Supervised learning in R:
caret to streamline the model building process
Trang Lê
R Ladies Philly Meetup
December 2, 2019
https://trang.page
@trang1618

- postdoc with Jason Moore
- author, maintainer
- npdr selects features with
nearest-neighbor concepts - stir reliefF on steroid
- privateEC differential privacy for machine learning
- npdr selects features with
- contributor
- tpot
- amateur runner
On the topic of ML, there are many things to talk about...
- challenges: missing data, outlier, bias, overfitting, colinearity, etc.
- unsupervised learning
- feature selection
-
R packages::recipes
- (lots of) clean data
- evaluation metrics
- deep learning
- automated machine learning
- big data
- terminology
adapted from Drew Conway’s Data Science Venn Diagram
hacking
skills
machine learning
math
statistics
domain knowledge
Danger zone!
data
science
traditional research
- ML primers
- Explore
- Ask questions
- Predict
- Visualize
but for today...
Regression
outcome: continuous/quantitative
e.g. How sick is patient?
on a scale of 10
Classification
outcome: discrete/categorical/class
e.g. Is patient sick?
TRUE, FALSE
1, 0
Supervised learning==Predictive modeling
During training...
hyperparameters
parameters
We tune the model's hyperparameters.
As we fit the model to the data, model learns parameters from the data.
Hyperparameters
Parameters
e.g. Elastic net is a type of models
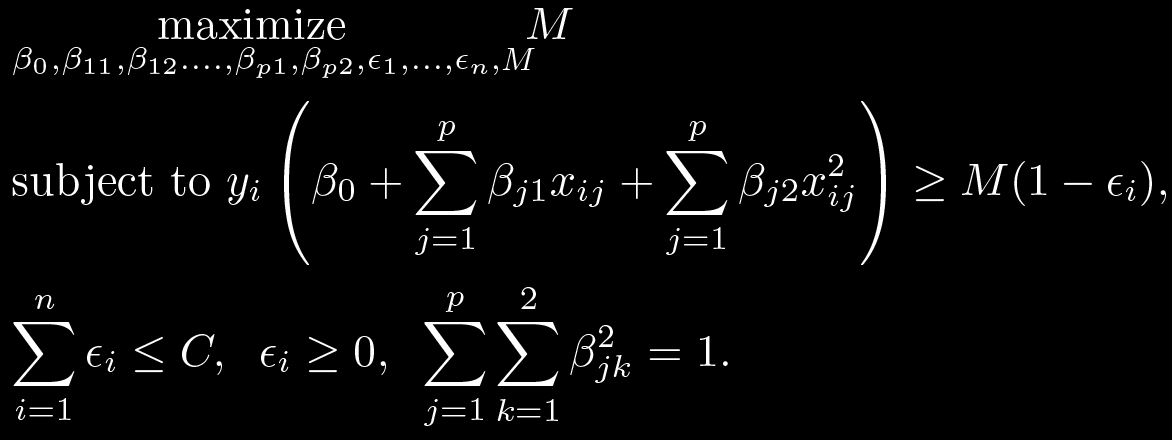
An Introduction to Statistical Learning, 2014
Supervised learning of tabular data
5 fold cross-validation
Data
Train
Test
Train
V
Train
V
Train
V
Train
V
Train
V
observation
sample
individual
subject
variable feature attribute
1. Define sets of model hyperparameters values
2. for each hyperparameter set:
3. for each resampling iteration:
4. Hold out specific samples
5. Fit model on training data
6. Predict the hold out samples
7. end
8. Average performance across hold out predictions
9. end
10. Find optimal hyperparameter set
11. Fit final model to all training data with
optimal parameter set
1. Define sets of model hyperparameters values
2. for each hyperparameter set:
3. for each resampling iteration:
4. Hold out specific samples
5. Fit model on training data
6. Predict the hold out samples
7. end
8. Average performance across hold out predictions
9. end
10. Find optimal hyperparameter set
11. Fit final model to all training data with
optimal parameter set
hyperparameter tuning
rf_fit <- train(
price ~ .,
data = Boston,
method = 'randomForest',
tuneGrid = expand.grid(
mtry = 2:7,
ntree = c(1000, 1500)
),
trControl = trainControl('cv')
)
caret was developed to
-
create a unified interface for predictive modeling with 238 models
- streamline model tuning using resampling
- helper functions for day-to-day model building tasks
- parallel processing for computational efficiency
- enable several feature selection frameworks
Max Kuhn, useR-2010
RStudio primers
- cmd/ctrl + enter execute line
- cmd/ctrl + shift + enter execute chunk
h(g(f(x)))
x %>% f() %>% g() %>% h()
Let's start with an example!
beer/name: John Harvards Simcoe IPA
beer/ABV: 5.4
beer/style: India Pale Ale (IPA)
review/appearance: 4/5
review/aroma: 6/10
review/palate: 3/5
review/taste: 6/10
review/overall: 13/20
review/time: 1157587200
review/text: On tap at the Springfield, PA location. Poured a deep and cloudy orange (almost a copper) color with a small sized white head. Tastes of oranges, light caramel and a very light grapefruit finish. I too would not believe the 80+ IBUs - I found this one to have a very light bitterness with a medium sweetness to it. Light lacing left on the glass.
Let's code!
Additional links
Repo for the workshop: https://github.com/trang1618/rladies-caret
Beer ratings dataset: https://www.kaggle.com/c/beer-ratings/data
Emil Hvitfeldt's post on tidy text and caret: https://www.hvitfeldt.me/blog/binary-text-classification-with-tidytext-and-caret/
Standard hyperparameter grids: https://github.com/EpistasisLab/tpot/blob/master/tpot/config/classifier.py
Elements of Statistical Learning:
https://web.stanford.edu/~hastie/ElemStatLearn/