In die Tiefe gehen:
Lektüre und Nutzung
digitaler Repräsentationen historischer Textzeugen.
Christian Thomas (HU & BBAW)


Digital-Humanities-Kolloquium an der BBAW, 6.10.2017
Gliederung
Teil I:
Thesen zur Lektüre (von (digitalen) Editionen)
im Zeitalter digitaler Medien;
Folgen für Produktion und Rezeption
Teil II:
Illustration der Thesen anhand konkreter Nutzungsbeispiele einer digitalen Edition
Thesen zur 'Lektüre' digitaler Editionen:
- Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
- Die Exploration der Grunddaten eröffnet weitere, eigene Lektüren (alternativ, konkurrierend, kontextualisierend z. Edition).
Digital-Humanities-Kolloquium an der BBAW, 6.10.2017
Thesen zur 'Lektüre' digitaler Editionen:
-
Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
- Edition = Auswahl, Interpretation, i.d.R. Vereinfachung.
- Die Edition wird über ein Interface – (e-)Buch, Website, HTML-/PDF-/etc.-Ausgabe – zugänglich gemacht und die Präsentation der Grunddaten wird für dieses Interface optimiert ==> weitere Auswahl, Interpretation, i.d.R. Vereinfachung.
- Beides sollte ausführlich dokumentiert werden, denn:
- Beide Prozesse sollten bei der Lektüre berücksichtigt werden!
Digital-Humanities-Kolloquium an der BBAW, 6.10.2017
Thesen zur 'Lektüre' digitaler Editionen:
-
Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
- Das Interface stellt den edierten Text dar, dabei je nach Medium mehr oder weniger tief strukturiert/annotiert.
- Die zugrunde liegenden Daten (und Metadaten) sind i.d.R. reichhaltiger als im Interface darstellbar; sie enthalten mehr Informationen als dort recherchierbar. (Bsp. Hybrid-Ed. MoE)
- > zur Lektüre: Menschen und Maschinen sollten diese Daten lesen können (und lesen dürfen)! (Negativ-Bsp. Asiatische Banise, s. Rez. AR)
Inspiriert vom Symposium DSEs as Interfaces (Graz 16), #DH2017, esp. @eerstewart1, @GretaFranzini #1, @GretaFranzini#2 u.v.a.
Digital-Humanities-Kolloquium an der BBAW, 6.10.2017
Thesen zur 'Lektüre' digitaler Editionen:
-
Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
- Das Interface ((e-)Buch, Website, HTML-/PDF-/etc.-Ausgabe) zeigt 1, 2, 3, ... von n Lektürewegen, kuratiert durch EditorIn.
- Die zugrunde liegenden Daten (und Metadaten) sind i.d.R. reichhaltiger als im Interface darstellbar; d.h. sie enthalten mehr Informationen als dort recherchierbar. (Bsp. Hybrid-Ed. MoE)
- > zur Lektüre: Menschen und Maschinen sollten diese Daten lesen können (und lesen dürfen)! (Negativ-Bsp. Asiatische Banise, s. Rez. AR)
Inspiriert vom Symposium DSEs as Interfaces (Graz 16), #DH2017, esp. @eerstewart1, @GretaFranzini #1, @GretaFranzini#2 u.v.a.
NB zum erwähnten u. vielen anderen Negativbeispielen:
Der fehlende Zugang zu den Grunddaten bzw. deren ständiger Verlust hat keine technischen Ursachen.
Es handelt sich v.a. um ein sozialisatorisches
(und auch förderpolitisches) Problem.
Digital-Humanities-Kolloquium an der BBAW, 6.10.2017
Thesen zur 'Lektüre' digitaler Editionen:
- Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
- Die Exploration der Grunddaten eröffnet weitere, eigene Lektüren (alternativ, konkurrierend, kontextualisierend z. Edition).
==> Diese können u. sollten durch die LeserInnen/NutzerInnen der Edition erschlossen werden ==> Lektüre im Digitalen.
Digital-Humanities-Kolloquium an der BBAW, 6.10.2017
Thesen zur 'Lektüre' digitaler Editionen:
- Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
-
Exploration der Grunddaten durch NutzerInnen = n Lektüren; Voraussetzungen dafür sind unter anderem:
- Gute Dokumentation (inhaltlich, editorisch und technisch)
- Zugang zu den Grunddaten & 'Data Literacy'
- Zugang zu geeigneten Tools¹ & 'Tool Literacy' (¹ z.B. für TEI-XML)
- i.d.R. erforderlich: Datenvor- & aufbereitung; -visualisierung
- Dokumentation der eigenen Lektüre (inhaltlich, (editorisch,) technisch); ggf. Bereitstellung der erzeugten Daten (z.B. edissPlus)
Digital-Humanities-Kolloquium an der BBAW, 6.10.2017
Einige Folgerungen für Produktion und Rezeption:
- Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
-
Exploration der Grunddaten durch NutzerInnen = n Lektüren; daher umso wichtiger:
- Lektürewege als vom Editor/in ausgewählt kennzeichnen.
- Nicht (nur) das Interface wichtig, sondern Reichhaltigkeit u. flexible Nutzbarkeit der Daten (für Menschen u. Maschinen).
- Traditionell: Lektüre auf autorisierten Pfaden (via Interface)
- +Digital: Exploration der Daten (via Download/API/...)
= Lektüre auf eigenen Pfaden, lesend und mit Tools.
Digital-Humanities-Kolloquium an der BBAW, 6.10.2017
II: Illustration der Thesen
Hintergrund:
Projekt "Hidden Kosmos":
Edition/Textkorpus
Nachschriften der 'Kosmos-Vorträge' A. v. Humboldts


