The Secret Life of event logs
@beorn__ // beorn@binaries.fr
Captain obvious once said
"You can't respond to something you do not see"
Foremost observability is a culture
Everyone should be interested
A beer definition please
- Metrics : time series
- Alerting : notifications
- Logging : events
- Tracing : zipkin
Metrics
Metrics are meant to establish a baseline.
You can deduce what is normal and maybe what is not

Alerting
Whenever a certain set of conditions are met, it triggers a notification (pager, phone, email, slack...)

Logging
Logging allows you to track behavior change, errors, warnings, correlate and report

Tracing
At the highest level, a trace tells the story of a transaction or workflow as it propagates through a (potentially distributed) system.

Let's focus on Event logs
Let's talk numbers
| what | throughput | volume |
|---|---|---|
| average | 1k eps | 86 M events/day |
| max before lag | 3k eps | 259M events/day |
| max in lab | 4k eps | 345M events/day |
Before
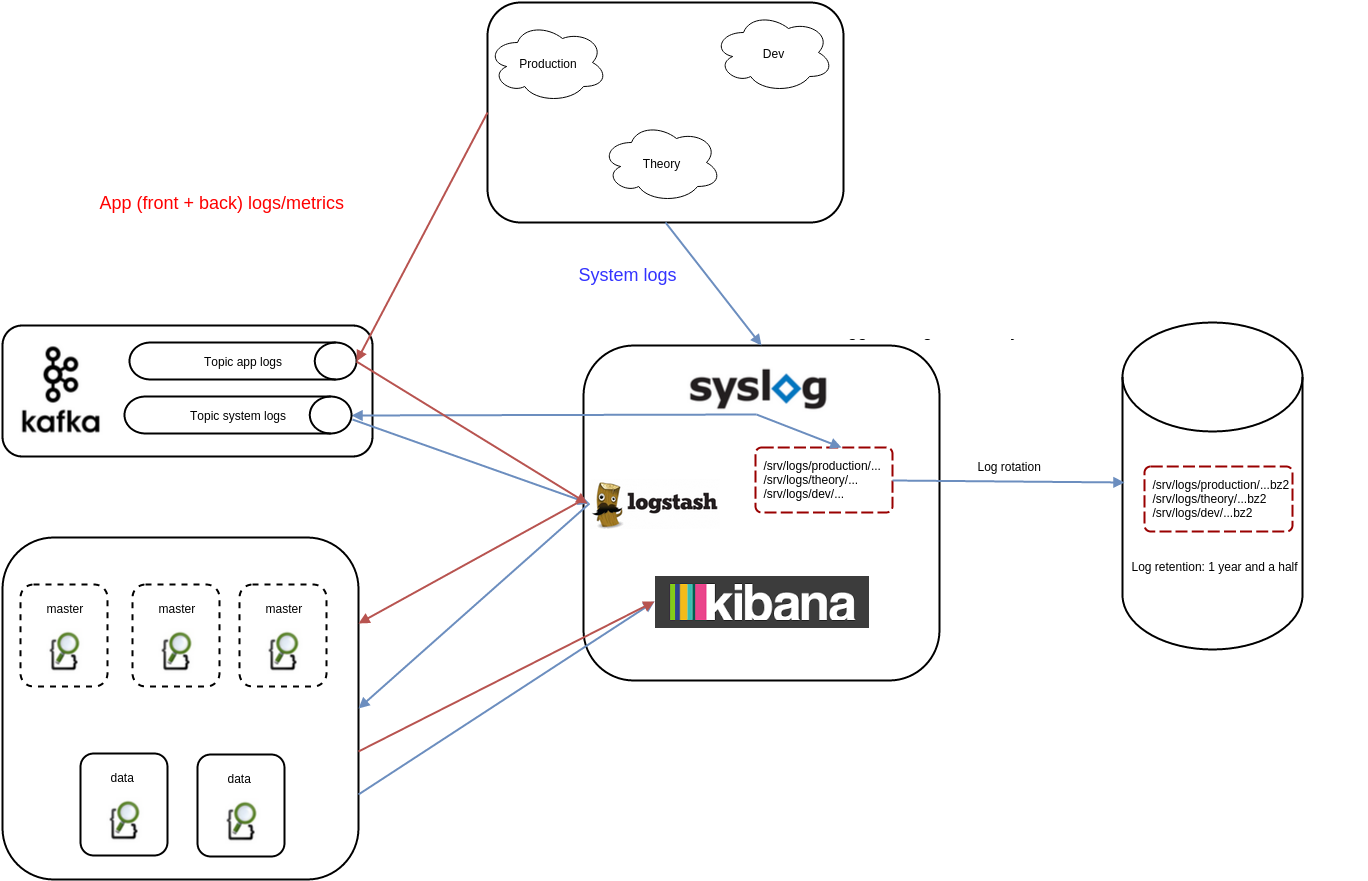
Now

Let's talk murders
| what | throughput | volume |
|---|---|---|
| average |
|
1296M events/day |
| max before lag |
|
7080M events/day |
| max in lab |
|
13392M events/day |
[...] no one can hear you stream
A certain amount of syslog messages were lost
A bigger amount of inbound Logstash messages were lost
An even bigger amount of outbound Logstash messages were lost
No kafka messages were lost
Well that was about a steady 67% of message loss
What happened ?
