Data mining
of studydrive


"nobody wants to fill out my survey"
Situation:
{
"id": 8,
"name": "Johann Schreiner",
"slug": "johann-schreiner",
"karma": 25,
"gender": null,
"karma_ranking": "Mouse",
"credits": "47872",
"image": {
"id": null,
"url_big": null,
"url_original": null,
"url_thumbnail": null,
"avatar": {
"url_thumb": "https://www.studydrive.net/images/avatars/karma/thumb/mouse.png",
"url_big": "https://www.studydrive.net/images/avatars/karma/big/mouse.png",
"url_original": "https://www.studydrive.net/images/avatars/karma/original/mouse.png"
}
},
"studies": []
}{
"is_owner": false,
"downloads_generated": "15675",
"flashcards_created": null,
"documents_created": null,
"posts_created": null
}{
"current_page": 1,
"from": 1,
"path": "https://www.studydrive.net/profile/8/documents",
"per_page": 20,
"to": 20,
"total": 181
}id: the userid
name: the users first and last name
slug: a computer-friendly version of the name
karma: the users karma points
karma_ranking: the users karma rank
credits: the users carma points
documents: the number of documents uploaded
downloads: the number of downloads these documents generated
const got = require('got');
const cheerio = require('cheerio');
const moment = require('moment');
const Queue = require('bull');
var queue = new Queue('crawl', 'redis://127.0.0.1:6379', { limiter: { max: 5, duration: 10 } });
let flag = false;
async function fetch(id) {
let profile_url = `https://www.studydrive.net/en/profile/xx/${id}`;
let stats_url = `https://www.studydrive.net/profile/${id}/stats`;
let documents_url = `https://www.studydrive.net/profile/${id}/documents?page=1`;
let html = await got(profile_url).then(res => res.body).catch((e) => {
return null;
});
if (html == null) {
return null;
}
let $ = cheerio.load(html, { normalizeWhitespace: true, decodeEntities: false });
let now = new Date().toISOString();
let obj = {
created_at: now,
id: id,
}
try {
let userdata = JSON.parse($('profile-show').attr(':profile'));
if (userdata.studies.length > 0) {
userdata.study = userdata.studies[0];
userdata.major = study.major;
}
obj = { ...obj, ...userdata }
} catch(e) {
}
delete obj['image'];
//obj['credits'] = Number(obj['credits']);
let options = {
headers: {
'x-requested-with': 'XMLHttpRequest'
}
}
let html2 = await got(documents_url, options).then((res) => {
return res.body;
}).catch((e) => {
if (e.statusCode == '404') {
return null;
}
});
if (html2 == null) {
return null;
}
let documents = JSON.parse(html2);
obj.documents = Number(documents.meta.total) || 0;
let html3 = await got(stats_url, options).then(res => res.body).catch((e) => {
console.log(e);
});
let stats = JSON.parse(html3);
obj.downloads = Number(stats.data.downloads_generated) || 0;
return obj;
}
function json2csv(obj) {
let keys = ['id', 'name', 'slug', 'karma', 'karma_ranking', 'credits', 'documents', 'downloads'];
let tmp = [];
if (obj) {
for (let k of keys) {
tmp.push(obj[k]);
}
return tmp.join(',');
} else {
return keys.join(',');
}
}
queue.process(async function(job, done){
let result = await fetch(job.data.id);
if (result) {
console.log(json2csv(result));
}
done();
});
async function seed() {
console.log(json2csv());
let start = 1134903;
let count = 100000;
for (let i = start, end = start + count; i < end; i++) {
queue.add({id: i});
}
}
seed();- 27 MB csv
- crawled: 1.6M
What can we say about this data?
