The interconnect layer covers all the mechanisms that knit a bunch of instances together into a cohesive system. That includes traffic management, load balancing, and discovery.
Who is interested in a single instance running by itself?
Routing, load balancing, failover, traffic management
-> Service Discovery with DNS
Your team needs to find the service owners and pry the DNS name or names out of them. An exchange of favors may be required, maybe a six-pack of beer in the extreme
-> Load Balancing with DNS
DNS round-robin load balancing is one of the oldest techniques...
Problems:
all the instances in the pool must be directly “routable” from callers.
the DNS round-robin approach suffers from putting too much control in the client’s hands.
DNS
DNS

-> Global Server Load Balancing with DNS
DNS
-> Global Server Load Balancing with DNS

DNS - to remember
- Use DNS to call services when they don’t change often.
- DNS round-robin offers a low-cost way to load-balance.
- “Discovery” is a human process. DNS names are supplied in configuration.
- DNS works well for global traffic management in coordination with local load balancers.
- Diversity is crucial in DNS hosts. Don’t rely on the same infrastructure for DNS hosts and production services.
Load Balancing
Software Load Balancing -> using reverse proxy server ( www.squid-cache.org, www.haproxy.org, http://httpd.apache.org, https://nginx.org)
Hardware Load Balancing -> as F5’s Big-IP
they operate closer to the network, hardware load balancers provide better capacity and throughput
Partitioning Request Types -> search requests may go to one set of instances, while use-signup requests go elsewhere.
Health Checks && Stickiness
Demand Control
...the world can crush our systems at any time. There’s no natural protection
-> There are two basic strategies: either refuse work or scale out.
-> sockets vs request !?
...we can see that the best thing to do under high load is turn away work we can’t complete in time
Demand Control - to remember
-> Reject work as close to the edge as possible. The further it penetrates into your system, the more resources it ties up.
-> Provide health checks that allow load balancers to protect your application code.
-> Start rejecting work when your response time is going to provoke retries
Network Routing
In the case of nearby servers, the routes are probably easy; they’ll just be based on the subnet addresses.
Routing gets a bit more complicated when distant services
Discovering Services
Service discovery really has two parts:
First, it’s a way that instances of a service can announce themselves to begin receiving a load
The second part is lookup. A caller needs to know at least one IP address to contact for a particular service
Service discovery is itself another service. It can fail or get overloaded. It’s a good idea for clients to cache results for a short time.
You can build a service discovery mechanism on top of a distributed data store such as Apache ZooKeeper or etcd.
Discovering Services
ZooKeeper is a “CP” system. That means when there’s a network partition (and there will be a network partition), some nodes won’t answer queries or accept writes. Since clients need to be available, they must have a fallback to use other nodes or previously cached results.
Discovering Services in Docker area
Docker Swarm starts containers to run service instances, it automatically registers them with the swarm’s dynamic DNS and load-balancing mechanism.
Migratory Virtual IP Addresses
You can set up your user base to use a DNS round-robin pointing at virtual IP addresses, as opposed to using the real IP addresses of the Content Gateway machines.
Because virtual IP addresses are not bound to machines, a Content Gateway cluster can take addresses from inactive nodes and distribute those addresses among the remaining live nodes.
Scalability
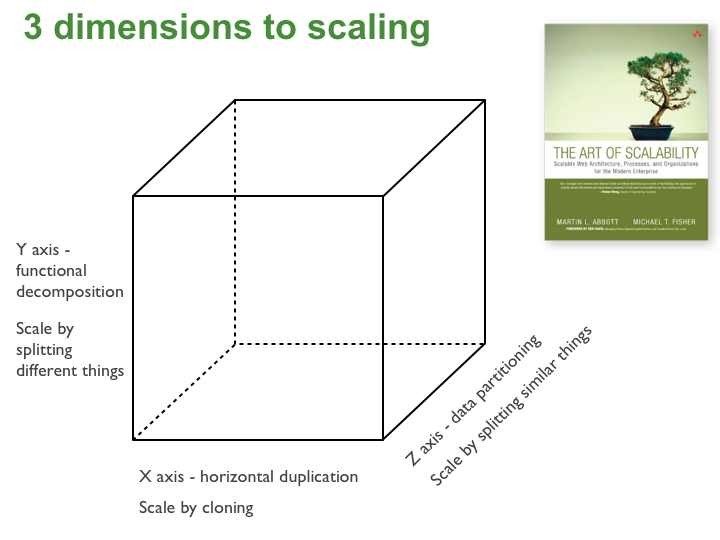
Release it - chapter 9
By Bogdan Posa



