Cassandra data modeling 101
the ring
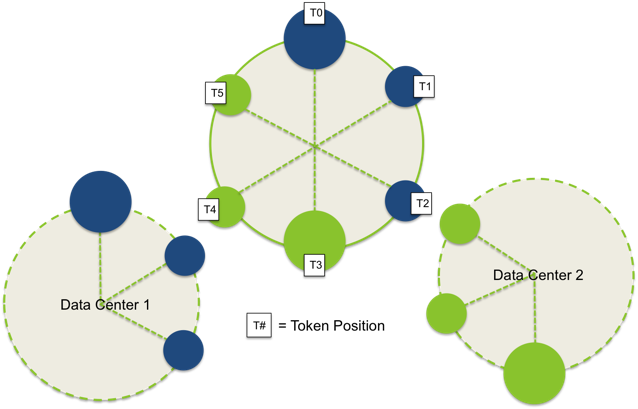
KEYSPACES & REPLICATION
CREATE KEYSPACE xdcr WITH replication = {
'class': 'SimpleStrategy', 'replication_factor': 2
};
01_simple_replication_strategy.cql
- SimpleStrategy
- only single data center
- places the first replica on a node determined by the partitioner.
- additional replicas are placed on the next nodes clockwise in the ring without considering topology (rack or data center location)
keyspaces & replication 2
CREATE KEYSPACE xdcr WITH replication = {
'class': 'NetworkTopologyStrategy',
'datacenter_1': 1,
'datacenter_2': 2
};
NetworkTopologyStrategy
02_network_replication_strategy.cql
- cluster deployed across multiple data centers
- specify how many replicas you want in each data center
- places replicas in the same data center by walking the ring clockwise until reaching the first node in another rack
- attempts to place replicas on distinct racks because nodes in the same rack (or similar physical grouping) often fail at the same time due to power, cooling, or network issues
Partition keys
&
clustering columns
cassandra table
SortedMap<RowKey, SortedMap<ColumnKey, ColumnValue>>PRIMARY KEY
PRIMARY KEY '(' <partition-key> ( ',' <identifier> )* ')' In CQL, the order in which columns are defined for the PRIMARY KEY matters. The first column of the key is called the partition key. It has the property that all the rows sharing the same partition key (even across table in fact) are stored on the same physical node. Also, insertion/update/deletion on rows sharing the same partition key for a given table are performed atomically and in isolation. Note that it is possible to have a composite partition key, i.e. a partition key formed of multiple columns, using an extra set of parentheses to define which columns forms the partition key. simple PK example
CREATE TABLE example (
id int PRIMARY KEY
);
INSERT INTO example (id) VALUES (1);
INSERT INTO example (id) VALUES (2);
INSERT INTO example (id) VALUES (3);
-------------------
RowKey: 1
=> (name=, value=, timestamp=1426254945765723)
-------------------
RowKey: 2
=> (name=, value=, timestamp=1426254945772053)
-------------------
RowKey: 3
=> (name=, value=, timestamp=1426254945777575)
03_single_PK.cql
partitioning & clustering
CREATE TABLE example (
id int,
last_seen timestamp,
bool1 boolean,
bool2 boolean,
PRIMARY KEY(id, last_seen)
);
-------------------
RowKey: 1
=> (name=2014-12-31 20\:00Z:, value=, timestamp=1426255185754510)
=> (name=2014-12-31 20\:00Z:bool1, value=01, timestamp=1426255185754510)
=> (name=2014-12-31 20\:00Z:bool2, value=01, timestamp=1426255185754510)
=> (name=2015-01-31 20\:00Z:, value=, timestamp=1426255185822199)
=> (name=2015-01-31 20\:00Z:bool1, value=01, timestamp=1426255185822199)
=> (name=2015-01-31 20\:00Z:bool2, value=00, timestamp=1426255185822199)
clustering columns
CREATE TABLE example (
id int,
last_seen timestamp,
bool1 boolean,
bool2 boolean,
PRIMARY KEY(id, last_seen, bool1)
);
-------------------
RowKey: 1
=> (name=2014-12-31 20\:00Z:true:, value=, timestamp=1426255345902457)
=> (name=2014-12-31 20\:00Z:true:bool2, value=01, timestamp=1426255345902457)
=> (name=2015-01-31 20\:00Z:true:, value=, timestamp=1426255345951879)
=> (name=2015-01-31 20\:00Z:true:bool2, value=00, timestamp=1426255345951879)05_PK_with_clustering.cql
you can't just select by last clustering column
copmpound partition keys
CREATE TABLE example (
id int,
year_month int,
last_seen timestamp,
bool1 boolean,
bool2 boolean,
PRIMARY KEY((id,year_month), last_seen)
);
-------------------
RowKey: 2:201502
=> (name=2015-01-31 20\:10Z:, value=, timestamp=1426256283358777)
=> (name=2015-01-31 20\:10Z:bool1, value=01, timestamp=1426256283358777)
=> (name=2015-01-31 20\:10Z:bool2, value=00, timestamp=1426256283358777)
-------------------
RowKey: 3:201501
=> (name=2014-12-31 20\:10Z:, value=, timestamp=1426256283327688)
=> (name=2014-12-31 20\:10Z:bool1, value=01, timestamp=1426256283327688)
=> (name=2014-12-31 20\:10Z:bool2, value=00, timestamp=1426256283327688)
06_compound_PK.cql
GENERAL ideas
- Don't think of relational table, think of a nested sorted map instead
- Many ways to model data in Cassandra, the best one depends on your case and query patterns
- Model Column Families around query patterns, but start with entities and relationships
- Denormalize and duplicate for read performance, but don't denormalize if you don't need to
- Think about query patterns and indexes upfront
- Think of phisical storage structure: keep data accessed together on disk
Cassandra data modelling 101
By Anton Kirillov