deleted accounts
284,989 (17.81%)
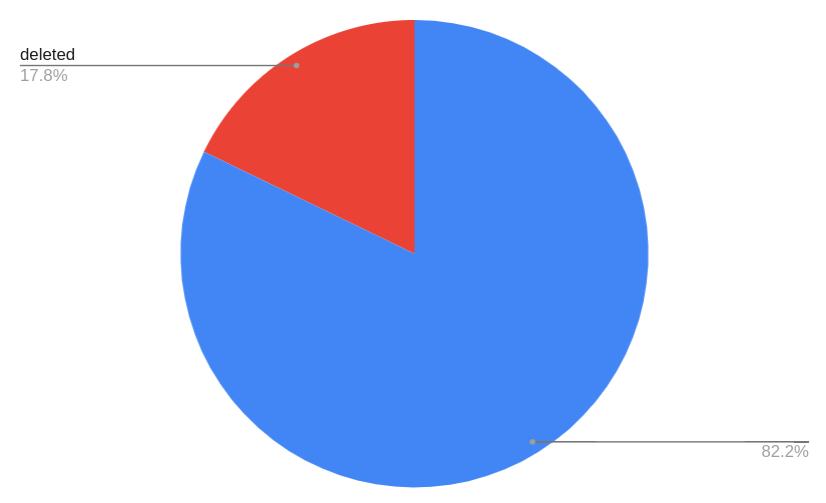
final dataset: 1,315,011
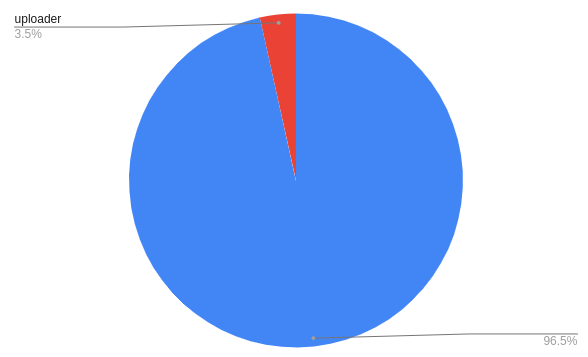
anonymous
1,137,043 (86.5%)
uploader*
45,823 (3.5%)
*number of documents > 0

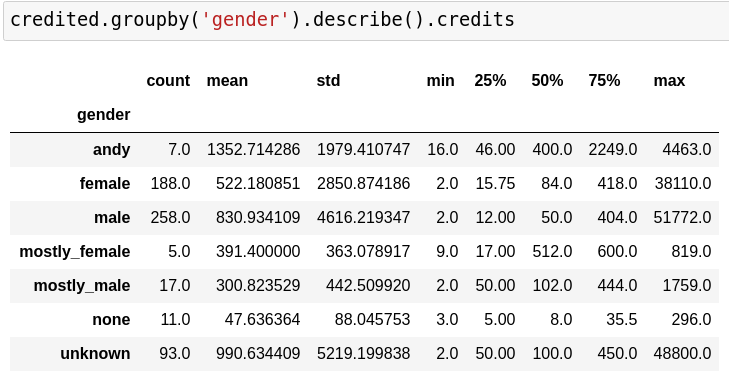
strong correlation: credits - downloads, documents
some correlation: downloads - documents
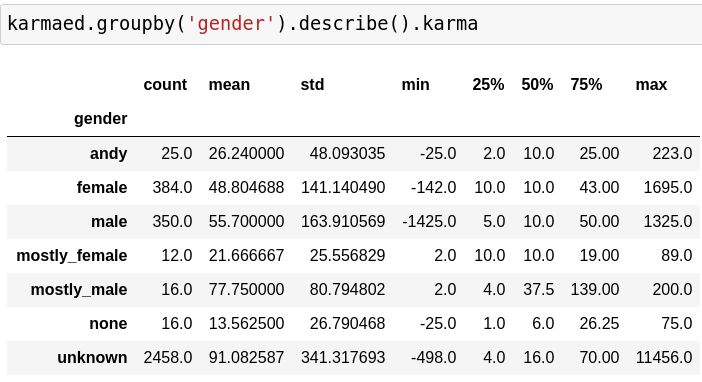
no correlation: karma
karma
credits
documents
downloads
- user-awarded points
- subjective
- non-monetary
- no limits (also negative)
- points given by the system
- objective
- monetary
- can be exchanged
- the number of documents uploaded by a user
