROPERTY CXX_INCLUDE_WHAT_YOU_USE ${iwyu_path})Declarations vs definitions - functions
// interface.h
int foo(); // fwd decl - definition is in a source file somewhere
inline int bar() { // needs to be inline if the body is in a header
return 42;
}
struct my_type {
int method { return 666; } // implicitly inline - can get inlined!
};
template <typename T> // a template - "usually" has to be in a header
T identity(T in) { return in; } // implicitly inline-
move function definitions out of headers
-
builds will be faster
-
use link time optimizations for inlining (or unity builds!)
-
-
some optimizations for templates exist - in later slides
Declarations vs definitions - types
// interface.h
#pragma once
struct foo; // fwd decl - don't #include "foo.h"!
#include "bar.h" // drag the definition of bar
struct my_type {
foo f_1(foo obj); // fwd decl used by value in signature - OK
foo* foo_ptr; // fwd decl used as pointer - OK
bar member; // requires the definition of bar
};// interface.cpp
#include "interface.h"
#include "foo.h" // drag the definition of foo
foo my_type::f_1(foo obj) { return obj; } // needs the definition of foo- used by value
- including in class definitions (size for memory layout)
- not in function declarations !!!
- types are used by reference/pointer
- pointer size is known by the compiler (4/8 bytes)
- compiler doesn't need to know the size of types
- types are used by value in function declarations
- either as a return type or as an argument
- this is less known !!!
- function definition will still need the full type definition
- call site also needs the full type definition
Declarations vs definitions - types
definition of types is necessary only when they are:
forward declarations are enough if:
On third-party libraries
- making wrapper types/headers might be smart
- example: platform specific stuff: <windows.h>
- dedicated headers with forward declarations
- instead of writing the same declarations manually
- STL example: <iosfwd> for the I/O streams
PIMPL - pointer to implementation
- AKA compilation firewall
- holds a pointer to the implementation type
// widget.h
struct widget {
widget();
~widget(); // cannot be defaulted here
void foo();
private:
struct impl; // just a fwd decl
std::unique_ptr<impl> m_impl;
};// widget.cpp
struct widget::impl {
void foo() {}
};
widget::widget() : m_impl(std::make_unique<widget::impl>()) {}
widget::~widget() = default; // here it is possible
void widget::foo() { m_impl->foo(); }PIMPL - pros & cons
- breaks the interface/implementation dependency
- less dragged headers ==> better compile times!
- implementation data members no longer affect the size
- helps with preserving ABI when changing the implementation
- lots of APIs use it (example: Qt, Autodesk Maya)
- requires allocation, also space overhead for pointer
- can use allocators
- extra indirection of calls - link time optimizations can help
- more code
PROS:
CONS:
on const propagation, moves, copies and other details: http://en.cppreference.com/w/cpp/language/pimpl
Abstract interfaces & factories
// interface.h
struct IBase {
virtual int do_stuff() = 0;
virtual ~IBase() = default;
};
// factory functions
std::unique_ptr<IBase> make_der_1(int);
std::unique_ptr<IBase> make_der_2();// interface.cpp
#include "interface.h"
// implementation 1
struct Derived_1 : public IBase {
int data;
Derived_1(int in) : data(in) {}
int do_stuff() override { return data; }
};
// implementation 2
struct Derived_2 : public IBase {
int do_stuff() override { return 42; }
};
// factory functions
std::unique_ptr<IBase> make_der_1(int in) {
return std::make_unique<Derived_1>(in);
}
std::unique_ptr<IBase> make_der_2() {
return std::make_unique<Derived_2>();
}Implementations of derived classes are obtained through factory functions
Abstract interfaces & factories
- breaks the interface/implementation dependency
- helps with preserving ABI (careful with the virtual interface)
- requires allocation, also space overhead for pointer
- extra indirection of calls (virtual)
- more code
- users work with (smart) pointers instead of values
- link time optimizations - harder than for PIMPL
PROS:
CONS:
Precompiled headers
- put headers that are used in many of the sources
- put headers that don't change often
- do regular audits to reflect the latest project needs
- often disregarded as a hack by many - HUGE mistake IMHO
- easy setup and benefits can be huge (although it depends...)
