第1回
ディープラーニング勉強会

Agenda
-
ディープラーニングって何?
-
ニューラルネットワーク
-
そもそも機械学習とは
ディープラーニング
って何?
まずはDemo
Digit Fantasies by a Deep Generative Model
手書き数字認識機を使って、数字画像を出力するデモ
MNISTは手書き数字認識用の標準的なデータセット
28x28ピクセル、各ピクセルは8ビットのグレイスケール、70000サンプルの数字の手書き画像データ
Morphing Faces
こちらは顔認識機のバージョン
Sentiment Analysis
SemanticではなくSentiment Analysis
書かれている文章が、nagativeなのかpositiveなのかを判定する
Deep Dream
Googleが公開したDeep Dreamは、画像認識アルゴリズムを応用して画像の中に「何が写っているか」を認識したものを画像として出力する
ディープラーニング
って何?
結局
ディープラーニングとは
ニューラルネットワークの一種であり、 多層構造のニューラルネットワークに、 脳科学分野の研究を応用したものである。 汎用的なAI、いわゆる強いAIの実現が期待されている。
簡単に言うと
ニューラルネットワークを活用したすごい画期的な技術!
何が凄くて、
何が画期的なのか?
それを理解するために、
ニューラルネットワークと機械学習について調べた
ニューラルネットワーク

-
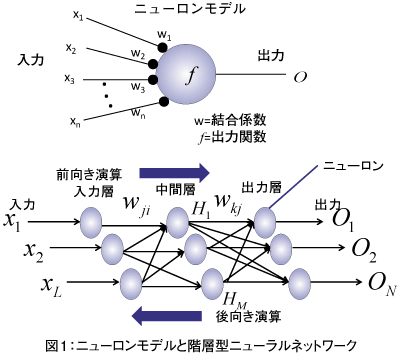
ニューラルネットワークとは
-
ニューラルネットワークの歴史
-
パーセプトロン
-
バックプロパゲーション
-
サポートベクターマシン
-
ディープラーニング
-
ニューラルネットワークとは
人間の脳の神経回路の仕組みを模した人工ニューロンが、
学習によってシナプスの結合強度を変化させ、
問題解決能力を持つようなモデル全般のことを指す

ニューラルネットワークの歴史
パーセプトロン
1958年 視覚と脳の機能をモデル化して、
人工ニューロンを使ったニューロネットワークが考案された。
シンプルなネットワークでありながら学習能力を持つため、
第一次ニューラルネットワークブームを巻き起こした。

しかし、単純パーセプトロンでは
”線形分離可能”な問題しか解けないことが、
1969年に証明されたためブームが終わった。
”線形分離可能”とは
「2つの点の集合が二次元平面上にあるとき、それらの集合を一本の直線で分離できること」
一般化して「n次元空間上の2つの点の集合をn-1次元の超平面で分離できること」も
線形分離可能と呼ぶ
線形分離可能でない簡単な例としては、XOR(排他的論理和)がある


線形分離可能
線形分離不可能
🔰用語説明
バックプロパゲーション
1986年 バックプロパゲーションもしくは誤差逆伝播法が
考案され、多層パーセプトロンの学習が可能になった。
多層になったことで線形分離不可能な問題が解けるようになった。
これにより第二次ニューラルネットワークブームが起きた。

