Neural Network Compression




Outline/Content
Pruning
- Learning both Weights and Connections for Efficient Neural Networks
- Pruning Filters for Efficient ConvNets



Cited By 3831 in 2021 Aug 12

- Regularization
- Dropout Ratio Adjustment
- Local Pruning and Parameter Co-adaptation
- Iterative Pruning
- Pruning Neurons
Regularization

Since we want to prune the weights near to zero
So add a regularizer to the weight will make weights near to zero
\(L_{total} \)
\(= L_{original} + \lambda \sum |w|^p\)
Dropout Ratio Adjustment
To keep the drop rate of each neuron B&A pruning.
(e.g. 30% before pruning, and 30% for pruned model)
The droprate of purned model should be adjust.

C : Numbers of non-zero connections/wieghts (∝ neuron^0.5)
D : Droprate

Local Pruning and Parameter Co-adaptation
After pruning, use old weight then continue training.
Not retrain with pruned structure with new initialized weight.
Iterative Pruning

Aggressive:
train -> prune 30% -> train
Iterative:
train -> prune 10% -> train-> prune 10% -> train -> prune 10% -> train
Pruning Neurons

The neurons with zero input/output connections can be safely pruned.
For implement, we should not care about this in some stages, since the regularized term will digest them to zero.
Results

Results

Results

Results

Cited By 1904 in 2021 Aug 12


Notation:
i : layer index
j : channel index
h,w : height, width
x : feature map
n : number of channels
F : convolution kernel
Note:
Convolution parameters size is \((n_i, n_{i+1}, k_h, k_w)\)
and \(F_{i,j}\) size is \(ni \times kh \times kw\)
\(n_i\)
\(n_{i+1}\)
If we prune the filter \(j\) of conv layer \(i\)
Then the feature map \(j\) will become all the same
Then we can remove the weights connect to these output neuron
\(n_i\)
\(n_{i+1}\)

(a) \(\frac{\text{norm}}{\text{max norm}}\) of layer i
(b) Acc of direct prune the first \(n\) smallset \(L_1\) norm filter
(c) Retarin of (b)

Compute L1 norm, pruning strategy of next layer:
1. Use green + yellow
2. Only use green

\(P(x_i) = conv_a(x_i) + conv_{c}(conv_{b}(x_{i}))\)
For residual block, \(conv_{a}\) & \(conv_{b}\) can be pruned without restrictions.
\(conv_{c}\) follow the \(conv_{a}\)'s output structure.
a
b
c



Prune small L1 norm
> Random prune
> Prune from largest norm


Regularization
- DSD: Dense-Sparse-Dense Training for Deep Neural Networks
- Exploring the Regularity of Sparse Structure in Convolutional Neural Networks
- Structured pruning of deep convolutional neural networks

Cited By 128 in 2021 Aug 12



Results

Results

Results

Results

Results


Cited By 168 in 2021 Aug 12






Cited By 459 in 2021 Aug 12

Quantization
- GEMMLOWP
(general matrix multiplication low precision) - "Conservative" Quantization: INT8
- Ristretto
- Some Tricks
"Aggressive" Quantization: INT4 and Lower - Quantization-Aware Training
- NOT IN DISTILLER
- Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding

8-bit : [0, 1, 2, ...., 255]








int8



int 8
int 8 x int8 => int 16
\(\sum\) int 16 => int32
\(=\)



"Conservative" Quantization: INT8
How to register the scale of bias/weights/activations?
Example for how to get scale

Relu 6
scale = \(\frac{6}{255}\)

Matrix
scale = \(max_{i,j}(a_{i,j})\) - \(min_{i,j}(a_(i,j))\)

Linear Activation
Feed some data on/offline, then monitor the value of max-min in hidden layer output
For more detail

Cited By 1040 in 2021 Aug 12


$$a \times (q_i+b)$$
$$c \times (q_i+d)$$


Cited By 163 in 2021 Aug 12

Ristretto





Some Tricks
"Aggressive" Quantization: INT4 and Lower
- Training / Re-Training
- Replacing the activation function
- Modifying network structure
- First and last layer
- Mixed Weights and Activations Precision
I skip this part, since it is too detail. :(
Quantization-Aware Training

Pseudo quantize in forward pass .
Do normal backward pass.