- the number of downloads generated by all the documents of a user
karma
credits
documents
downloads
- status, recognition
- monetary, competition
- quantity of contributions
- quality of contributions
karma
credits
documents
downloads
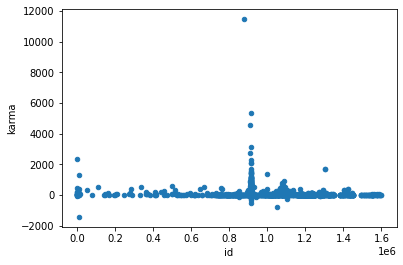
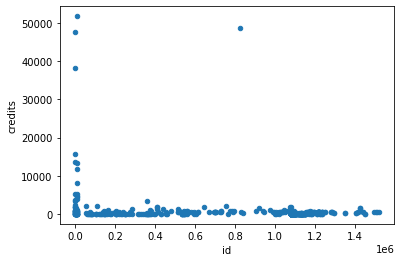
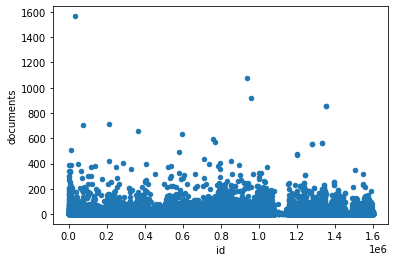
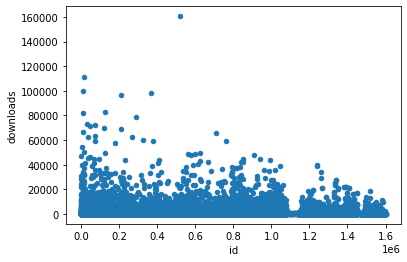
id as a chronic order
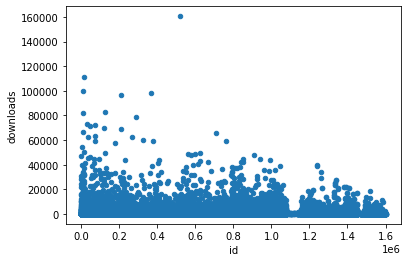
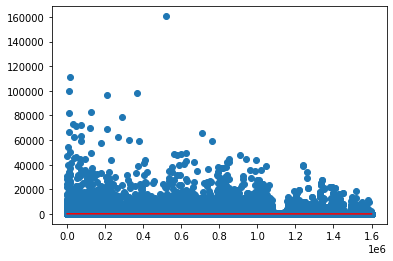

Sub-Grouping
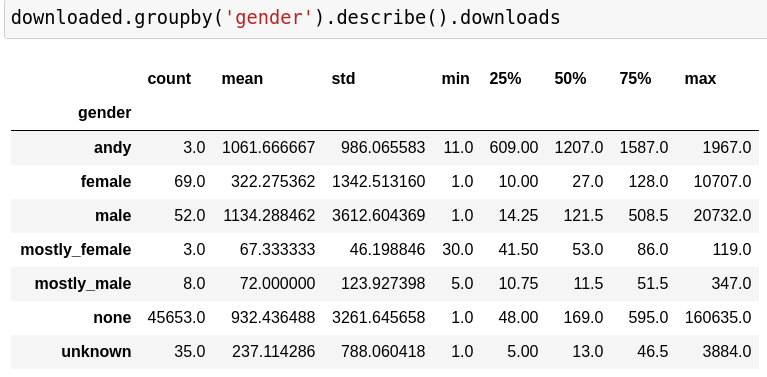
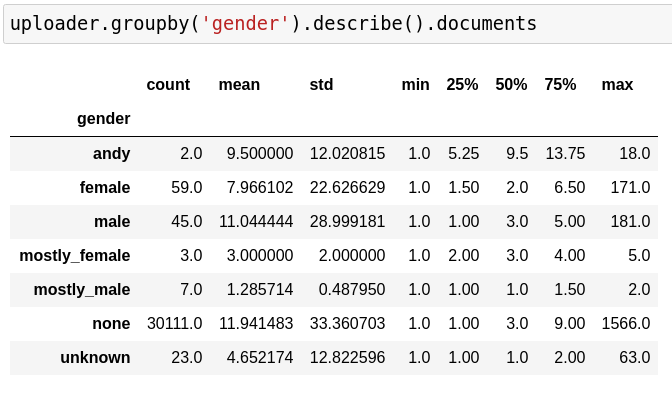
Can you predict the gender from the first name?