debunking (R)syslog myths
- libc syslog() is reliable
- UDP is reliable enough
- TCP is 100% reliable
- @@collectorip (aka tcp forwarding) is EVIL
- syslog has no TZ
- rsyslog does not scale
libc syslog() is reliable
#include <syslog.h>
void openlog(const char *ident, int option, int facility);
void syslog(int priority, const char *format, ...);
void closelog(void);
void vsyslog(int priority, const char *format, va_list ap);"syslog() generates a log message, which will be distributed by syslogd(8).
The priority argument is formed by ORing the facility and the level values (explained below).
The remaining arguments are a format, as in printf(3) and any arguments required by the format, except that the two character sequence %m will be replaced by the error message string strerror(errno). A trailing newline may be added if needed"
(debian stretch man page)
UDP is reliable enough
- Connectionless protocol
- The old 66% usage packet loss rule
- Packet re-assembly when size > MTU
- Internet
How many of you are using UDP syslog messages ?
How many of you can drop completely UDP syslog messages ?
TCP is 100 % reliable
"People tend to be lazy and so am I. So I postponed to do "the right thing" until now: read RFC 793, the core TCP RFC that still is not obsoleted (but updated by RFC3168, which I only had a quick look at because it seems not to be relevant to our case). In 793, read at least section 3.4 and 3.7. In there, you will see that the local TCP buffer is not permitted to consider a connection to be broken until it receives a reset from the remote end. This is the ultimate evidence that you can not build a reliable syslog infrastructure just on top of TCP (without app-layer acks)."
@@collectorip is evil
Rsyslogd has a fine grained queue management see [1]
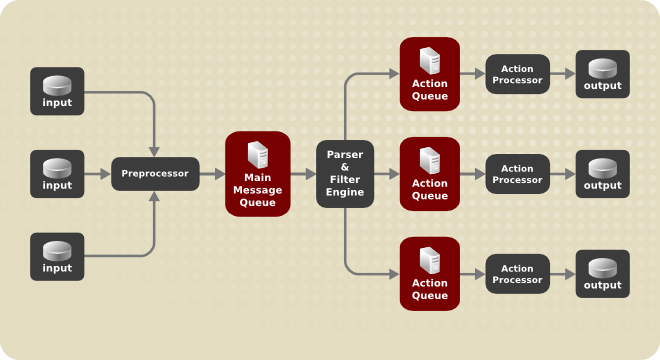
@@collectorip is evil
By default rsyslogd uses synchronous queues

@@collectorip is evil
################################
# Configure queues and messages
################################
# set max message size
$MaxMessageSize 1048576
# main queue settings
# use in-memory asynchronous processing
$MainMsgQueueType LinkedList
# save in-memory data if rsyslog shuts down
$MainMsgQueueSaveOnShutdown on
# we allow to discard what is less important than errors
$MainMsgQueueDiscardSeverity 4
# Action queue configuration
# use in-memory asynchronous action queue
$ActionQueueType LinkedList
# infinite retries on insert failure
$ActionResumeRetryCount -1
# set file name, also enables disk assisted mode. unique per destination server
$ActionQueueFileName thisisthequifilename
# memory consumption in objects, means (MaxMessageSize * MainMsgQueueSize) bytes maximum
$ActionQueueSize 50000
# limit queue size on disk
$ActionQueueMaxDiskSpace 1g
# start storing on disk when queue is this big (90% of the queue)
$ActionQueueHighWatermark 45000
# dont push to disk anymore when we reach this one
$ActionQueueLowWatermark 5000
# begin to drop less important messages when queue is this big
$ActionQueueDiscardmark 49000
# make spool files bigger
$ActionQueueMaxFileSize 10m
# where we store to disk when memory overflows
$WorkDirectory /var/spool/rsyslog
$MainMsgQueueFileName mainqueuesyslog has no TZ
Luckily rsyslog can apply templates to messages
7. Structured Data IDs ............................................20
7.1. timeQuality ...............................................20
7.1.1. tzKnown ............................................21
7.1.2. isSynced ...........................................21
7.1.3. syncAccuracy .......................................21
7.1.4. Examples ...........................................21Excerpt from rfc5424
# RSYSLOG_TraditionalFileFormat - the “old style” default log file format with low-precision timestamps
# RSYSLOG_FileFormat - a modern-style logfile format similar to TraditionalFileFormat, both with high-precision timestamps and timezone information
# RSYSLOG_TraditionalForwardFormat - the traditional forwarding format with low-precision timestamps. Most useful if you send messages to other syslogd’s or rsyslogd below version 3.12.5.
