Pythology
CC: https://flic.kr/p/8kEcVA
Plumbing for Data Science
Pradeep Gowda
Proofpoint Inc
@btbytes

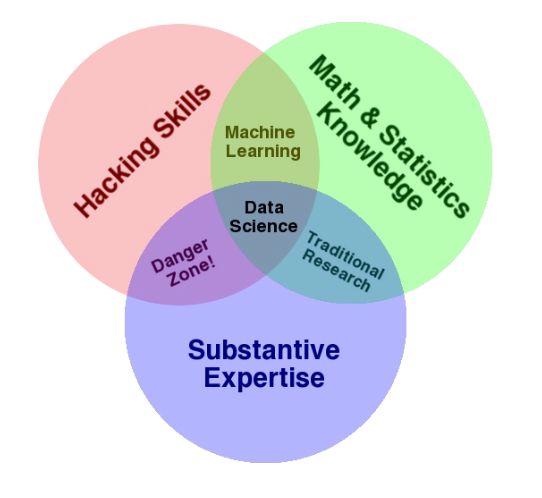
Data Science
Drew Conway, IQT Quarterly, 2011
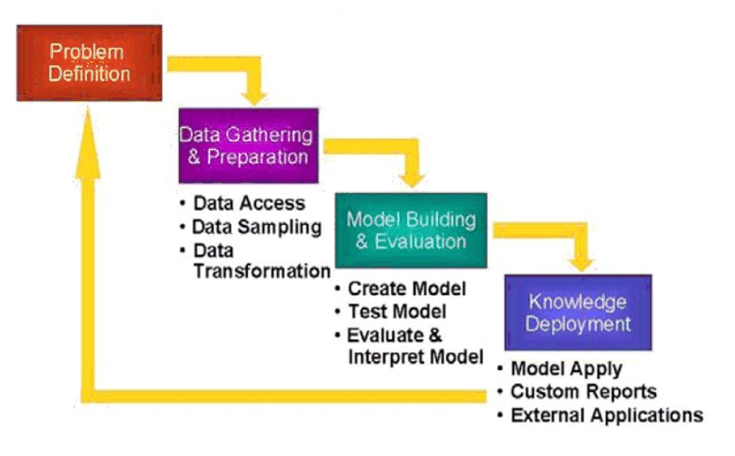
Courtesy: Oracle
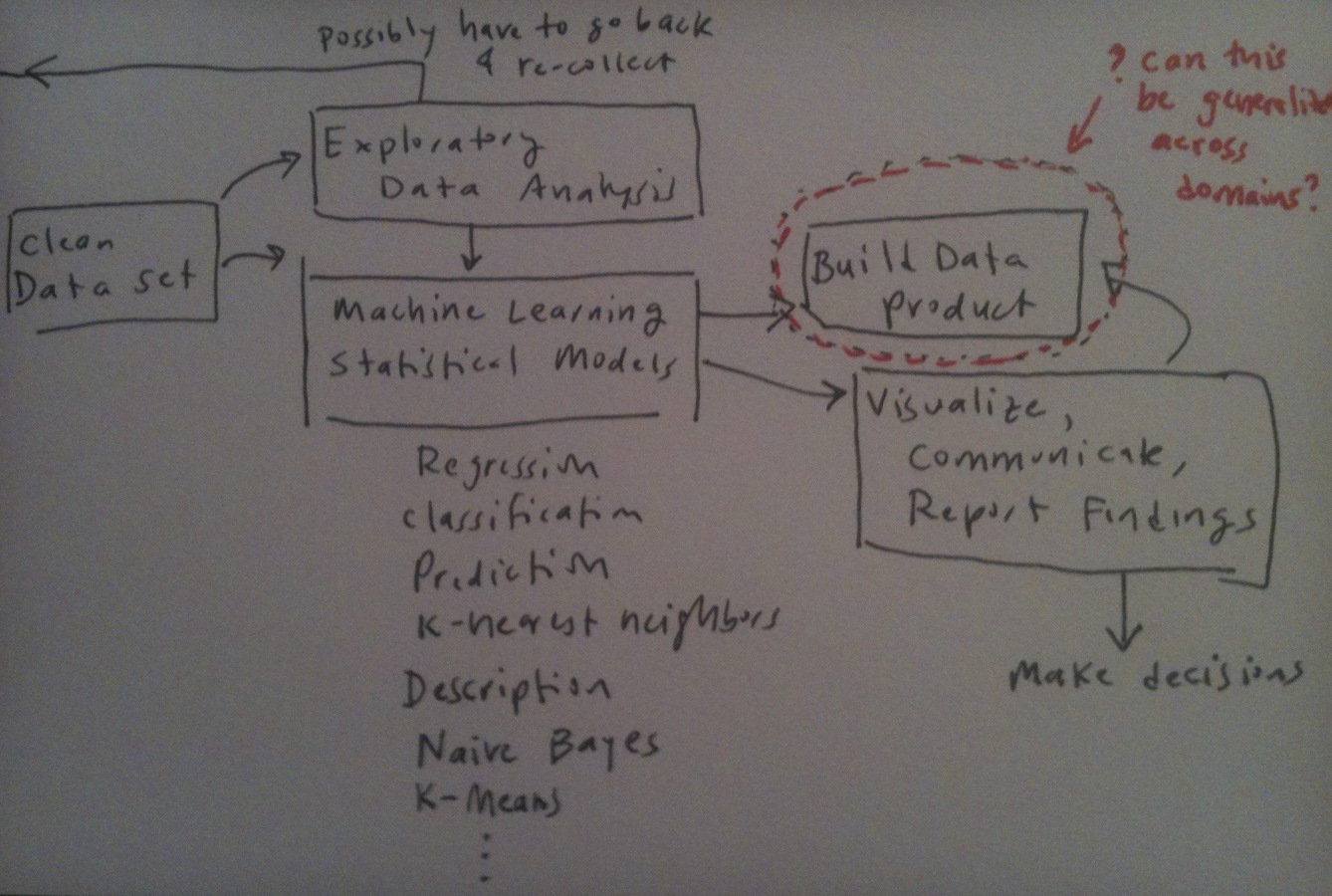
Source: http://columbiadatascience.com/
Exploration
Engineering
Machine Learning, EDA etc.,
"Big Data"
Data Plumbing
Quick turnaround?
Automation
Framework
Working with data is messy
Be language and tool agnostic
Get familiar with the command line