// precompiled.h
#pragma once
// system, runtime, STL
#include <cstdio>
#include <vector>
#include <map>
// third-party
#include <dynamix/dynamix.hpp>
#include <doctest.h>
// rarely changing project-specific
#include "utils/singleton.h"
#include "utils/transform.h"Precompiled headers - usage
-
supported by mainstream compilers
- MSVC: "/Yc" & "/Yu" (also ability to share it)
- GCC/Clang: "-x c++-header"
- only one PCH per translation unit :(
- force-include for convenience
- /FI (MSVC) or -include (GCC/Clang)
- build system support
- AKA: amalgamated, jumbo, lump, SCU
- include all original source files in one (or a few) unity source file(s)
Unity builds
// unity file
#include "core.cpp"
#include "widget.cpp"
#include "gui.cpp"- headers get parsed only once if included from multiple sources
- less compiler invocations
- less instantiation of the same templates
- HIGHLY underrated
- NOT because of reduced disk I/O - filesystems cache aggressively
- less linker work
- used at Ubisoft (14+ years), Unreal, WebKit
The main benefit is compile times:
- up to 10+ times faster (depends on modularity)
- best gains: short sources + lots of includes
- faster (and not slower) LTO (WPO/LTCG)
- ODR (One Definition Rule) violations get caught
- this one is huge - still no reliable tools
- .
- .
- enforces code hygiene
- include guards in headers
- no statics and anon namespaces in headers
- less copy/paste of types & inline functions
Unity builds - pros
// a.cpp
struct Foo {
// implicit inline
int method() { return 42; }
};// b.cpp
struct Foo {
// implicit inline
int method() { return 666; }
};- might slow down some workflows
- minimal rebuilds... WRONG! actually faster because of link time!
- might interfere with parallel compilation
- these ^^ can be solved with tuning/configuring
- some C++ stops compiling as a unity (blog post)
- clashes of symbols in anonymous namespaces
- overload ambiguities
- using namespaces in sources
- preprocessor
- miscompilation - rare (but possible)
- successful compilation with a wrong result
- preprocessor, overloads (also non-explicit 1 arg constructors)
- good tests can help!
Unity builds - cons
- CMake 3.16 !!!
- or use cotire as a CMake module
- FASTBuild (build system)
- Visual Studio experimental support for Unity builds (details)
- can produce multiple unity source files
- can exclude files (if problematic, or for incremental builds)
Unity builds - how to maintain
these:
others:
A patch to clang that:
- gives unique names to symbols in anonymous namespaces
- undef's macros from top-level source files
==> minimal changes to Chromium required
==> parts of it get built 3 times faster !!!!
"JumboSupport: making unity builds easier in Clang"
http://lists.llvm.org/pipermail/cfe-dev/2018-April/057579.html
Unity builds - potential Clang support
- __declspec(noinline) / __attribute__((noinline))
- and careful with __forceinline / __attribute__((always_inline))
- leads to compile time savings
- might even help with runtime (instruction cache bloat)
- implicit culprit: destructors
- especially for heavily repeated constructs
- asserts in testing frameworks
- example: doctest - "The fastest feature-rich C++11 single-header testing framework"
Inlining annotations
explicitly disable inlining:
- "don't pay for what you don't use"
- explicitly delete the ones which you don't need from headers
- especially for POD types
- less work for the compiler/linker
- some libraries even declare (default) ctors/dtors out of line (not in the header) for this exact purpose *cough* doctest
- the gains will likely be miniscule ==> effort is questionable
Special member functions
type(); // in header
type::type() = default; // in cpp- linkers sometimes can fold identical functions - but more work
- only if proven you aren't taking their addresses (required by the standard)
- this way: less work for the compiler/linker
- now it is syntactically easier to move function bodies out of the header
- use link time optimizations for inlining (or unity builds!)
Templates - argument-independent code
template <typename T>
class my_vector {
int m_size;
// ...
public:
int size() const { return m_size; }
// ...
};
// my_vector<T>::size() is instantiated
// for types such as int, char, etc...
// even though it doesn't depend on Tclass my_vector_base { // type independent
protected: // code is moved out
int m_size;
public:
int size() const { return m_size; }
};
template <typename T> // type dependent
class my_vector : public my_vector_base {
// ...
public:
// ...
