










Viktor Kirilov
C++ dev
by Viktor Kirilov (2019 edition)
Passionate about
Introduction: WHAT and WHY
precompiled headers
unity builds
hardware
build systems
caching
distributed builds
diagnostics
static vs dynamic linking
linkers
PIMPL
forward declarations
includes
templates
binary bloat
annotations
modules
parallel builds
toolchains
tooling
symbol visibility
compilers
memes
HOW
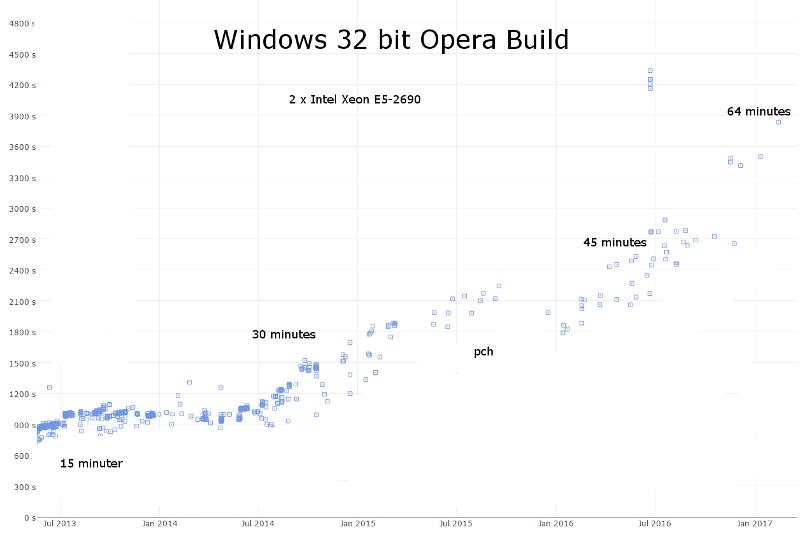
Opera 32 bit on Windows
in 3 years 6 months:
Actually the folks at Rust sympathize with us :D
| compiled as | time | increase |
|---|---|---|
| C | 5 sec | baseline |
| C++98 | 5.6 sec | +12% |
| C++11 | 5.6 sec | +12% |
| C++17 | 5.8 sec | +14% |
| compiled as | time | increase |
|---|---|---|
| C++98 | 8.4 sec | baseline |
| C++11 | 9.8 sec | +17% |
| C++17 | 10.8 sec | +29% |
C codebase (impl)
C++ codebase (impl + tests) (ver 1.2.8)
| Header | GCC 7 - size | lines of code | MSVC 2017 - size | lines of code |
|---|---|---|---|---|
| cstdlib | 43 kb | 1k | 158 kb | 11k |
| cstdio | 60 kb | 1k | 251 kb | 12k |
| iosfwd | 80 kb | 1.7k | 482 kb | 23k |
| chrono | 190 kb | 6.6k | 841 kb | 31k |
| variant | 282 kb | 10k | 1.1 mb | 43k |
| vector | 320 kb | 13k | 950 kb | 45k |
| algorithm | 446 kb | 16k | 880 kb | 41k |
| string | 500 kb | 17k | 1.1 mb | 52k |
| optional | 660 kb | 22k | 967 kb | 37k |
| tuple | 700 kb | 23k | 857 kb | 33k |
| map | 700 kb | 24k | 980 kb | 46k |
| iostream | 750 kb | 26k | 1.1 mb | 52k |
| memory | 852 kb | 29k | 1.0 mb | 40k |
| random | 1.1 mb | 37k | 1.4 mb | 67k |
| functional | 1.2 mb | 42k | 1.4 mb | 58k |
| regex | 1.7 mb | 64k | 1.5 mb | 71k |
| ALL OF THEM | 2.6mb | 95k | 2.3mb | 98k |
measurements of compile time for different headers:
"C++ Headers are Expensive!"