UNIX metaphors - pipe, filter, composable programs
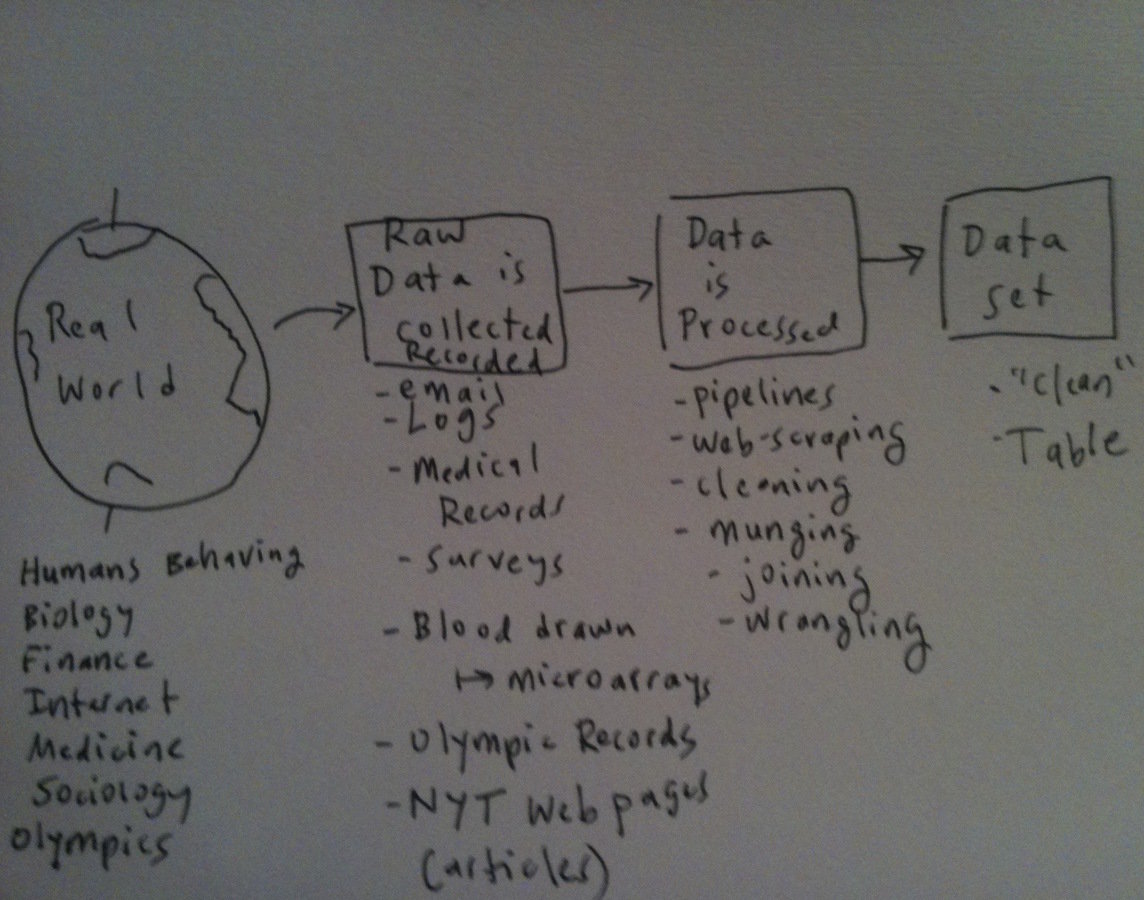
The data landscape
Data sources
- Server logs
- Sensors
- Human generated (twitter, geolocation)
- APIs
- Databases
- RDBMS
- No/NotOnly/New SQL databases
Data Formats
- API
- JSON
- XML
- HTML - web scraping
- Delimited files
- Binary
- XLS
- Legacy
- "unstructured" data
Tools of the trade
Skill sets
- Basic programming ability
- procedural
- object based
- scripting
- Text processing
- Network / HTTP
- Databases (and some SQL)
What's in your toolkit?