};
Templates - C++11 extern template
// interface.h
#include <vector>
template <typename T>
T identity(T in) { return in; }// somewhere.cpp
#include "interface.h"
// do not instantiate these templates here
extern template int identity<int>(int);
extern template float identity<float>(float);
extern template class std::vector<int>;
// will not instantiate
auto g_int = identity(5);
auto g_float = identity(15.f);
std::vector<int> a;
// will instantiate for bool
auto g_unsigned = identity(true);- no instantiation/codegen where extern-ed but still has to be parsed...
- precompiled headers or unity builds !!!!
- some STL implementations do it for std::basic_string<char, ...>
- https://arne-mertz.de/2019/02/extern-template-reduce-compile-times/
// somewhere_else.cpp
#include "interface.h"
// instantiation for float
template float identity<float>(float);
// instantiation for std::vector<int>
template class std::vector<int>;
// instantiation for identity<int>()
auto g_int_2 = identity(1);the class/function has to be explicitly instantiated somewhere
for all types it is used with... or linker errors!
Templates - move functions out of headers
// interface.h
// declaration
template <typename T>
T identity(T in);
template <typename T>
struct answer {
// declaration
T calculate();
};// interface.cpp
#include "interface.h"
// definition
template <typename T>
T identity(T in) { return in; }
// definition
template <typename T>
T answer<T>::calculate() {
return T(42);
}
// explicit instantiations for int/float
template int identity<int>(int);
template float identity<float>(float);
// explicit instantiation for int
template struct answer<int>;
// user.cpp
#include "interface.h"
auto g_int = identity(666);
auto g_float = identity(0.541f);
auto g_answer = answer<int>().calculate();The "Rule of Chiel":
- looking up a memoized type
- adding a parameter to an alias call
- adding a parameter to a type
- calling an alias
- instantiating a type
- instantiating a function template
- SFINAE
Templates - cost of operations
A fascinating talk:
code::dive 2017 – Odin Holmes – The fastest template metaprogramming in the West
- use variadic templates sparingly
- recursive templates are bad business
- especially when not memoized
- recursive template arguments are even worse
-
now that we have "constexpr if" we can use a lot less SFINAE
- if constexpr might be preferrable even to tag dispatching
Templates - other notes
-
metashell - interactive template metaprogramming shell
- Clang-based
- GUI: https://github.com/RangelReale/msgui
-
https://github.com/mikael-s-persson/templight
- Clang-based
- profile time/memory consumption of template instantiations
- interactive debugging sessions
- https://github.com/mikael-s-persson/templight-tools
- Cevelop IDE (Eclipse CDT based) - Template Visualization
Templates - tools
-
CppCon 2017: Eddie Elizondo “Optimizing compilation times with Templates”
- reducing compile times of Thrift-generated code: type tags to circumvent SFINAE and use overload resolution
- diagnostics
- -ftime-report - breakdown of time spent in compiler phases
- templight
-
C++Now 2018: Odin Holmes “Boost.TMP: Your DSL for Metaprogramming” - Alternative title: "Boost your TMP-Fu"
- metaprogramming through composition
- builds onto his previous talk
- brigand, kvasir, metal, mp11 - http://metaben.ch/
Templates - other good talks
- book: C++ Templates: The Complete Guide (2nd Edition)
- The Cost of Recursive Instantiation
- Recursive template arguments example
- Improving compile times of C++ code
- Making Compiles Slow Through Abuse of Templates
-
Compile Time, Binary Size Reductions and C++'s future for sol3
- lambdas in templates that capture everything
- tuples, fold expressions, tag dispatching, if constexpr
- 37% less project compile time with a custom std::functuon
Templates - more resources
- -ftime-report - breakdown of different compiler phases
- -ftime-trace (Clang) - Chrome tracing flamegraph - by Aras Pranckevičius
- /Bt - frontend & backend (optimizer/codegen)
- /time - for the linker
- /d2cgsummary - Anomalistic Compile Times for functions
- first advertised by Aras Pranckevičius - "Best-unknown-MSVC-flag"
- /d1reportTime - includes, classes, functions - times - blog post
- /d1templateStats
- surprising 1 line fix => 20% faster builds thanks to these flags
- Updating VS 2017 15.6 to 15.8 => 2x slower for template instantiations
Diagnostics - compilation
some functions trigger pathological cases (or bugs) in compilers/optimizers
Clang/GCC:
MSVC:
- Bloaty McBloatface: a size profiler for ELF/Mach-O binaries
- Sizer: Win32/64 executable size report utility
- SymbolSort: measuring C++ code bloat in Windows binaries
- twiggy: call graph analyzer (wasm only, no ELF/Mach-O/PE/COFF yet)
- nm - Unix tool to inspect the symbol table of binaries
- nm --print-size --size-sort --demangle --radix=d YOUR_BINARY
- dumpbin: Microsoft COFF Binary File Dumper
- common culprit: templates (because length of names matters!!!)