predicting gender from first name
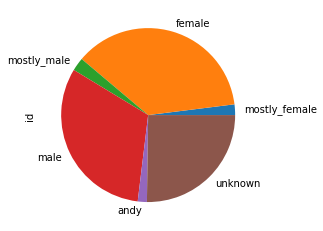
andy: 3016
female: 65627.0
male: 56522.0
mostly_female: 3520.0
mostly_male: 4390.0
none: 1137043.0
unknown: 44893.0
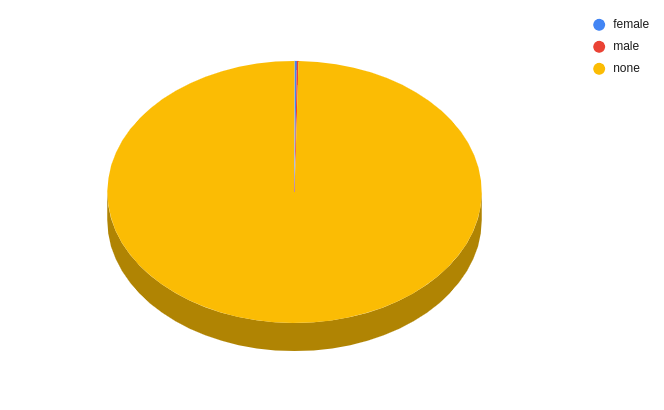
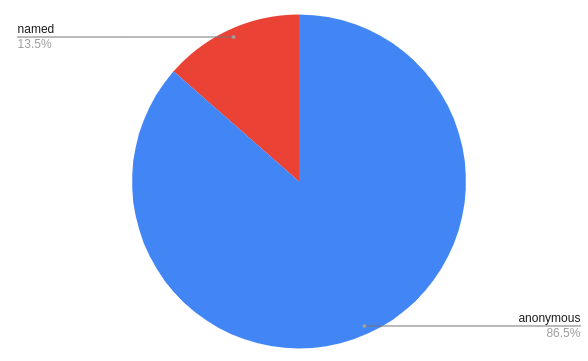
99% of the people who upload documents use it anonymously
uploader (45653)
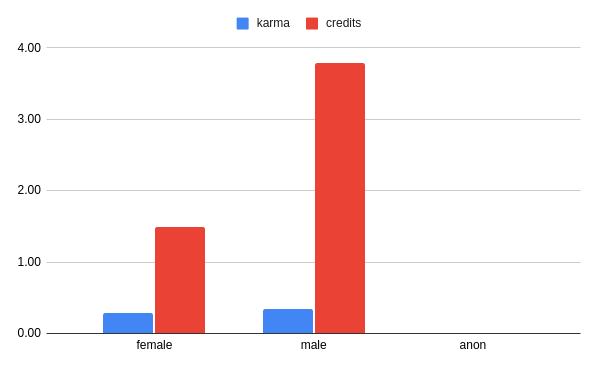
on average, anonymous people have nearly no karma or credit points…
0.29 1.50
0.34 3.79
0.00 0.01
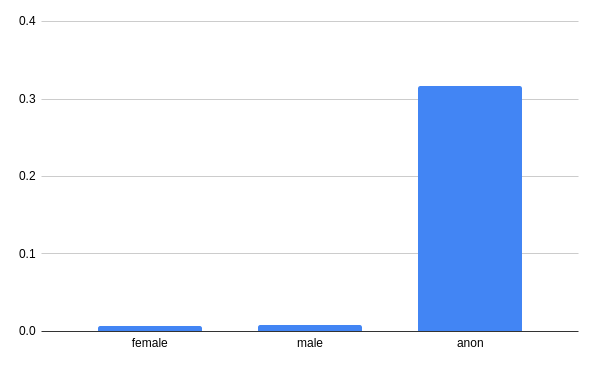
… but when it comes to downloads they clearly lead the board.
0.007162
0.008793
0.316233
status, recognition
monetary, competition
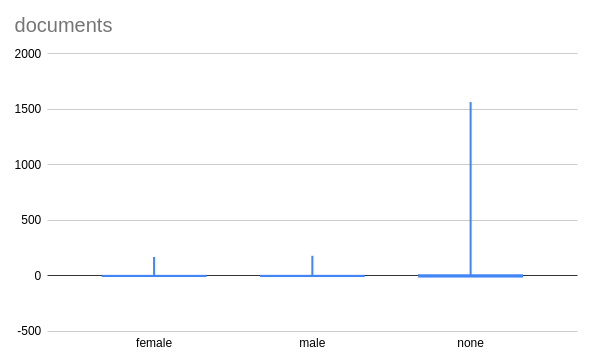
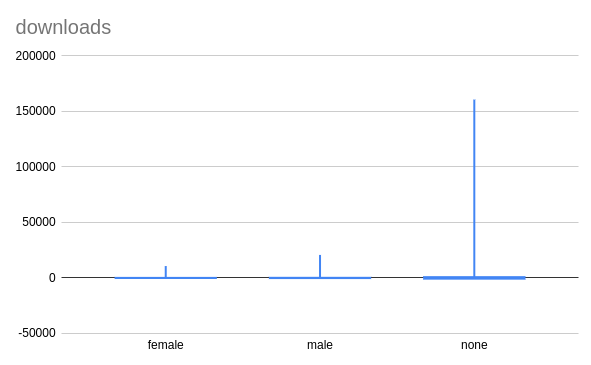
quantity of contributions
quality of contributions
conclusion
- data mining helps to gather larger amounts of data easily
- data mining gives a more 'total' view
- data is limited to the technical possibilities
- data is objective and not subconsciously manipulated
- data can not be linked to other (subjective) questions
Thanks.
open discussion
studydrive.net
By doebi