# RSYSLOG_SysklogdFileFormat - sysklogd compatible log file format. If used with options: $SpaceLFOnReceive on, $EscapeControlCharactersOnReceive off, $DropTrailingLFOnReception off, the log format will conform to sysklogd log format.
# RSYSLOG_ForwardFormat - a new high-precision forwarding format very similar to the traditional one, but with high-precision timestamps and timezone information. Recommended to be used when sending messages to rsyslog 3.12.5 or above.
# RSYSLOG_SyslogProtocol23Format - the format specified in IETF’s internet-draft ietf-syslog-protocol-23, which is very close to the actual syslog standard RFC5424 (we couldn’t update this template as things were in production for quite some time when RFC5424 was finally approved). This format includes several improvements. You may use this format with all relatively recent versions of rsyslog or syslogd.
# RSYSLOG_DebugFormat - a special format used for troubleshooting property problems. This format is meant to be written to a log file. Do not use for production or remote forwarding.
# tcp collectors
*.* @@mycollectorvip:514;RSYSLOG_SyslogProtocol23FormatRsyslog does not scale
UDP loadbalancing
TCP loadbalancing
# haproxy: syslog
# ----------------
# A.B.C.D is the service VIP ip address
frontend fe_syslog
bind A.B.C.D:514
default_backend syslog
backend be_syslog
balance leastconn
# A.B.C.E and A.B.C.F are the servers IP
server syslog01 A.B.C.E:514 check port 514 inter 3s fall 3
server syslog02 A.B.C.F:514 check port 514 inter 3s fall 3 backup
# ipvs: syslog UDP load balancer with round robin scheduler
# A.B.C.D us the VIP service ip address
-A -u A.B.C.D:514 -s rr
# now forward towards real servers A.B.C.E and A.B.C.F
-a -u A.B.C.D:514 -r A.B.C.E:514 -m -w 1
-a -u A.B.C.D:514 -r A.B.C.F:514 -m -w 1(Tricks | treats)
checklist:
- use the "& ~" idiom to stop processing the message that what was just matched by the precedent line
- handle fat streams first
- there is a better new syntax but for compatibility use the old syntax on servers
- do not sync() after each line unless you really need it -/path/to/filename
- use partitions.auto with omkafka output module
if $app-name == 'myfatapp' then -/srv/logs/myfatapp.log
& ~
if $app-name == 'mynormalapp' then -/srv/logs/mynormalapp.log
& ~
Module thou shall enable
"Fix invalid UTF-8 sequences. Most often, such invalid sequences result from syslog sources sending in non-UTF character sets, e.g. ISO 8859. As syslog does not have a way to convey the character set information, these sequences are not properly handled. While they are typically uncritical with plain text files, they can cause big headache with database sources as well as systems like ElasticSearch"
module(load="mmutf8fix")
action(type="mmutf8fix")
Dismay channel
###############
#### RULES ####
#########################
# /etc/rsyslog.d/50-defaultrules.conf
# define output channels
$outchannel auth,/var/log/auth.log,524288000,/usr/local/sbin/logrotatenow
[...]
