用R爬各式各樣的網站
天下雜誌資料記者 林佳賢
我工作都在做什麼事
- 爬資料
- 清理資料
- 分析資料
一開始,爬資料的時間佔了九成
後來,爬資料的時間慢慢減少到三成
爬資料是資料分析過程中訓練起來最有效的部分
- 對新手來說,爬資料跟魔法一樣
- 但整個過程其實都是SOP
- 熟練之後,爬資料就是執行例行公事
為何用R?
- library很多
- 有好用的IDE
- 爬完資料後的資料清理與分析很好用
爬資料可以大致分成三種
- 靜態url
- 靜態api
- 動態自動瀏覽器
靜態url
- 網址就是內容本身
- 網址會隨著內容作微調
- 爬資料裡最簡單的一種
首先,觀察要爬的網站
這是蘋果日報即時新聞的網站
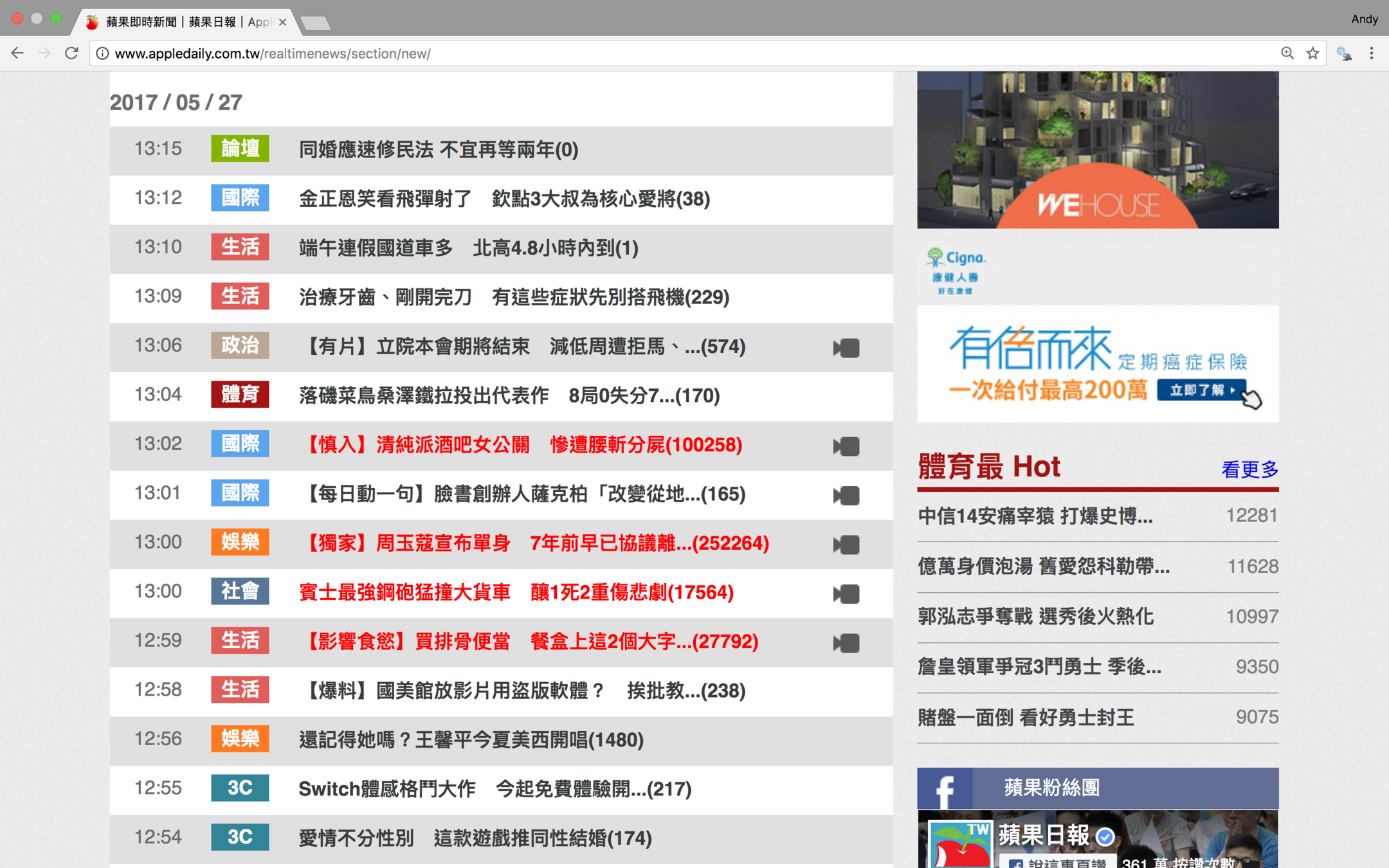
網址長這樣
目標是把每則新聞的標題和內文爬下來
首先要取得所有新聞的超連結
我們需要這些文字的超連結
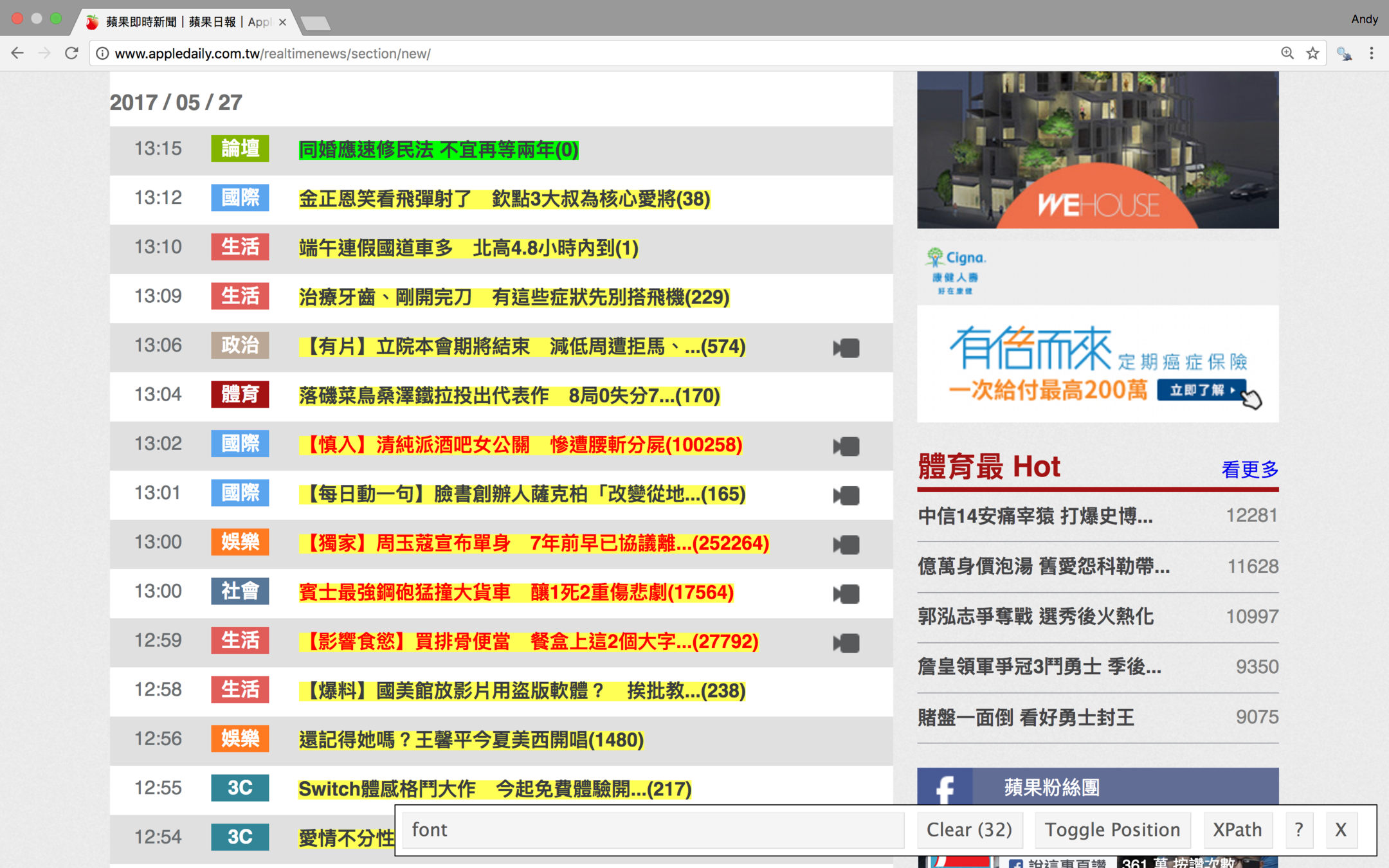
使用Rvest
library(rest)
# 讀取剛剛圖片的頁面
doc <- read_html("http://www.appledaily.com.tw/realtimenews/section/new/")
# 選取所有highlight的文字,這裡使用Chrome的檢查功能,觀察要選取的文字的css selector
article_title <- html_nodes(doc, ".rtddt:not(.blog) a")