- demangling: undname.exe / c++filt / https://demangler.com
Diagnostics - binary bloat
PGO
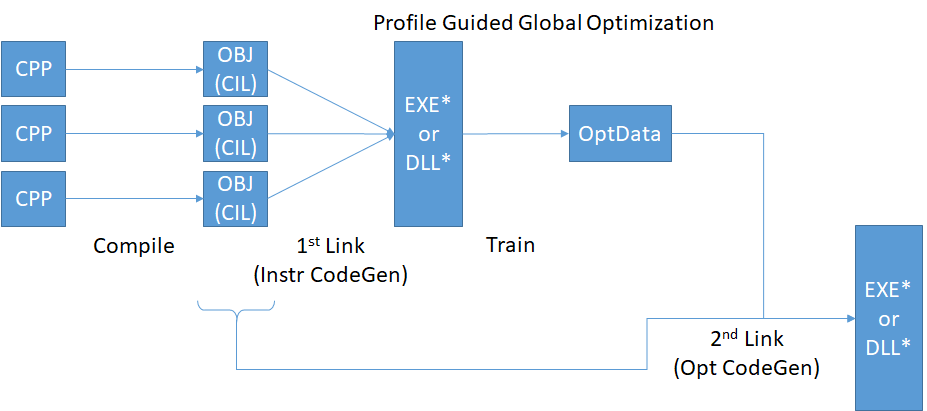
- instrumented compilation
- training - gathering profile data
- recompilation with training data
PGO-built compilers (and linkers !!!)
10... 15... 20% faster when tailored for your codebase
GCC: "profiledbootstrap" and "bootstrap-lto" targets
- gets compiled with PGO instrumentation
- compiles itself with the instrumented binary
- or your code
- compiles itself with the profile from the last build
- also: LTO, -march=native
Clang can also be PGO-bootstrapped
Build systems
Make
MSBuild
FASTBuild
Ninja
Buck
Bazel
Scons
Autotools
Jam
Boost.Build
Qmake
CMake
tup
build2
shake
IncrediBuild
Meta build systems:
Gyp
Waf
Meson
Premake
Custom...
XCode
Please
Tundra
GN
Build systems
- "g++ src1.cpp src2.cpp ..." is not a build system
- dependency tracking - for minimal and parallel rebuilds
- help managing scale
- includes, flags, link libs
- help with refactoring/restructuring
- help with tool integration
- not all are created equal
- HUGE topic (trade-offs, approaches) - but lets focus just on speed
- most old build systems have high overhead (MSBuild, make)
- suboptimal dependency and change detection/scanning
Parallel builds
- Ninja, FASTBuild, IncrediBuild: best in this regard
- make: -jN (and through CMake: "cmake --build . -- -jN")
-
MSBuild (build system behind Visual Studio):
- /MP[processMax] - in CMake: "target_compile_options(target /MP)"
-
inability to parallelize compilation of dependent dlls
- IncrediBuild fixes this when integrated with Visual Studio
-
thread oversubscription (no overarching scheduler):
- 8 projects in parallel (8 cpp each + /MP) ==> 64 threads!
- Ninja instead of MSBuild as the VS backend!
- since recently supports running Custom Build Tools in parallel
- Make VC++ Compiles Fast Through Parallel Compilation - Bruce Dawson
- careful with unity builds and "long poles"
- modern LTO/LTCG technology is parallelizable too
Meta build systems
- one canonical description of the project
-
can generate build files for different build systems
- hopefully including IDEs
- that means +1 step to build your code
- build files have to be updated occasionally
- usually extensible - with different backends
- CMake...
