MySQL @ Synthesio
@gestassy // gestassy@synthesio.com
-
Used to handle PB of web traffic @ eTF1
-
Now cope with billions of Mentions @ Synthesio
- Some music, also
whoami

-
Synthesio is the leading social intelligence tool for social media monitoring & social analytics.
-
Synthesio crawls the Web for relevant data, enriches it with sentiment analysis and demographics to build social analytics dashboards.
Synthesio

- MySQL, SGBD since 1995
-
Your workload is not mine
-
= my solution is certainly not what you need
-
= you can’t rely on generic workload tests
-
-
I won’t go into mysql internals/system/kernel tracing
Disclaimer
our main clusters
-
Historical storage for… everything, until 2015.
-
Percona PXC (Galera) or Master/Slave replication
-
InnoDB
-
a few clients, quite a lot of queries
-
simple structure and transactions
-
avg 30% storage organic growth
-
Stable architecture since 2015
MySQL @Synthesio, Oct 2017
MySQL @Synthesio, Oct 2017

Metadata Cluster

-
Percona PXC 5.6
-
3.5To of deduplicated data
-
650 inserts/s
-
800 updates/s
-
11k questions/s
-
250 sim. connections
-
Percona PXC 5.6
-
8To of deduplicated data
-
1k inserts/s
-
1.5k updates/s
-
8k questions/s
-
1k sim. connections
Frontend storage
- Percona Master-Slave 5.7
- 26To of deduplicated data
- 700 insert/s ~= 60M Mentions/day
- 500 sim. connections
Mentions cold storage

- Galera principles
- Galera not principles
- Cluster - Qorum
- Garbd
- Replication sequence
- Flow control
- Node provisionning
- SST / IST
- Schema upgrade RSU/TOI/pt-online-schema-change
- Load balacing with haproxy
- Performance setup
- Partitionned Tables
- Monitoring
- Backup policy
Agenda
Galera 3

-
InnoDB (or XtraDB) required
-
Multi-Master
-
Synchronous
-
Automatic nodes provisioning
Galera main principles

wsrep_provider=/usr/lib/libgalera_smm.so-
Write scalable : don't add nodes if you need more writes
-
Distributed :
-
Each node contains the full dataset
-
A slow node in write will impact the whole cluster write speed (outside gcs.fc_limit)
-
-
Perfectly synchronous : commit are applied in order but asynchronously (by default wsrep_sync_wait=0)
Galera is not
Based on
- Percona Server
- Percona Xtrabackup
- Codership Galera library
- Performance improvements, bug fixes, security
- pxc_strict_mode
Percona XtraDB Cluster
- Galera is Qorum-based
- Avoid split brain with an odd number of nodes
- The 3rd node can be a Galera Arbitrator : garbd
Cluster - Qorum
- It's only a facade
- A process that is part of the cluster, receives and ack all the traffic of the cluster, but does not process any SQL
- Cannot provoke Flow control
- It can be hosted on a small machine : no CPU or Disk load
- Essential component to replace a classic Master/Master Replication with a 2 nodes Galera cluster
Galera Arbitrator - Garbd
- Galera communication is not mysql replication
- Nodes speak to each other on port 4567 (Group communication)
- ports 4568 and 4444 for IST/SST (initial setup)
- Uses binary log events (but no physical binary log needed)
- Parallel Replication (wsrep_slave_threads) is efficient
- Each Transaction is replicated on commit
Cluster - Multi Master
- Each Transaction is replicated on commit
- On replication : first commit wins
- 2-phase commit : Certification / Apply commit
- Before responding to a commit on a node, the node has a mechanism to accept it = certification
Multi Master Replication

