


















Daniel Morandini
Software Developer @KIM
Andreas Unterhuber and Daniel Morandini
KIM Keep In Mind GmbH
25/10/2023 - 14th Workshop Computer Science Research Meets Business
www.keepinmind.info
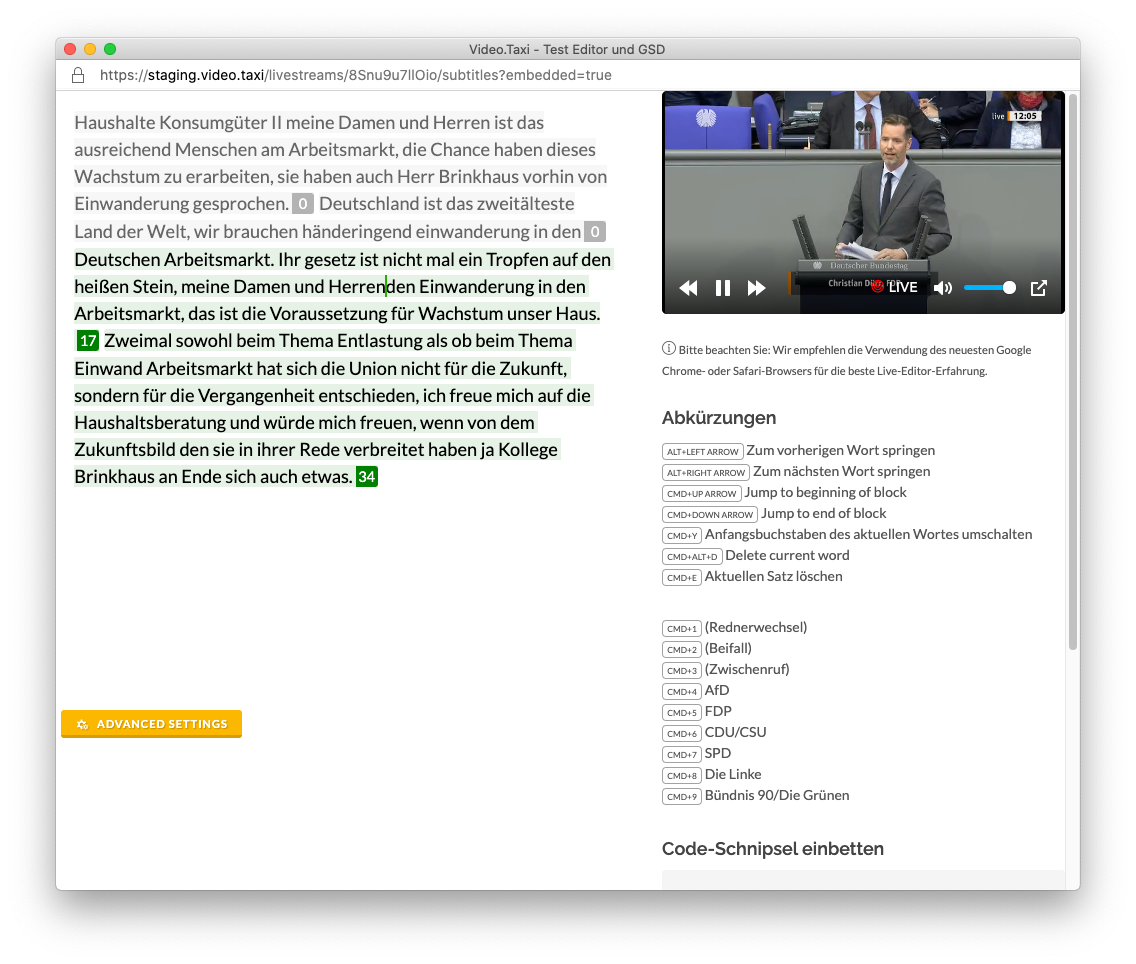
Automatic subtitle generation, player screenshot
Humans in the loop, subtitle editor screenshot
Still too much human intervention!
