Delivering A
'Big Data ReadY'
MVP
Gregory Chomatas
Dublin Google Developers Group - 2013 July 30th
http://linkedin.com/in/gchomatas
CHOMATAS
GregorY
t: @gchomatas
http://www.astroboa.org
Entrepreneur
SW Engineer
Betaconcept / Astroboa: Founder
Aquinetix: Co-founder / CTO




7 yearS ago I realized...
Too Much RDBMS SODA
LOTS of Object-relational Mismatch
DB is not the center of MY application
Domain Driven Design / Behaviour Driven Design
vs
Database Driven Design
At That time not Many alternatives existed
so we decided to roll our own data store solution...
Astroboa to the rescue
Hybrid Document-Graph Store focused on data semantics
Similar to Google Datastore & OrientDB
- External 'app independent' Semantic Data Model
- Model as you go
- Security per Entity instance / property
- Versioned Entities
- Automated REST APIs encapsulating the data layer
- Hyperlinked Resources
- Polyglot Persistence (Experimental) *
The "Bigness' in big data
Two main paths to the realization of 'BIGNESS'
Luckily both paths converge to common principles & tools that can manage BIG Complexity & BIG Volume
Big Data EnlighteNment
Big 'Data Problems' (complexity)
-
single point of failure / resilience
- cross data center
-
human fault tolerance
-
store / search unstructured or semi-structured data
-
flexible data modeling (e.g. traverse relationships)
- data versioning
- polyglot programming
- multitenancy
- share / data as a service
- semantic web / multiple formats - endpoints
'BIG DATA' Problems (VOLUME)
- high volume
- high velocity
- real-time APIs / act in real time
- data as others service / dirty data from open sources
- log collection / aggregation
linear / Horizontal scaling
