


Daniel Himmelstein
Head of Data Integration at Related Sciences. Digital craftsman of the biodata revolution.
July 8, 2015
Daniel Himmelstein
Sergio Baranzini Lab
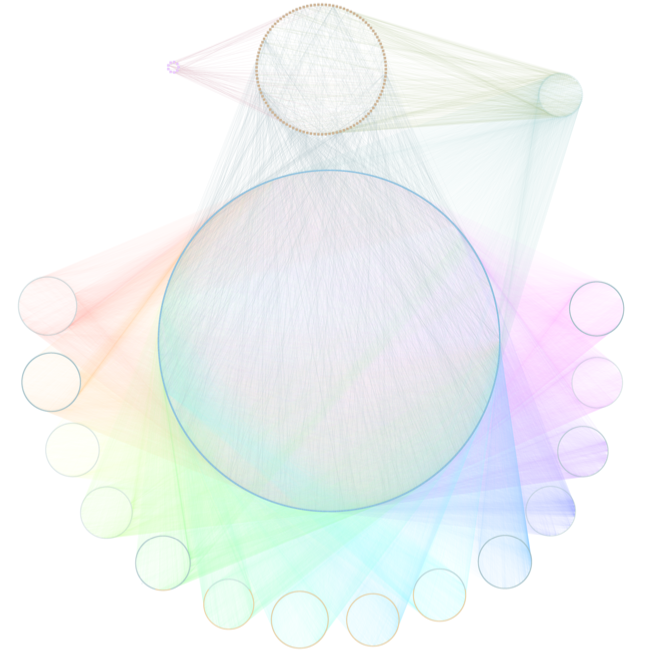
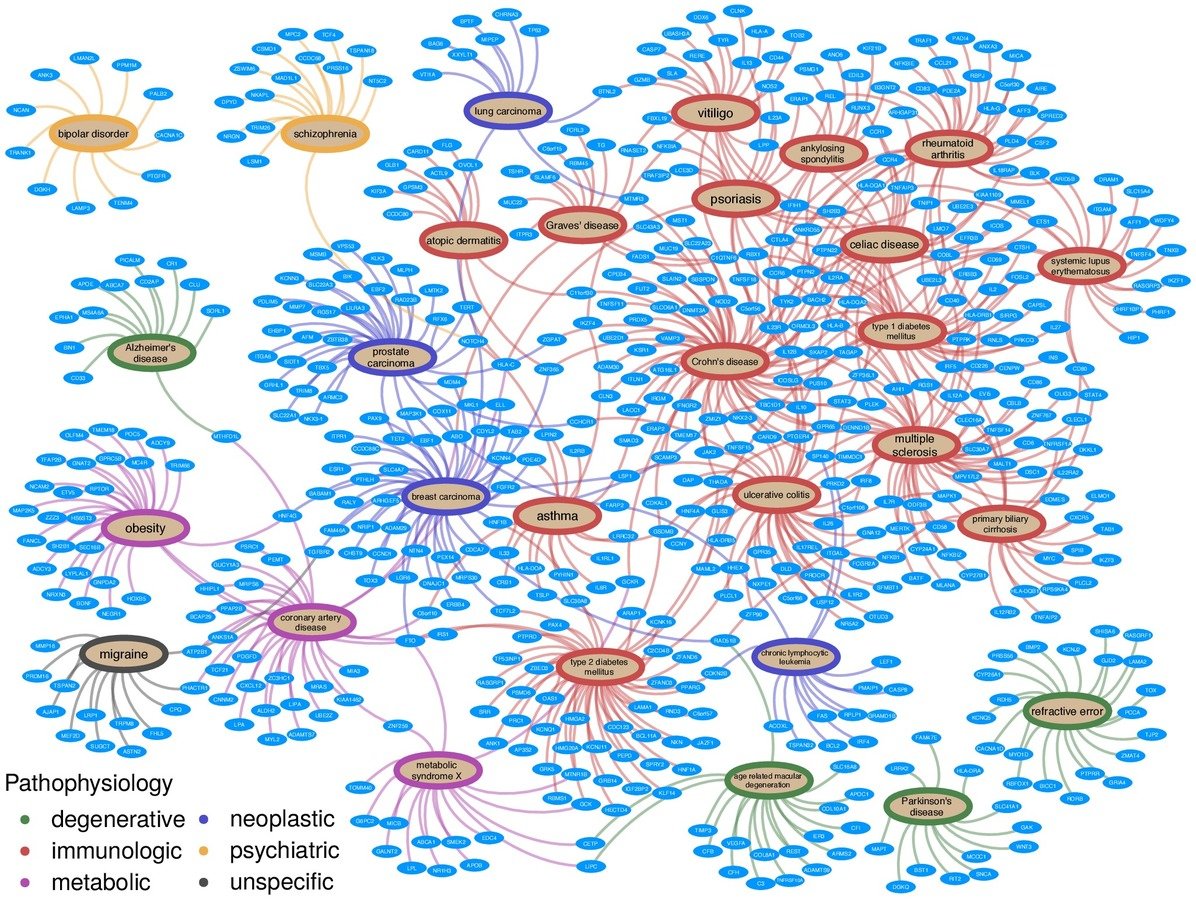