# 選取所有要的文字之後,把這些文字的「超連結」拿出來
article_link <- html_attr(article_title, "href")取得的網址長這樣

這樣只是蘋果即時新聞的第一頁
第二頁的網址長這樣
兩頁網址的比較
第二頁就是網址後面多一個2,我們就能自己創造出100頁的網址
使用Rvest
library(rest)
# 生成46頁的即時新聞
base_url <- "http://www.appledaily.com.tw/realtimenews/section/new/"
page_link <- paste0(base_url, 1:46)
# 先生成一個空的串列等等要放全部的文章連結
total_article_link <- c()
# 寫一個迴圈把46頁的文章連結都抓下來
for(j in 1:46) {
doc <- read_html(page_link[j])
...
total_article_link <- c(total_article_link, article_link)
}有了46頁所有文章的連結之後,就來抓個別文章的內容
使用Rvest
library(rest)
# 由於拿到的連結不是完整連結,我們需要在前面加上蘋果日報的網域
base_url <- "http://www.appledaily.com.tw"
# 先生成一個空串列,等等要放文字
total_content <- vector("list", length(total_article_link))
# 寫一個迴圈把所有文章連結跑一遍
for(k in seq_along(total_article_link)) {
true_url <- paste0(base_url, total_article_link[k])
doc <- read_html(true_url)
# 選取文章的區塊
content <- html_node(doc, "#summary")
# 把文章文字拿出來
content_text <- html_text(content)
# 把文章放到先前生成的空串列
total_content[[k]] <- content_text
}這樣就可以把蘋果日報網上的即時新聞內容都爬下來了
靜態api
- 網址不是內容本身
- 要用Chrome的檢查功能才能看到真正的「網址」
- 最重要的是找到真正的網址在哪
這是591租屋網的搜尋結果頁面
第一頁的網址長這樣
第二頁的網址長這樣
兩頁的網址都一樣,可是兩頁的內容明明不一樣啊!
這時候就要打開Chrome的的開發人員工具(command+option+i)
點選Network=>重新整理
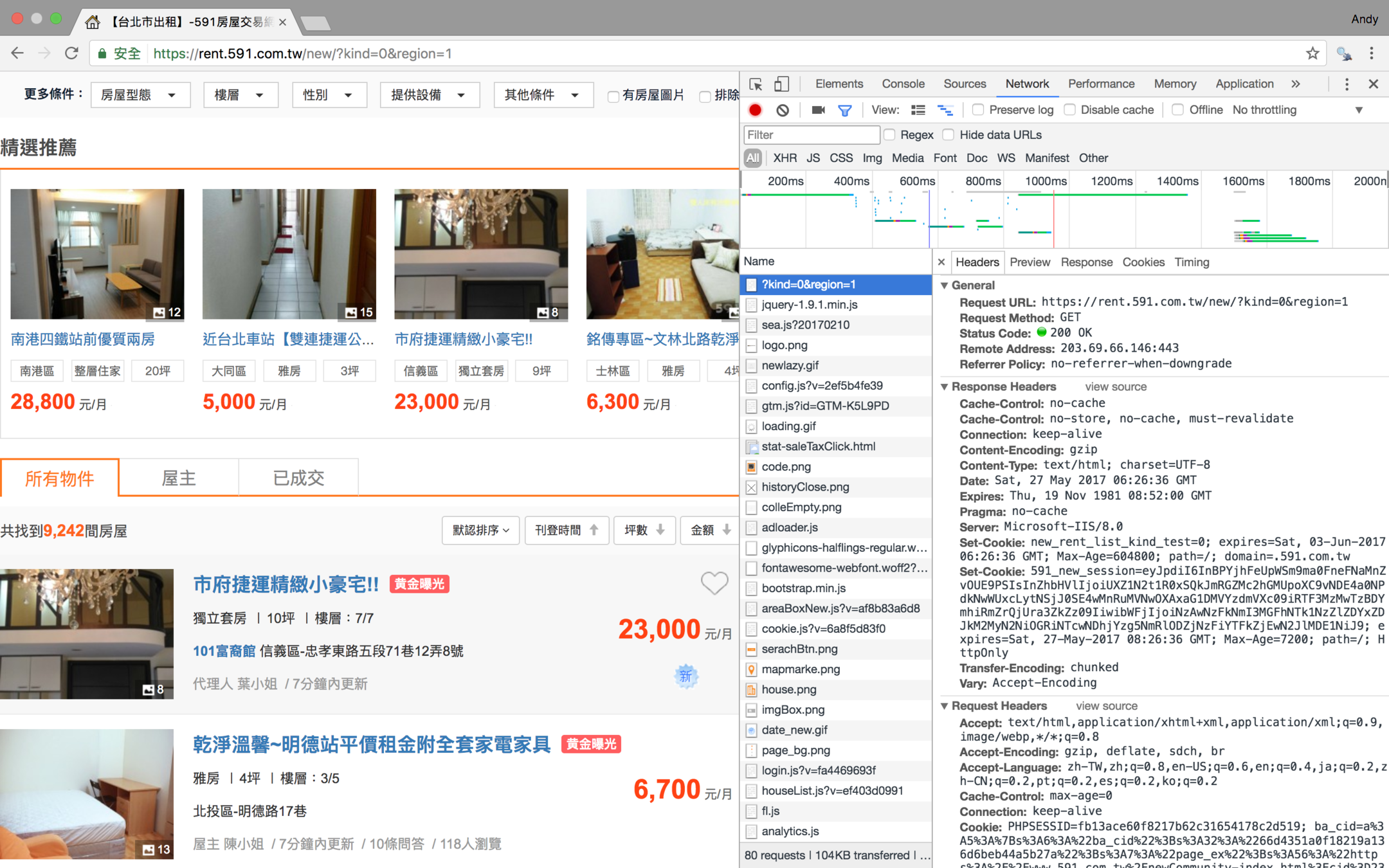
把右上角的地方放大