I am not a Big data Start-up!
- Start-up = Growth (5% - 10%) / week
- 1000 writes per aquaculture farm per day
- 120 farms on public beta = 120000 writes / day
- 1st month: 176 farms = 176000 writes / day
- 6th month: 1181 farms = 1.2M writes / day
- 1st year: 17045 farms = 17M writes / day (200/sec)
- 2nd year: 2421143 = 2.4B writes / day (27777 / sec)
ARE YOU SURE ?
a sucessful SaaS is a big data service
it's JUST an MVP - we will ADD all these big data stuff later
- A Big Data architecture can be simpler than a traditional one
- The right data store can increase productivity
- Keep it simple but not compromise the architectural concepts
- Balance between technical debt & technical equity
- An enterprise business system will usually win on underlying technological innovation, robustness and enterprise readiness
- "In business there is nothing more valuable than a technical advantage your competitors don't understand" - Paul Graham
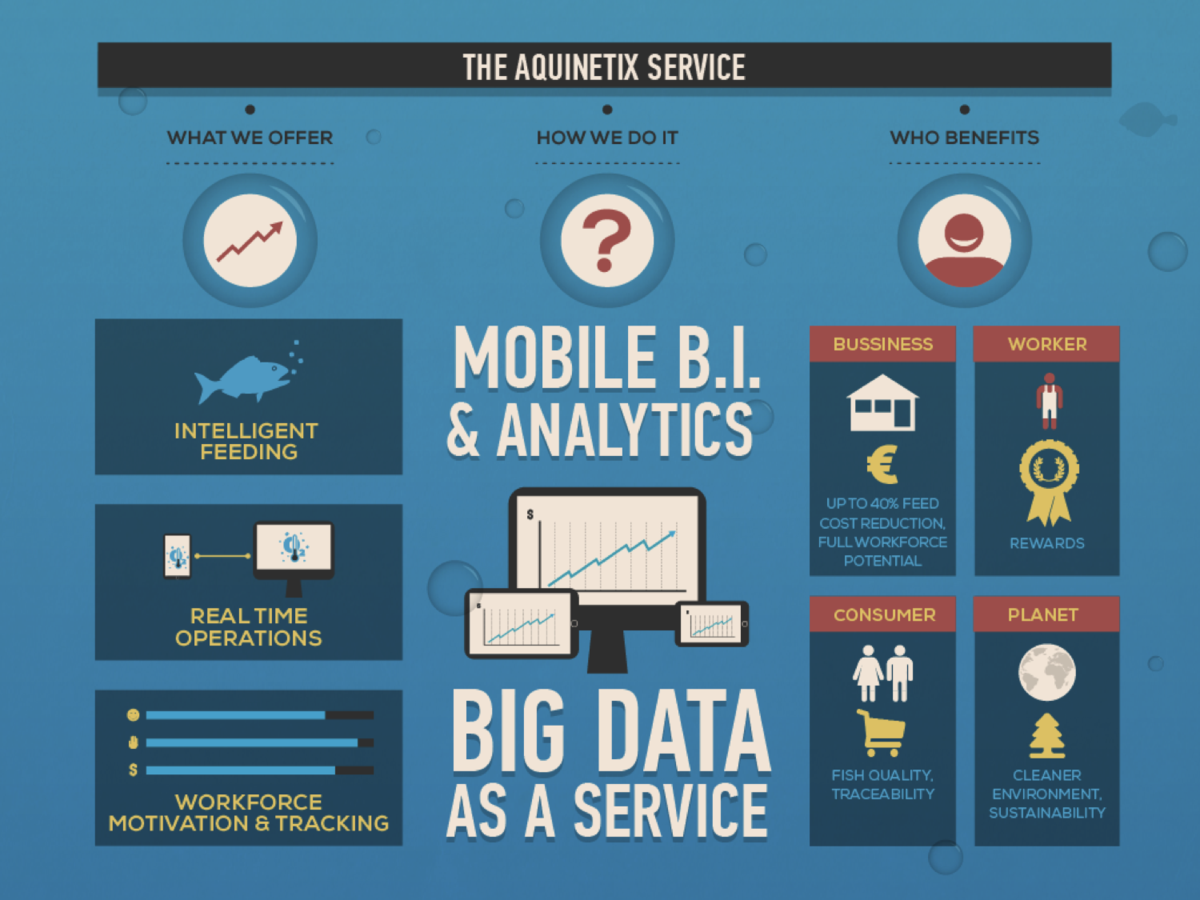
Key BIG DATA Architecture features
Distributed Storage
- APPLICATION database vs INTEGRATION database
- Mix several data models / polyglot persistence
- External Data Schema / Common Data Structures
- Data Store encapsulated by an API (Data Services)
- Append only / save changes vs state (event sourcing)
KEY BIG DATA ARCHITECTURE FEATURES
Distributed Computing
- Asynchronous processing
- Real Time Event Processing / Streaming
- Simple decoupled services exposed through REST or RPC APIs (business services)
- Thick web clients / mob. apps using the REST or Streaming APIs
- Client-level multivariate data analysis & complex visualization
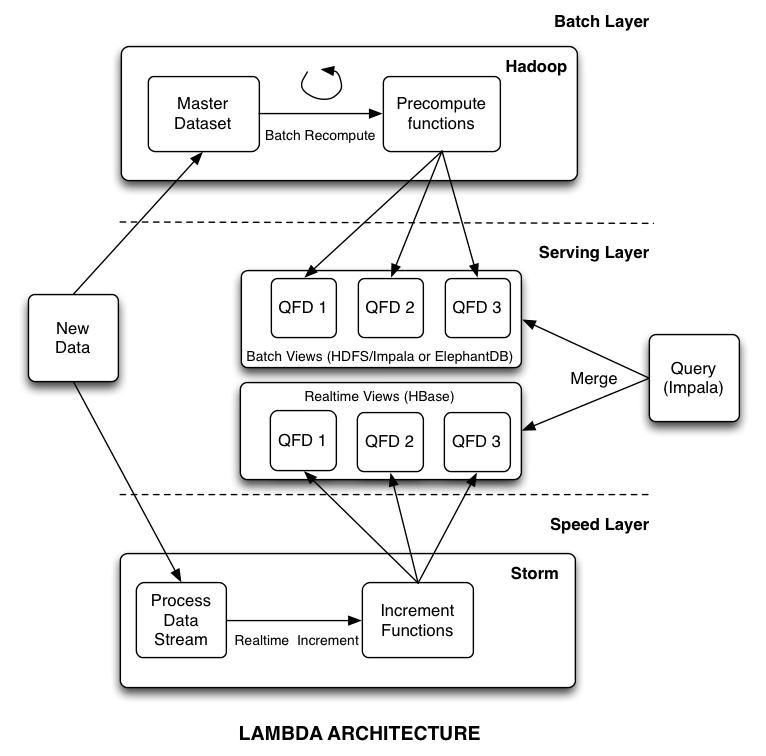
The Lambda architecture
by Nathan Marz and James Warren