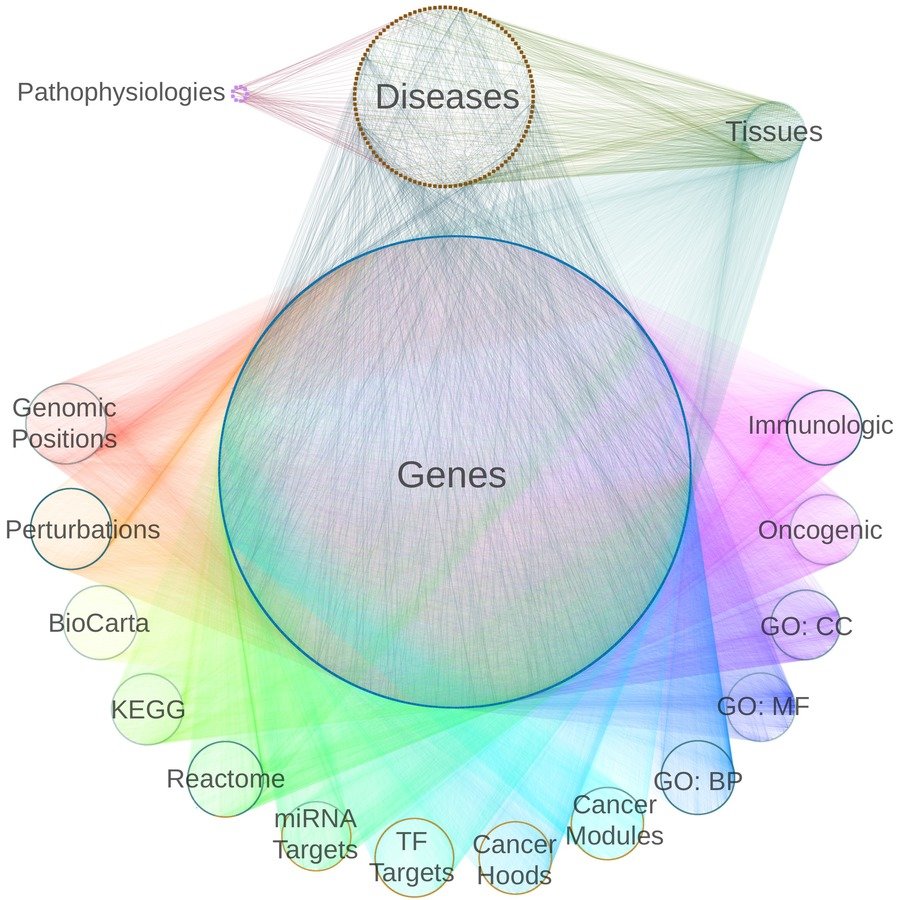
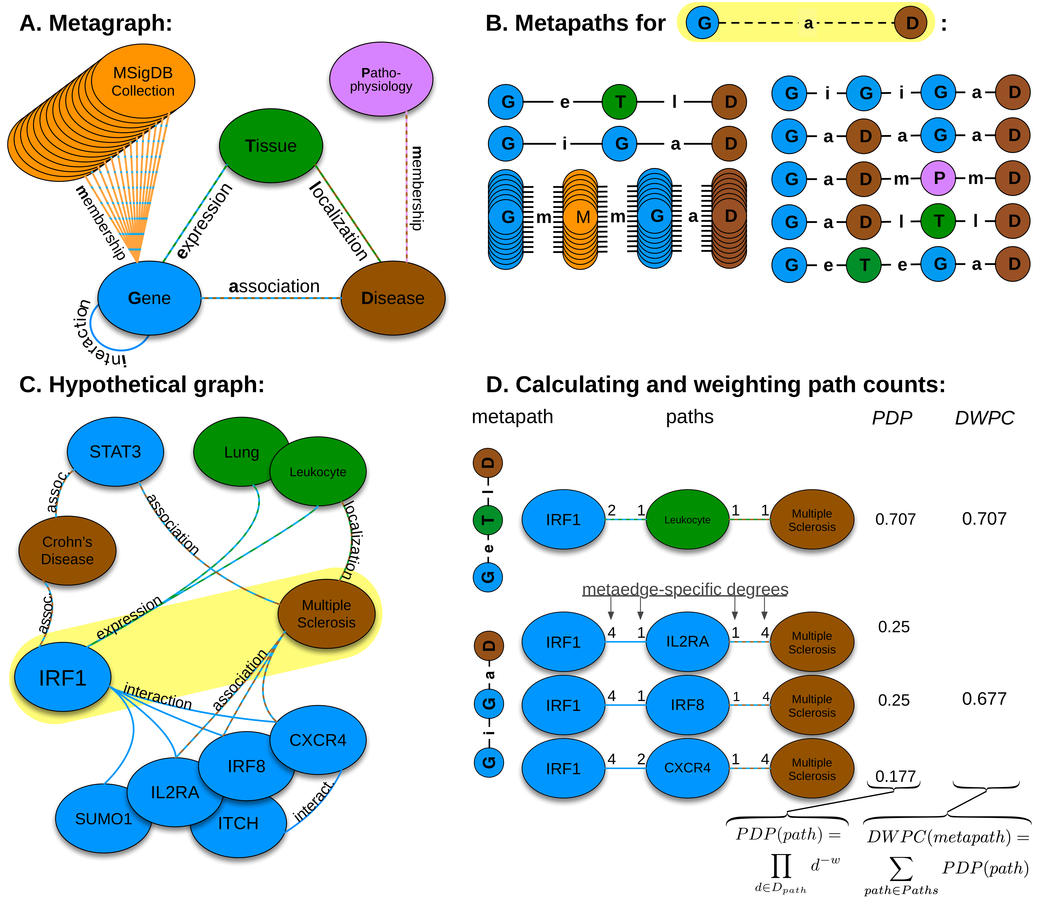
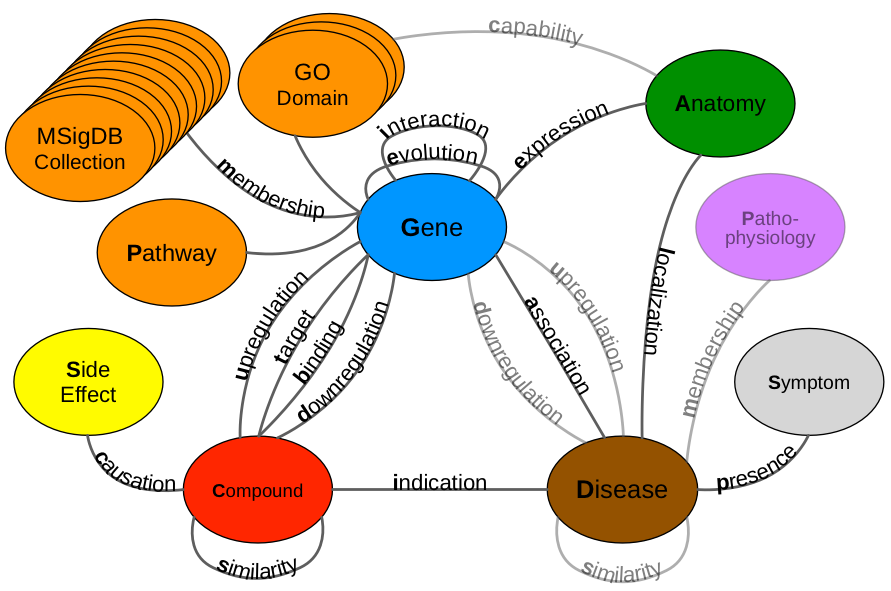
network of pathogenesis:
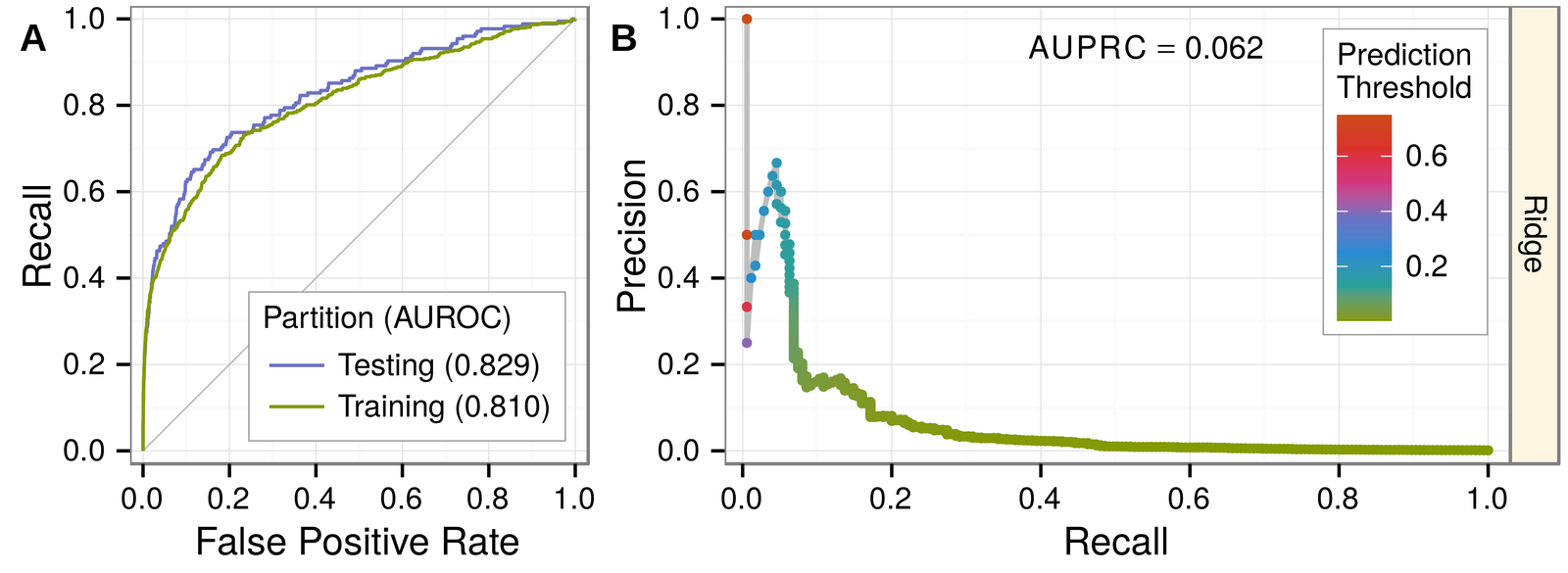
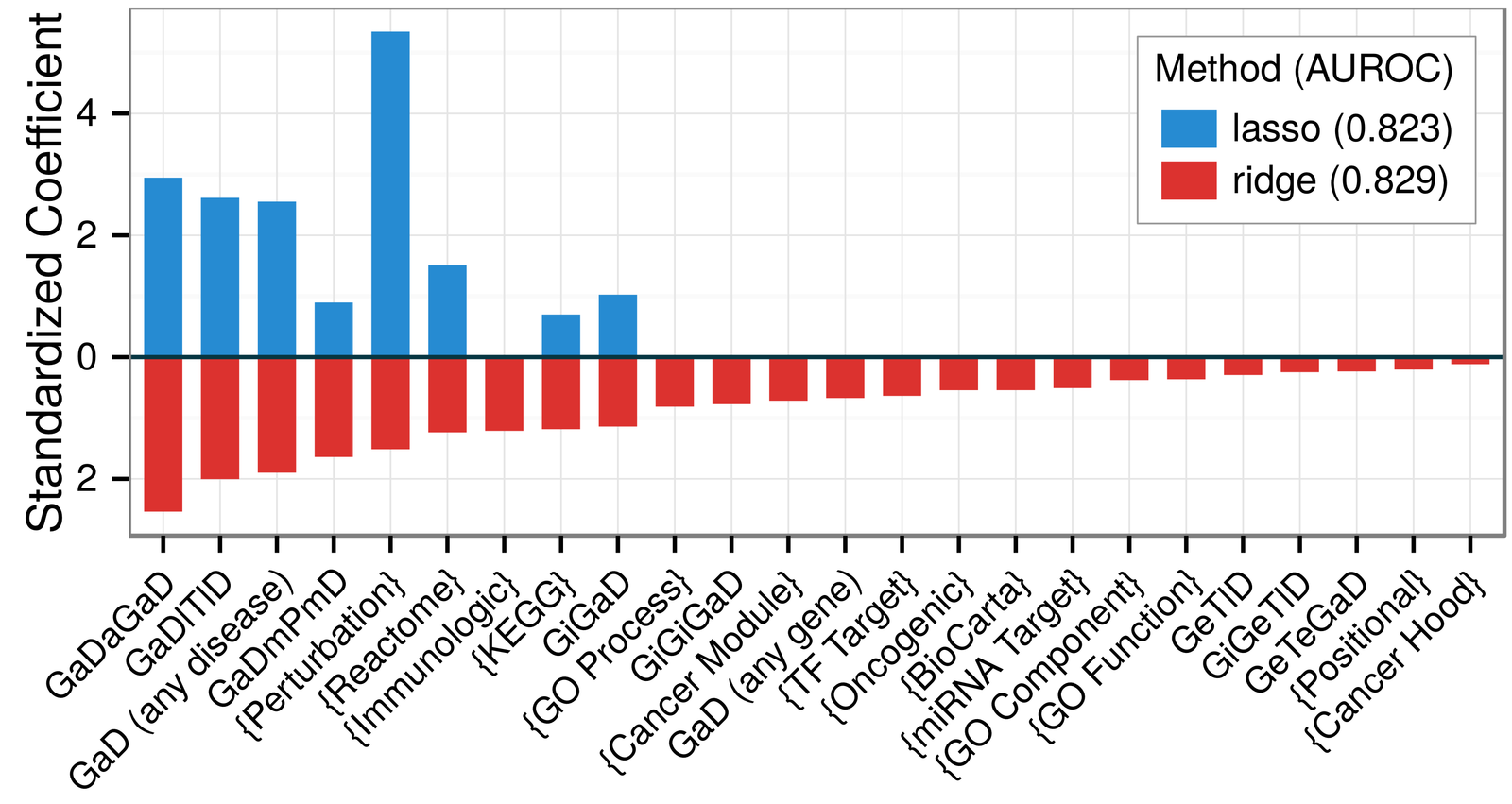