$outchannel messages,/var/log/messages,524288000,/usr/local/sbin/logrotatenow
#!/bin/sh
# /usr/local/sbin/logrotatenow
logrotate -f /etc/logrotate.conf
Link rsyslogd to logrotate using output channels
The Mozlog format
{
"Timestamp": 145767775123456,
"Type": "request.summary",
"Logger": "myapp",
"Hostname": "server-a123.mozilla.org",
"EnvVersion":"2.0",
"Severity": 6,
"Pid": 1337,
"Fields":{
"agent": "curl/7.43.0",
"errno": 0,
"method": "GET",
"msg": "the user wanted something.",
"path": "/something",
"t": 5,
"uid": "12345"
}
}We did use the mozlog format for kafka
omkafka
# see available properties here http://www.rsyslog.com/doc/master/configuration/properties.html
module(load="omkafka")
template(name="json_lines"
type="list"
option.json="on") {
constant(value="{")
# Timestamp has to be a unixstamp (uint64) that goes to the nanosecond
constant(value="\"Timestamp\":") property(name="timereported" dateFormat="unixtimestamp") constant(value="000000000")
constant(value="\",\"Payload\":\"") property(name="msg")
constant(value="\",\"Hostname\":\"") property(name="hostname")
constant(value="\",\"EnvVersion\":\"1.0")
constant(value="\",\"Severity\":\"") property(name="syslogseverity-text")
constant(value="\",\"Pid\":\"") property(name="procid")
constant(value="\",\"Fields\": {")
constant(value="\"facility\": \"") property(name="syslogfacility-text")
constant(value="\",\"priority\":\"") property(name="syslogpriority-text")
constant(value="\",\"tag\":\"") property(name="syslogtag")
constant(value="\",\"program\":\"") property(name="app-name")
constant(value="\",\"received\":\"") property(name="timegenerated" dateFormat="rfc3339")
constant(value="\"}")
constant(value="}\n")
}
main_queue(
queue.workerthreads="1" # threads to work on the queue
queue.dequeueBatchSize="100" # max number of messages to process at once
queue.size="10000" # max queue size
)
action(
type="omkafka"
template="json_lines"
topic="syslog"
broker=["kafkahost01","kafkahost02"]
partitions.auto="on"
errorFile="/var/log/rsyslog_kafka_errors.log"
)
(r)syslog conclusions
- syslog() has bindings/libs in every language
- Use async queues
- Use RFC5424-ish rsyslog template for logs
- UDP is still better than nothing
- TCP is sufficient for us
- RELP is the ultimate solution for ensuring reliability
- use mmutf8fix
- think about performance when processing log streams
- prefer structured messages format (JSON here)
- kafka is perfectly supported in recent rsyslog versions
- rsyslogd is very fast
s/(Logstash|Heka)/Hindsight/
Heka's tomb
TL;DR
Hi everyone,
I'm loooong overdue in sending out an update about the current state of
and plans for Heka. Unfortunately, what I have to share here will
probably be disappointing for many of you, and it might impact whether
or not you want to continue using it, as all signs point to Heka getting
less support and fewer updates moving forward.
The short version is that Heka has some design flaws that make it hard
to incrementally improve it enough to meet the high throughput and
reliability goals that we were hoping to achieve. While it would be
possible to do a major overhaul of the code to resolve most of these
issues, I don't have the personal bandwidth to do that work, since most
of my time is consumed working on Mozilla's immediate data processing
needs rather than general purpose tools these days. Hindsight
(https://github.com/trink/hindsight), built around the same Lua sandbox
technology as Heka, doesn't have these issues, and internally we're
using it more and more instead of Heka, so there's no organizational
imperative for me (or anyone else) to spend the time required to
overhaul the Go code base.
Heka is still in use here, though, especially on our edge nodes, so it
will see a bit more improvement and at least a couple more releases.
Most notably, it's on my list to switch to using the most recent Lua
sandbox code, which will move most of the protobuf processing to custom
C code, and will likely improve performance as well as remove a lot of
the problematic cgo code, which is what's currently keeping us from
being able to upgrade to a recent Go version.
Beyond that, however, Heka's future is uncertain. The code that's there
will still work, of course, but I may not be doing any further
improvements, and my ability to keep up with support requests and PRs,
already on the decline, will likely continue to wane.
So what are the options? If you're using a significant amount of Lua
based functionality, you might consider transitioning to Hindsight. Any
Lua code that works in Heka will work in Hindsight. Hindsight is a much
leaner and more solid foundation. Hindsight has far fewer i/o plugins
than Heka, though, so for many it won't be a simple transition.
Also, if there's someone out there (an organization, most likely) that
has a strong interest in keeping Heka's codebase alive, through funding
or coding contributions, I'd be happy to support that endeavor. Some
restrictions apply, however; the work that needs to be done to improve
Heka's foundation is not beginner level work, and my time to help is
very limited, so I'm only willing to support folks who demonstrate that
they are up to the task. Please contact me off-list if you or your
organization is interested.