(late 2022)
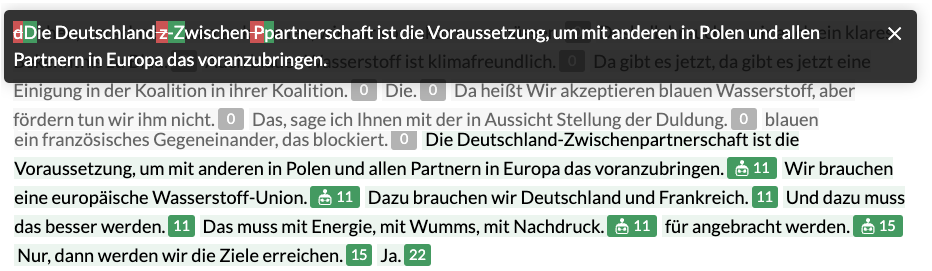
Original Sentence
Corrected Sentence
align tokens and corrections
Corrections Vocabulary
Original Sentence
Corrected Sentence
find correction tags for each original token
Corrections Vocabulary
Sentence
Correction Labels
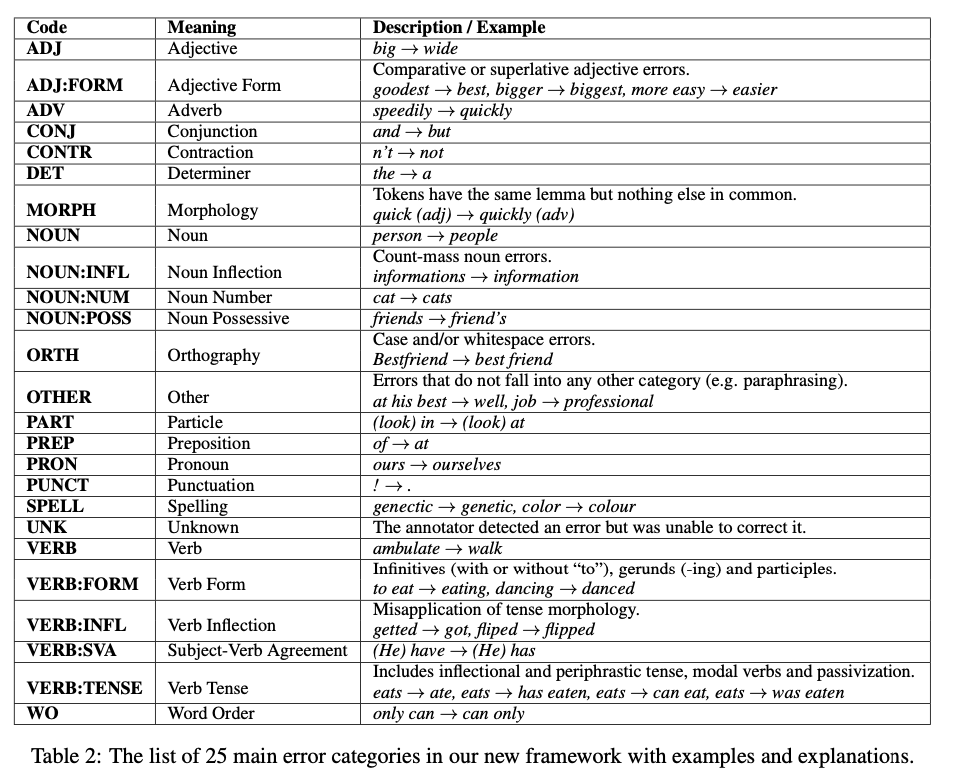
| CATEGORY | IMPACT |
|---|---|
| R:ORTH | 13% |
| M:PUNCT | 10% |
| R:SPELL | 10% |
| R:NOUN | 7% |
| U:PUNCT | 7% |
| R:PUNCT | 4% |
| TOTAL | 51% |
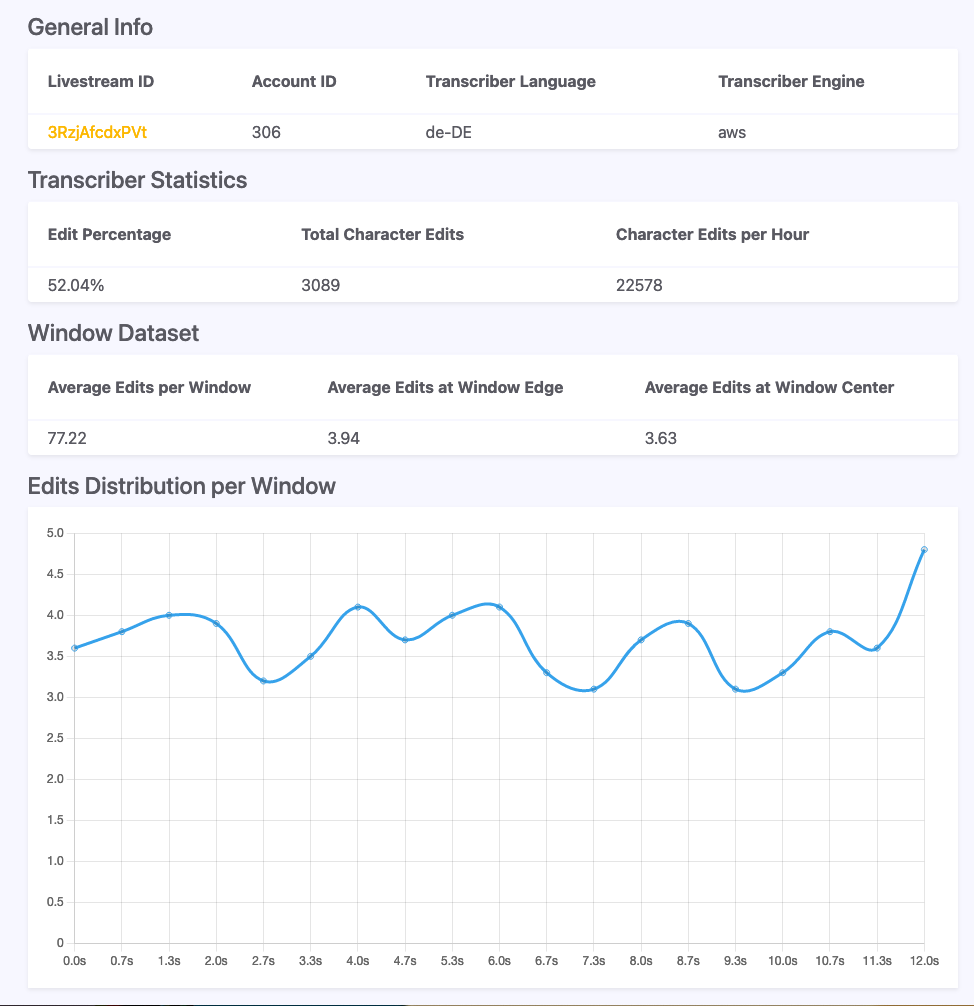
=========== Token-Based Detection ============
TP FP FN Prec Rec F0.5
46625 24798 60177 0.6528 0.4366 0.594
==============================================
Andreas Unterhuber and Daniel Morandini
KIM Keep In Mind GmbH
25/10/2023 - 14th Workshop Computer Science Research Meets Business
www.keepinmind.info
By Daniel Morandini