| future | 1.12 s |
|---|---|
| experimental/filesystem | 0.612 s |
| filesystem | 0.594 s |
| regex | 0.426 s |
| string | 0.4 s |
| future | 1.57 s |
|---|---|
| filesystem | 0.92 s |
| atomic | 0.702 s |
| regex | 0.698 s |
| locale | 0.641 s |
MSVC
Clang
| Header | GCC 7 - size | lines of code | MSVC 2017 - size | lines of code |
|---|---|---|---|---|
| hana | 857 kb | 24k | 1.5 mb | 69k |
| optional | 1.6 mb | 50k | 2.2 mb | 90k |
| variant | 2 mb | 65k | 2.5 mb | 124k |
| function | 2 mb | 68k | 2.6 mb | 118k |
| format | 2.3 mb | 75k | 3.2 mb | 158k |
| signals2 | 3.7 mb | 120k | 4.7 mb | 250k |
| thread | 5.8 mb | 188k | 4.8 mb | 304k |
| asio | 5.9 mb | 194k | 7.6 mb | 513k |
| wave | 6.5 mb | 213k | 6.7 mb | 454k |
| spirit | 6.6 mb | 207k | 7.8 mb | 563k |
| geometry | 9.6 mb | 295k | 9.8 mb | 448k |
| ALL OF THEM | 18 mb | 560k | 16 mb | 975k |
Any great talk starts with... Disclaimers!
The C++ philosophy: "don't pay for what you don't use"
might also uncover bugs
& improve runtime!
find_program(iwyu_path NAMES include-what-you-use iwyu)
set_property(TARGET hello PROPERTY CXX_INCLUDE_WHAT_YOU_USE ${iwyu_path})// interface.h
int foo(); // fwd decl - definition is in a source file somewhere
inline int bar() { // needs to be inline if the body is in a header
return 42;
}
struct my_type {
int method { return 666; } // implicitly inline - can get inlined!
};
template <typename T> // a template - "usually" has to be in a header
T identity(T in) { return in; } // implicitly inlinemove function definitions out of headers
builds will be faster
use link time optimizations for inlining (or unity builds!)
some optimizations for templates exist - in later slides
// interface.h
#pragma once
struct foo; // fwd decl - don't #include "foo.h"!
#include "bar.h" // drag the definition of bar
struct my_type {
foo f_1(foo obj); // fwd decl used by value in signature - OK
foo* foo_ptr; // fwd decl used as pointer - OK
bar member; // requires the definition of bar
};// interface.cpp
#include "interface.h"
#include "foo.h" // drag the definition of foo
foo my_type::f_1(foo obj) { return obj; } // needs the definition of foo
definition of types is necessary only when they are:
forward declarations are enough if:
// widget.h
struct widget {
widget();
~widget(); // cannot be defaulted here
void foo();
private:
struct impl; // just a fwd decl
std::unique_ptr<impl> m_impl;
};// widget.cpp
struct widget::impl {
void foo() {}
};
widget::widget() : m_impl(std::make_unique<widget::impl>()) {}
widget::~widget() = default; // here it is possible
void widget::foo() { m_impl->foo(); }
PROS:
CONS:
on const propagation, moves, copies and other details: http://en.cppreference.com/w/cpp/language/pimpl
// interface.h
struct IBase {
virtual int do_stuff() = 0;
virtual ~IBase() = default;
};
// factory functions
std::unique_ptr<IBase> make_der_1(int);
std::unique_ptr<IBase> make_der_2();// interface.cpp
#include "interface.h"
// implementation 1
struct Derived_1 : public IBase {
int data;
Derived_1(int in) : data(in) {}
int do_stuff() override { return data; }
};
// implementation 2
struct Derived_2 : public IBase {
int do_stuff() override { return 42; }
};
// factory functions
std::unique_ptr<IBase> make_der_1(int in) {
return std::make_unique<Derived_1>(in);
}
std::unique_ptr<IBase> make_der_2() {
return std::make_unique<Derived_2>();
}Implementations of derived classes are obtained through factory functions
PROS:
CONS:
// precompiled.h
#pragma once
// system, runtime, STL
#include <cstdio>
#include <vector>
#include <map>
// third-party
#include <dynamix/dynamix.hpp>
#include <doctest.h>
// rarely changing project-specific
#include "utils/singleton.h"
#include "utils/transform.h"// unity file
#include "core.cpp"
#include "widget.cpp"
#include "gui.cpp"The main benefit is compile times:
// a.cpp
struct Foo {
// implicit inline
int method() { return 42; }
};// b.cpp
struct Foo {
// implicit inline
int method() { return 666; }
};
these:
others:
A patch to clang that:
==> minimal changes to Chromium required
==> parts of it get built 3 times faster !!!!
