Druid.io: магия лямба-архитектуры
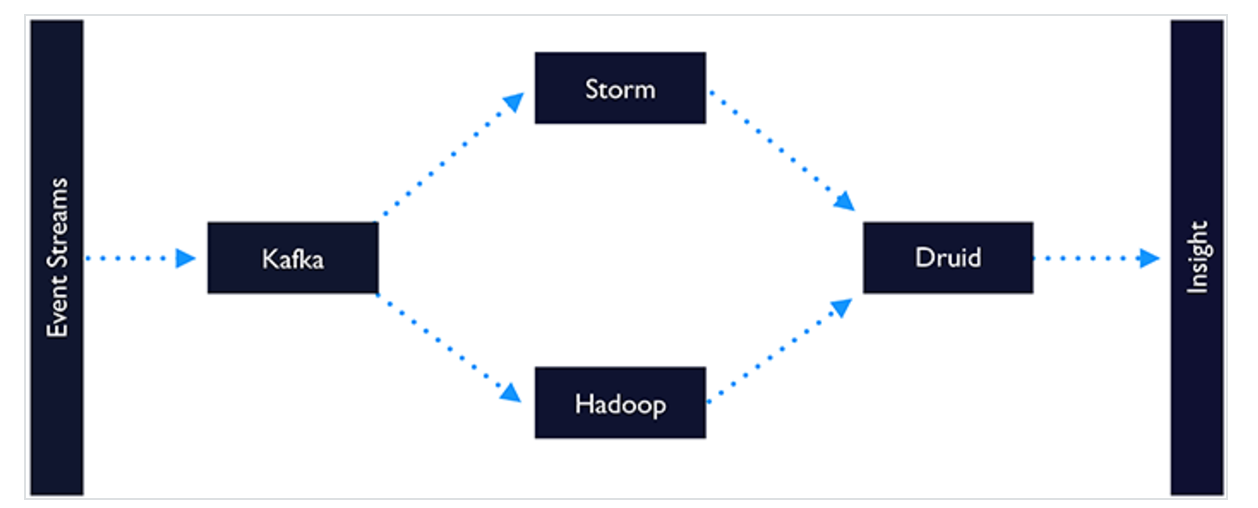
Hadoop
OLAP
Kafka
Druid





Предпосылки
- Много данных
- Очень много данных
- Нужно быстро отвечать на запросы
Задача: графики посещения web-страниц в реальном времени
- Может быть сотни и тысячи событий в минуту
- Нужна агрегация по ~10 измерениям, их количество будет увеличиваться
- Пользователи хотят видеть новые данные сразу
- В поступающих данные содержится не вся нужная информация
| date | user | url | browser | os | device |
|---|---|---|---|---|---|
| 12.03.17 10:01 | 1 | www.ya.ru | Opera | Windows | DT |
| 12.03.17 13:44 | 4 | www.st.com | UC | Android | Samsung |
| 12.03.17 15:23 | 2 | www.ya.ru | Safari | iOS | iPhone |
Традиционный подход: реляционные БД
- Слишком много данных чтобы работать напрямую
- Вычислять промежуточные view - замедление в доставке данных
- Для быстрой работы запросов нужны индексы по каждому полю
- И даже так это слишком медленно...
- А еще сложно добавить логику по обогащению данных
Альтернативный подход: NoSQL
- Обычно поддерживают поиск только по одному ключу
- Проблемы с надежностью
- Все еще сложно добавить логику по обогащению данных
Альтернативный подход: MapReduce
- Легко добавлять логику!
- Но медленные ответы на запросы
... есть ли магический молоток?
Лямбда-архитектура!
Nathan Marz
- Быстрые ответы на запросы
- Пользователь сразу видит новые данные
- Надежно
- Просто
Так бывает???