store raw, immutable, perpetual data
query = function(all data)
combine batch & real time stream processing to compute arbitrary functions on arbitrary data
THE LAMBDA ARCHITECTURE
Ultimate Design Rule
KEEP it SIMPLE
The conventional ARCHITECTURE
new data store criteria
Distributed
Easy to change schema & queries
Simple to install, configure, operate
one component
auto-shard
peer-to-peer
Minimize impedance mismatch
Boost productivity

Directly store my aggregates
{
"date": "2013-02-28",
"allocated_worker": "swp4jhi4Tm6VxY1nueX2yw",
"cage": "1GuuHWTaQc-kpPcRV5uBGA",
"feed": "7IWmy2FATcS9Vh0RB1onXQ",
"quantity_approved": 12.5,
"farm": "__uBZUr3RWOqOSkszfbRLw",
"species": "KDU-2LCjRRynby9HLifc3g",
"batch": "i6MgxixnSCGwGWb0037wlQ",
"execution": {
"feeder": "swp4jhi4Tm6VxY1nueX2yw",
"quantity_fed": 12.5,
"species_position_start": "top",
"species_position_end": "middle",
"start": "2013-02-28T07:59:57.668Z",
"end": "2013-02-28T08:00:03.216Z",
"feeder_position_end": {
"lat_lon": {"lat": 37.7066959, "lon": 23.16831896},
"altitude": 40,
"accuracy": 12
}
}
}
The candidates
| Key-Value | Document | Column | Graph |
|---|---|---|---|
| Riak | MongoDB | Cassandra | Neo4J |
| Redis | CouchBase | HBase | Infinite Graph |
|
Pr. Voldemort
|
OrientDB
|
Hypertable | OrientDB |
| MemcacheDB | ElasticSearch | Accumulo |
Titan |
|
DynamoDB |
Google Datastore |
SimpleDB |
Virtuoso |
My COOL data store tip
elasticsearch document store
No other NoSQL store comes close to the out of the box utility and usability of Elastic Search
schema less, multi tenant, replicating & sharding document store that implements extensible & advanced search features (geo spatial, faceting, filtering, etc.)
REST API to CREATE / UPDATE (partially) / DELETE / READ aggregates / entities
REST Search API with full text search out of the box
MULTI-TENANT friendly with REST API for creating / updating DBs & entity types
Dynamic / Semi-Dynamic / Fixed schema
Elastic search power
index over 95GB/h/node
8-node cluster: sub-200ms response for complex searches on 10B+ records
(oracle OR mysql) AND replication
apple AND ip*d
john AND city:Dublin
species:"Sea Bream" AND execution.date:[20130701 TO 20130730]
taxicub AND ("Dublin"^2 OR "Cork")
"facets" : {
"locations" : { "terms" : {"field" : "city"} }
}
"terms" : [ {
"term" : "Dublin",
"count" : 130
}, {
"term" : "Cork",
"count" : 20
}, {
"term" : "Galway",
"count" : 1
} ]
Faceted Browsing
Histograms / GEO Distance

"facets" : {
"Feed_Histogram" : {
"date_histogram" : {
"key_field" : "date",
"value_field" : "execution.quantity_fed",
"interval" : "month"
}
}
}
"filter" : {
"geo_distance_range" : {
"from" : "200km",
"to" : "400km"
"pin.location" : {
"lat" : 40,
"lon" : -70
}
}
}
"filter" : {
"geo_polygon" : {
"person.location" : {
"points" : [
{"lat" : 40, "lon" : -70},
{"lat" : 30, "lon" : -80},
{"lat" : 20, "lon" : -90}
]
}
}
}
"filter" : {
"geo_distance" : {
"distance" : "200km",
"pin.location" : {
"lat" : 40,
"lon" : -70
}
}
}
RDBMS out - Document store in
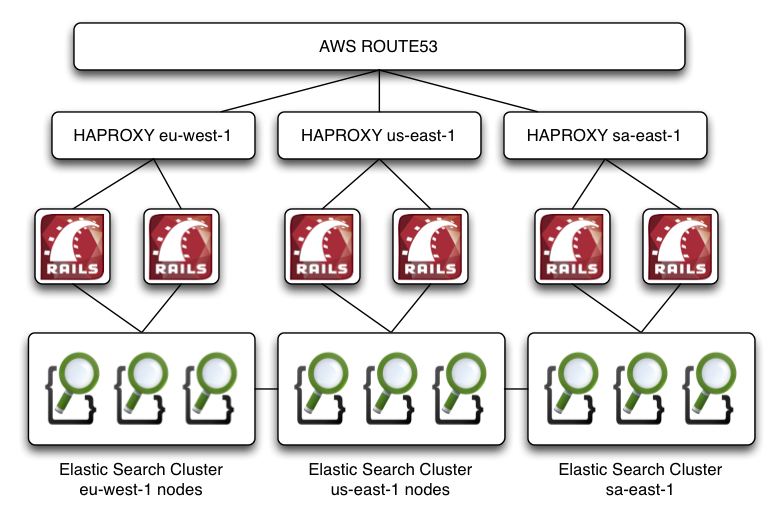
what about my relations
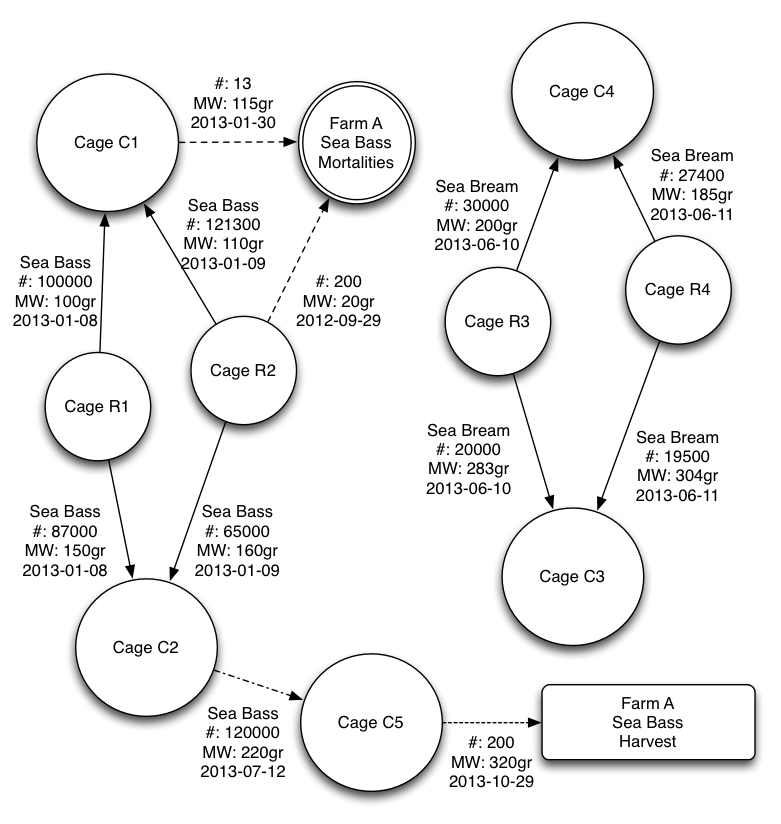
Lets Go Polyglot
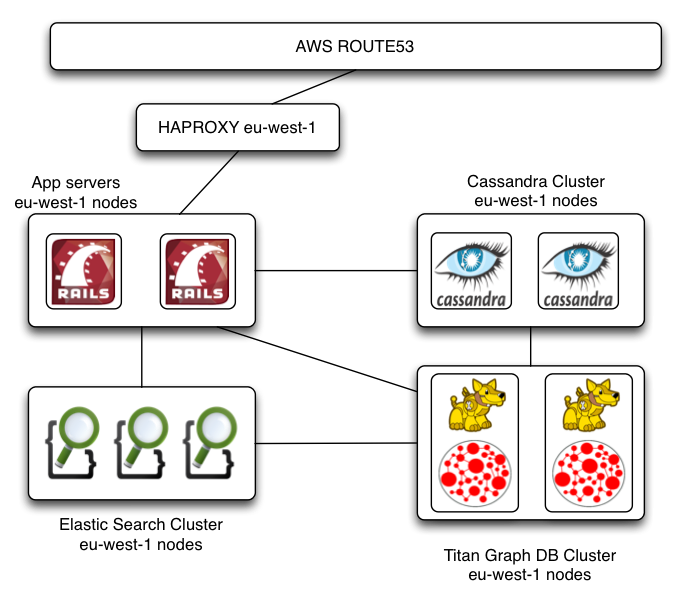
The TITAN GRAPH DB
- Distributed
- Pluggable storage (Cassandra, HBase, Berkeley DB)