Humboldts 'Kosmos-Vorträge'
- Berlin, 1827/28; ! ≠ Kosmos, 1845–62
- keine autorisierte Publikation der Vorträge durch Humboldt
- Humboldt verbat sich Druck von Nachschriften, "Eingriff in mein Eigenthum" (Spenersche Zeitung, 12.12.1827)
nichts […] widerwärtiger, als publicirt
zu sehen, was ein Gemisch von Gehörtem
und Selbstzugesetztem ist.“
(A.v.H an R. Zeune, Berlin, 16.2.1857)
Anonym (Hrsg.) 1934
Hamel/Tiemann (Hrsg.) 1993 [2. A. 2004]


Humboldts 'Kosmos-Vorträge'
- Berlin, 1827/28, zwei Kurse:
- Berliner Universität, 62 Stunden,
~400 Studis, Staff, Gasthörern -
Sing-Akademie, 16 Stunden,
~1000 HörerInnen 'gemischtes' Publikum
- Berliner Universität, 62 Stunden,
... ein Meilenstein der
Wissenschaftspopularisierung
(Hamel/Tiemann 1993)

(c) Schiller-Nationalmuseum, Marbach
Humboldts 'Kosmos-Vorträge'
- Berlin, 1827/28; ! ≠ Kosmos, 1845–62
- keine autorisierte Publikation der Vorträge durch Humboldt
- A.v.H.s ursprüngliche Manuskripte
im Nachl. verstreut, aber (z.T.) erhalten
– entgegen Humboldts Angaben:
Bei freier Rede habe ich [...]
nichts über meine Vorträge schriftlich aufgezeichnet
(A.v.H in der 'Vorrede' zum Kosmos, Bd. 1, S. X.)

Humboldts 'Kosmos-Vorträge'




SBB-PK, Nachl. A.v.H., diverse Fragmente des Manuskripts bzw. Materialien zu Humboldts Vorträgen
Projekt "Hidden Kosmos"

≈ 3600 Seiten,
≈ 4,5M Zeichen,
≈ 660K Tokens,
≈ 103K Types.
Projekt "Hidden Kosmos"

≈ 3600 Seiten,
≈ 4,5M Zeichen,
≈ 660K Tokens,
≈ 103K Types.
Nachschriften der 'Kosmos-Vorträge' A. v. Humboldts

| Projekt- Förderung |
Texterfassung und -anntoation | Publikation und ling. Erschließg. | Nachhaltigkeit & Dissemination |
|---|

Nachschriften der 'Kosmos-Vorträge' A. v. Humboldts
| Texterfassung und -anntoation | Publikation und ling. Erschließg. |
|---|
Texterfassung und -Annotation gemäß P5 Text Enoding Initiative
“The TEI-C is… a consortium which collectively develops and maintains
a standard for the representation of texts in digital form.” (http://www.tei-c.org/)
TEI-C = Herausgeber der TEI Guidelines:
- XML-basierter, freier, internationaler (de facto-) Standard
- umfassend dokumentiert
- plattformunabhängig, flexibel nutzbar
- menschen- & maschinenlesbar
- generische und TEI-spezifische Tools
- (prinzipiell) interoperabel