- Command line tools
- Programming language
- Python. Duh!
- Data analysis Tools
- PyData, R etc.,
- Language Libraries
- Database query tools
- Spreadsheet (like) programs
Command line tools
- wget
- curl
- head/tail
- grep
- sort
- cut
- sed
- awk
- uniq
Of the UNIX heritage
Third party tools: jq, CSVKit etc.,
Demo time
at the end... time permitting

Why Python
- Community
- Availability
- Approachability
- Multi-faceted
- Well understood (limitations and strengths)
- A fair balance of expressiveness, power, permissibility
- Team player
Batteries included
- String
- Process
- OS
- CSV
- Glob
- Arg/Opt parse
- ConfigParse
- Json
- XML/ElementTree
- Collections
Third party Libraries
- Requests - HTTP client
- BeautifulSoup - HTML scraping
- Arrow - date and time
- SQLAlchemy - database access
# Installing third party packages:
pip install arrow
pip install requests
# PROTIP: look up virtualenv and virtualenvwrapper
# Alternate: conda [part of Continuum.io / anaconda package]Text Encoding
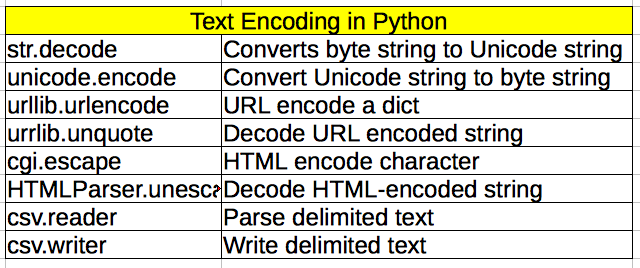
Text: Regular Expression
For parsing multi-line structured records: see pyparsing
ACME-1245:V2
import re
str = 'ACME-1245:V2'
match = re.search(r'\w{4}-\d{4}:\w+', str)
if match:
print 'found', match.group()
else:
print 'did not find'Four-letter identifier followed by a "dash" followed by a 4 digit number followed by a "colon" followed by another string
Time
strptime
PROTIP: strftime.org
# From string to time
from time import strptime
print strptime('2015-05-01', '%y-%m-%d')
time.struct_time(tm_year=2015, tm_mon=5, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=121, tm_isdst=-1)
#From time to string
from time import strftime
print strftime('%Y-%m-%dT%H:%M:%S', datetime.timetuple(datetime.now()))
Time: Arrow
>>> import arrow
>>> utc = arrow.utcnow()
>>> utc
<Arrow [2013-05-11T21:23:58.970460+00:00]>
>>> utc = utc.replace(hours=-1)
>>> utc
<Arrow [2013-05-11T20:23:58.970460+00:00]>
>>> local = utc.to('US/Pacific')
>>> local
<Arrow [2013-05-11T13:23:58.970460-07:00]>
>>> arrow.get('2013-05-11T21:23:58.970460+00:00')
<Arrow [2013-05-11T21:23:58.970460+00:00]>
>>> local.timestamp
1368303838
>>> local.format('YYYY-MM-DD HH:mm:ss ZZ')
'2013-05-11 13:23:58 -07:00'
>>> local.humanize()
'an hour ago'
Fetching Data off the web
import requests
import json
r = requests.get('http://httpbin.org/get')
if r.status_code == 200:
data = json.loads(r.text)
print "Your IP is: ", data['origin']
print "FYI, the text response: \n", r.text
print "prettified json: \n", json.dumps(data, sort_keys=True,
indent=4, separators=(',', ': '))
Requests/GET
Your IP is: 108.223.55.55
FYI, the text response:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.5.1 CPython/2.7.9 Darwin/14.3.0"
},
"origin": "108.223.55.55",
"url": "http://httpbin.org/get"
}
prettified json:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.5.1 CPython/2.7.9 Darwin/14.3.0"
},
"origin": "108.223.55.55",
"url": "http://httpbin.org/get"
}
import requests
data = {'name': 'Who?', 'age': 55}
r = requests.get('http://example.com', data=data)