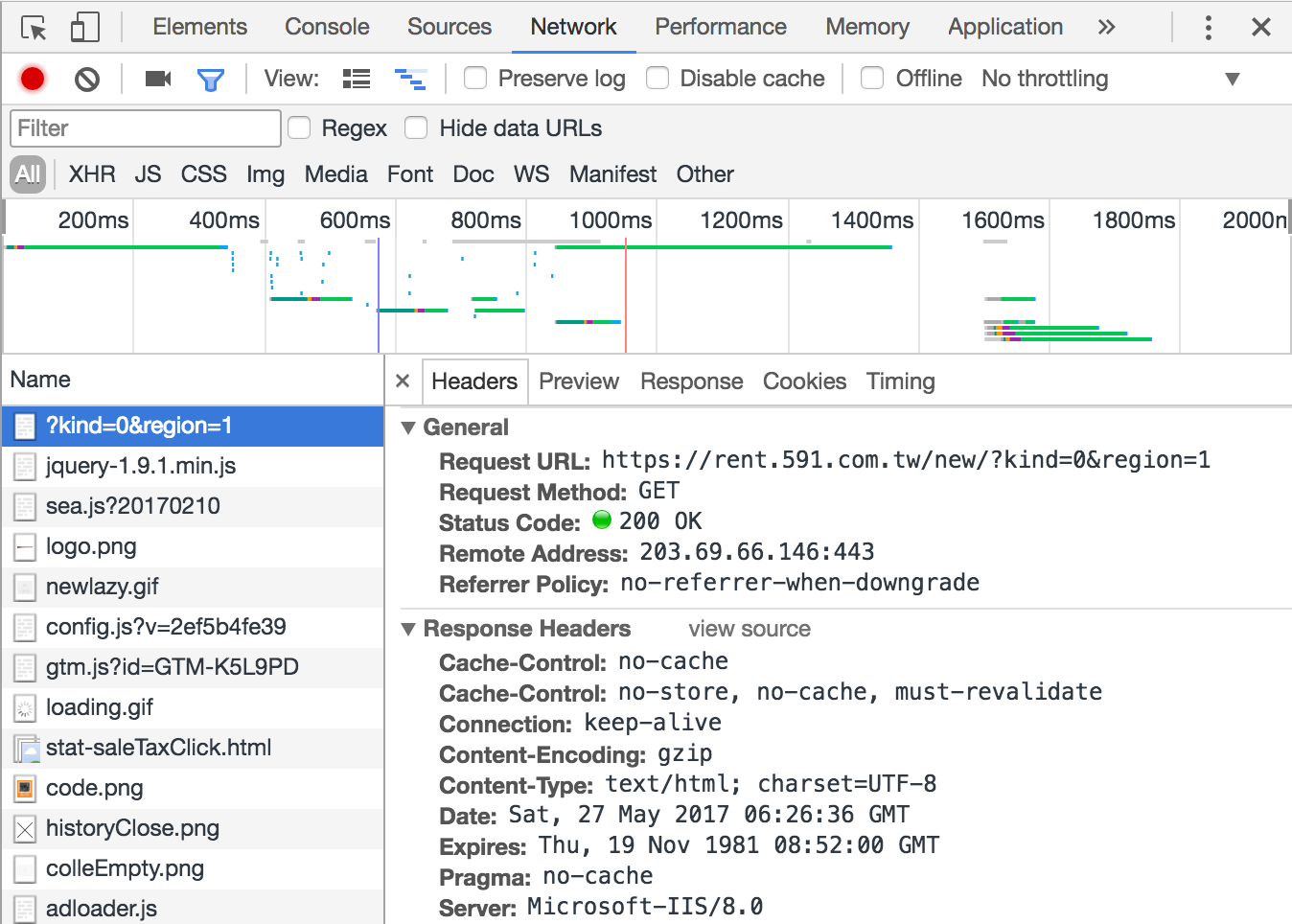
這裡就有真正的網址了
第二頁長這樣
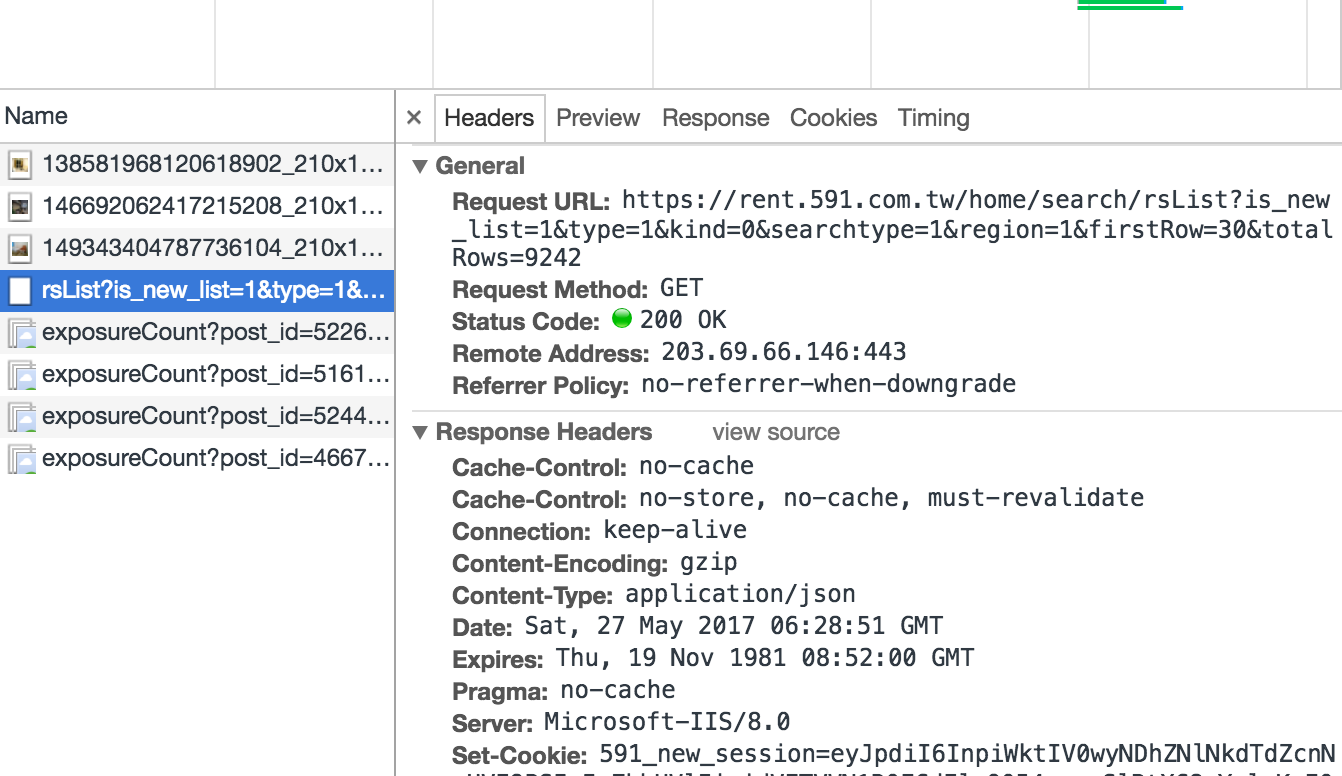
第二頁真正網址長這樣
https://rent.591.com.tw/home/search/rsList?is_new_list=1&type=1&kind=0&searchtype=1®ion=1&firstRow=30&totalRows=9242
第三頁真正網址長這樣
https://rent.591.com.tw/home/search/rsList?is_new_list=1&type=1&kind=0&searchtype=1®ion=1&firstRow=60&totalRows=9246
兩頁比較
https://rent.591.com.tw/home/search/rsList?is_new_list=1&type=1&kind=0&searchtype=1®ion=1&firstRow=30&totalRows=9246
https://rent.591.com.tw/home/search/rsList?is_new_list=1&type=1&kind=0&searchtype=1®ion=1&firstRow=60&totalRows=9246
找到每個頁面真正網址的差異點了!
看一下preview
