{AI for hackers}
A quick-start guide on how to get started making using AI and ML



Artificial Intelligence
Machine
Learning
Deep
Learning
Supervised
Learning
Unsupervised
Learning
Reinforcement
Learning
Supervised
Learning
Unsupervised
Learning
Reinforcement
Learning
Computer Vision & Natural Language Processing
Audio data is usually doable, but results are less good
Some rules of thumb
| Mature tech | Heavy duty (forget RPI) |
| Easy to start with | Hard to understand |
Tabular data is most likely classical machine learning
Reinforcement Learning is mainly interesting for games
Some rules of thumb
Unsupervised ML sucks hard for makers
Try to minimize your inputs and outputs
Python is King

C++ is the Workhorse
Google Colab is Queen
Jupyter is the Workhorse

Frameworks

Matlab


Intel OneAPI

ONNX

TensorRT

PyTorch


TensorFlow / Keras
+ Lite!
Scikit
Learn

NVIDIA is the enemy
Ideation


See ML as an advanced SENSOR
Or even replace what a human would manually input
In many cases ML will not be needed, let alone DL
Take any maker project then swap out the sensor / API / human with ML
Do it anyway
¯\_(ツ)_/¯
IF xxxx THEN yyyy
Person is present on the camera feed
Tweet is unfriendly
Audio sample contains dog barks
Build from a cool technology outward
OR
Replace some niche, highly specific code
OR
Let's Make Something!

Problem Statement
Working from home and not working out
Conceptual Solution
Lock PC every hour and force pushups
Conceptual Solution

or proximity sensor?
or weight sensor?
Replace Sensor with ML


The cycle of misery
DATA
MODEL
DEPLOYMENT
DATA
MODEL
DEPLOYMENT
All examples of CV applications

Keypoints
Partial credit: Anthony Sarkis, Standford CS231n
DATA
MODEL
DEPLOYMENT

paperswithcode.com
DATA
MODEL
DEPLOYMENT
DO NOT REINVENT THE WHEEL
Pretrained Models

Transfer Learning

DATA
MODEL
DEPLOYMENT
Pretrained Models
Transfer Learning
🔥Huggingface
🔥Pinto Model Zoo
Tensorflow Hub
TensorFlow Model Garden
OpenVino Model Zoo
Awesome Pytorch List
Awesome TensorFlow Lite
The project itself on Github
DATA
MODEL
DEPLOYMENT
Pretrained Models
Transfer Learning
🔥Huggingface

from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
pipe = pipe.to('cuda')
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
DATA
MODEL
DEPLOYMENT
Pretrained Models
Transfer Learning
DATA
MODEL
DEPLOYMENT
Pretrained Models
Transfer Learning
Reuse pretrained model that's closest to what you want
Retrain only last layers with little data
???
Profit
DATA
MODEL
DEPLOYMENT
Pretrained Models
Transfer Learning
DATA
MODEL
DEPLOYMENT

Found BlazePose on PINTO model zoo
DATA
MODEL
DEPLOYMENT



Monolith
API Server
Hardware
DATA
MODEL
DEPLOYMENT
Monolith
API Server
Hardware
DATA
MODEL
DEPLOYMENT
Monolith
API Server
Hardware
DATA
MODEL
DEPLOYMENT


DATA
MODEL
DEPLOYMENT
DATA
MODEL
DEPLOYMENT

| kp1 | kp2 | kp3 | kp4 | kp5 | kp6 | kp7 | kp8 | kp9 | |
|---|---|---|---|---|---|---|---|---|---|
| x | 2 | 3 | 5 | 7 | 8 | 9 | 0 | -1 | 4 |
| y | 6 | 8 | 1 | 3 | 5 | -4 | -2 | 1 | 0 |
Tabular Data in diguise!
>>> from sklearn.svm import SVC
>>> clf = make_pipeline(StandardScaler(), SVC(gamma='auto'))
>>> clf.fit(X, y)
Pipeline(steps=[('standardscaler', StandardScaler()),
('svc', SVC(gamma='auto'))])
>>> print(clf.predict([[-0.8, -1]]))
[1]DATA
MODEL
DEPLOYMENT
PUSH UP
PUSH DOWN