r.textRequests/POST
Interacting with APIs
httpie
comes in handy for automating
- testing / learning new APIs
- data downloads
- automating periodic data fetches
http://httpbin.org/
# You can install httpbin as a library from PyPI and run it as a WSGI app.
$ pip install httpbin
$ gunicorn httpbin:appDatabases
"Data comes in, Data goes out..."
"You can't explain that!"
SQL. Learn it.
PostgreSQL
Database recommendation? one word...
SQL Skills
- SELECT statement
- WHERE clause
- JOINs
- Basics of indexing
Command line tools in Python
Let the program do one small thing well
Make it configurable via the command line switches
Make it configurable via a configuration file
Python libraries for building
Command line tools
Inbuilt Libraries
- fileinput
- argparse
Thirdparty Libraries
- docopt
fileinput
#!/usr/bin/env python
# Program to print words that start with an uppercase letter
# example usage: cat test.txt | ./filterr
import fileinput
import string
for line in fileinput.input():
words = line.split()
for word in words:
first_letter = ord(word[0])
if first_letter >=65 and first_letter <=90:
print wordcat ~/tmp/habits.txt| ./filterr
Habits
John
Doe
Marchargparse
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('-s', action='store', dest='simple_value',
help='Store a simple value')
parser.add_argument('-c', action='store_const', dest='constant_value',
const='value-to-store',
help='Store a constant value')
parser.add_argument('-t', action='store_true', default=False,
dest='boolean_switch',
help='Set a switch to true')
parser.add_argument('-f', action='store_false', default=False,
dest='boolean_switch',
help='Set a switch to false')
parser.add_argument('-a', action='append', dest='collection',
default=[],
help='Add repeated values to a list',
)
parser.add_argument('-A', action='append_const', dest='const_collection',
const='value-1-to-append',
default=[],
help='Add different values to list')
parser.add_argument('-B', action='append_const', dest='const_collection',
const='value-2-to-append',
help='Add different values to list')
parser.add_argument('--version', action='version', version='%(prog)s 1.0')
results = parser.parse_args()
print 'simple_value =', results.simple_value
print 'constant_value =', results.constant_value
print 'boolean_switch =', results.boolean_switch
print 'collection =', results.collection
print 'const_collection =', results.const_collectionargparse ..
$ python argparse_action.py -h
usage: argparse_action.py [-h] [-s SIMPLE_VALUE] [-c] [-t] [-f]
[-a COLLECTION] [-A] [-B] [--version]
optional arguments:
-h, --help show this help message and exit
-s SIMPLE_VALUE Store a simple value
-c Store a constant value
-t Set a switch to true
-f Set a switch to false
-a COLLECTION Add repeated values to a list
-A Add different values to list
-B Add different values to list
--version show program's version number and exitbut then... who has time to write all those switches..
docopt
"""Naval Fate.
Usage:
naval_fate.py ship new <name>...
naval_fate.py ship <name> move <x> <y> [--speed=<kn>]
naval_fate.py ship shoot <x> <y>
naval_fate.py mine (set|remove) <x> <y> [--moored | --drifting]
naval_fate.py (-h | --help)
naval_fate.py --version
Options:
-h --help Show this screen.
--version Show version.
--speed=<kn> Speed in knots [default: 10].
--moored Moored (anchored) mine.
--drifting Drifting mine.
"""
from docopt import docopt
if __name__ == '__main__':
arguments = docopt(__doc__, version='Naval Fate 2.0')
print(arguments)Where to go from here



Summary
- It is still programming
- Embrace the chaos
- Plumbing vs Architecting vs Building
- Document your steps ("Repeatable")
- Python is an expressive language. Learn it. Use it.
Thanks!
Contact:
@btbytes
http://github.com/btbytes
pradeep@btbytes.com
Slides will be on indypy's github repo
Plumbing for data science
By Pradeep Gowda
Plumbing for data science
Pythology Lecture Series - May 1, 2015