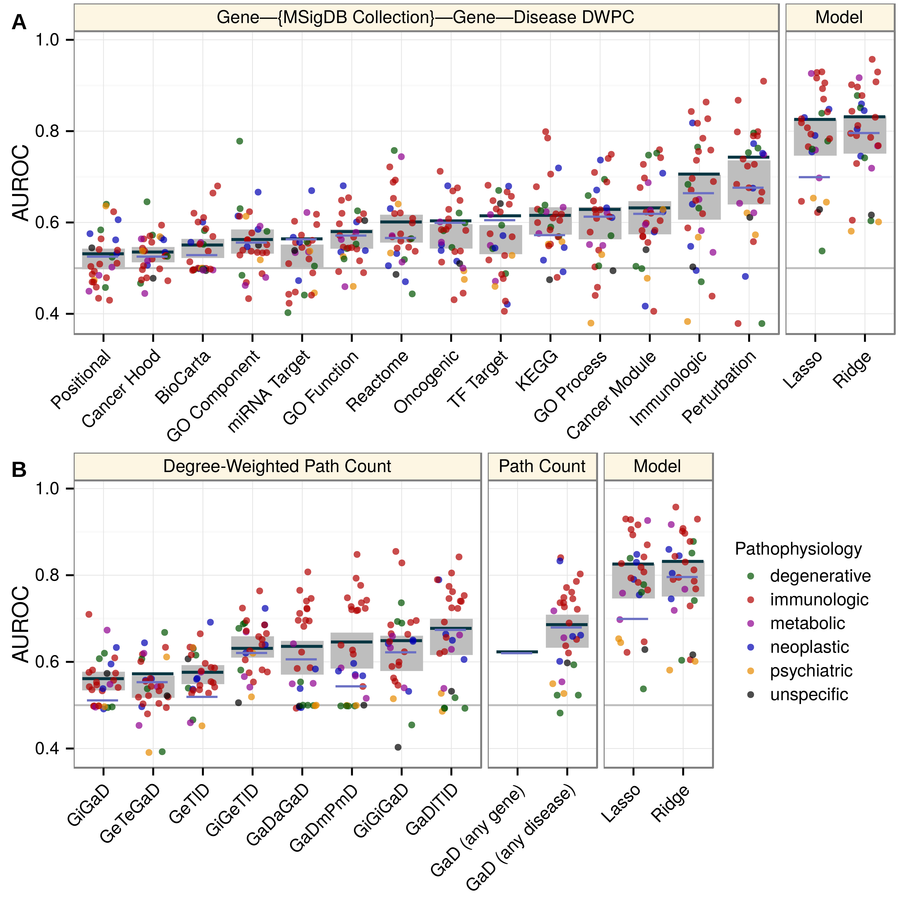
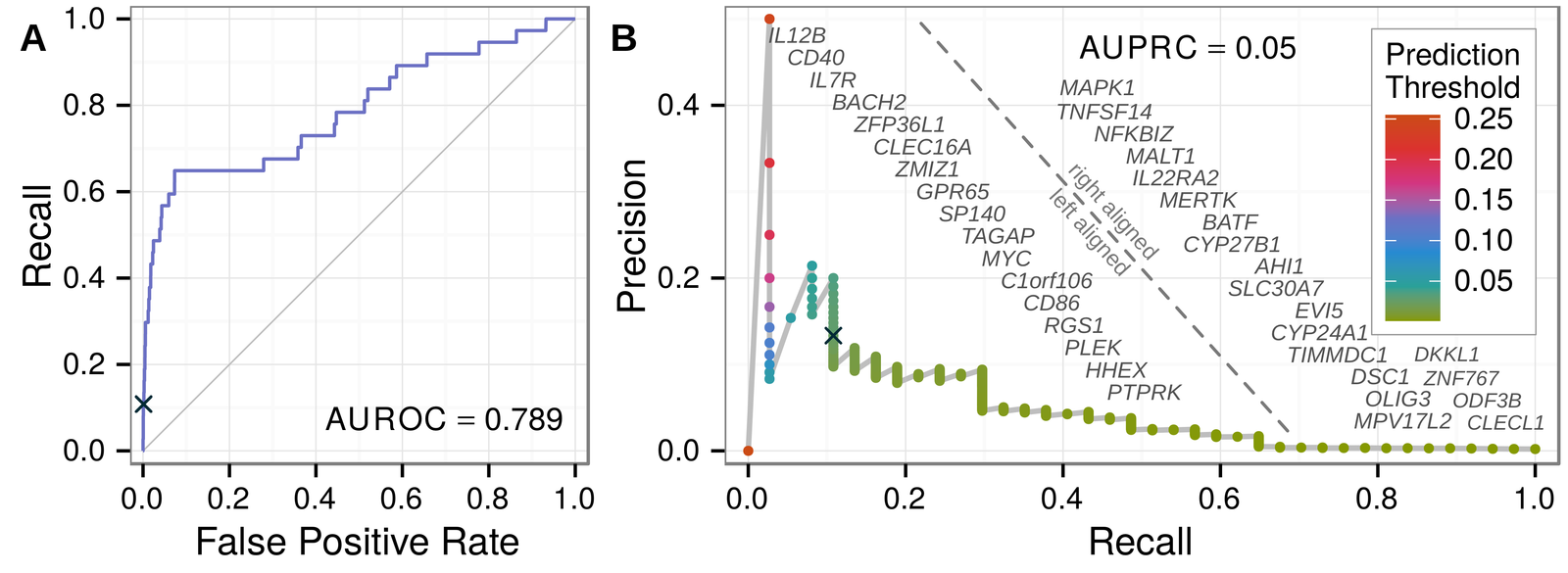
classifier:
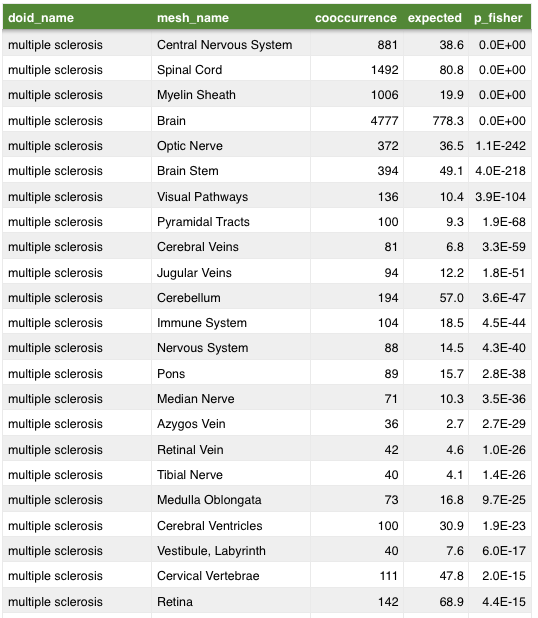
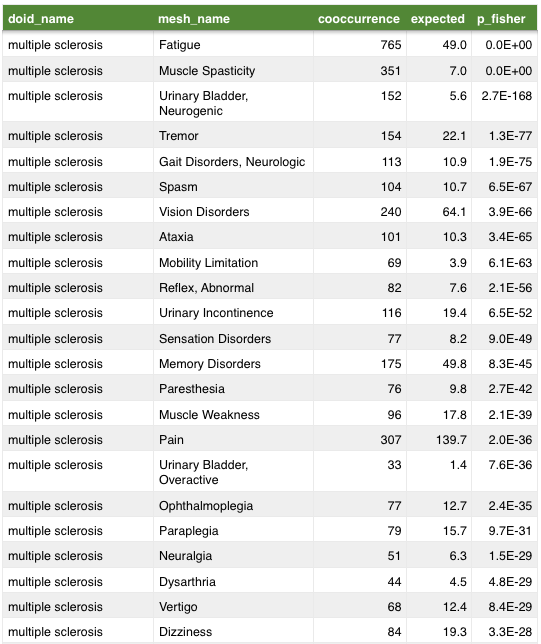
mechanisms of pathogenesis:
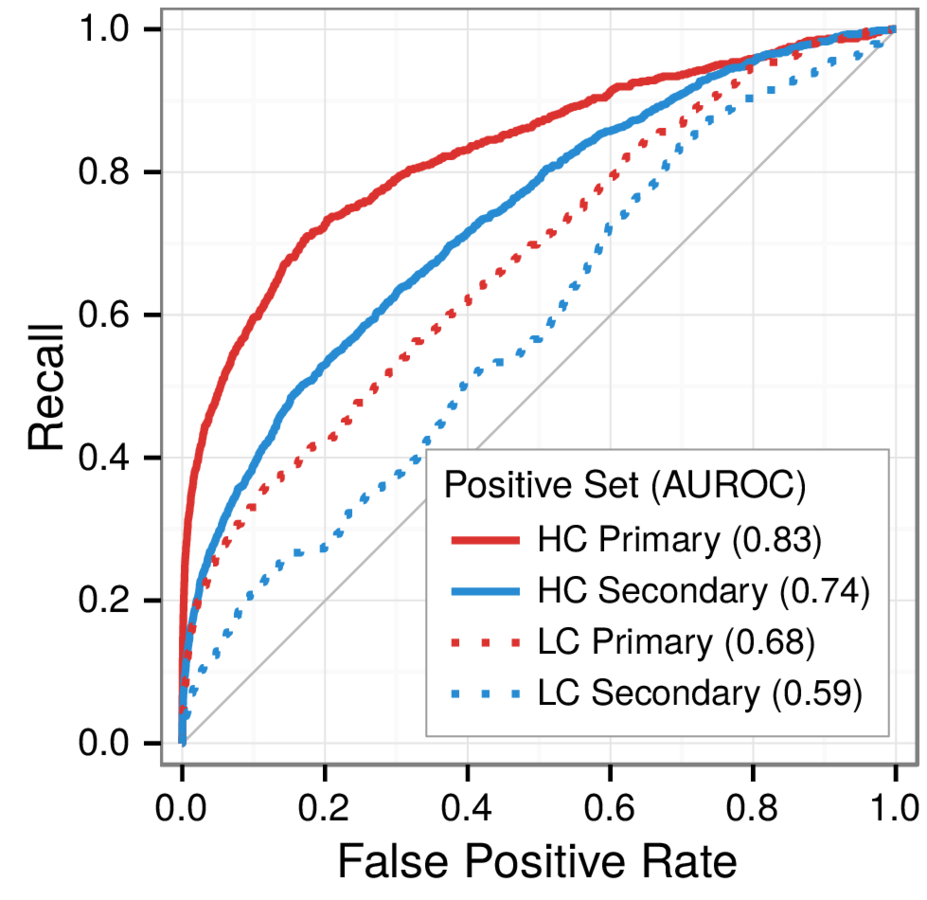
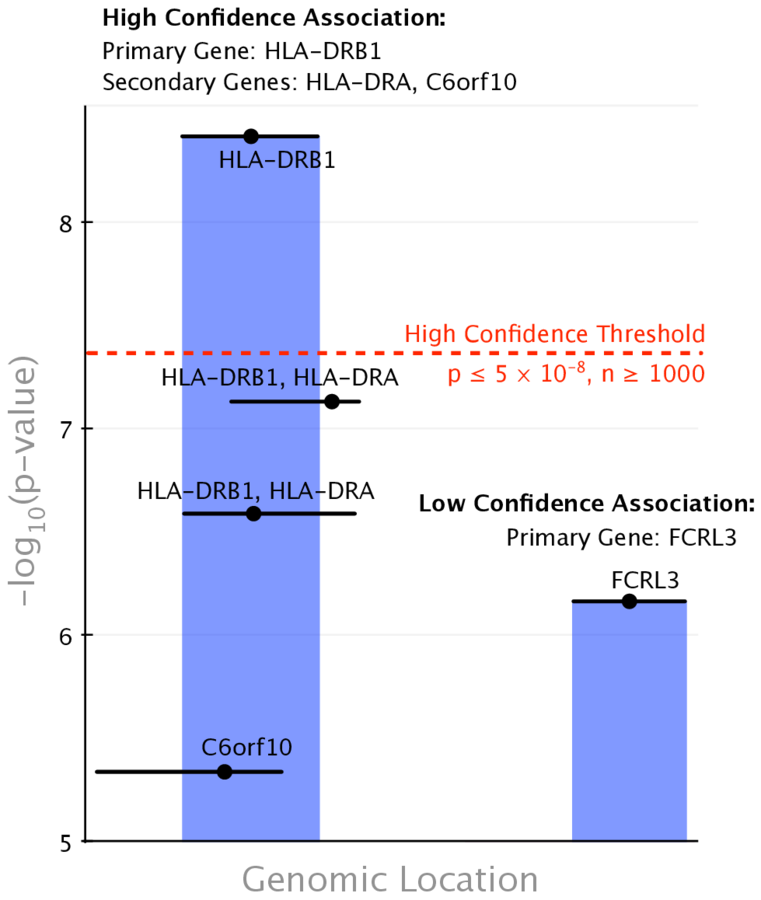
gold standard for our supervised approach
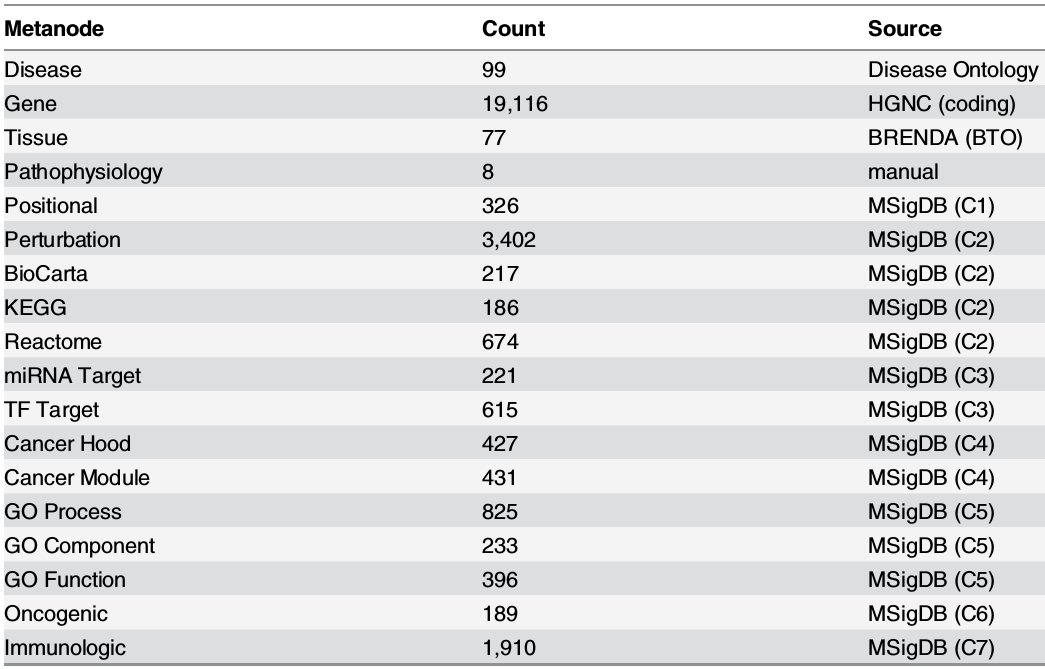
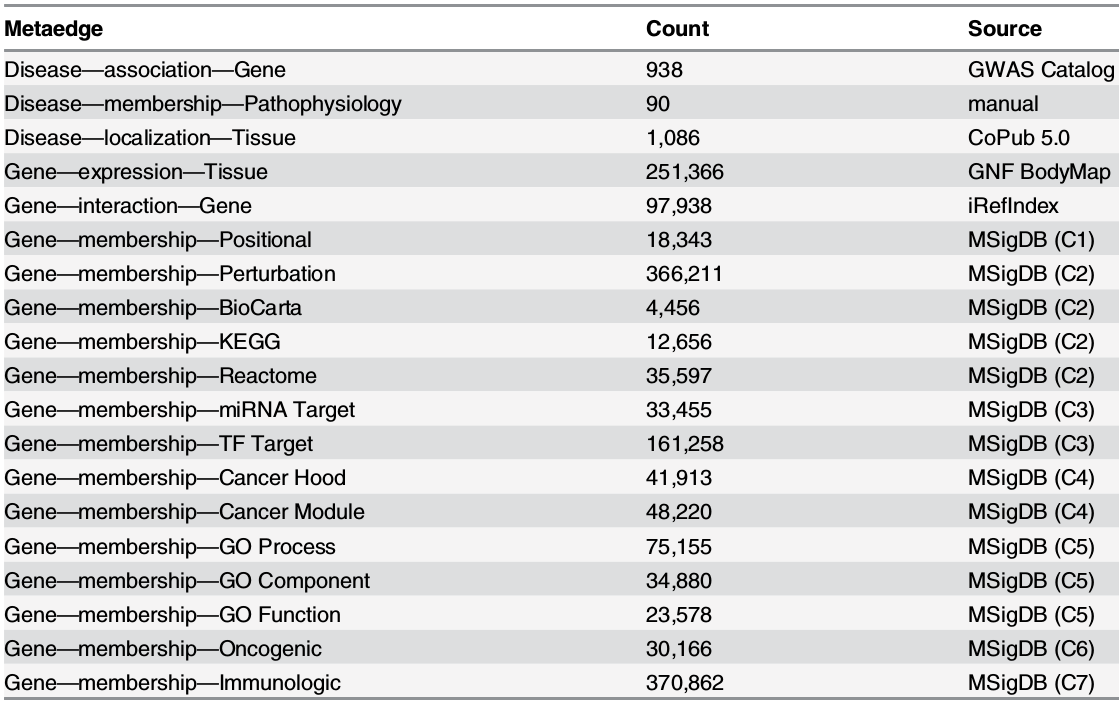
aggregated 4 resources:
MEDI-HPS – combines RxNorm, MedlinePlus, SIDER 2, and Wikipedia
ehrlink – linked data from health records
LabeledIn – expert and MTurk curated drug labels
PREDICT – UMLS links, drugs.com, drug labels
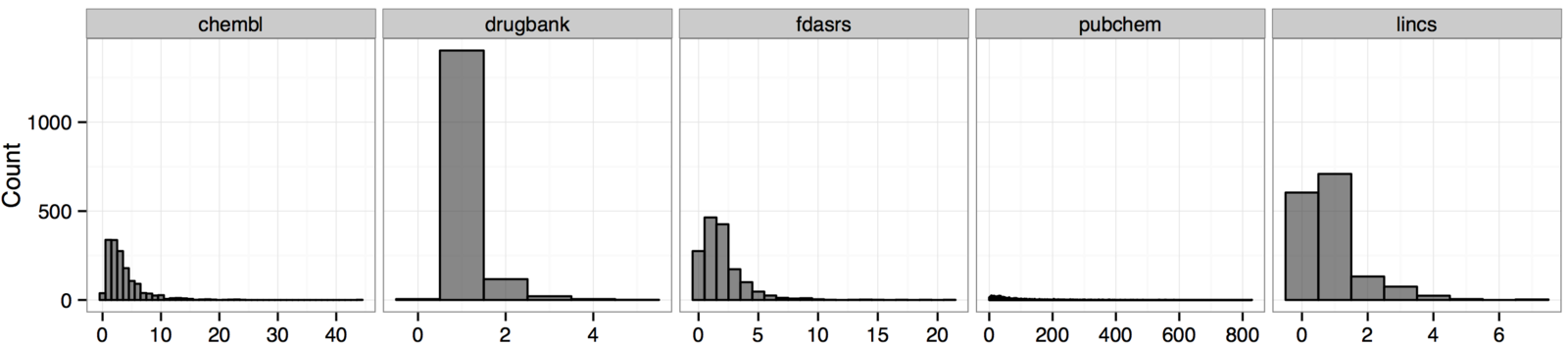
1,388 high and 1,114 low-confidence indications
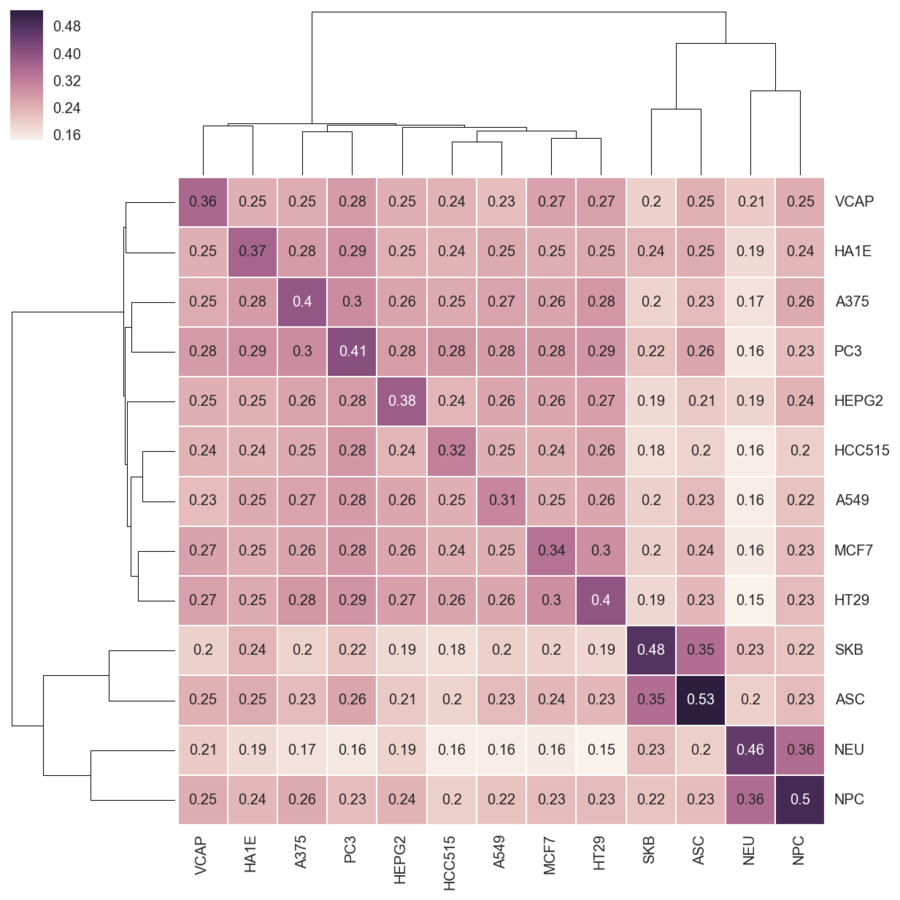