Идея
- Три основных слоя приложения: Batch Layer, Serving Layer, Speed Layer
- Batch Layer и Speed Layer дополняют друг друга в обработке данных
- Данные возвращаются пользователю с помощью Query Layer
Ключевая предпосылка
Данные
Raw Data
Все остальное
V1 = F(Raw Data)
V2 = F(V1)
...
| Пользователь А посетил страницу ххх в 22:30 12.03.17 |
| Пользователь B посетил страницу yyy в 14:15 13.03.17 |
| Пользователь А посетил страницу yyy в 15:27 13.03.17 |
| ... |
| Пользователь | Страница | Посещений |
|---|---|---|
| A | xxx | 1 |
| B | yyy | 1 |
| A | yyy | 1 |
| Страница | Посещений |
|---|---|
| xxx | 1 |
| yyy | 2 |
Raw Data
V1
V2
Важно
- Raw Data неизменны и верны по умолчанию
- Все остальные представления вычисляются на основе Raw Data
Алгоритмы: recomputational vs incremental
Recomputational: чтобы учесть новые данные, нужно повторить вычисления с нуля
Incremental:
новые данные можно добавлять без перевычисления
(a_1 + a_2 + ... + a_n) / n
(S_{n-1} + a_n) / n
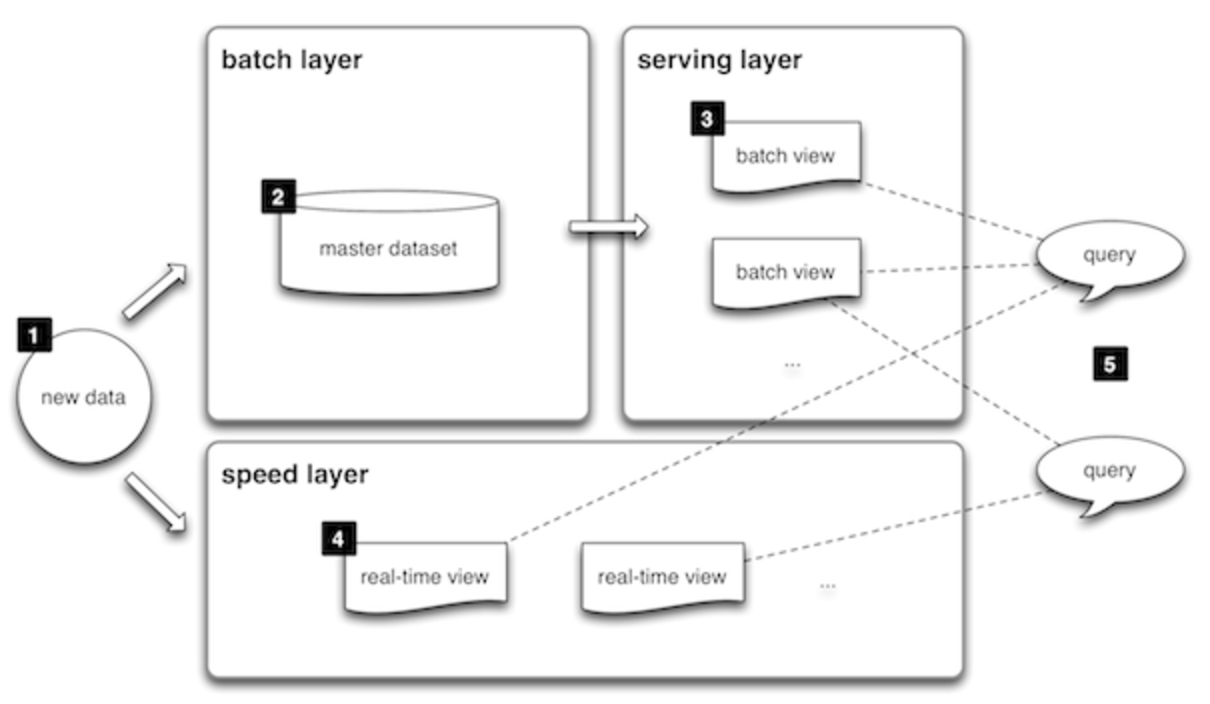
Batch Layer
- Raw Data хранятся в неизменном виде и только добавляются новые
- Необходимые представления регулярно перевычисляются с помощью recomputational алгоритмов
- Ошибку в алгоритме легко исправить, перезапустив вычисления
хранит данные и вычисляет представления на основе полных данные
Serving Layer
- Работает только с данными внутри нужного представления
- Нет необходимости обновления данных кроме полной перезаписи
быстро отвечает на запросы к данным
Speed Layer
- Использует инкрементальные алгоритмы для той же задачи, что и batch layer
- Результаты работы выбрасываются после обработки батча
инкрементально обновляет новые поступающие данные до обработки батча
Query Layer
- Обращается к Serving Layer и Speed Layer за данными
- Агрегирует результаты
отвечает на запросы пользователей