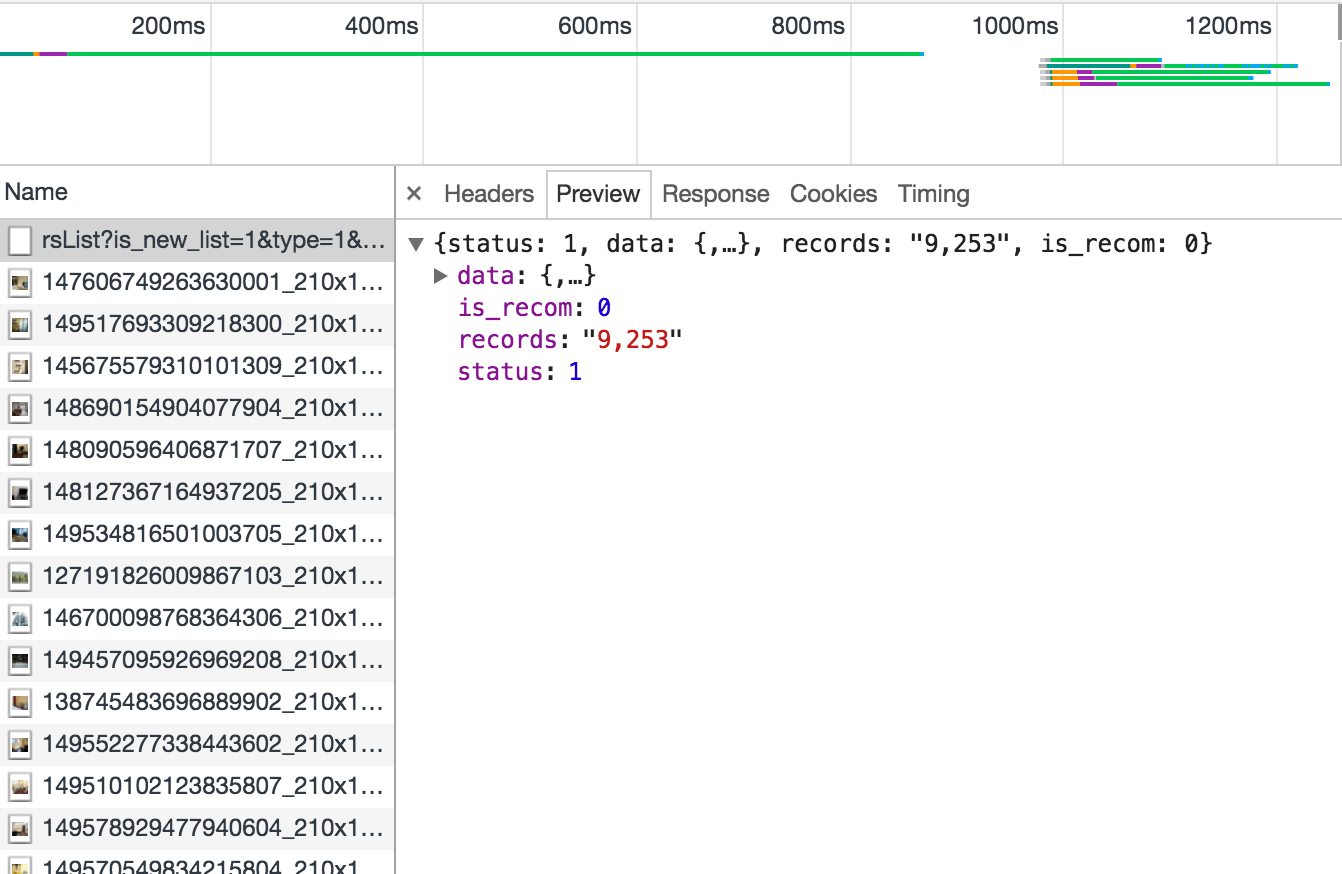
這一次使用jsonlite
# 由於這次抓下來的內容是json格式,我們要使用jsonlite
library(jsonlite)
# 取得真正網址的內容
url <- "https://rent.591.com.tw/home/search/rsList?is_new_list=1&type=1&kind=0&searchtype=1®ion=1&firstRow=0&totalRows=9246"
json_content <- fromJSON(url)
# 把躲在json_content裡面,我們真的想要的租屋資訊拿出來
df <- json_content$data
df <- df$datadf長這樣
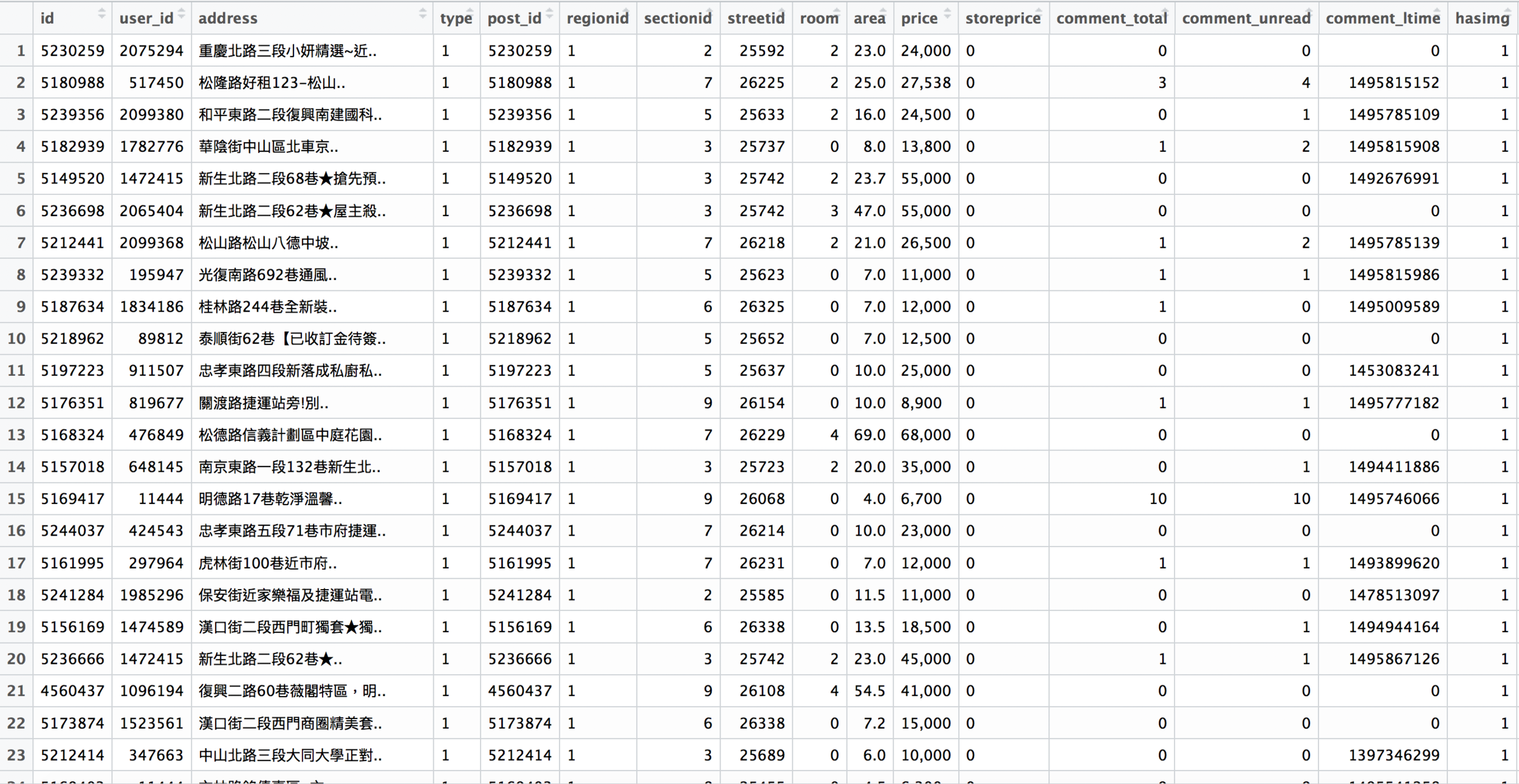
自動生成所有頁面的真正網址
# 先生成間隔30的數列,length.out是數列的長度
steps <- seq(from = 0, by = 30, length.out = 20)
# 把網址中的firstRow數字取代成剛剛生成的數字
total_link <- paste0(url <- "https://rent.591.com.tw/home/search/rsList?is_new_list=1&type=1&kind=0&searchtype=1®ion=1&firstRow=",