Anyone casually following along can probably stop reading here. Those of
you interested in the gory details can read on to hear more about what
the issues are and how they might be resolved.
First, I'll say that I think there's a lot that Heka got right. The
basic composition of the pipeline (input -> split -> decode -> route ->
process -> encode -> output) seems to hit a sweet spot for composability
and reuse. The Lua sandbox, and especially the use of LPEG for text
parsing and transformation, has proven to be extremely efficient and
powerful; it's the most important and valuable part of the Heka stack.
The routing infrastructure is efficient and solid. And, perhaps most
importantly, Heka is useful; there are a lot of you out there using it
to get work done.
There was one fundamental mistake made, however, which is that we
shouldn't have used channels. There are many competing opinions about Go
channels. I'm not going to get in to whether or not they're *ever* a
good idea, but I will say unequivocally that their use as the means of
pushing messages through the Heka pipeline was a mistake, for a number
of reasons.
First, they don't perform well enough. While Heka performs many tasks
faster than some other popular tools, we've consistently hit a
throughput ceiling thanks to all of the synchronization that channels
require. And this ceiling, sadly, is generally lower than is acceptable
for the amount of data that we at Mozilla want to push through our
aggregators single system.
Second, they make it very hard to prevent message loss. If unbuffered
channels are used everywhere, performance plummets unacceptably due to
context-switching costs. But using buffered channels means that many
messages are in flight at a time, most of which are sitting in channels
waiting to be processed. Keeping track of which messages have made it
all the way through the pipeline requires complicated coordination
between chunks of code that are conceptually quite far away from each other.
Third, the buffered channels mean that Heka consumes much more RAM than
would be otherwise needed, since we have to pre-allocate a pool of
messages. If the pool size is too small, then Heka becomes susceptible
to deadlocks, with all of the available packs sitting in channel queues,
unable to be processed because some plugin is blocked on waiting for an
available pack. But cranking up the pool size causes Heka to use more
memory, even when it's idle.
Hindsight avoids all of these problems by using disk queues instead of
RAM buffers between all of the processing stages. It's a bit
counterintuitive, but at high throughput performance is actually better
than with RAM buffers, because a) there's no need for synchronization
locks and b) the data is typically read quickly enough after it's
written that it stays in the disk cache.
There's much less chance of message loss, because every plugin is
holding on to only one message in memory at a time, while using a
written-to-disk cursor file to track the current position in the disk
buffer. If the plug is pulled mid-process, some messages that were
already processed might be processed again, but nothing will be lost,
and there's no need for complex coordination between different stages of
the pipeline.
Finally, there's no need for a pool of messages. Each plugin is holding
some small number of packs (possibly as few as one) in its own memory
space, and those packs never escape that plugin's ownership. RAM usage
doesn't grow, and pool exhaustion related deadlocks are a thing of the past.
For Heka to have a viable future, it would basically need to be updated
to work almost exactly like Hindsight. First, all of the APIs would need
to be changed to no longer refer to channels. (The fact that we exposed
channels to the APIs is another mistake we made... it's now generally
frowned upon in Go land to expose channels as part of your public APIs.)
There's already a non-channel based API for filters and outputs, but
most of the plugins haven't yet been updated to use the new API, which
would need to happen.
Then the hard work would start; a major overhaul of Heka's internals, to
switch from channel based message passing to disk queue based message
passing. The work that's been done to support disk buffering for filters
and outputs is useful, but not quite enough, because it's not scalable
for each plugin to have its own queue; the number of open file
descriptors would grow very quickly. Instead it would need to work like
Hindsight, where there's one queue that all of the inputs write to, and
another that filters write to. Each plugin reads through its specified
input queue, looking for messages that match its message matcher,
writing its location in the queue back to the shared cursors file.
There would also be some complexity in reconciling Heka's breakdown of
the input stage into input/splitter/decoder with Hindsight's
encapsulation of all of these stages into a single sandbox.
Ultimately I think this would be at least 2-3 months full time work for
me. I'm not the fastest coder around, but I know where the bodies are
buried, so I'd guess it would take anyone else at least as long,
possibly longer if they're not already familiar with how everything is
put together.
And that's about it. If you've gotten this far, thanks for reading.