- Node 1 receives commit: Query is in state "wsrep in pre-commit stage"
- Node 1 creates a write-set (bin log event + all references to PK, UK, FK)
- Node 1 Replicates the write-set to the gcomm channel (wsrep_gcomm_uuid)
- Awaits for certification of all nodes
- Sends response : OK or DEADLOCK
Multi Master Replication
- On the Group communication :
- Node 1 receive the write-set, certifies it.
- Node 2 and 3 certify the write-set and put the transaction in queue to be applied asynchronously (wsrep_local_recv_queue)
Multi Master Replication
- Certification process ensure writeset can be applied on a node
- It can fails if another writeset in the queue impacts the same keys.
-
wsrep_local_cert_failures/ wsrep_local_bf_aborts: - When a locally ongoing transaction conflits with the writeset to be applied, it is killed during the certification process
- Long-lasting transactions may be more vulnerables
Certification
- Traditional MySQL replication garantees at best a replication lag of 0 second
- Galera replication garantees at worst a replication lag in numbers of transactions
- If a node reach its gcs.fc_limit, it sends to the cluster a pause signal : wsrep_flow_control_sent, blocking all writes on the cluster, until (gcs.fc_limit x gcs.fc_factor) is met.
Galera Flow Control
wsrep_provider_options = "gcs.fc_limit = 10000; gcs.fc_factor = 0.8; gcs.fc_master_slave = yes"- gcs.fc_master_slave allows a dynamic change of the gcs.fc_limit (gcs.fc_limit = gcs.fc_limit x nodes quantity)
- In most cases : set to yes to disable
Galera Flow Control
wsrep_provider_options = "gcs.fc_limit = 10000; gcs.fc_factor = 0.8; gcs.fc_master_slave = yes"- IST : Incremental State Transfer
- SST : State SnapshotTransfer (Full dataset)
Automatic Node Provisioning
Joining Cluster Sequence
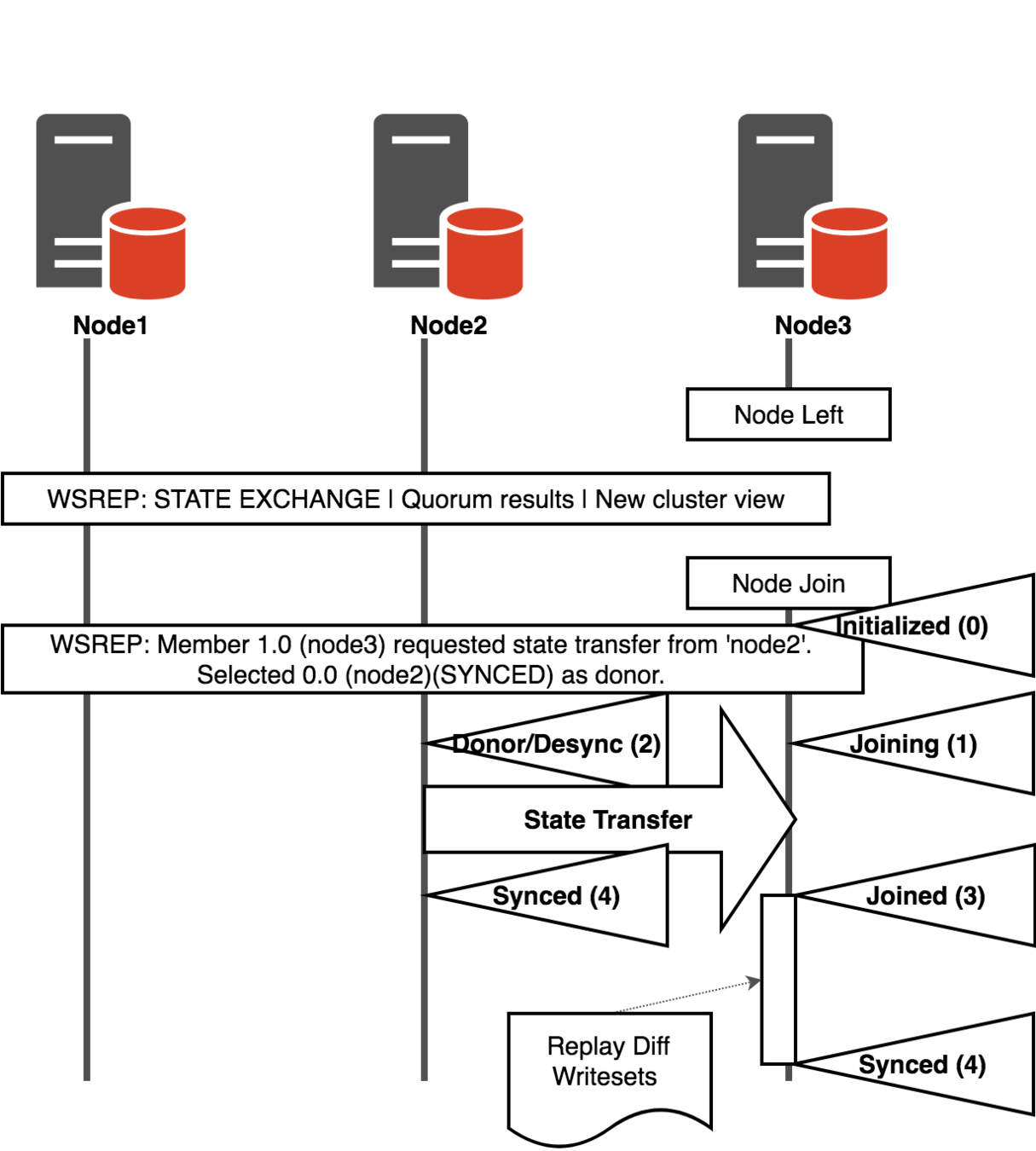
wsrep_local_stateIST
- Occurs when a previously member of the cluster re-joins it, with a consistent data set
- The donor (wsrep_sst_donor) need to have all missing writesets in its Galera cache (and a little more)
- => gcache file should be sized to avoid an SST after a maintenance period
IST - gcache calculation
show global status like 'wsrep_replicated_bytes';
show global status like 'wsrep_received_bytes';
+------------------------+-------------+
| Variable_name | Value |
+------------------------+-------------+
| wsrep_replicated_bytes | 14024686476 |
+------------------------+-------------+
1 row in set (0.01 sec)
+----------------------+----------------+
| Variable_name | Value |
+----------------------+----------------+
| wsrep_received_bytes | 25424591549980 |
+----------------------+----------------+
1 row in set (0.00 sec)
\frac{wsrep\_received\_bytes_{t1} - wsrep\_received\_bytes_{t0} + wsrep\_replicated\_bytes_{t1} - wsrep\_replicated\_bytes_{t0}}
{(t1-t0)}
*
t(downtime)
wsrep_provider_options = "gcache.size=10G"SST with xtrabackup
wsrep_sst_method=xtrabackup-v2- xtrabackup uses innoDB redo log, reads the LSN
- xtrabackup copy the innodb data files and then performs crash recovery
- Non-blocking for innoDB
- my.cnf
[sst]
inno-apply-opts="--use-memory=40G"Schema Upgrades
- TOI - Total Isolation Order
- RSU - Rolling Schema upgrade
- Percona's pt-online-schema-change
Total Order Isolation
- DDL query is replicated as a normal statement
- All nodes executes the modification at the same time, in a isolated way. Deadlock are sent to ongoing transactions, then everything is blocked until the modification is complete.
- We noticed, on a heavy-write cluster, the DDL Query won't even occur.
SET SESSION wsrep_OSU_method='TOI';Rolling Schema Upgrade
- DDL query is applied locally only
- The node is Desynchronized during the schema upgrade
- The query must be applied manually to each node
- There's an intermediate state where the schema is not consistent between the nodes
SET SESSION wsrep_OSU_method='RSU';RSU - Blue/Green deployment ?









IT WORKS IN THEORY
not in production
Rolling Schema Upgrade




What happens when a table is created
pt-online-schema-change
- works with wsrep_OSU_method = TOI
- Copy the structure of the table to be modified
- Apply modifications on the copy
- Copy rows
- Rename tables and drop the old one
- No locks on the source table during operation
- Many security check
pt-online-schema-change --alter "ADD COLUMN c1" D=testdb,t=mytable --max-flow-ctl=33.3 --executept-online-schema-change
pt-online-schema-change --alter "ADD COLUMN c1 INT" D=test,t=history_uint --max-flow-ctl=33.3 --execute
No slaves found. See --recursion-method if host sql01 has slaves.
Not checking slave lag because no slaves were found and --check-slave-lag was not specified.
Operation, tries, wait:
analyze_table, 10, 1
copy_rows, 10, 0.25
create_triggers, 10, 1
drop_triggers, 10, 1
swap_tables, 10, 1
update_foreign_keys, 10, 1
Altering `test`.`history_uint`...
Creating new table...
Created new table test._history_uint_new OK.
Altering new table...
Altered `test`.`_history_uint_new` OK.
2017-10-19T10:40:16 Creating triggers...
2017-10-19T10:40:17 Created triggers OK.
2017-10-19T10:40:17 Copying approximately 1 rows...
2017-10-19T10:40:17 Copied rows OK.
2017-10-19T10:40:17 Analyzing new table...
2017-10-19T10:40:17 Swapping tables...
2017-10-19T10:40:17 Swapped original and new tables OK.
2017-10-19T10:40:17 Dropping old table...
2017-10-19T10:40:17 Dropped old table `test`.`_history_uint_old` OK.
2017-10-19T10:40:17 Dropping triggers...
2017-10-19T10:40:17 Dropped triggers OK.
Successfully altered `test`.`history_uint`.
Schema Upgrade
- Schema updates are more complex to handle with Galera
- Avoid breaking (incompatible) change, like column type
- Disassemble DDL orders in several steps
- Keep DBs schema simples
Load-balancing for Galera
HA Proxy
## Check ports for Mysql:
## Xinetd can answer on these ports
## 9001 : Master : auth test + simple query
## 9002 : Slave : slave is running + slave lag not too high
## 9003 : Galera : galera cluster_status is Primary and local_state is 4
listen vip_mysql
bind 10.10.10.10:3306
default_backend be_mysql
backend be_mysql
balance source
option httpchk GET
server mysql01 10.10.0.12:3306 check port 9003 inter 5s rise 2 fall 3
server mysql02 10.10.0.13:3306 check port 9003 inter 5s rise 2 fall 3 backup
server mysql03 10.10.0.14:3306 check port 9003 inter 5s rise 2 fall 3 backup
TCP Connection but HTTP healthcheck :
Xinetd scripts based on https://github.com/olafz/percona-clustercheck
HA Proxy
- Essential for Galera Operations and failover
- When a node (N1) goes down, a backup (N2) takes over the traffic
- When the node is back :
- New connections are made on N1
- Persistent connections are still operating on N2
- => provokes certifications failures and deadlocks
- Solution :
- => FW N1(port 3306) while State Transfer
- => un-FW N1 and FW N2 when N1 wsrep_local_recv_queue=0
Future for us: ProxySQL
- Sounds promising :
- Seamless failover
- R/W Split, sharding
- operations on query level
- binlogs
Main levers for performances
Hardware / Kernel
-
RAID 10, XFS (25% faster on seq write on HDDs)
-
Linux kernel 4.x (we use 4.9 on Debian 8)
-
System tuning :
-
disk schedulers = deadline on bare metal, noop on VM
-
vm.swapiness = 1
-
increase open-files-limit in limits.conf
-
MTU 9000 (+8% network perf)
-
-
For Galera : same machines for all nodes
- Network tolerance for Galera:
evs.keepalive_period = PT3S; evs.inactive_check_period = PT10S; evs.suspect_timeout = PT30S; evs.inactive_timeout = PT1M; evs.install_timeout = PT1M;"
my.cnf
-
innodb_flush_log_at_trx_commit
-
1 : ACID ! at each transaction : InnoDB log buffer -> log file -> disk.
-
0 : InnoDB log buffer (1/s) -> log file (x/s)-> flush disk.
-
1s lost if any mysqld crashes
-
-
2 : InnoDB log buffer (each transaction)-> log file (x/s)-> flush disk.
-
1s lost if the OS/HW crashes
-
-
-
innodb_flush_log_at_timeout=x
my.cnf
innodb_write_io_threads=4
innodb_read_io_threads=4
innodb_io_capacity=10000
innodb_file_per_table = 1
innodb_file_format = barracuda
innodb_change_buffering=all
innodb_flush_method=O_DIRECT
my.cnf
-
table_definition_cache= 2000
-
table_open_cache = 5000
table_open_cache_instances = 16
my.cnf
- When a table grows and the code can't be modified
Partitioned Tables
CREATE TABLE `history_uint` (
`itemid` bigint(20) unsigned NOT NULL,
`clock` int(11) NOT NULL DEFAULT '0',
`value` bigint(20) unsigned NOT NULL DEFAULT '0',
`ns` int(11) NOT NULL DEFAULT '0',
KEY `history_uint_1` (`itemid`,`clock`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50100 PARTITION BY HASH (itemid)
PARTITIONS 32 */- But as we work with big tables, it's costly : in disk space, I/O, and blocked transactions
Partitioned Tables
ALTER TABLE `history_uint` COALESCE PARTITION 4;
ALTER TABLE `history_uint` ADD PARTITION PARTITIONS 12;
ALTER TABLE `history_uint` REMOVE PARTITIONING;
- Number of partitions can be modified at any time
Partitioned Tables
- Maintenance operations can be done per partition
-
Alter table ... rebuild partition p0
-
Alter table ... optimize partition p0
-
And also : analyze, repair, check
Especially useful for queries on composite index that can return nothing, for instance :
SELECT * FROM history_uint h WHERE h.itemid='541969' AND h.clock>1492000245
Partitioned Tables
SET optimizer_switch = 'index_condition_pushdown=off';If we select only indexed fields, mysql read only index and it's fast. If a result is found, it's also fast.
Otherwise, ICP starts by filtering result with clock field and then filter by itemid.
The problem is, partition hash is by itemid. So there's all partitions to scroll before sending no result.
Partitioned Tables
- Still, queries need to be adapted
-
Wrong:
-
Select data from table_partitioned where id < 100 and id >10
-
-
Correct:
-
Select data from table_partitioned where id in ( 11, 12 … 99)
-
testing : Maxwell
- Reads binary log events and write rows to Kafka
mysql> insert into `test`.`maxwell` set id = 1, daemon = 'Stanislaw Lem';
maxwell: {
"database": "test",
"table": "maxwell",
"type": "insert",
"ts": 1449786310,
"xid": 940752,
"commit": true,
"data": { "id":1, "daemon": "Stanislaw Lem" }
}
Moniroting
Morinoting
Observability

- Cluster Status = Primary
- Flow Control sent / received ~ 0
- Replication queues: local_recv_queue_current < gcs.fc_limit
- Certifications Failures ~ 0
- Local State = 4
- no ERROR in err file
Alerting
- package percona-zabbix-templates
- provides all necessary metrics to monitor properly a Galera or single MySQL Server
Monitoring - zabbix
- TCP Connections must be persistent
- Client must be able to reconnect if connection is dropped
- Optimizer hints are usefull !
- All queries to databases must includes a comment :
Who sent this query ?
SELECT /* machine:/path/to/code class:line */ foo
FROM ….Backups
-
A main cluster has always its delayed slave
-
Binary logs are still collected in real time
-
SQL_Delay guarantees a delay to intervene in case of unwanted drop database or any other PEBCAK
Delayed Slave
CHANGE MASTER TO MASTER_DELAY = 7200;-
the delayed slave runs periodically an innobackupex, streamed with xbstream to backup servers, then prepared (--apply-logs)
-
innobackupex --incremental : differential backup On frequently modified data, incremental backup are not really faster
Cold backups
-
Each full backup can be copied to a dedicated mysql server, to be use to operate the rollback operation
Restore backups
Questions ?
@gestassy // gestassy@synthesio.com
Also: We're Hiring ...
Mysql-Galera@Synthesio
By gestassy