- the (meta) build system we love to hate
- sort-of the industry standard by now
- use modern CMake (target-based) and new policies
- generation phase can be a big bottleneck (thousands of targets)
- https://github.com/cristianadam/cmake-checks-cache
- might also build it with PGO
Diagnosing/monitoring parallelism
Make VC++ Compiles Fast Through Parallel Compilation - Bruce Dawson
Diagnosing/monitoring parallelism
IncrediBuild build monitor - article
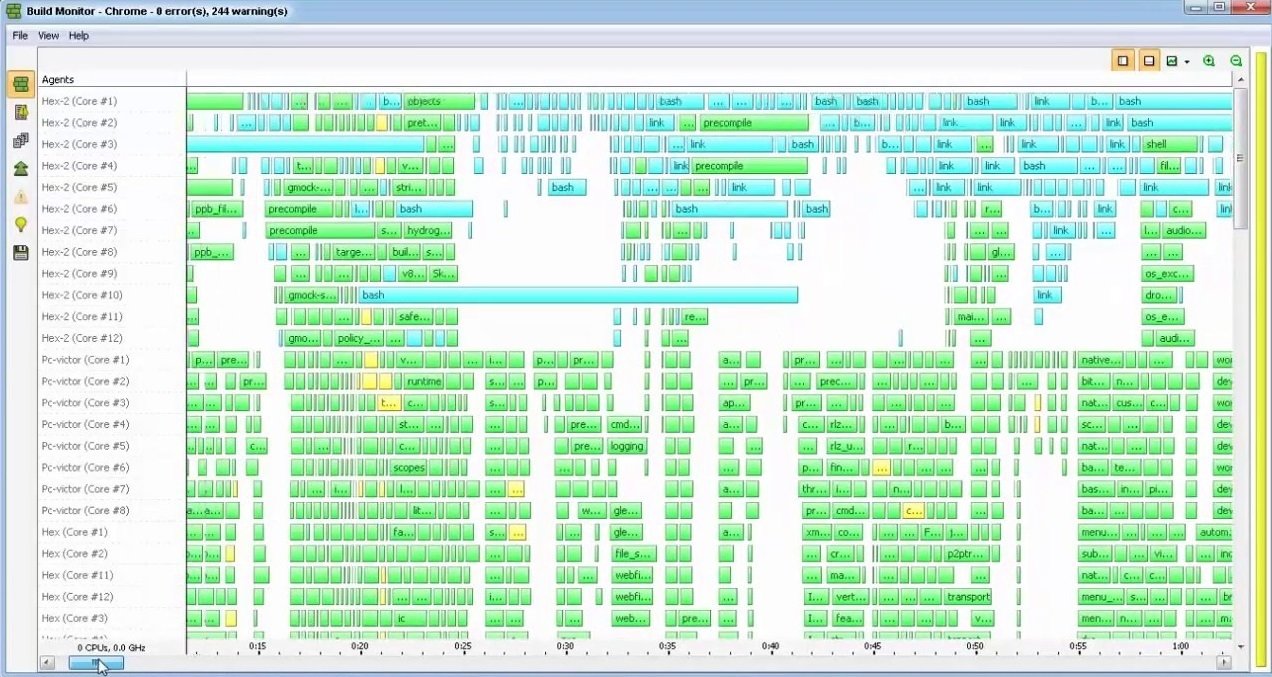
Diagnosing/monitoring parallelism
Chrome's about:tracing (flame graph) - chrome://tracing/

- ninjatracing
- buck build system
- not related to parallelism, but for
-ftime-trace in clang: - other blog post
Sort-of winners (in terms of speed)
- FASTBuild
- unity builds
- precompiled headers
- caching
- distributed builds
- best parallelization
- generates project files
- multiplatform
- multi-compiler
- tiny
- might get a CMake backend
- others...
haven't looked into these yet
- buck << by Facebook
- bazel << by Google
- build2 << modules! :D
- meson << hot contender
- ...