steps,
"&totalRows=9246")
# 預先生成存放每一頁租屋資訊的串列
total_rent <- vector("list", length(total_link))
# 寫一個迴圈把20個頁面都跑一次
for(i in seq_along(total_link)) {
json_content <- fromJSON(total_link[i])
df <- json_content$data
df <- df$data
total_rent[[i]] <- df
}最後就能得到600筆租屋資訊
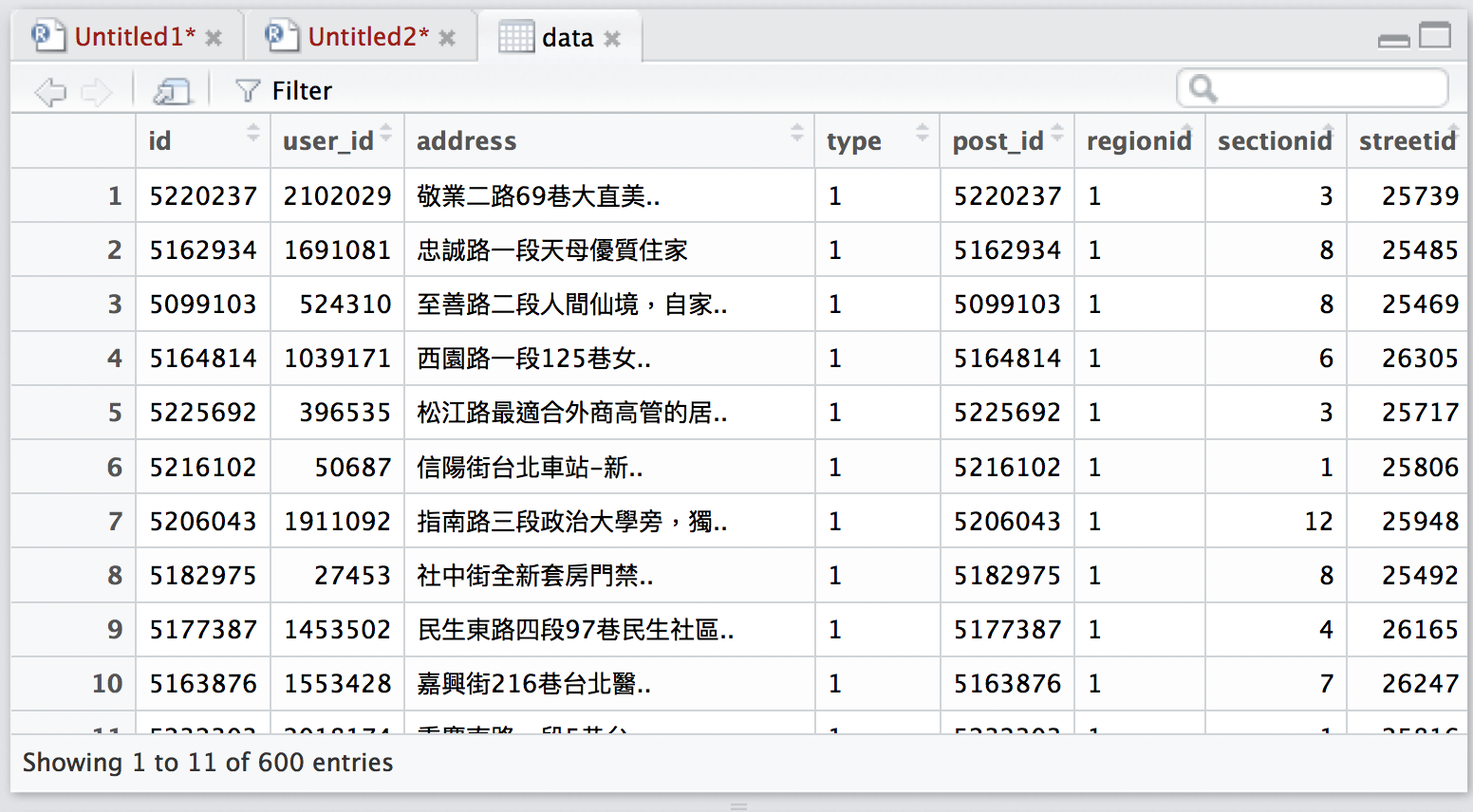
靜態api的重點
- 要打開瀏覽器的開發工具才能找到
- 通常是重整頁面之後最上面的項目
- 拿下來的東西有可能是json等格式
動態自動瀏覽器
- 用開發工具找到的東西很奇怪
- 網站方會擋非瀏覽器使用者
- 通常是資料庫的形式
聯合徵信的住宅貸款統計查詢網
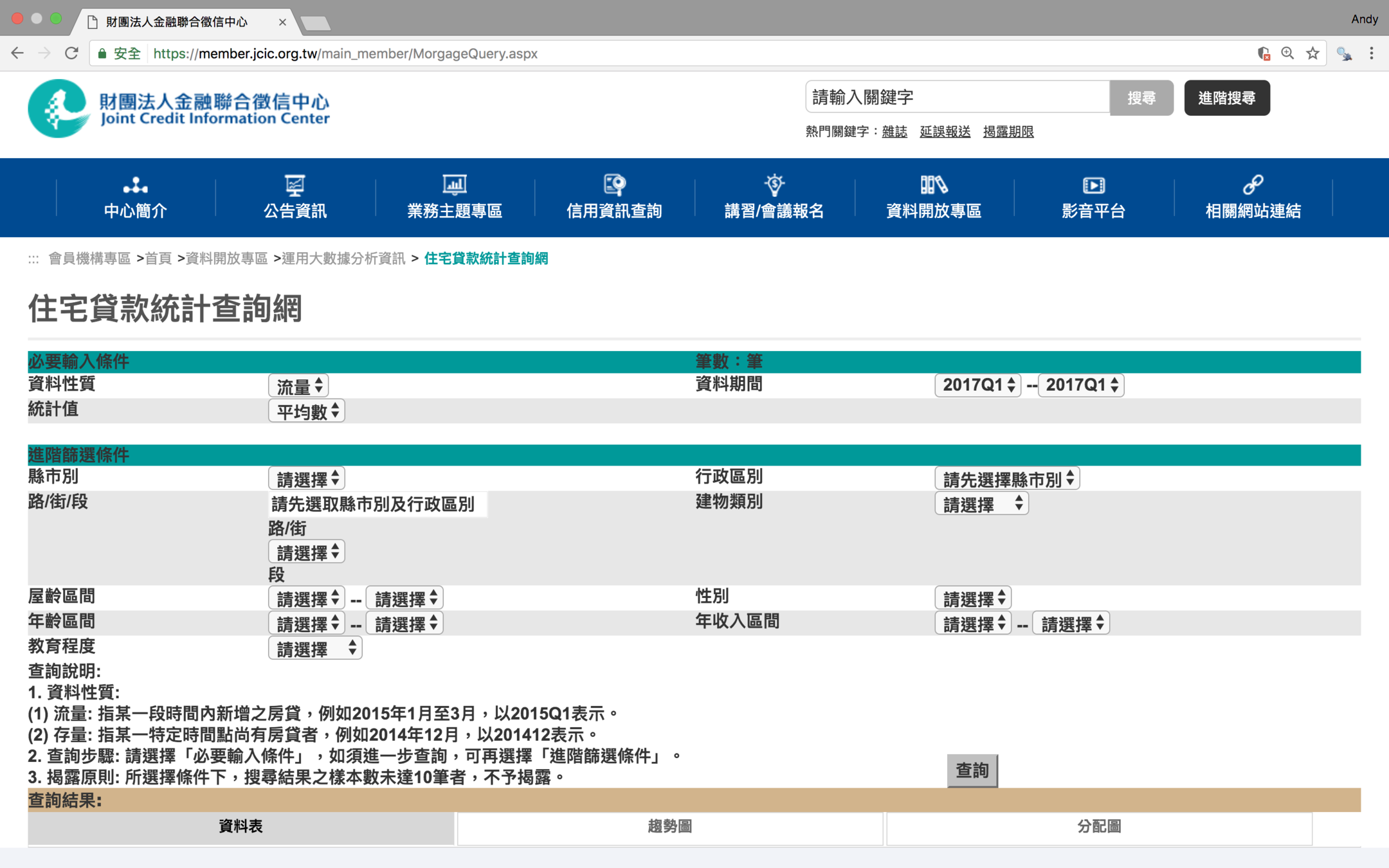
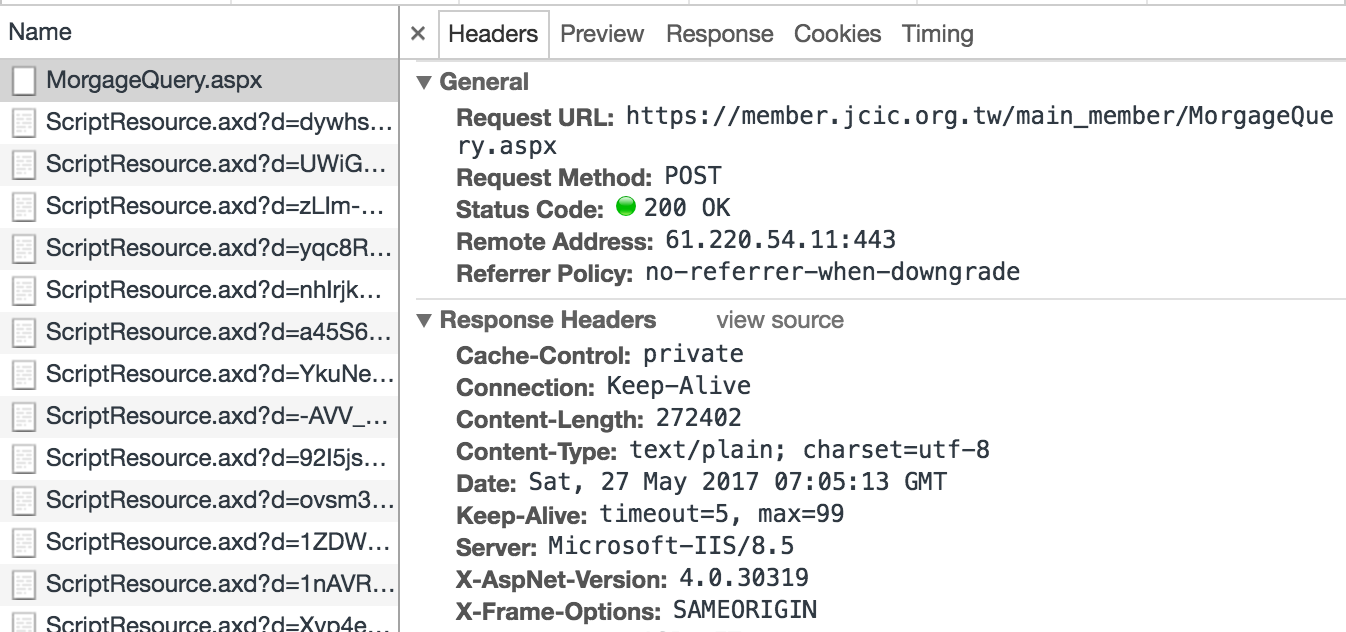
按下查詢後,開發工具顯示是一個POST,代表需搭配相關參數
往下拉到Form Data,看到一堆怪東西
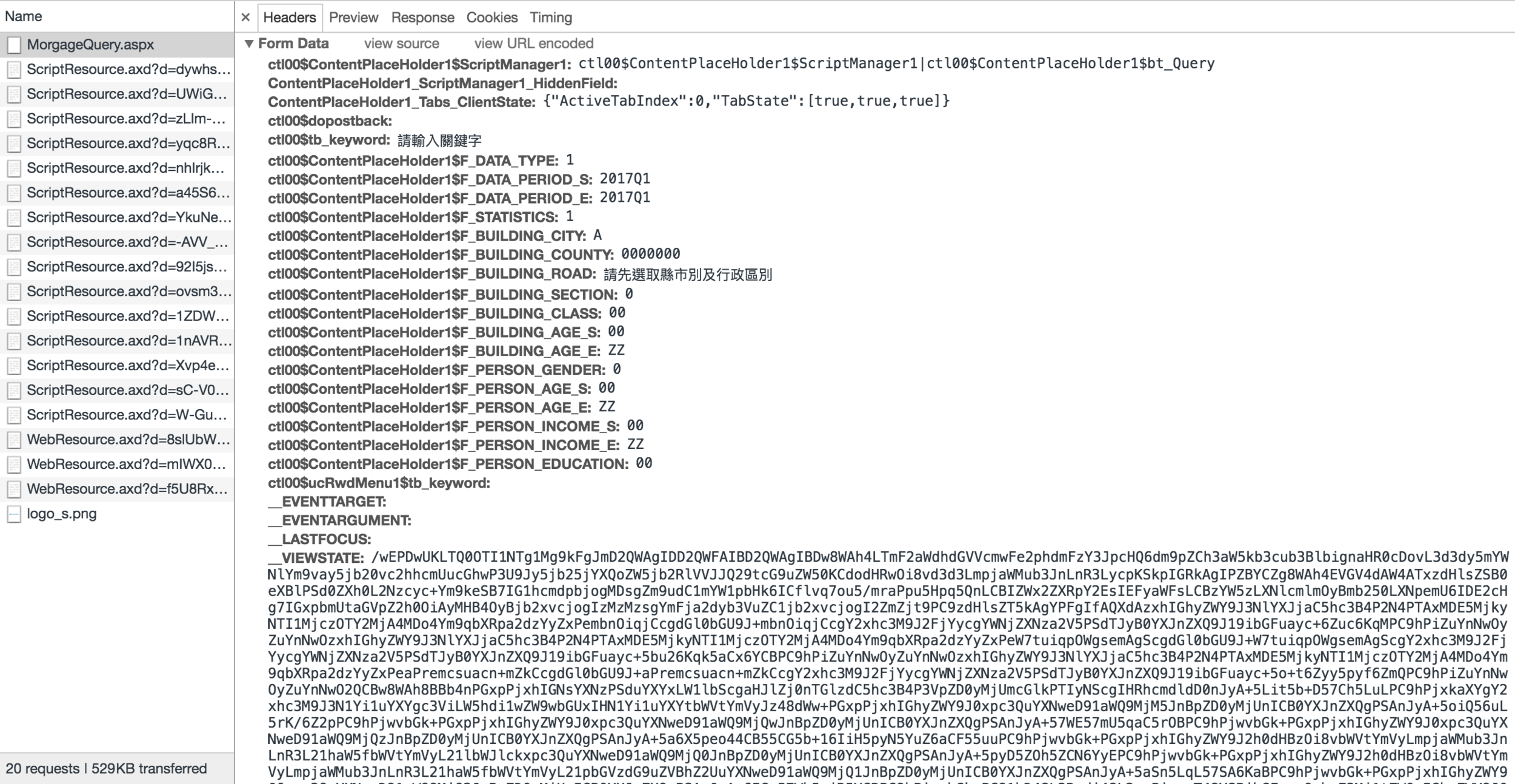
看到一堆看不懂的怪東西的話,代表這個網頁的生成不是用正常邏輯
這次要使用Rselenium
# RSelenium是R用來模擬瀏覽器行為的package
library(RSelenium)
# 在使用RSelenium之前,需要先下載相關驅動
# 下載之後,把驅動程式放到電腦的PATH位置
# RSelenium可以使用許多種驅動,我使用的是Phantomjs
# 啟動驅動程式
pJS <- phantom()
# 手動等五秒讓驅動啟動
Sys.sleep(5)
# 開啟遠端瀏覽器,這裡使用的是phantomjs瀏覽器
remDr <- remoteDriver(browserName = 'phantomjs')
# 打開瀏覽器
remDr$open()接下來做的每一件事,都是模擬平常使用瀏覽器的動作
# 開啟網頁
remDr$navigate("https://member.jcic.org.tw/main_member/MorgageQuery.aspx")
# 看一下網頁的名稱
remDr$getTitle()[[1]]
# 選取一個要素
webElem <- remDr$findElement(using = 'css selector', "#ContentPlaceHolder1_F_BUILDING_CITY > option:nth-child(1)")
# 點它
webElem$clickElement()
...