Also, thanks to everyone who's contributed to Heka in any way, be it by
code, doc fixes, bug reports, or even just appreciation. I'm sorry for
those of you using it regularly that there's not a more stable future.
Regards,
-rHindsight was born on heka's ashes
Love at first Hindsight
- written in C, modular, light, fast
- did i say fast ?
- lua bindings everywhere
- helpful project leader
- used in production at mozilla
- ES
- kafka
- mozlog
- syslog
- [...]
Fresh is a fresh
- Target build is CentOS
- The three projects are using cmake which allows cpack usage
- Debian offers old versions which are buggy if you intend to use ES
- Use latest versions for each of the three projects (hindsight, lua_sandbox, and lua_sandbox_extensions)
- There's a docker image
Opinionated
- The message matcher now uses Lua string match patterns (not LPEG) instead of RE2 expressions in Heka
- Looping messages was removed. It has always been a bad idea in Heka.
- Heka's Splitters/Decoders/Encoders no longer exist they simply become part of the input/output plugins respectively
- Checkpoints are now all managed by the Hindsight infrastructure
Production grade
In UNIX everything is a file
In Hindsight input and ouput plugins :
- are and should be sandboxed
- have their own thread
- have their own error handler
- can be CRUD-ed live
Note that analysis plugins are sharing threads
/etc/hindsight/
└── hindsight.cfg
/srv/hindsight/
├── admin
├── load
│ ├── analysis
│ ├── input
│ └── output
├── output
│ ├── analysis
│ └── input
└── run
├── analysis
├── input
└── output
Architecture

Trink and his trinkets

Hindsight admin is pretty cool
LPEG && regexps
LPEG is a new pattern-matching library for Lua, based on Parsing Expression Grammars (PEGs) ( read The joy of LPEG )
LPEG is capture oriented.
Lpeg actually consists of two modules :
- The core LPEG module is written in C and allows you to compose parser objects using operator overloading, building them up from primitives returned from tersely named constructor functions.
- The re module which provides a more normal PEG syntax for parsers, which despite the name of the module are rather different from regular expressions. This module is written in Lua, using an LPEG parser to parse PEGs and construct lpeg parsers from them. The PEG syntax is extended so that you can define "captures".
LPEG Core module
| Core pattern | Description |
|---|---|
| lpeg.P(string) | Matches string literally |
| lpeg.P(n) | Matches exactly n characters |
| lpeg.S(string) | Matches any character in string (Set) |
| lpeg.R("xy") | Matches any character between x and y (Range) |
| patt^n | Matches at least n repetitions of patt |
| patt^-n | Matches at most n repetitions of patt |
| patt1 * patt2 | Matches patt1 followed by patt2 |
| patt1 + patt2 | Matches patt1 or patt2 (ordered choice) |
| patt1 - patt2 | Matches patt1 if patt2 does not match |
| -patt | Equivalent to ("" - patt) |
| #patt | Matches patt but consumes no input |
| lpeg.B(patt) | Matches patt behind the current position, consuming no input |
Matches
LPEG Core module
Captures
| Core pattern | Description |
|---|---|
| lpeg.C(patt) | the match for patt plus all captures made by patt |
| lpeg.Carg(n) | the value of the nth extra argument to lpeg.match (matches the empty string) |
| lpeg.Cb(name) | the values produced by the previous group capture named name (matches the empty string) |
| lpeg.Cc(values) | the given values (matches the empty string) |
| lpeg.Cf(patt, func) | a folding of the captures from patt |
| lpeg.Cg(patt [, name]) | the values produced by patt, optionally tagged with name |
| lpeg.Cp() | the current position (matches the empty string) |
| lpeg.Cs(patt) | the match for patt with the values from nested captures replacing their matches |
| lpeg.Ct(patt) | a table with all captures from patt |
| patt / string | string, with some marks replaced by captures of patt |
| patt / number | the n-th value captured by patt, or no value when number is zero. |
| patt / table | table[c], where c is the (first) capture of patt |
| patt / function | the returns of function applied to the captures of patt |
| lpeg.Cmt(patt, function) | the returns of function applied to the captures of patt; the application is done at match time |