- Ninja - less features but crazy fast - intented to be generated by a meta-build system
- GN (GYP replacement)
- can generate ONLY ninja
- IndrediBuild
- tup
Possible build system improvements
when a dynamic library is linked
- triggers relinking of other libraries that depend on it
- EVEN WHEN THE ABI HASN'T CHANGED :(
"Pruning Dynamic Rebuilds With libabigail"
compare hashes of the ABI to determine if dependent
DSOs should be relinked
https://engineering.mongodb.com/post/pruning-dynamic-rebuilds-with-libabigail
Possible to implement in most build systems
Other possibilities: don't rebuild on whitespace only changes
Internal vs external linkage
use internal linkage for implementation details in source files
// file_1.cpp
// internal linkage
namespace { int ans = 42; }
// internal linkage
static int foo() { return ans; }
// external linkage
int bar() { return foo(); }// file_2.cpp
// will get it from file_1.cpp
int bar();
// internal linkage
namespace { int ans = 666; }
// internal linkage
static int foo() { return bar(); }
... foo() + ans ==> "708"- eases the burden on the linker
- easier to remove the function entirely if inlined
- give unique names to not fight with unity builds
- or nest inside of a named namespace!
- don't expect huge gains from this
- big discussion overall - but here we care about build times
- much much faster - handles only the exported interface
Static vs dynamic linking
prefer dynamic (.dll, .so, .dylib) over static (.lib, .a)
- Unix: all symbols exported by default
- opposite to Windows - which got the default right!
- UNIX: compile with -fvisibility=hidden
- improves link time
- annotate the required parts of the API for exporting
- circumvents the GOT (Global Offset Table) for calls => profit
- load times also improved (extreme templates case: 45 times)
- reduces the size of your DSO by 5-20%
- for details: https://gcc.gnu.org/wiki/Visibility
- clang-cl on windows: /Zc:dllexportInlines- => 30% faster chrome build
- alternative: -fvisibility-inlines-hidden
- all inlined member functions are hidden
- no source code modifications needed
- careful with local statics in inline functions
- can also explicitly annotate with default visibility
Dynamic linking - symbol visibility
Multiplatform symbol export annotations
#if defined _WIN32 || defined __CYGWIN__
#define SYMBOL_EXPORT __declspec(dllexport)
#define SYMBOL_IMPORT __declspec(dllimport)
#define SYMBOL_HIDDEN
#else
#define SYMBOL_EXPORT __attribute__((visibility("default")))
#define SYMBOL_IMPORT
#define SYMBOL_HIDDEN __attribute__((visibility("hidden")))
#endif
#ifdef DLL_EXPORTS // on this depends if we are exporting or importing
#define MY_API SYMBOL_EXPORT
#else
#define MY_API SYMBOL_IMPORT
#endif
MY_API void foo();
class MY_API MyClass {
int c;
SYMBOL_HIDDEN void privateMethod(); // only for use within this DSO
public:
MyClass(int _c) : c(_c) { }
static void foo(int a);
};Linkers
- gold (unix)
- comes with binutils starting from version 2.19
- -fuse-ld=gold
- not threaded by default
- configure with "--enable-threads"
- use: "--threads", "--thread-count COUNT", "--preread-archive-symbols"
- lld even faster than gold - https://lld.llvm.org/ - multithreaded by default
- Unix: Split DWARF - article - building clang/llvm codebase
- 10%+ faster full builds and 40%+ faster incremental builds
- CMake - LINK_WHAT_YOU_USE
- can also build the linker yourself and add -flto, -march=native (or even do a PGO build of the linker with your codebase)
Linkers - LTO and other flags
- clang
- GCC 8: link time and interprocedural optimization (also for >> GCC 9 <<)
- MSVC - lots of improvements, also regarding LTCG
- lots of improvements in the recent years
- /debug:fastlink – generate partial PDB (new format)
- /INCREMENTAL for debug
- VS 2019 - huge speedups in 15.9 (~x2), and even some more in 16.2!