# 最後在完成所有動作之後,可以抵達我們要的網頁狀態
# 在取得當前頁面的原始碼,並用rvest進行處理
df <- remDr$getPageSource()[[1]]簡單的說,RSelenium就是用電腦,自動做滑鼠和鍵盤做的事
可以想像成玩線上遊戲的時候,寫外掛腳本自動練功打怪
可以模擬的動作很多
- 在空白框裡輸入文字
- 在下拉選單裡選擇選項
- 點擊搜尋按鈕
- 複製文字
- 螢幕截圖
透過模擬瀏覽器的行為,就不需要開發工具找真正網址,網站方也察覺不到我們
但是缺點是:很麻煩!
這些程式碼,只是下載一個表格
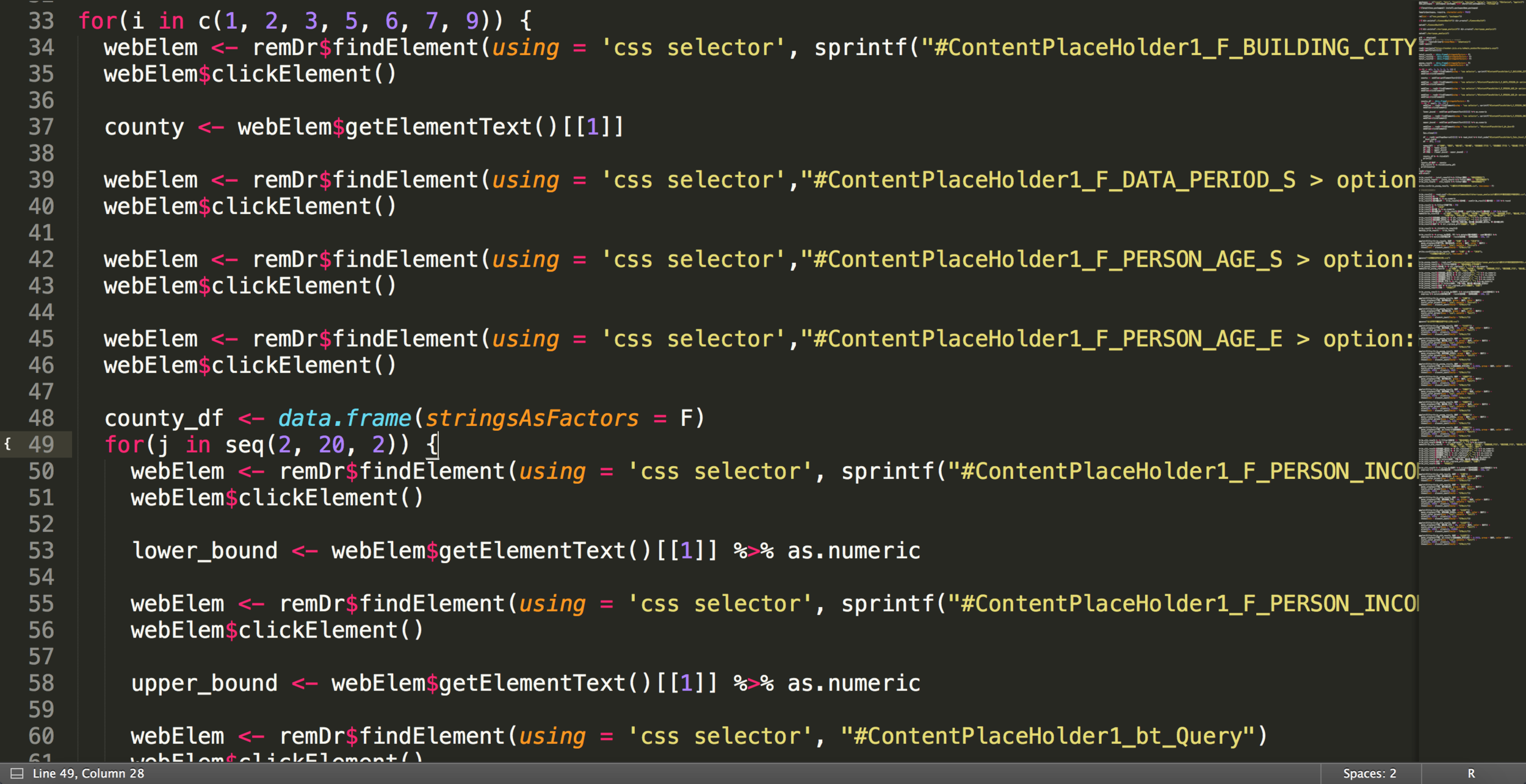
平常用滑鼠點起來很快,要用程式實現,就要找老半天
所以動態自動瀏覽器,是不得已才採取的手段
三種爬資料方式
- 靜態網址最簡單,也最少遇到
- 靜態api最常見,變化也最多
- 動態自動瀏覽器才能解決的情況不多,但遇到的話就要有心理準備
但最重要的是,不要把別人的網站塞爆
Q & A
用R爬各式各樣的網站
By Andy Lin
用R爬各式各樣的網站
for iThome Tech Talk