"JumboSupport: making unity builds easier in Clang"
http://lists.llvm.org/pipermail/cfe-dev/2018-April/057579.html
explicitly disable inlining:
type(); // in header
type::type() = default; // in cpptemplate <typename T>
class my_vector {
int m_size;
// ...
public:
int size() const { return m_size; }
// ...
};
// my_vector<T>::size() is instantiated
// for types such as int, char, etc...
// even though it doesn't depend on Tclass my_vector_base { // type independent
protected: // code is moved out
int m_size;
public:
int size() const { return m_size; }
};
template <typename T> // type dependent
class my_vector : public my_vector_base {
// ...
public:
// ...
};
// interface.h
#include <vector>
template <typename T>
T identity(T in) { return in; }// somewhere.cpp
#include "interface.h"
// do not instantiate these templates here
extern template int identity<int>(int);
extern template float identity<float>(float);
extern template class std::vector<int>;
// will not instantiate
auto g_int = identity(5);
auto g_float = identity(15.f);
std::vector<int> a;
// will instantiate for bool
auto g_unsigned = identity(true);// somewhere_else.cpp
#include "interface.h"
// instantiation for float
template float identity<float>(float);
// instantiation for std::vector<int>
template class std::vector<int>;
// instantiation for identity<int>()
auto g_int_2 = identity(1);the class/function has to be explicitly instantiated somewhere
for all types it is used with... or linker errors!
// interface.h
// declaration
template <typename T>
T identity(T in);
template <typename T>
struct answer {
// declaration
T calculate();
};// interface.cpp
#include "interface.h"
// definition
template <typename T>
T identity(T in) { return in; }
// definition
template <typename T>
T answer<T>::calculate() {
return T(42);
}
// explicit instantiations for int/float
template int identity<int>(int);
template float identity<float>(float);
// explicit instantiation for int
template struct answer<int>;
// user.cpp
#include "interface.h"
auto g_int = identity(666);
auto g_float = identity(0.541f);
auto g_answer = answer<int>().calculate();The "Rule of Chiel":
A fascinating talk:
code::dive 2017 – Odin Holmes – The fastest template metaprogramming in the West
some functions trigger pathological cases (or bugs) in compilers/optimizers
Clang/GCC:
MSVC:
10... 15... 20% faster when tailored for your codebase
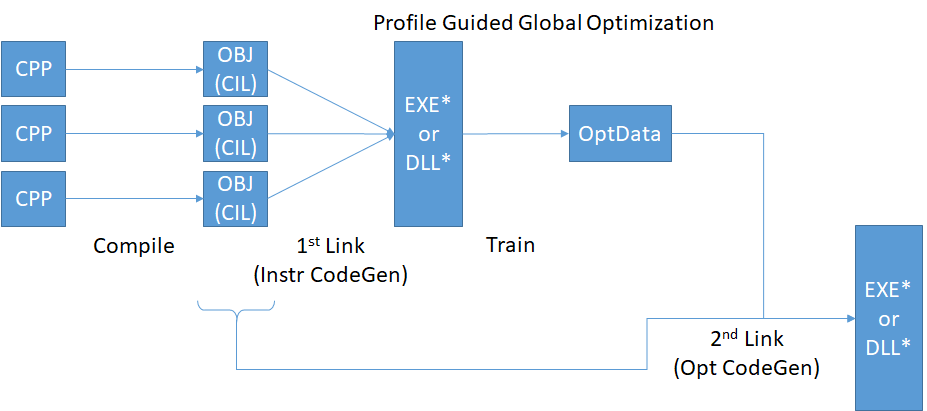
GCC: "profiledbootstrap" and "bootstrap-lto" targets
Clang can also be PGO-bootstrapped
Make
MSBuild
FASTBuild
Ninja
Buck
Bazel
Scons
Autotools
Jam
Boost.Build
Qmake
CMake
tup
build2
shake
IncrediBuild
Meta build systems:
Gyp
Waf
Meson
Premake
Custom...