-
LTCG
- /LTCG:incremental
- also parallel - /cgthreads:8 instead of the default 4
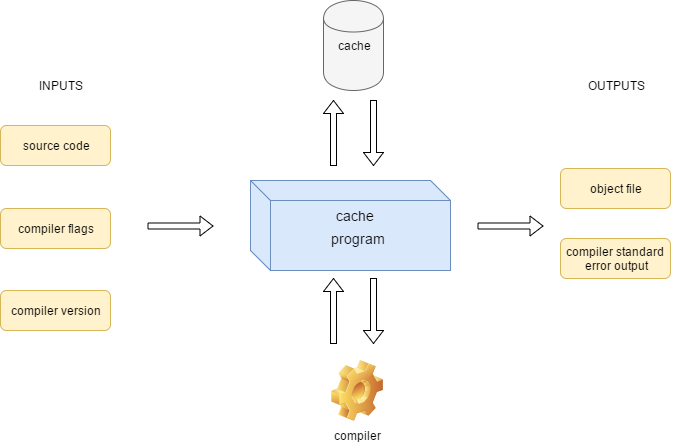
Compiler caches
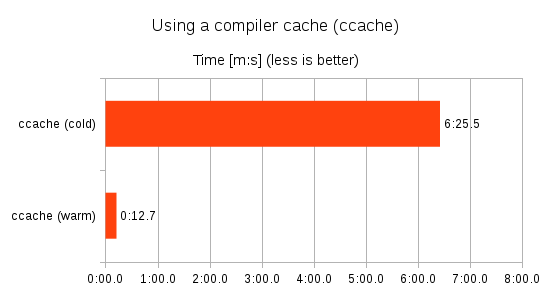
"compiler wrapper" -
maps a hash of:
- preprocessed source (TU)
- compilation flags
& compiler version
==> to an object file
- First run (cold cache) is a bit slower than without the wrapper
- Consecutive >> FULL << rebuilds
are much faster (warm cache)
Compiler caches
- For Unix alike: ccache (GCC, Clang), cachecc1 (GCC)
- For Windows: clcache (MSVC), cclash (MSVC)
- http://fastbuild.org/ - straight out of the build system!
-
https://github.com/mozilla/sccache (GCC, Clang, MSVC)
- ccache with cloud storage over AWS S3/GCS/Redis
-
https://stashed.io/ (MSVC)
- also distributed & with cloud storage
-
zapcc - a Clang fork - not a wrapper! - mail thread
- in memory caching server for requested compilations
- biggest gains on heavy templates - article
- recently open-sourced - future not clear
- WebKit can compile x2~x5 times faster - more benchmarks
Compiler caches
- caches work best for full rebuilds - not minimal
find_program(CCACHE_PROGRAM ccache)
if(CCACHE_PROGRAM)
set_property(GLOBAL PROPERTY RULE_LAUNCH_COMPILE "${CCACHE_PROGRAM}")
endif()
project(SomeProject)Distributed builds

- https://github.com/distcc/distcc
- https://github.com/icecc/icecream
- https://www.incredibuild.com/
- some reddit thread
- OMG again that build system!!! ==> http://fastbuild.org/
- some article: Speed up C++ compilation, part 3: distributed compilation
export CCACHE_PREFIX=DISTCCHardware



Hardware
- more cores
- make sure you have enough RAM && parallel builds setup
- RAM disks (file system drive in your RAM instead of ssd/hdd)
- better than SSDs
- don't expect huge gains though...
- mount $TEMP as a RAM disk (%TEMP% for windows)
- build output to RAM disk (most important - because of the link step)
- also put the compiler there!
-
CppCon 2014: Matt Hargett "Common-sense acceleration of your MLOC build"
- touches on network I/O issues and many other topics
What if the fundament is bad

Physical design
-
physical structure/design
- often neglected
- every project starts small... some end up big and it's too late
- reasoning about components and modularity - IMPORTANT!!!
- physically (and logically): files, dependencies, includes
- benefits: fast builds, easy to reason, easy to refactor
- Article: Physical Structure and C++ - A First Look
-
John Lakos (Bloomberg)
- book: "Large-scale C++ Software Design"
- multi-part talk: "Advanced Levelization Techniques"
- C++Now 2018: “C++ Modules & Large-Scale Development”
- Controversial article: Physical Design of The Machinery
Dependency analysis
- cmake --graphviz=[file]
- Most tools from the "Finding unnecessary includes" slide
- Understand by scitools
- CppDepend
- cpp-dependencies - Graphviz
- Doxygen - Graphviz
- maybe even SourceTrail
- IDE tools
Dependency analysis

Boost.Variant - Boost dependencies and bcp - by Stephen Kelly
MODULES
Modules - history
- 2004.11.05: first proposal: n1736 - Modules in C++
- by Daveed Vandevoorde - working on EDG - the only compiler supporting exported templates (and aiding in their deprecation)
- dropped from C++11 after a few revisions ==> headed for a TR
- 2011: work on first implementation in Clang - by Douglas Gregor
- 2014.05.27: standardization continues with n4047 - A Module System for C++
- by Gabriel Dos Reis, Mark Hall and Gor Nishanov
- after a few revisions - didn't enter C++17 - left as a TS
-
latest work: will enter C++20, many other papers omitted from this list
- 2017.06.16: Business Requirements for Modules
- 2018.01.29: n4720 - Working Draft, Extensions to C++ for Modules
- 2018.03.06: Another take on Modules , p0924r0
- 2018.05.02: Modules, Macros, and Build Systems
- 2018.10.08: Merging Modules, p1218r0, p1242r0
Modules - motivation
- compile times...!!! hopefully? no?