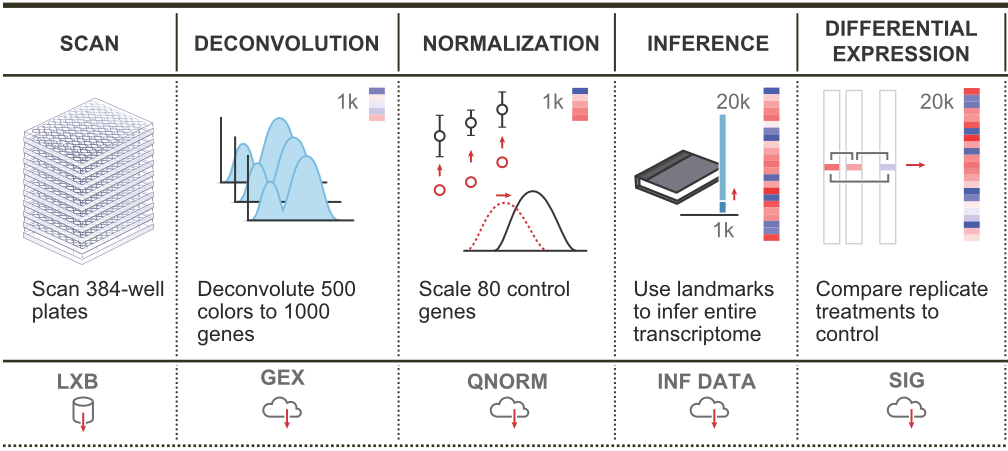
We combine all signatures for each DrugBank compound to get a consensus signature
http://thinklab.com/d/67
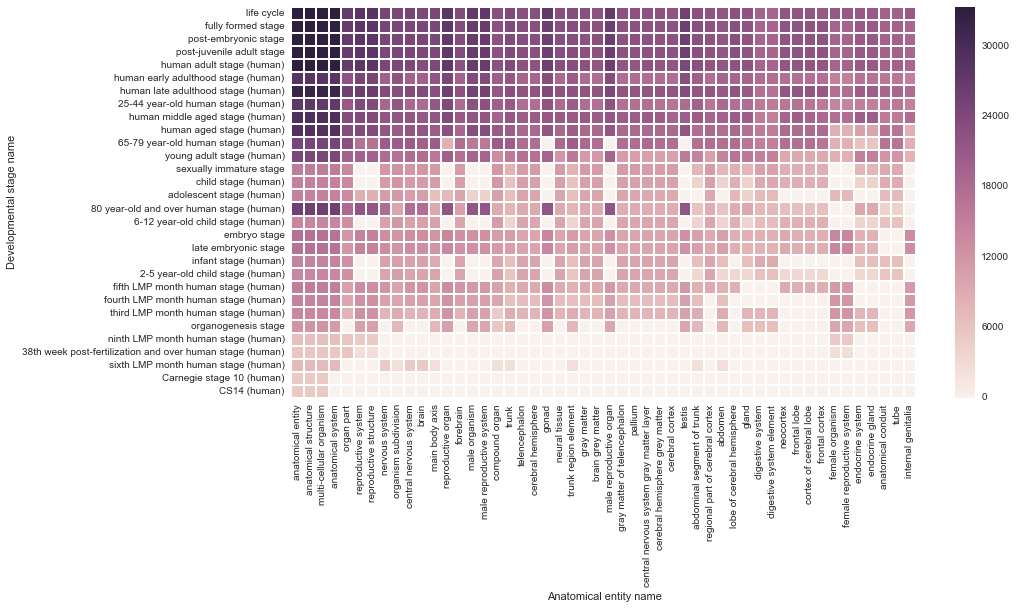
Bgee
curates microarray and RNA-Seq experiments