XCode
Please
Tundra
GN
Make VC++ Compiles Fast Through Parallel Compilation - Bruce Dawson
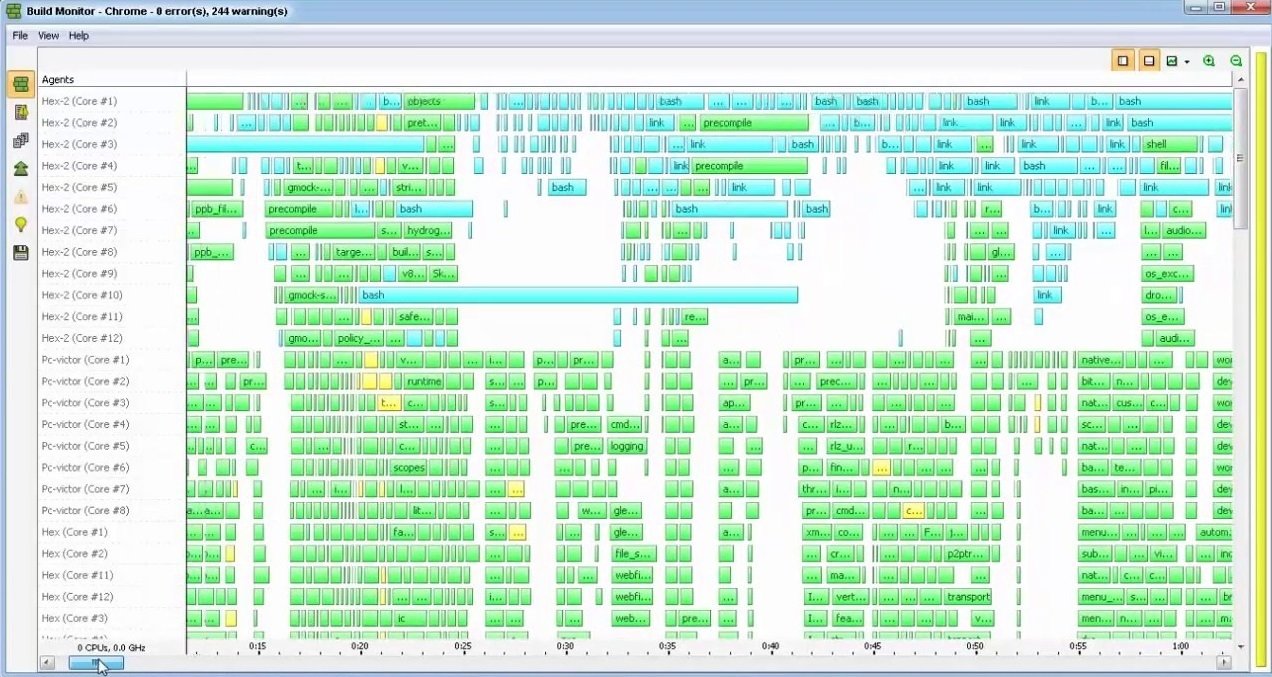
IncrediBuild build monitor - article
Chrome's about:tracing (flame graph) - chrome://tracing/
haven't looked into these yet
when a dynamic library is linked
"Pruning Dynamic Rebuilds With libabigail"
compare hashes of the ABI to determine if dependent
DSOs should be relinked
https://engineering.mongodb.com/post/pruning-dynamic-rebuilds-with-libabigail
Possible to implement in most build systems
Other possibilities: don't rebuild on whitespace only changes
use internal linkage for implementation details in source files
// file_1.cpp
// internal linkage
namespace { int ans = 42; }
// internal linkage
static int foo() { return ans; }
// external linkage
int bar() { return foo(); }// file_2.cpp
// will get it from file_1.cpp
int bar();
// internal linkage
namespace { int ans = 666; }
// internal linkage
static int foo() { return bar(); }
... foo() + ans ==> "708"prefer dynamic (.dll, .so, .dylib) over static (.lib, .a)
#if defined _WIN32 || defined __CYGWIN__
#define SYMBOL_EXPORT __declspec(dllexport)
#define SYMBOL_IMPORT __declspec(dllimport)
#define SYMBOL_HIDDEN
#else
#define SYMBOL_EXPORT __attribute__((visibility("default")))
#define SYMBOL_IMPORT
#define SYMBOL_HIDDEN __attribute__((visibility("hidden")))
#endif
#ifdef DLL_EXPORTS // on this depends if we are exporting or importing
#define MY_API SYMBOL_EXPORT
#else
#define MY_API SYMBOL_IMPORT
#endif
MY_API void foo();
class MY_API MyClass {