DTA-Basisformat für Manuskripte


Cf. Haaf/Thomas 2017, https://jtei.revues.org/1650

Texterfassung und -Annotation
- erweitertes DTA-Basisformat (DTABf):
DTABf für Manuskripte (DTABf-M) - Metadaten, Dokument-Struktur, 'Typographie'
<!-- […] -->
<pb facs="#f0007" n="2r"/>
<!-- […] -->
<div n="1">
<head>Physikalische Geographie bei <persName resp="#CT" ref="http://d-nb.info/gnd/118554700">A. v. Humboldt</persName>.</head><lb/>
<milestone rendition="#hr" unit="section"/><lb/>
<div type="session" n="1">
<head type="rightMargin">
<!-- […] --><hi rendition="#b">1.</hi><space dim="horizontal"/> 3. <choice><abbr>Nov.</abbr><!-- […] -->
</head><lb/>
<p>Als Einleitung in die <choice><abbr>physik.</abbr><expan resp="#CT">physikalische</expan></choice>
<choice><abbr>Geogr.</abbr><expan resp="#CT">Geographie</expan></choice> gebe ich eine Übersicht<lb/>
der Zustände im allgemeinen, in welchen die Materie uns<lb/>
im Weltraume erscheint, und fange daher mit denjenigen<lb/>
Körpern an<del rendition="#s">,</del> welche in der Lichtbildung begriffen scheinen.<lb/>
<!-- […] -->
</p><lb/>
<!-- […] -->
Texterfassung und -Annotation
- Manuskript-typische Textmerkmale wie Überschreibungen, @hand-Wechsel, <metamark/>s u.a.

Texterfassung und -Annotation
- Manuskript-typische Textmerkmale wie Überschreibungen, @hand-Wechsel, <metamark/>s u.a.
-
= wichtig (nicht nur)
für Nachschriften: Eingriffe Dritter, Unsicherheiten und Fehler(!) der Schreiber usw.
Texterfassung und -Annotation:
Nutzungsmöglichkeiten
Beispiel: Bleistift-Gebrauch in parthey_msgermqu1711_1828 (XML)

Texterfassung und -Annotation:
Nutzungsmöglichkeiten
Beispiel: Bleistift-Gebrauch in parthey_msgermqu1711_1828 (XML)

Texterfassung und -Annotation:
Nutzungsmöglichkeiten
Beispiel: Bleistift-Gebrauch in parthey_msgermqu1711_1828 (XML)
> Mehrzahl im Abschnitt Geographie des Organischen
- 54. St.: Kennzeichen des Organischen
- 55.–57. St.: Geographie der Pflanzen
- 58. St.: Geographie der Thiere
Texterfassung und -Annotation:
Nutzungsmöglichkeiten



Texterfassung und -Annotation
- Auszeichnung von <persName> mit @ref GND/VIAF/Wikidata/...
<item>3, die <hi rendition="#u">englischen</hi> Messungen unter dem
General <persName resp="#CT" ref="http://d-nb.info/gnd/130800600">
R.<metamark><space dim="horizontal"/></metamark></persName>
<metamark>(?)</metamark> und
<persName resp="#CT" ref="http://d-nb.info/gnd/1055317457">M<metamark>....</metamark></persName>
<add place="right"><metamark>?</metamark></add><lb/>
<!-- [...] --> <item>4, Drei grosse Messungen in <hi rendition="#u">Ostindien</hi> von dem
General <persName resp="#CT" ref="http://d-nb.info/gnd/117574406">
L<metamark><space dim="horizontal"/></metamark></persName>
<metamark>?</metamark><lb/>
und <persName>T<metamark><space dim="horizontal"/></metamark></persName> <metamark>?</metamark></item><lb/>
Texterfassung und -Annotation
- Auszeichnung von <persName> mit @ref GND/VIAF/Wikidata/...