- preprocessor includes led to:
- leaked symbols & implementation details
- name clashes
- making tooling hard
- workarounds (include guards)
- include order matters
- more DRY (don't repeat yourself)
- forward declarations
- code duplication in headers/sources
Modules - VS 2017 example
import std.core; // containers, algorithms, etc.
import M_1; // our module!
int main() {
std::vector<std::string> v = getStrings();
std::copy(v.begin(), v.end(),
std::ostream_iterator<std::string>(std::cout, "\n"));
}import std.core; // containers, string
export module M_1; // named M_1
export std::vector<std::string> getStrings() {
return {"Plato", "Descartes", "Bacon"};
}cl.exe /experimental:module /EHsc /MD /std:c++latest /module:export /c mod_1.cpp
cl.exe /experimental:module /EHsc /MD /std:c++latest /module:reference M_1.ifc /c main.cpp
cl.exe main.obj mod_1.obj
Modules - how they work
- BMI (Binary Module Interface) files
- consumed by importers
- produced by compiling a MIU (Module Interface Unit)
- (maybe) contains serialized AST (abstract syntax tree) with the exported parts of the parsed C++
- unlike precompiled headers:
- composability of multiple modules
- explicit code annotations to define visible interfaces
Modules - obsolete techniques
- PIMPL!!! (mostly)
- unless you need to provide ABI stability of your APIs
- forward declarations (mostly)
- precompiled headers
- unity builds (mostly)
Modules - the current state
- big companies are invested in them (think BIG)
- there are 3 implementations already (MSVC, Clang, GCC)
- coming in C++20
- when standardized and implemented in compilers:
- do not expect astronomical gains in speed (for now)
- build system support is hard
- notably build2 supports modules!
- slow adoption in existing software
- updating toolchains
- source code changes
- third party dependencies
- if it ain't "broke" don't fix it

More on modules
Many details: exported macros?!?! - resources:
- CppCon 2015: Gabriel Dos Reis “Large Scale C++ with Modules: What You Should Know"
- CppCon 2016: Manuel Klimek “Deploying C++ modules to 100s of millions of lines of code"
- CppCon 2016: Gabriel Dos Reis “C++ Modules: The State of The Union"
- CppCon 2017: Boris Kolpackov “Building C++ Modules”
- CppCon 2017: Nathan Sidwell “Adding C++ modules-ts to the GNU Compiler”
- CppCon 2018: John Lakos - “C++ Modules and Large-Scale Development“
- CppCon 2018: Nathan Sidwell - “Progress with C++ Modules“ <<<<<
- article - Modules are not a tooling opportunity
- article - Using C++ Modules in Visual Studio 2017
- article - What exactly is the proposed module system?
- article - Trying out clang 5 modules in a 70k loc project.
- article - Common C++ Modules TS Misconceptions
Even more on modules
Next steps
- consider runtime C++ compilation & hotswap
- make source control checkouts faster
- tests
- doctest? please!!! it's great, trust me :)
- ctest has -j N
- Continuous integration
- IDE integration of tools for better productivity
- change language :| Nim is the anwser *cough*
Enforcing
Vague rules + no enforcement + path of least resistance
+ human nature → chaos
- code reviews
- automation
- tooling
- code hygiene metrics/diagnostics
- clang-based
- pre-commit hooks
- CI checks
- notifications
- tooling
I'm free for consultant work!
You can hire me to fix your C++ build times.
Expect something along the lines of this:
https://onqtam.github.io/programming/2019-12-20-pch-unity-cmake-3-16/
Q&A
- Slides: https://slides.com/onqtam/faster_builds
- Blog: http://onqtam.github.io
- GitHub: https://github.com/onqtam
- : https://twitter.com/KirilovVik
- E-Mail: vik.kirilov@gmail.com
Other useful links: