Profiling degli utenti Twitter:
sviluppo di un algoritmo che sfrutta le informazioni presenti nel microblogging
UNIVERSITÀ DEGLI STUDI DI CATANIA
DIPARTIMENTO DI INGEGNERIA ELETTRICA, ELETTRONICA E INFORMATICA
CORSO DI LAUREA IN INGEGNERIA INFORMATICA
Laureando:
Castellano Gabriele
Relatore:
Prof. Mangioni Giuseppe
Anno accademico 2013/2014
Obiettivo
Ideare ed implementare un algoritmo capace di identificare gli interessi e le competenze di un dato utente Twitter, analizzando i messaggi tweet da esso pubblicati;
applicare quindi tale procedura ad una lista di utenti contenuta in un database, ed archiviare i risultati ottenuti in modo da renderli accessibili successivamente.
Scenario applicativo
PanPan - Ask Everywhere è un'applicazione disponibile per smartphone Android e iOS che permette agli utenti di ottenere velocemente informazioni geolocalizzate su un argomento ben preciso.
L'algoritmo è stato realizzato appositamente per migliorare la suddetta applicazione, in particolare nella fase di ricerca degli utenti più adatti a rispondere alla domanda formulata.
Strumenti utilizzati
- Il progetto è stato realizzato attraverso il Python, linguaggio di programmazione ad alto livello multipiattaforma la cui chiarezza e semplicità incrementa la produttività;
- Come database è stato utilizzato MongoDB, e l'interfaccia è stata realizzata attraverso l'apposita libreria pymongo;
- DBpedia e la stessa Wikipedia vengono più volte interrogate nel corso dell'esecuzione dell'algoritmo;


Strumenti utilizzati
- Per poter usufruire delle informazioni prelevate dal web in formato XML l'algoritmo utilizza la libreria python ElementTree;
- Tagme, tool online progettato dall'Università di Pisa, si è rivelato molto utile per la ricerca delle parole-chiave contenute nei tweet degli utenti.
Funzionamento dell'algoritmo
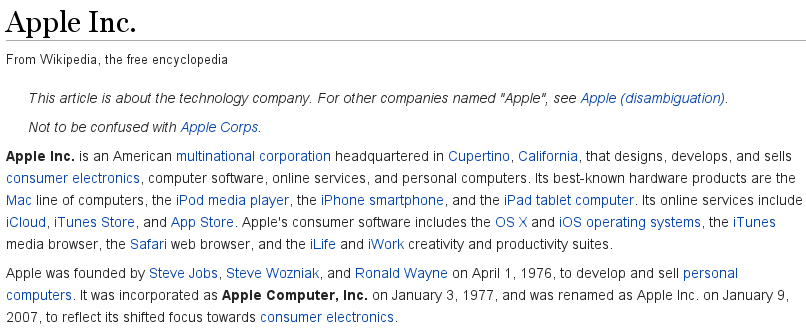
Il "profilo" dell'utente che l'algoritmo si propone di creare viene identificato da un'insieme di 10 Categorie, rappresentanti i principali Topic di interesse; esse sono un particolare tipo di pagine Wikipedia.
La ricerca di queste avviene a partire dalle parole-chiave prelevate dai tweet, a ciascuna delle quali viene associata una Entity attraverso Tagme; le Entità non sono altro che normali articoli Wikipedia.
Funzionamento dell'algoritmo
Tweet: "I don't want an Apple computer."
Funzionamento dell'algoritmo
L'algoritmo si divide essenzialmente in due fasi:
- inizialmente viene estratto un insieme di Categorie dalla totalità dei tweet del profilo;
- infine vengono scelte le Categorie corrette tra tutte quelle disponibili, valutandole in base ad un punteggio assegnato a ciascuna di esse.
Funzionamento dell'algoritmo
Analizzando ciascun tweet pubblicato dall'utente, le Entity restituite da Tagme vengono memorizzate all'interno di un bag-of-world in cui viene tenuta traccia solo della frequenza con cui ogni parola-chiave è stata richiamata.
Servendosi del grafo presente in Wikipedia, per ogni Entità viene costruito il relativo albero di Categorie; i livelli più bassi conterranno Topic più generici.
Ricavare un insieme di Categorie dai tweet
Funzionamento dell'algoritmo
Ricavare un insieme di Categorie dai tweet
Tweet: "Arsenal winger Walcott: Becks is my England inspiration"
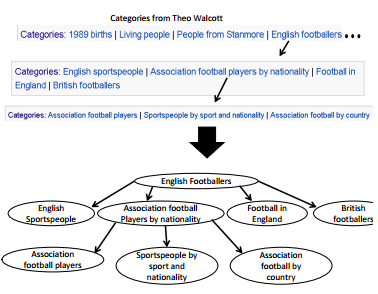
Livello 1
Livello 2
Livello 3
Funzionamento dell'algoritmo
Una volta ottenuta la struttura completa con i vari livelli di Categorie, viene assegnato un rank a ciascuna di esse:
Individuare le Categorie più importanti
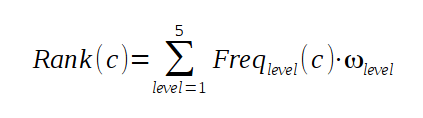
Le 10 con rank più alto vengono identificate come "Profilo" dell'utente in esame.
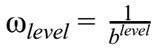
| Size of K | | Avg. Precision (± Std-Dev) |
| 5 | | 0.95 ± 0.10 |
| 10 | | 0.90 ± 0.08 |
| 25 | | 0.85 ± 0.08 |
Risultati Sperimentali
Al fine di verificare l'efficacia dell'algoritmo implementato, sono state effettuate prove sperimentali su alcuni account Twitter;
di seguito viene riportata passo per passo l'analisi del profilo IngInform_CT, adibito a fornire agli studenti informazioni e aggiornamenti sul corso di studi.