Цена
- Затраты памяти
- Затраты вычислительных ресурсов
- Дублирование логики
- Зоопарк технологий
"Big Data isn't called "Big Data" for nothing" (c)
Druid.io
- Хранилище данных для работы с OLAP-запросами
- Оптимизирован для работы с большим количеством данных
- Новые данные доступны сразу
- Поддерживает идеи лямбда-архитектуры
- Open sourced by Metamarkets in 2012
- Текущая версия - 0.9.2
Важные моменты
- Хранит данные только в агрегированном виде
- Данные хранятся в виде immutable сегментов
- Column store
- Использует инвертированный индекс
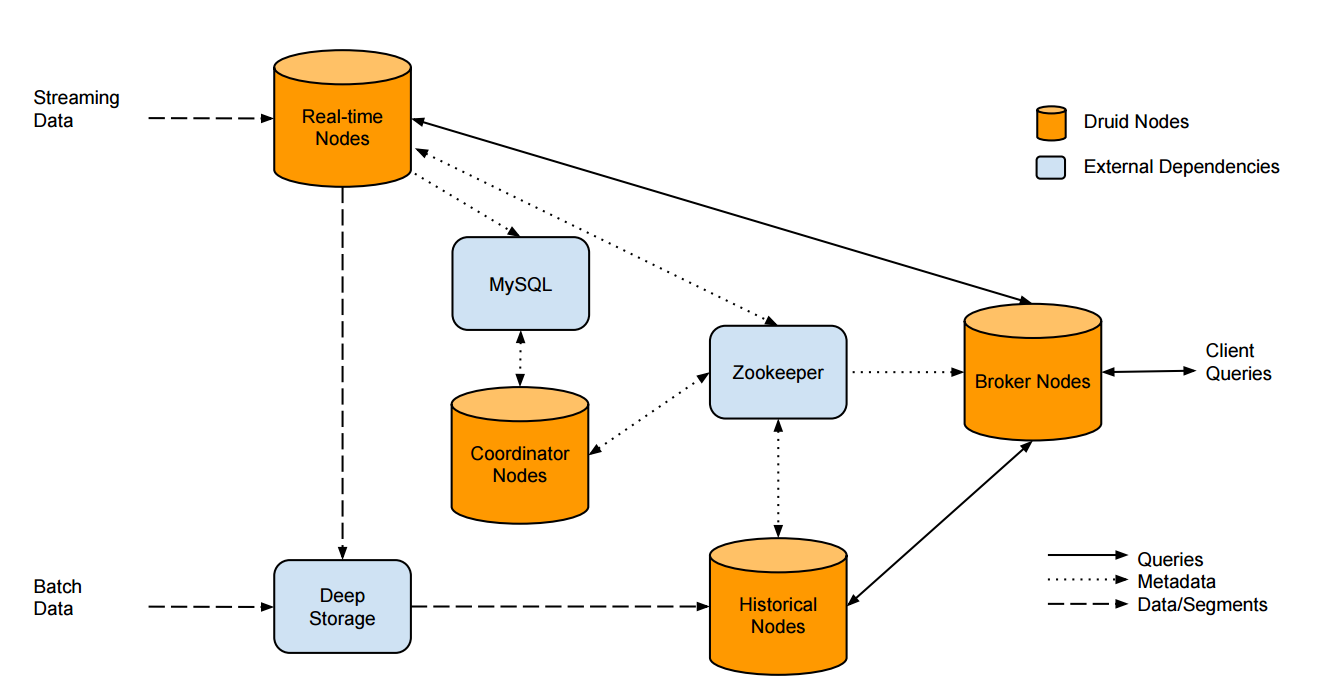
Архитетура
- Состоит из нескольких типов нод:
- Historical Node
- Realtime Node
- Broker Node
- Coordinator Node
- Indexing Service
- Может быть несколько инстансов каждого типа
- Для обмена данными используется zookeeper
- Данные хранятся в deep storage
- Информация о сегментах хранится в metadata storage
Historical Node
- Загружает сегменты в память по команде
- Отвечает на запросы по сегменту
- Выгружает сегменты из памяти по команде
- Использует deep storage в качестве источника сегментов
Realtime Node
- Непрерывно получает новые данные
- Данные хранятся в памяти и периодически дампятся на диск
- По окончанию периода формируется сегмент и выгружается в deep storage
Broker Node
- Отвечает на запросы пользователей
- Разбивает запрос по сегментам и обращается к соответствующим нодам
- Используется кэш
Coordinator
- Отвечает за балансирование нагрузки
- Запускается периодически
- Отдает команды на загрузку/выгрузку сегментов
- Данные о сегментах хранятся в metadata storage
Indexing Service
- Отвечает за управление сегментами (создание/слияние/удаление)
- Основное применение - батч-загрузка данных
- Данные могут загружаться в виде файла или из hdfs
- Состоит из нескольких компонентов: Overlords, Middle Managers и Peons