<choice><abbr>Rſe</abbr><expan resp="#SB">Reiſe</expan></choice> <choice><abbr>ds</abbr><expan resp="#SB">des</expan></choice>
<hi rendition="#aq">
<persName resp="#SB" ref="http://d-nb.info/gnd/100648282">
Kuki</persName></hi><lb/>
Texterfassung und -Annotation


Texterfassung und -Annotation
- Ansetzung vs. Vorlage:
- Welche Namen waren dem Publikum bekannt, welche nicht?
- Anzahl der Vorkommen pro Nachschrift und insgesamt:
- z.B. Uni vs. Sing-Akad.: Welches Personal für welchen Kurs?
- Ältere vs. aktuelle Forschung: Nachwuchsförderer A.v.H?
- Kosmos-Vorträge auf der Höhe der wiss. Forschung der Zeit?
- Welcher Nachschreiber 'überhört' welche Personen?
- Vernetzung: API/BEACON:
- z.B. Porträtindex/Wikimedia Comm.s, edition-humboldt.de ...
Personenregister: Nutzungsmöglichkeiten und Anschlussfragen



Siehe auch: Instrumente

Siehe auch: Bibliographie

Datensets für Coding da Vinci


Zugriff auf die Texte via DTA









Text-Bild-Ansicht:
- Text-Darstellung
(= XSLT-Transformation aus DTABf-M XML) - z.B. HTML: inklusive
graphischer Umsetzung einiger Elemente der Annotation


dies fand
<subst>
<del rendition="#s" hand="#pencil">
<subst>
<del rendition="#ow">
<supplied reason="covered" cert="high" resp="#CT">ich</supplied>
</del>
<add place="across" hand="#ink2">
<persName ref="http://d-nb.info/gnd/118554700">Humbold</persName></hi>
</add>
</subst>
</del>
<add place="superlinear" hand="#pencil">ich</add>
</subst> auf dem Chimboraßo,
<!-- Beispiel vereinfacht: <hi> entfernt, cf. http://www.deutschestextarchiv.de/nn_msgermqu2345_1827/17 -->
Abriſſe liefern
<subst>
<del rendition="#ow">w<unclear reason="covered" cert="low" resp="#BF">ü</unclear></del>
<add place="across">dü</add>
</subst>r
<subst>
<del rendition="#ow"><unclear reason="covered" cert="low" resp="#CT">de</unclear></del>
<add place="across">fte</add>
</subst>, welches<lb/>

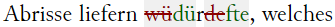
HTML
TEXT
Abriſſe liefern
<subst>
<del rendition="#ow">w<unclear reason="covered" cert="low" resp="#BF">ü</unclear></del>
<add place="across">dü</add>
</subst>r
<subst>
<del rendition="#ow"><unclear reason="covered" cert="low" resp="#CT">de</unclear></del>
<add place="across">fte</add>
</subst>, welches<lb/><TextCorpus>
<tokens>
<!--[...]-->
<token ID="w14c">Abriſſe</token>
<token ID="w14d">liefern</token>
<token ID="w14e">dürfte</token>
<token ID="w14f">,</token>
<token ID="w150">welches</token>
<!--[...]-->
</tokens>
<sentences>
<sentence ID="sc" tokenIDs="<!--[...]--> w14c w14d w14e w14f w150 <!--[...]-->"/>
</sentences>
<lemmas>
<!--[...]-->
<lemma tokenIDs="w14c">Abriß</lemma>
<lemma tokenIDs="w14d">liefern</lemma>
<lemma tokenIDs="w14e">dürfen</lemma>
<lemma tokenIDs="w14f">,</lemma>
<lemma tokenIDs="w150">welches</lemma>
<!--[...]-->
</lemmas>
<POStags>
<!--[...]-->
<tag tokenIDs="w14c">NN</tag>
<tag tokenIDs="w14d">VVINF</tag>
<tag tokenIDs="w14e">VMFIN</tag>
<tag tokenIDs="w14f">$,</tag>
<tag tokenIDs="w150">PWS</tag>
<!--[...]-->
</POStags>
<orthography>
<!--[...]-->
<correction tokenIDs="w14c" operation="replace">Abrisse</correction>
<!--[...]-->
</orthography>
</TextCorpus>TCF
<choice>
<orig>Abriſſe</orig>
<reg resp="#cab">Abrisse</reg>
</choice> liefern
<choice>
<orig>
<subst>
<del rendition="#ow">w<unclear reason="covered" cert="low" resp="#BF">ü</unclear></del>
<add place="across">dü</add>
</subst>r
<subst>
<del rendition="#ow"><unclear reason="covered" cert="low" resp="#CT">de</unclear></del>
<add place="across">fte</add>
</subst>
</orig>
<reg resp="#cab">dürfte</reg>
</choice>, welches<lb/>DTA-'norm.xml'