- Indexing with Elastic Search & Lucene
- Blueprints Interface
- Gremlin Query Language
- Rexter Server adds JSON-based REST interface
Easy Graph Traversal with gremlin
// calculate basic collaborative filtering for user 'Gregory'm = [:]g.v('name','Gregory').out('likes').in('likes').out('likes').groupCount(m)m.sort{-it.value}
Start on a single machine
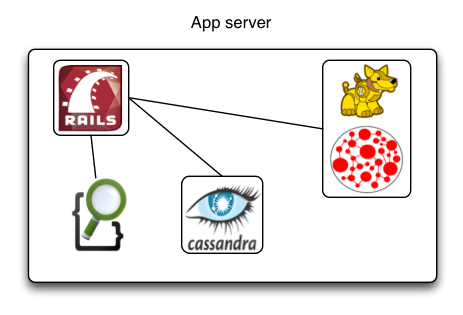
Data store selection tips (1)
-
Use polyglot persistence with multiple data models
-
Start with a Document Store as your system of record
-
Mix it with a key-value Store for keeping sessions, shopping cart, user prefs, counters, caching
- Mix it with a Graph store to keep and traverse entity relationships
- Use a Column Store as your system of record if you need performance rather than flexibility and you know well your data model & queries
- Keep a relational db for queries on transient data (reporting on inter-aggregate relationships)
DATA STORE SELECTION TIPS (2)
- Prefer one-component stores rather than many moving parts
-
Choose a store that makes it easy to experiment with schema and query changes & supports easy data migrations
- Prefer stores that can work with both dynamic & fixed schemas (there is always an implicit schema)
-
In early prototypes avoid Column stores as they have a high cost on schema and query changes
Data Store Selection Tips (3)
- Choose stores that support auto-sharding
- Prefer peer-to-peer replication rather than master-slave
-
Replication factor N = 3 is a good standard choice
- Consistency Adjustment Quorum: W > N/2 , W+R > N
All that Said...
