Streamlining Site Migrations
Agenda
- Review of the migration tool/concept: Quack
- Philosophy
- Process
- Code
- Discuss going forward

(Q)uack Philosphy
-
Distributed
- Able to run on multiple machines so we can control speed and so that it scales to any site
-
Source Agnostic
- Able to import data from any site and source or mix of sources
- DB Connection
- Binary files
- Site Scraping
- Able to import data from any site and source or mix of sources
-
Modular and Reusable
- Written in a manner that allows us to reuse code from one migration to the next
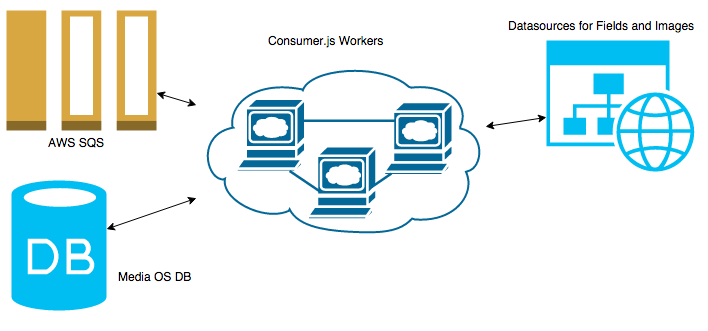
Distributed
Uses AWS SQS to distribute the work across any number of machines / EC2 instances.
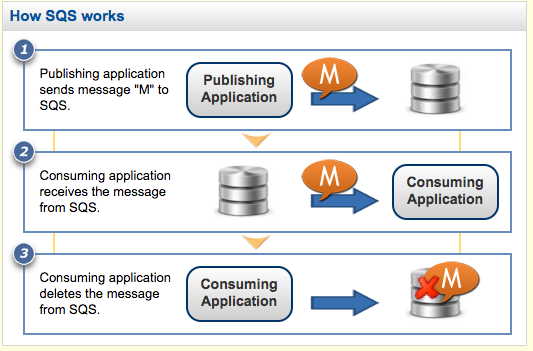
Cluster SSH running jobs
Source Agnostic
The data driver is modular so we can pull data using page scraping, a db connection, binary files, or combination of multiple sources. This lets you get the data faster.
function getImage(post_id, typeOfCall) {
if ( typeof typeOfCall === 'undefined') {
typeOfCall = "/?p=";
} else {
typeOfCall = "/?attachment_id=";
}
return new RSVP.Promise(function(resolve, reject) {
curl.fromUrl(config.live_url + typeOfCall + post_id, function(err, res) {
if (!err && typeOfCall == "/?attachment_id=" && res.images.length > 0) {
res.image = res.images[6].replace('-300x300.jpg', '.jpg');
res.link = config.live_url + typeOfCall + post_id;
res.title = res.title.replace(' - Prima', '').replace(/-/g, ' ').trim();
if (res.openGraphDescription == '') {
res.openGraphDescription = res.title;
}
resolve(res);
}
reject('Curl Failed');
});
});
}
Modular and Reusable
Quack is written in NodeJS and relies heavily on modules and promises. This allows us to reuse code between migrations and make use of the NPM
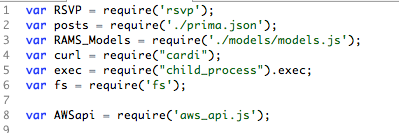
High Level Overview of Process
main.js
- Define 'message' (ID and job_name)
- create corresponding job_name function that uses the message ID as a parameter
- Create Q
- Populate Q with all messages
- Create EC2 Instances
- Upload self onto instance
- Run Consumer. JS
Practically Speaking
- Define URLs as message, and the job_name as process_url.
- Define process_url function to scrape the url given for the fields needed.
- For Prima I did this manually and put it in a config file.
- Use a sitemap or crawler to populate the Q with all the URLS you want to import.
- For Prima I did this manually.
- For Prima I did this manually
- For Prima I did this manually
High Level Overview of Process
Consumer.js
- Get message from Q
- Run job from message and pass ID as parameter
- Delete message only on success
- Get next Message
Practically Speaking
- get the URL and job from the Q
- Pass URL to the the process_url function
- Delete message from Q.
function processMessage(message) {
var postMessage = JSON.parse(message.Body);
// postMessage.type decides what work we need to run
switch (postMessage.type) {
case 'article':
// postMessage.post_id is the message lookup ID to run the job
getArticle(posts[postMessage.post_id])
.then(getFeatureImage)
.then(insertImage)
.then(insertEditor)
.then(addRedirects)
.then(insertArticle)
.then(function(post){
//DELETE MESSAGE FROM Q
removeFromQueue(message);
//GET NEW MESSAGE
main();
})
.catch(handleErr);
break;
case 'gallery':
getGallery(posts[postMessage.post_id])
.then(getFeatureImage)
.then(insertImage)
.then(insertEditor)
.then(addRedirects)
.then(getGalleryImages)
.then(insertGallery)
.then(function(post) {
removeFromQueue(message);
main();
})
.catch(handleErr);
break;
}
}
Beta Code
only on success
Future Plans
- Write a RAMS DB connector and remove current PHP dependency
- refactor code so its more modular
- automate the site scaffolding
- create and update RAMS models to handle features as necessary
- recipes
- collections
- tv shows
- Create frontend UI
- 2 to X weeks of work?

now what.
Streamlining Site Migrations
By Daniel Nakhla
Streamlining Site Migrations
Quick Intro into the dev behind migrating site content into mediaos