LPEG re module
Syntax Description
( p ) grouping
'string' literal string
"string" literal string
[class] character class
. any character
%name pattern defs[name] or a pre-defined pattern
name non terminal
<name> non terminal
{} position capture
{ p } simple capture
{: p :} anonymous group capture
{:name: p :} named group capture
{~ p ~} substitution capture
{| p |} table capture
=name back reference
p ? optional match
p * zero or more repetitions
p + one or more repetitions
p^num exactly n repetitions
p^+num at least n repetitions
p^-num at most n repetitions
p -> 'string' string capture
p -> "string" string capture
p -> num numbered capture
p -> name function/query/string capture equivalent to p / defs[name]
p => name match-time capture equivalent to lpeg.Cmt(p, defs[name])
& p and predicate
! p not predicate
p1 p2 concatenation
p1 / p2 ordered choice
(name <- p)+ grammar
available PEGs
/usr/lib/luasandbox/modules/lpeg
├── bsd
│ └── filterlog.lua
├── cbufd.lua
├── common_log_format.lua
├── date_time.lua
├── ip_address.lua
├── linux
│ ├── cron.lua
│ ├── dhclient.lua
│ ├── dhcpd.lua
│ ├── groupadd.lua
│ ├── groupdel.lua
│ ├── kernel.lua
│ ├── login.lua
│ ├── named.lua
│ ├── pam.lua
│ ├── puppet_agent.lua
│ ├── sshd.lua
│ ├── sudo.lua
│ ├── su.lua
│ ├── systemd_logind.lua
│ └── useradd.lua
├── logfmt.lua
├── mysql.lua
├── postfix.lua
├── syslog.lua
└── syslog_message.lua
Come out and play
a cool lpeg grammar tester

Come out and play
a cool lpeg grammar benchmark

Plug in baby
-- This input reads from syslog and decodes into mozlog
filename = "kafka.lua"
instruction_limit = 0
output_limit = 8 * 1024 * 1024
brokerlist = "kafkaserver1,kafkaserver2"
-- In balanced consumer group mode a consumer can only subscribe on topics, not topics:partitions.
-- The partition syntax is only used for manual assignments (without balanced consumer groups).
topics = {"syslog"}
-- https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md#global-configuration-properties
consumer_conf = {
log_level = 7,
["group.id"] = "hindsight",
["message.max.bytes"] = output_limit,
}
-- https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md#topic-configuration-properties
topic_conf = {
["compression.codec"] = "none"
-- ["auto.commit.enable"] = true, -- cannot be overridden
-- ["offset.store.method"] = "broker", -- cannot be overridden
}
-- Specify a module that will decode the json data and inject the resulting message.
decoder_module = "decoders.heka.json_mutate_synthesiolog"
decoders_heka_json_mutate_synthesiolog = {
-- try to decode json string nested in Payload
payload_maybe_json = true,
-- discard when nested json is parsed ok
keep_payload = false,
-- override root fields using Fields fields
remap_hash_root = {
severity = "Severity",
host = "Hostname",
pid = "Pid",
}
}an input plugin declaration file
JSON Voorhees
--[[
# Heka JSON Message Decoder Module
https://wiki.mozilla.org/Firefox/Services/Logging
The above link describes the Heka message format with a JSON schema. The JSON
will be decoded and passed directly to inject_message so it needs to decode into
a Heka message table described here:
https://mozilla-services.github.io/lua_sandbox/heka/message.html
## Decoder Configuration Table
* none
## Functions
### decode
Decode and inject the resulting message
*Arguments*
- data (string) - JSON message with a Heka schema
*Return*
- nil - throws an error on an invalid data type, JSON parse error,
inject_message failure etc.
--]]
-- Imports
local cjson = require "cjson"
local inject_message = inject_message
local M = {}
setfenv(1, M) -- Remove external access to contain everything in the module
function decode(data)
inject_message(cjson.decode(data))
end
return MHere's a decoder
unplugged
-- Mozlog formatted output plugin
filename = "elasticsearch_bulk_api.lua"
message_matcher = "TRUE"
memory_limit = 200 * 1024 * 1024
-- ticker_interval = 10
address = "A.B.C.D"
port = 9200
timeout = 10
flush_count = 50000
flush_on_shutdown = false
preserve_data = not flush_on_shutdown --in most cases this should be the inverse of flush_on_shutdown
discard_on_error = false
-- See the elasticsearch module directory for the various encoders and configuration documentation.