APP CONTEXT is always the determining factor for selecting your store
as well as...
Safety / Stability
Productivity
Community
Performance
Tooling / Operation easeness
Data Modeling tips
- Remember that you fit your model to the data store and not Vice Versa (APPLICATION vs INTEGRATION DB)
- Use a Schema
- Build your aggregates or column families according to your use cases, i.e. DENORMALIZE per your query requirements
- Aggregates form the boundaries for ACID operations (transactions)
-
Pre-compute Question Focused Datasets (materialized views) to provide data organized differently from their primary aggregates
Are We finished YET?
NOT QUITE!
Do something with our monolithic app
Split THE Monolithic Application
-
Wrap data stores into DATA SERVICES
-
Create BUSINESS SERVICES on top of Data Services
-
Prefer RESTful APIs for services (ROA)
- Use a Binary Serialization Framework to create RPC APIs if performance is a concern (ROA / SOA)
- Move MVC* to fat mobile / web client apps that consume the APIs
JavaScript in the browser is one of the world's most widely distributed execution environments & Deployment is trivial !
decoupled serviceS
Fat Client
Single Page App
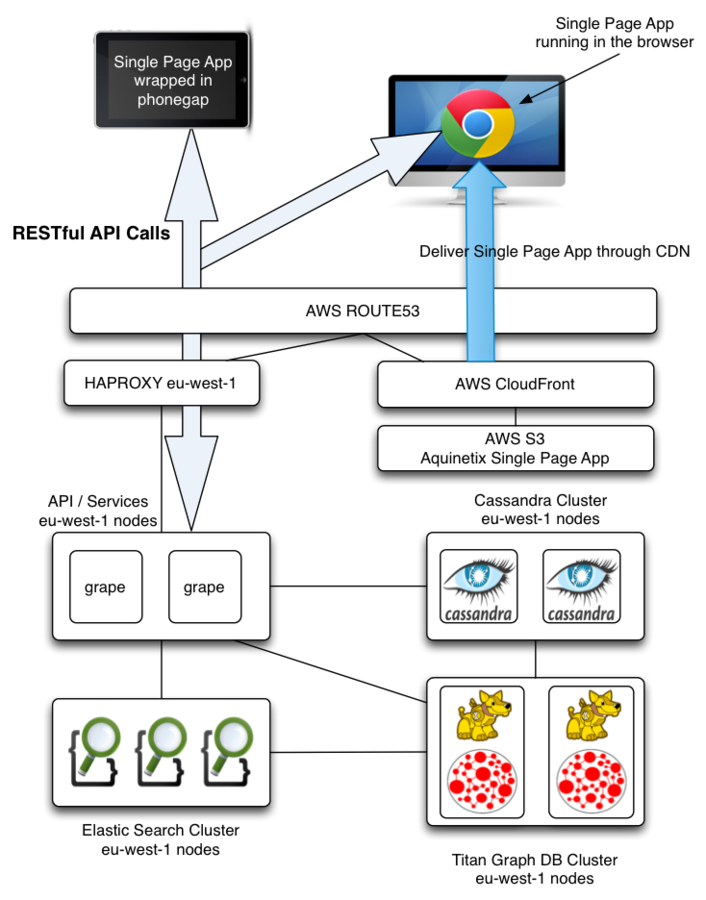
Api framework / DSL
class API < Grape::API
version 'v1', :using => :header, :vendor => 'aquinetix.com'
default_format :json
content_type :json, "application/json"
content_type :tsv, "text/tab-separated-values"
formatter :tsv, Aquinetix::TsvFormatter
content_type :kml, "text/xml"
formatter :kml, Aquinetix::KmlFormatter
mount CageAPI
mount CageEventsAPI
mount DeviceAPI
mount FeedAPI
mount FeedingAPI
mount LossCountEventAPI
mount OxygenSamplingEventAPI
mount SigninAPI
mount TemperatureSamplingEventAPI
mount UserAPI
add_swagger_documentation markdown: true, base_path: "http://..."