{
"queryType": "groupBy",
"dataSource": "sample_datasource",
"granularity": "day",
"dimensions": ["country", "device"],
"filter": {
"type": "and",
"fields": [
{ "type": "selector", "dimension": "carrier", "value": "AT&T" },
{ "type": "or",
"fields": [
{ "type": "selector", "dimension": "make", "value": "Apple" },
{ "type": "selector", "dimension": "make", "value": "Samsung" }
]
}
]
},
"aggregations": [
{ "type": "longSum", "name": "total_usage", "fieldName": "user_count" },
{ "type": "doubleSum", "name": "data_transfer", "fieldName": "data_transfer" }
],
"intervals": [ "2012-01-01T00:00:00.000/2012-01-03T00:00:00.000" ],
"having": {
"type": "greaterThan",
"aggregation": "total_usage",
"value": 100
}
}[
{
"version" : "v1",
"timestamp" : "2012-01-01T00:00:00.000Z",
"event" : {
"country" : <some_dim_value_one>,
"device" : <some_dim_value_two>,
"total_usage" : <some_value_one>,
"data_transfer" :<some_value_two>,
"avg_usage" : <some_avg_usage_value>
}
},
{
"version" : "v1",
"timestamp" : "2012-01-01T00:00:12.000Z",
"event" : {
"dim1" : <some_other_dim_value_one>,
"dim2" : <some_other_dim_value_two>,
"sample_name1" : <some_other_value_one>,
"sample_name2" :<some_other_value_two>,
"avg_usage" : <some_other_avg_usage_value>
}
},
...
]В нашем проекте
- Druid хранит данные и отвечает на запросы
- Данные обогащаются в процессе batch-обработки
- Map Reduce для обогащения данных и подготовки файлов
- HDFS как deep storage
- Kafka для realtime загрузки данных
В итоге
- Подход действительно работает
- Большие требования по памяти и ресурсам
- Сложно управлять системой
- Много подводных камней в реализации
Ссылки
- http://lambda-architecture.net
- http://druid.io
- Big Data: Principles and best practices of scalable realtime data systems
Спасибо за внимание =)
lambda-architecture
By annaalkh