int c;
SYMBOL_HIDDEN void privateMethod(); // only for use within this DSO
public:
MyClass(int _c) : c(_c) { }
static void foo(int a);
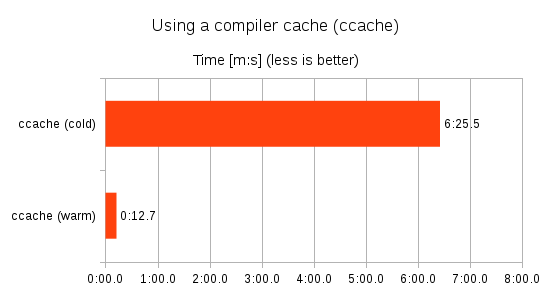
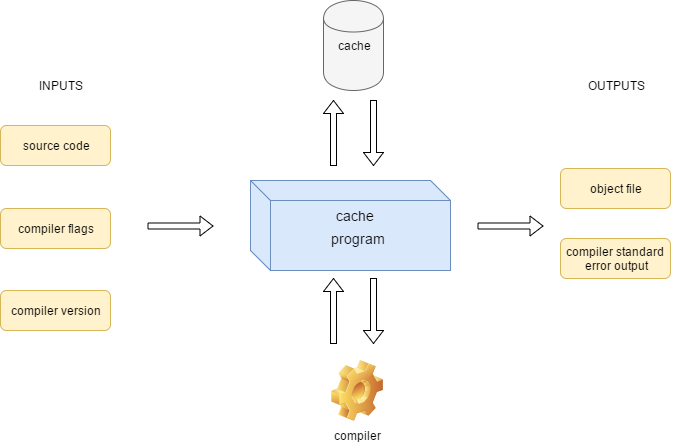
};"compiler wrapper" -
maps a hash of:
==> to an object file
find_program(CCACHE_PROGRAM ccache)
if(CCACHE_PROGRAM)
set_property(GLOBAL PROPERTY RULE_LAUNCH_COMPILE "${CCACHE_PROGRAM}")
endif()
project(SomeProject)export CCACHE_PREFIX=DISTCCBoost.Variant - Boost dependencies and bcp - by Stephen Kelly
MODULES
import std.core; // containers, algorithms, etc.
import M_1; // our module!
int main() {
std::vector<std::string> v = getStrings();
std::copy(v.begin(), v.end(),
std::ostream_iterator<std::string>(std::cout, "\n"));
}import std.core; // containers, string
export module M_1; // named M_1
export std::vector<std::string> getStrings() {
return {"Plato", "Descartes", "Bacon"};
}cl.exe /experimental:module /EHsc /MD /std:c++latest /module:export /c mod_1.cpp
cl.exe /experimental:module /EHsc /MD /std:c++latest /module:reference M_1.ifc /c main.cpp
cl.exe main.obj mod_1.objMany details: exported macros?!?! - resources:
Vague rules + no enforcement + path of least resistance
+ human nature → chaos
You can hire me to fix your C++ build times.
Expect something along the lines of this:
https://onqtam.github.io/programming/2019-12-20-pch-unity-cmake-3-16/
Other useful links:
By Viktor Kirilov
Covers absolutely every possible tool/technique to improve compile and link times for C++ code (2019 edition)