Classification Annotation
DATA
MODEL
DEPLOYMENT
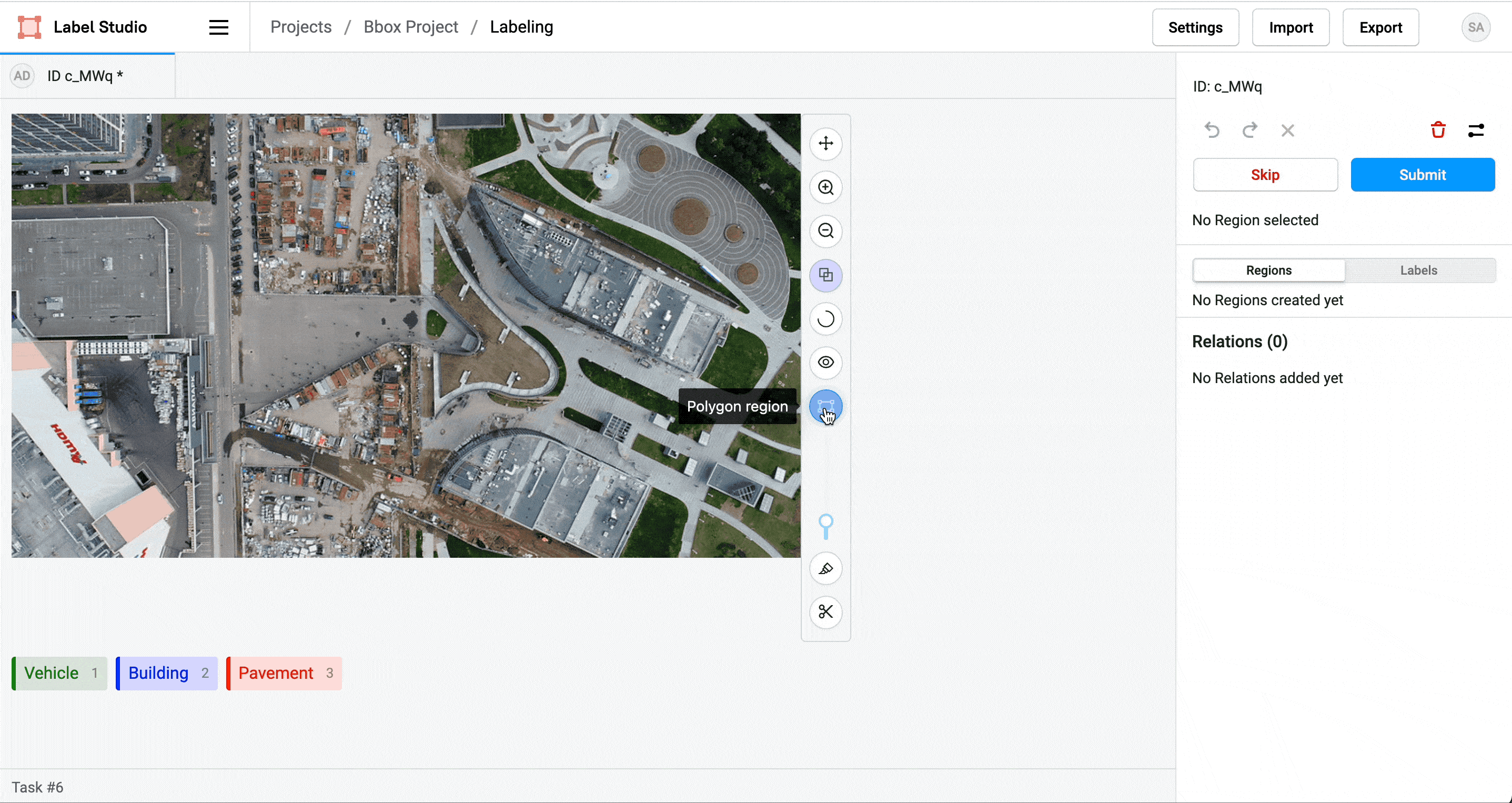