Cited By 5574 in 2021 Aug 12



Huffman Coding
most/least
frequent token with
shortest/longest
binary codes
for smaller storage
E.g.
A : 100, B:10, C:1, D:1
All 2bits : 2 x (100+10+1+1) = 224 bits
0/10/110/111 (1/2/3/3 bits)
100+20+3+3 = 126 bits

Knowledge Distillation
- Distilling the Knowledge in a Neural Network
-
NOT IN DISTILLER
From (2020 May) [TA 補充課] Network Compression (1/2): Knowledge Distillation (由助教劉俊緯同學講授)- Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer
- Relational Knowledge Distillation

Cited By 6934 in 2021 Aug 12


Teacher's prob : p
Student's prob : q
Soft Probability




Cited By 876 in 2021 Aug 12



Cited By 225 in 2021 Aug 12


Conditional Computation
- Deep Convolutional Network Cascade for Facial Point Detection
- Adaptive Neural Networks for Efficient Inference
-
NOT IN DISTILLER
- SBNet


Cited By 1409 in 2021 Aug 12

CNN Model
Input : Cropped Face
Output : 5 x,y pair (eyes, nose, mouth)


Multi-level input
Level 1 : Whole Face/Upper Face/Down Face
Level 2 : Cropped Left Eye/Right Eye ...
Level 3 : Smaller Crop ...

Cited By 144 in 2021 Aug 12

Note :
- The Deeper the better performance in these cases
- The Deeper the more expensive in these cases
\(\gamma\) : a classifier to determine go to next stage or just use current feature to predict the result

minimize inference time
such that the loss of metric(such as acc, cross entropy, etc.)
Not easy to solve/understand
Now focus on the last layer of early exit


\(T\) : time cost of full model
\(T_4\) : time cost while exit at conv\(_4\)
\(\sigma_4\) : output of conv\(_4\)
\(\tau(\gamma_4)\) : time cost of decision function \(\gamma_4(\sigma_4(x))\)

As a classification problem with sample weight

Oracle Label

Sample Weight


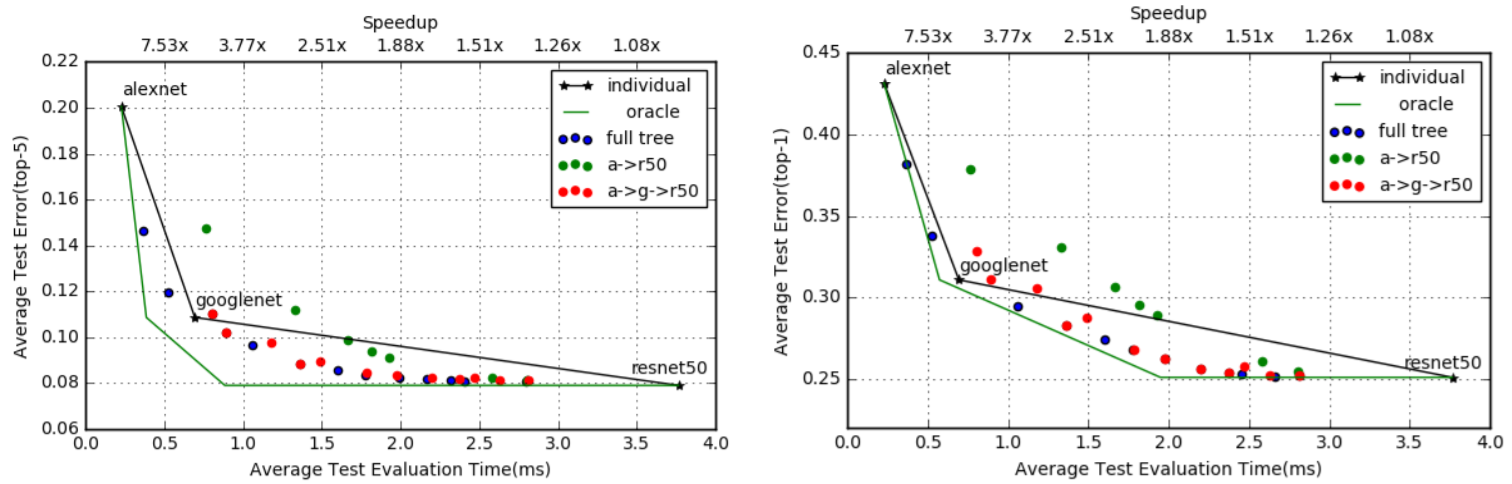
Cited By 103 in 2021 Aug 12


Motivation/Result

Light Model for Mask Generation

Heavy computation for few blocks
Other Resources
- A Survey of Model Compression and Acceleration for Deep Neural Networks
- 張添烜 模型壓縮與加速
- Efficient Inference Engine
- Once For All
- Song Han


Cited By 531 in 2021 Aug 12
Not Cover



Cited By 1919 in 2021 Aug 12
How to solve the irregular pruning & very sparse matrix in ASIC
Application Specific Integrated Circuit

Cited By 277 in 2021 Aug 12









1989 出生