end
API FRAMEWORK / DSL
class FeedingAPI < Grape::API
resource :feedings do
desc 'Create a new feeding'
post do
execute_farm_obj_create_request 'Feeding'
end
desc 'Perform a FULL or PARTIAL update of an existing feeding'
params do
requires :id, type: String, desc: "The id (UUID) of ..."
optional :fields, type: String, desc: "Which fields ..."
end
put '/:id' do
execute_farm_obj_update_request 'Feeding'
end
desc 'Get a feeding by its id (UUID)'
params do
requires :id, :type => String, :desc => "Feeding id."
end
get '/:id' do
execute_farm_obj_instance_get_request 'Feeding'
end
end
end
Swagger UI
MVC*at the client
-
Mobile app with backbone.js & phonegap
-
Management / BI Console with AngularJS
-
Visualization with D3.js
-
Multivariate Dataset Analysis at the browser with crossfilter.js
-
App workflow & build with yeoman, grunt, bower
* MVP, MVVM, MVC, MVW
Asynchronous / Real Time processing & Streaming API
RabbitMQ + RabbitMQ Web-Stomp Plugin at the server
SockJS, Stomp js libs at the client
Real-time event stream processing with ESPER
Alternative message brokers:
node.js + zeromq
kestrel
pusher
kafka (> 100k msg/sec)
Alternative Real-time stream processing: Storm
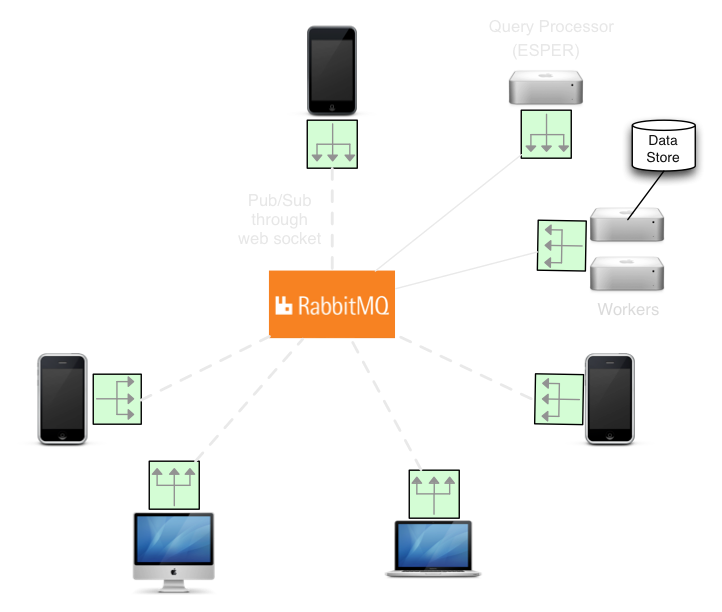
Use cases
count ratings, votes, click-throughs
block abusive crawlers
rate-limit apis
detect spamming attempts
track performance and trigger alerts
batch process logs
subscribe to Stomp topics from js
ws = new SockJS('http://node1.aquinetix.com:15674/stomp')
@client = Stomp.over(ws)
@client.connect('aquinetix', 'password', (x) =>
@on_connect(x)
@on_error, "/")
on_connect: (x) ->
console.log "Connected to message broker"
@feeding_subscr_id = @client.subscribe '/topic/feeding', (message) =>
feeding = JSON.parse(message.body)
Aq_Manager.events.trigger 'feeding_execution:arrived', feeding
@position_subscr_id = @client.subscribe '/topic/position', (message) =>
position = JSON.parse(message.body);
Aq_Manager.events.trigger 'worker_position:arrived', position
@client.send('/topic/feeding', {}, JSON.stringify(feeding_obj))
REAL time event processing with esper
select count(*) as tps, max(retweetCount) as maxRetweets from TwitterEvent.win:time_batch(1 sec)
select fraud.accountNumber as accntNum, fraud.warning as warn, withdraw.amount as amount,
MAX(fraud.timestamp, withdraw.timestamp) as timestamp, 'withdrawlFraud' as desc
from FraudWarningEvent.win:time(30 min) as fraud,