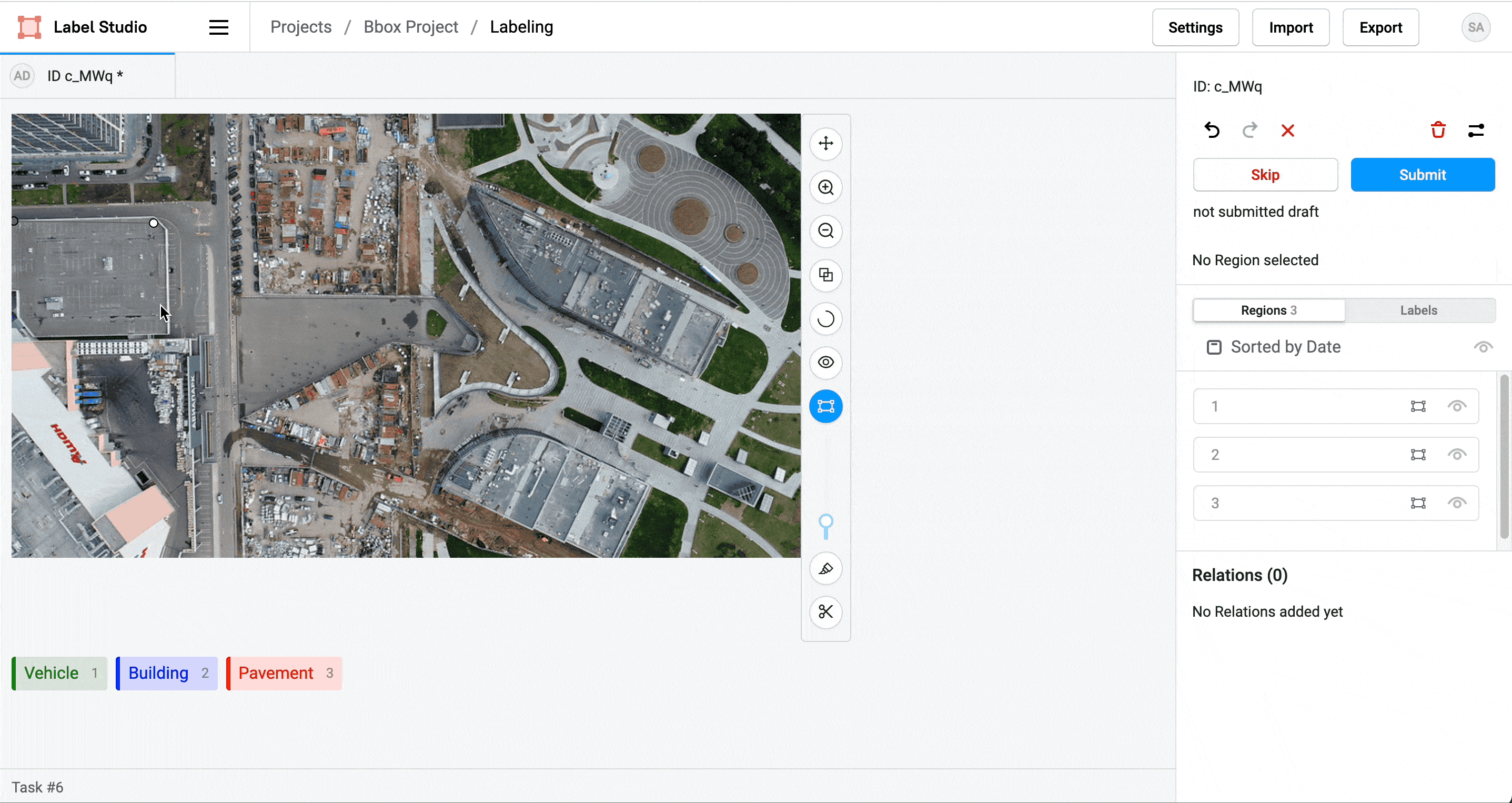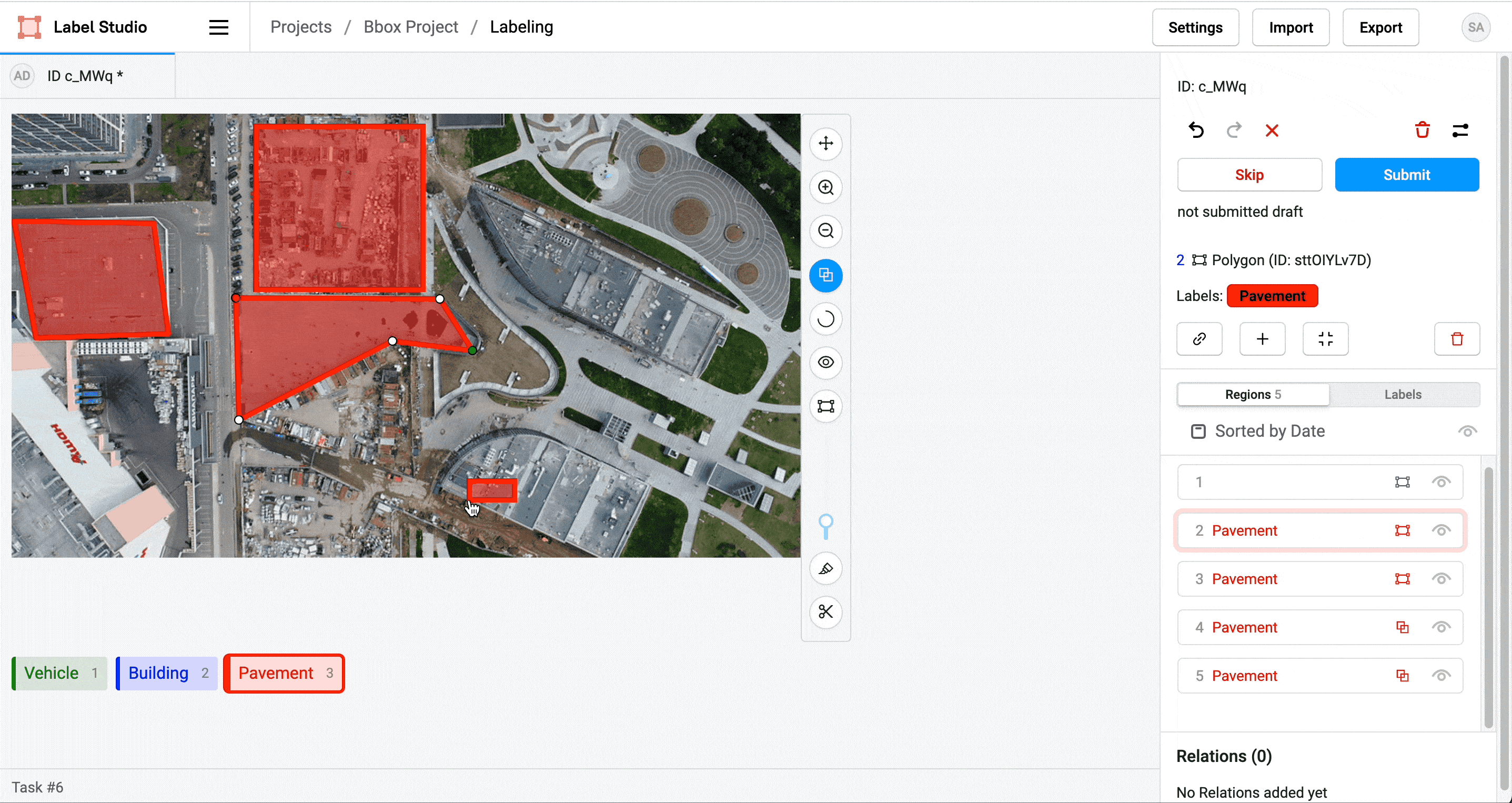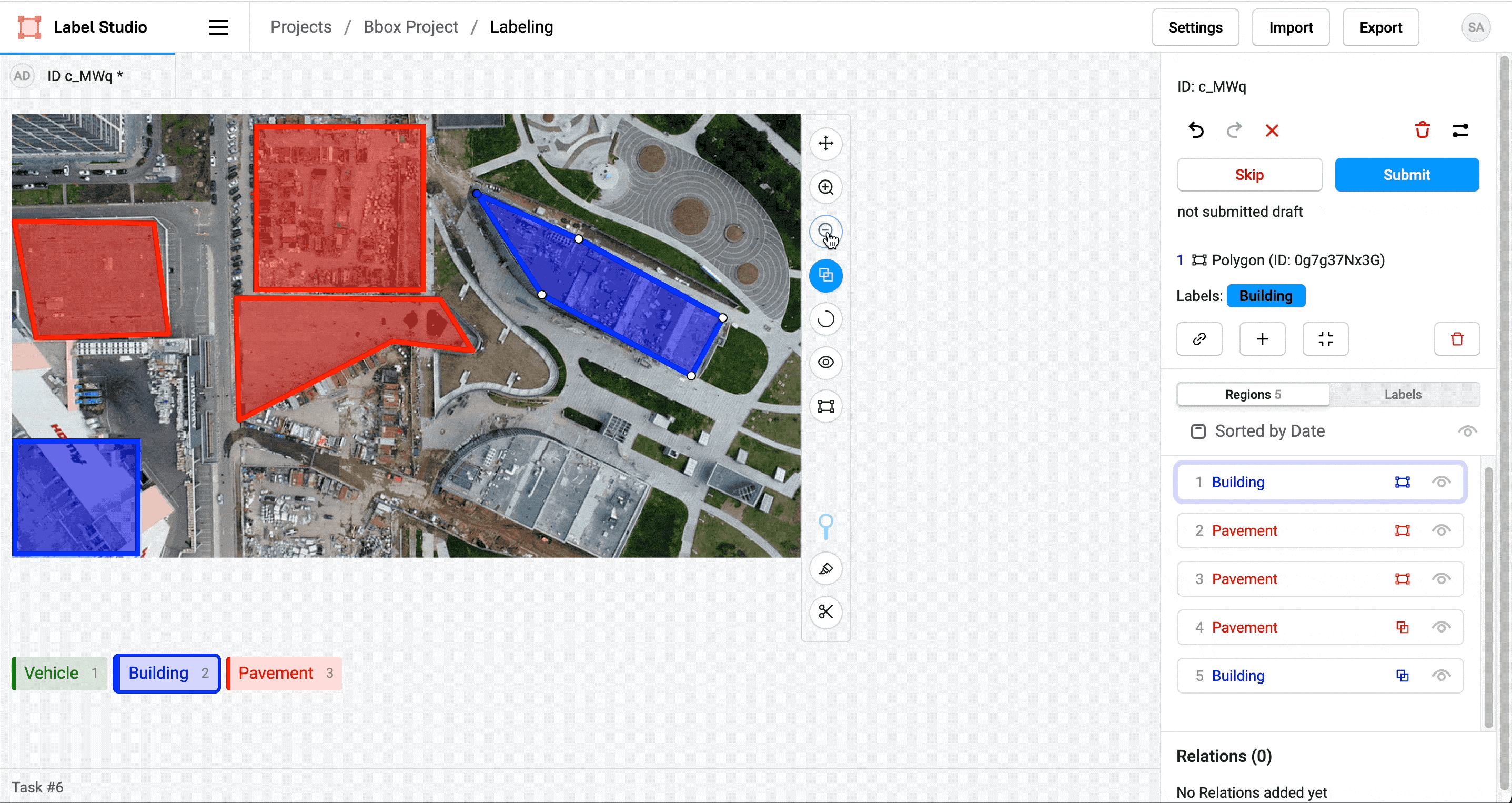
Label Studio labelstud.io
DATA
MODEL
DEPLOYMENT
DIY Labeling Tool
DATA
MODEL
DEPLOYMENT
Sound Familiar??