Risultati sperimentali
Sessione di laurea in ingegneria informatica (#inginfct) giorno 22/07/2014 alle ore 9.00 in aula Oliveri
Alcuni tweet di esempio prelevati dall'account
Publicato l'elenco degli studenti (CDS Ing. Informatica) #inginfct relativo ai 3 cfu del corso "Linguaggio Python"
Il bando per l'iscrizione ai corsi di laure dell'Ateneo di Catania (#unict, #inginfct) è stato pubblicato oggi.
#unict, #inginfct Gli studenti del 1 anno sono invitati giovedì 23/01, ore 14 in aula magna per discutere delle azioni di tutoraggio.
Risultati sperimentali
L'algoritmo ha analizzato la totalità di 92 tweet, e da essi ha ricavato se seguenti Entità:
Entità ricavate dalla totalità dei tweet
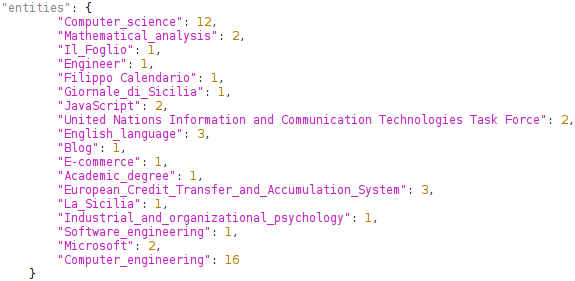
Risultati sperimentali
Le 10 Categorie ricavate a partire dalle Entità

Le 10 categorie ricavate costituiscono il "Profilo" di IngInform_CT. Notiamo che la maggior parte di esse sono relative all'Ingegneria Informatica; in più il programma è riuscito anche a comprendere il fatto che l'utente avesse qualcosa a che fare con l'istruzione (Categorie Engineering_disciplines e Education_by_subject)
Conclusioni e sviluppi futuri
Dagli esempi analizzati si evince che i risultati ottenuti dall’algoritmo sono conformi con gli obbiettivi prefissati in partenza; i tempi di esecuzione però sono vari e possono andare dai 10 minuti alle 2/3 ore per utente analizzato. Questo dipende principalmente dal numero di richieste che l’applicativo effettua per interfacciarsi con tutti i servizi online ai quali si appoggia.
Conclusioni e sviluppi futuri
Per aumentare le prestazioni è assolutamente necessario azzerare i tempi di attesa dovuti alle numerose connessioni coi server. ll servizio on line al quale vengono fatte più richieste è Wikipedia, per questo è già stato avviato dal team di sviluppo di PanPan un progetto che consiste nel download dell'intera enciclopedia e nella sua memorizzazione in un archivio locale.
Archiviazione di Wikipedia in un server locale

Conclusioni e sviluppi futuri
Questo servizio online viene richiamato per ogni tweet dell’utente, e comporta grossi rallentamenti abbastanza evidenti anche dall’output che il programma fornisce durante la sua esecuzione; per eliminare questi tempi di attesa è già stato avviato lo sviluppo di un progetto interno alternativo a Tagme: verrà dunque a breve ultimato un algoritmo capace di ricavare le parole-chiave dai tweet che sarà in esecuzione sui server di PanPan.
Implementare un algoritmo alternativo a Tagme
Conclusioni e sviluppi futuri
Inoltre per poter utilizzare il database generato da questo progetto sarà necessario sviluppare un algoritmo da inserire all'interno dell'applicazione PanPan vera e propria, che riesca ad inquadrare il Topic di ogni domanda ed individuare all'interno del database gli utenti che hanno tra le loro 10 almeno una Categoria simile al Topic stesso.
Sviluppare l'algoritmo complementare in PanPan
Fine
Grazie a tutti per l'attenzione!
Presentazione Tesi
By Gabriele Castellano