http://bgee.unil.ch/
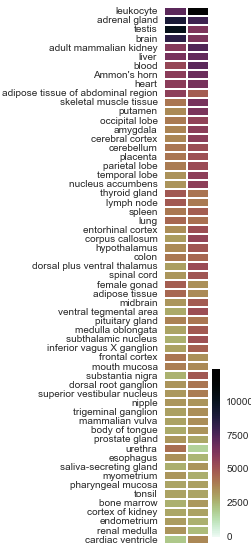
TISSUES
transcriptomics, proteomics, text mining, UniProtKB
http://tissues.jensenlab.org/About
http://thinklab.com/d/81
http://thinklab.com/d/81#293
http://thinklab.com/d/81#293
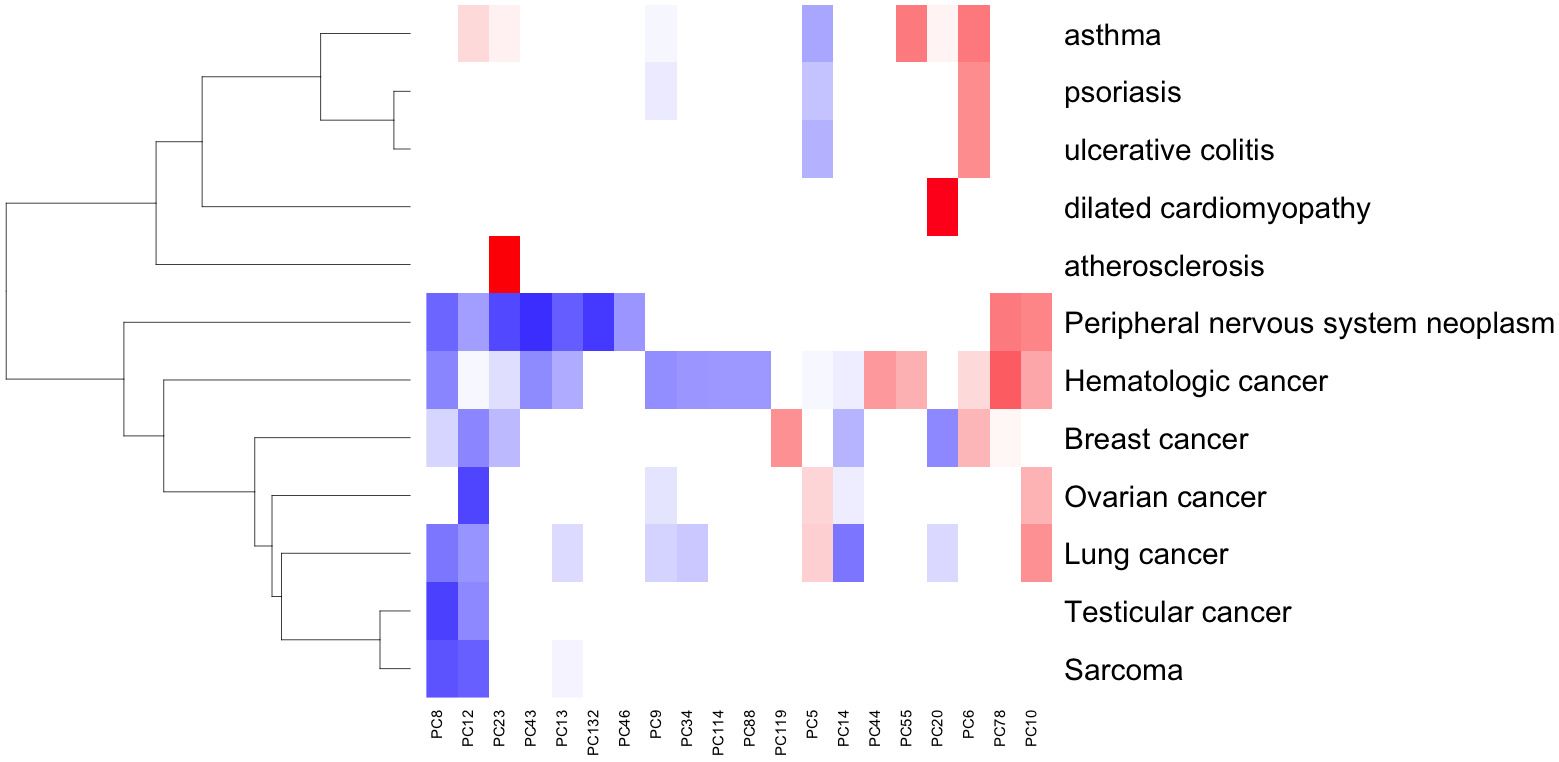
depletion is more common than enrichment
highly-specialized tissues have the greatest differential expression
By Daniel Himmelstein
Presentation to the Atul Butte group at UCSF on July 8, 2015