DATA
MODEL
DEPLOYMENT
DATA
MODEL
DEPLOYMENT
Classical ML doesn't need a model server
class Inference:
def __init__(self):
training_task = Task.get_task(task_id='4cbfaf6975df463b89ab28379b00639b')
self.scaler = joblib.load(training_task.artifacts['scaler_remote'].get_local_copy())
self.model = joblib.load(training_task.artifacts['model_remote'].get_local_copy())
def preprocess_landmarks(self, landmarks):
self.scaler.transform(landmarks)
return landmarks
def run_model(self, landmarks):
predicted = self.model.predict(landmarks)
return predicted
def predict(self, landmarks):
scaled_landmarks = self.preprocess_landmarks(landmarks)
predicted = self.run_model(scaled_landmarks)
return predictedGOOD ENOUGH
The cycle of misery
DATA
MODEL
DEPLOYMENT
Labeling Tool Edition
DATA
MODEL
DEPLOYMENT
Text to speech
DATA
MODEL
DEPLOYMENT
Text to speech
🔥Huggingface
Premade APIs

from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
model = SpeechEncoderDecoderModel.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
processor = Speech2Text2Processor.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
inputs = processor("hey_newline.wav", sampling_rate=16_000, return_tensors="pt")
generated_ids = model.generate(inputs=inputs["input_values"],
attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)DATA
MODEL
DEPLOYMENT
Text to speech
🔥Huggingface
Premade APIs
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
model = SpeechEncoderDecoderModel.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
processor = Speech2Text2Processor.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
inputs = processor("hey_newline.wav", sampling_rate=16_000, return_tensors="pt")
generated_ids = model.generate(inputs=inputs["input_values"],
attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)DATA
MODEL
DEPLOYMENT
Just build it in
This slide structure is already a dumpster fire
Recap
Recap
+ Voice activated labeling tool
Final Result
+ Voice activated labeling tool

Takeaways
Use pretrained models: check Huggingface
Force ML into your project
Label yourself, you don't need much

victor@projectwhy.be
projectwhy.be
@VictorSonck
Check out ClearML!
It's Open Source
It can help