Abriſſe liefern
<subst>
<del rendition="#ow">w<unclear reason="covered" cert="low" resp="#BF">ü</unclear></del>
<add place="across">dü</add>
</subst>r
<subst>
<del rendition="#ow"><unclear reason="covered" cert="low" resp="#CT">de</unclear></del>
<add place="across">fte</add>
</subst>, welches<lb/>Zugriff auf die Texte via DTA/DDC


DTA-Analysen, z.B. SemCloud

DTA-Analysen, z.B. DiaCollo

DDC-Suche mit GermaNet
DDC-Suche mit GermaNet-Erweiterung, Synset "Grundstoff; Urstoff"

Externe Tools: Voyant
Externe Tools: WCopyfind



Externe Tools: WCopyfind







Digital-Humanities-Kolloquium an der BBAW, 6.10.2017
Thesen zur 'Lektüre' digitaler Editionen:
- Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
-
Exploration der Grunddaten durch NutzerInnen = n Lektüren; Voraussetzungen dafür sind unter anderem:
- Gute Dokumentation (inhaltlich, editorisch und technisch)
- Zugang zu den Grunddaten & 'Data Literacy'
- Zugang zu geeigneten Tools¹ & 'Tool Literacy' (¹ z.B. für TEI-XML)
- i.d.R. erforderlich: Datenvor- & aufbereitung; -visualisierung
- Dokumentation der eigenen Lektüre (inhaltlich, (editorisch,) technisch); ggf. Bereitstellung der erzeugten Daten (z.B. edissPlus)
Digital-Humanities-Kolloquium an der BBAW, 6.10.2017
Literaturempfehlungen (Auswahl):
-
John Unsworth: "Scholarly Primitives: what methods do humanities researchers have in common, and how might our tools reflect this?", [J. Unsworth' Blog], 2000 cf. http://www.people.virginia.edu/~jmu2m/Kings.5-00/primitives.html.
-
Patrick Sahle: Digitale Editionsformen. Zum Umgang mit der Überlieferung unter den Bedingungen des Medienwandels, 3 Bände, Norderstedt: Books on Demand 2013.
-
Ted Underwood: "It looks like you’re writing an argument against data in literary study …" In: The Stone and the Shell, 21. Sept. 2017.
-
Ders.: A Genealogy of Distant Reading. In: DHq, 11, 2 (2017).
#DHBBAW-Kollkquium 6.10.2017
By Christian Thomas
#DHBBAW-Kollkquium 6.10.2017
Christian Thomas (BBAW, HU Berlin) In die Tiefe gehen: Lektüre- und Nutzungsmöglichkeiten digitaler Repräsentationen historischer Textzeugen. Der Vortrag gibt zunächst einen Einblick in die Erstellung TEI-XML-basierter Text-Editionen mit einem Fokus auf Handschriften des 19. Jahrhunderts (am Beispiel der Nachschriften zu Humboldts Kosmos-Vorlesungen 1827/28 in Berlin). Anhand dessen wird erläutert, inwiefern sich die Repräsentation historischer Textzeugen im Zuge des Medien- bzw. Paradigmenwechsels von printorientierten Formaten hin zu genuin digitalen Editionsformen verändert. Dies hat zum einen Auswirkungen auf Produktionsseite, d.h. auf die editorische Praxis, vor allem aber – und hierauf wird der Schwerpunkt des Vortrags liegen – auf die Rezeptionsseite: Digitale Edition müssen nicht nur anders konzipiert und produziert, sondern auch anders gelesen werden, will man das Potential der (in der germanistischen Editionsphilologie teilweise immer noch:) ‘neuen’ Medien ausschöpfen. Die Editionspraxis schreitet von der linearen Auszeichnung textoberflächlicher Phänomene bzw. deren an- oder nachgelagerter diskursiver, spezifischer Beschreibung weiter in Richtung standardisierter, formalisierter Annotation, die in die mehrdimensionale, vielschichtige Tiefe des Textzeugen führt.