encoder_module = "encoders.elasticsearch.mozlog"
encoders_elasticsearch_common = {
es_index_from_timestamp = true,
index = "hindsight-v1-%{Logger}-%{priority}-%{%Y.%m.%d}",
type_name = "%{Logger}",
}
an output ES plugin
Output partitioning
-- Mozlog formatted output plugin
filename = "elasticsearch_bulk_api.lua"
message_matcher = "Uuid < '\008'"
memory_limit = 200 * 1024 * 1024
-- ticker_interval = 10
address = "A.B.C.D"
port = 9200
timeout = 10
flush_count = 50000
flush_on_shutdown = false
preserve_data = not flush_on_shutdown --in most cases this should be the inverse of flush_on_shutdown
discard_on_error = false
-- See the elasticsearch module directory for the various encoders and configuration documentation.
encoder_module = "encoders.elasticsearch.mozlog"
encoders_elasticsearch_common = {
es_index_from_timestamp = true,
index = "hindsight-v1-%{Logger}-%{priority}-%{%Y.%m.%d}",
type_name = "%{Logger}",
}
- In our environment an ES HTTP client can handle 1.5k qps
- Our logging ES cluster can handle 82k qps
- partitioned messages using Uuid for generating 64 threads in the message_matcher
Checkpoints and pruning
filename = "prune_input.lua"
ticker_interval = 60
input = true
analysis = trueoutput/hindsight.cp
_G['input'] = '4614:698382171'
_G['input->analysis0'] = '4614:694589659'
_G['input->analysis1'] = '4614:694589659'
_G['input->analysis2'] = '4614:697919521'
_G['input->analysis3'] = '4614:692267096'
_G['analysis'] = '0:0'
_G['analysis->output.http-elasticsearch-01'] = '0:0'
[...]
_G['analysis->output.http-elasticsearch-32'] = '0:0'
_G['input->output.http-elasticsearch-01'] = '4614:697919521'
[...]
_G['input->output.http-elasticsearch-32'] = '4614:697919521'
run/input/file-prune.cfg
Live debugging
:Uuid: F06E5BE4-E640-48CD-AFD9-3F56D12F9EF7
:Timestamp: 1970-01-01T00:00:03.416000000Z
:Type: logfile
:Logger: FxaAuthWebserver
:Severity: 7
:Payload: <nil>
:EnvVersion: <nil>
:Pid: <nil>
:Hostname: trink-x230
:Fields:
| name: body_bytes_sent type: 3 representation: B value: 6428434
| name: remote_addr type: 0 representation: ipv4 value: 1.2.3.4
| name: request type: 0 representation: <nil> value: GET /foobar HTTP/1.1
| name: status type: 3 representation: <nil> value: 200
| name: http_user_agent type: 0 representation: <nil> value: curl-and-your-UA
| name: http_x_forwarded_for type: 0 representation: <nil> value: true
| name: http_referer type: 0 representation: <nil> value: -- Hindsight does hot-reload at a plugin level
- Hindsight can filter messages using message_matcher
- Combine this with debug.lua and you obtain live debugging
filename = "heka_debug.lua" -- the file to use
message_matcher = "TRUE" -- display ALL messagesES tips
- Use (dynamic) templates for mappings
- Use recent ES 5.x (rollovers, aliases, stability)
- Use automatic rollovers to avoid huge indices
- Use index named retention policy
Kibana



Looking back
- truncated JSON problem
- fully scalable
- predictable costs (ES mostly)
- kafka and kafkacat are awesome for debugging
- use debug.lua
- have a theory environment
- LPEG is hard but totally worth it
- adoption is related to performance an reliability
Questions ?
@beorn__ // beorn@binaries.fr
Thanks !
Oh... We're hiring !

We're hiring !
Links
[1] Queues in Rsyslog
http://www.rsyslog.com/doc/v8-stable/concepts/queues.html
[2] Libc syslog functions
https://www.gnu.org/software/libc/manual/html_node/syslog_003b-vsyslog.html#syslog_003b-vsyslog
[3] Hindsight full documentation
http://mozilla-services.github.io/hindsight/
[4] Adventures in hindsight 1/2
http://www.rottenbytes.info/post/adventures-in-hindsight/
[5] Adventures in hindsight 2/2
http://www.rottenbytes.info/post/adventures-in-hindsight-2/
[6] Github Hindsight
https://github.com/mozilla-services/hindsight
[7] State and future of heka
https://github.com/mozilla-services/hindsight
[8] The joy of lpeg
http://fanf.livejournal.com/97572.html
[9] An introduction to Parsing Expression Grammars with LPeg
http://leafo.net/guides/parsing-expression-grammars.htmlLife of an event log @synthesio.com
By Aurélien Rougemont
Life of an event log @synthesio.com
Talk about replacing logstash with Hindsight