WithdrawalEvent.win:time(30 sec) as withdraw
where fraud.accountNumber = withdraw.accountNumber
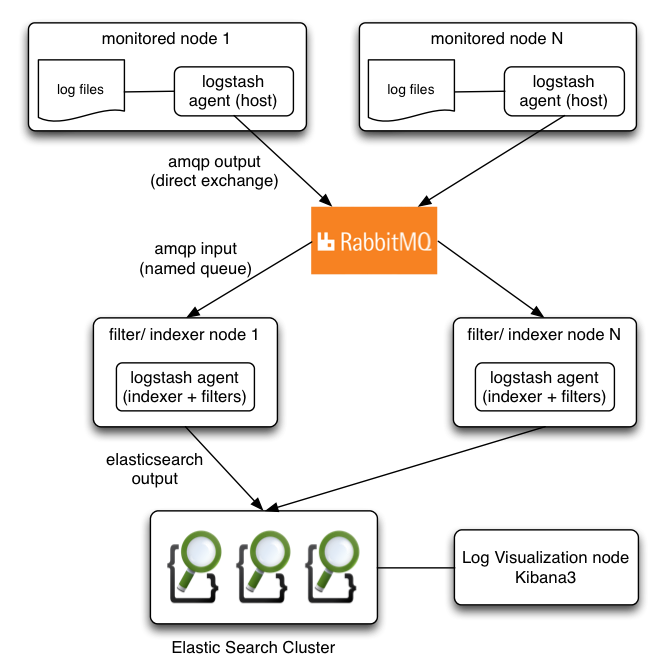
LOG activity and operational data
Today a critical part of the production features of websites
Logstash + ElasticSearch + Kibana 3
WRAPUP
Should availability, robustness & scalability be added to your hypotheses & value proposition ?
if YES then :
Adopt an architecture with decoupled and distributed components at early stages. Build your team around it & balance technical debt / equity to get:
Increased team productivity, Increased readiness and agility, Sustainability
Build your data models around your use cases rather than around your database and experiment with a polyglot persistence strategy
Start with the most easy to install, configure & operate technologies.
Keep it SIMPLE & SUSTAINABLE
Links / references
-
Introduction to NoSQL - Martin Fowler goto; conference
-
Martin Fowler at NoSQL Matters conference
-
Book on the Lambda Architecture
-
Talk on Lambda Architecture
- William Pietri - Going the Distance: Building a Sustainable Startup
-
Don't Let the Minimum Win Over the Viable - Harvard Business Review
-
Elastic Search Document DB & Search Engine
-
Cassandra Column DB
-
Titan Graph DB
- Astroboa Semantic Document Store
-
http://www.rabbitmq.com/web-stomp.html
- https://github.com/jmesnil/stomp-websocket/
LINKS / REFERENCES
- https://github.com/sockjs/sockjs-client
-
https://github.com/robey/kestrel
- https://github.com/JustinTulloss/zeromq.node
- http://kafka.apache.org/index.html
- https://github.com/nathanmarz/storm
- https://developers.helloreverb.com/swagger/
- https://github.com/wordnik/swagger-ui
Delivering a "Big Data Ready" Minimum Viable Product
By Gregory Chomatas
Delivering a "Big Data Ready" Minimum Viable Product
In most cases talking about big data follows an "a posteriori" view where an organization overwhelmed by huge amounts of log files and numerous data sources scattered among its departments decides to put some order to the mess and get some value out of the "big data", usually building a Hadoop cluster. In this presentation I take the opposite direction and try to demonstrate how to proactively design and build product architectures that manage to remain simple and lean while at the same time anticipate the big data complexities and solve them easily and elegantly from day one.