バックプロパゲーションは、
ニューラルネットワークを学習するための
”教師あり学習”の以下の様なアルゴリズム
- ニューラルネットワークに学習データのサンプルを与える
- ネットワークの出力とサンプルの答えを比較し、各出力ニューロン毎に誤差を求める
- 出力層に近い層から順番に、誤差が小さくなるようにニューロン間の重みを修正していく
- 全ての学習データについて、上記のstepを繰り返し重みを収束させる
”教師あり学習”とは
機械学習の学習方法のカテゴリの一つ
”教師あり学習”、”教師なし学習”、”半教師あり学習”、”強化学習” などがある
🔰用語説明
-
教師あり学習:入力と出力の組を元に学習を行う
- 例1:スパム分類(入力=メール、出力=スパムor普通)
- 例2:株価予測(入力=株価に関する全情報、出力=明日の株価)
- 例3:遺伝子と病気の相関分析(入力=各遺伝子の発現量、出力=患者の症状)
-
教師なし学習:入力データのみから学習を行う
- 例1:店舗クラスタリング(入力=店舗情報、出力=似た店舗グループに分類)
- 例2:不正アクセス検出(入力=パケット、出力=通常のアクセスパターンと異なるかどうか)
- 半教師あり学習:教師ありデータとなしデータが混在したデータで学習を行う
- 強化学習:試行した結果、環境から得られたフィードバックによって学習を行う。主に機械制御などに使われる。
バックプロパゲーションの限界
- 学習での収束が遅い
- 局所解にハマりやすい
- そもそも汎化能力が高くなかった
1992年サポートベクターマシンが考案され、
汎化能力が高く収束が早かったため
バックプロパゲーションと
第二次ニューラルネットワークのブームは終わった
”汎化能力”とは
🔰用語説明
学習データだけではなく、未知のデータに対しても
正しく分類・予測ができる能力
学習データだけに最適化されてしまい、未知のデータに対して
正しい分類や予測ができない状態を ”過学習” と言う
過学習が起きる主な原因
- 学習データが少なすぎて、偏りがある場合
- データの特徴数が多すぎる場合
- 狭い範囲のデータで学習した場合
- 過去のデータに適応しすぎた場合
SVM
サポートベクターマシン

1992年に考案されたサポートベクターマシンは、
2値の識別を行う識別器を構成する。
学習データを分割する
マージンが最大となる超平面を求めるアルゴリズム。
サポートベクターマシンの特徴
- マージンを最大化するため汎化能力が高く、パターン識別能力がとても優秀
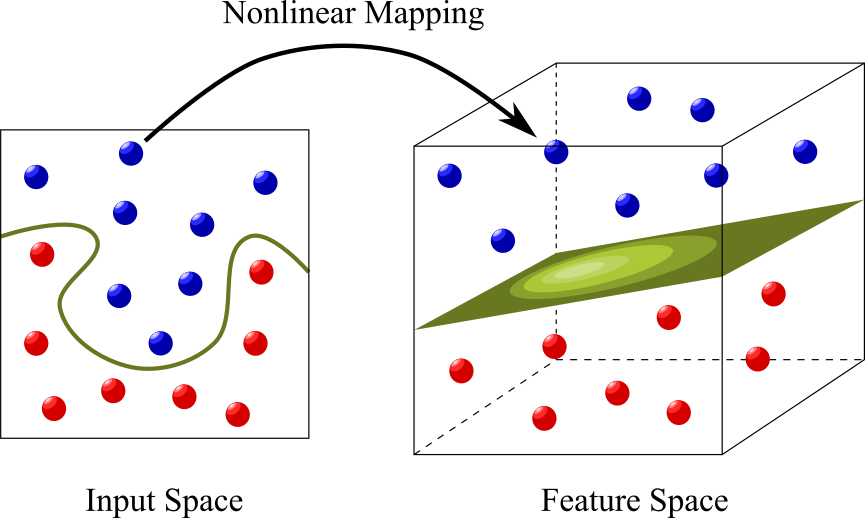
- 線形分離を行うアルゴリズムだが、
”カーネルトリック”と言われる手法に
よりデータを高次元に射影すること
で、線形分離不可能な問題も解ける - アルゴリズムに正則化(過学習を防ぐ仕組み)
の項が含まれている - SVMはニューラルネットワークではなく、代数的な手法
とにかく凄い!
SVMのDemo
ディープラーニング
2006年に脳の視覚野の研究結果等を参考にして、
多層のニューラルネットワークを用いる手法が考案された。
教師なし学習によってデータのパターンを
自動で発見できることが最大の特徴

ニューラルネットワークの逆襲
ニューラルネットワークの逆襲
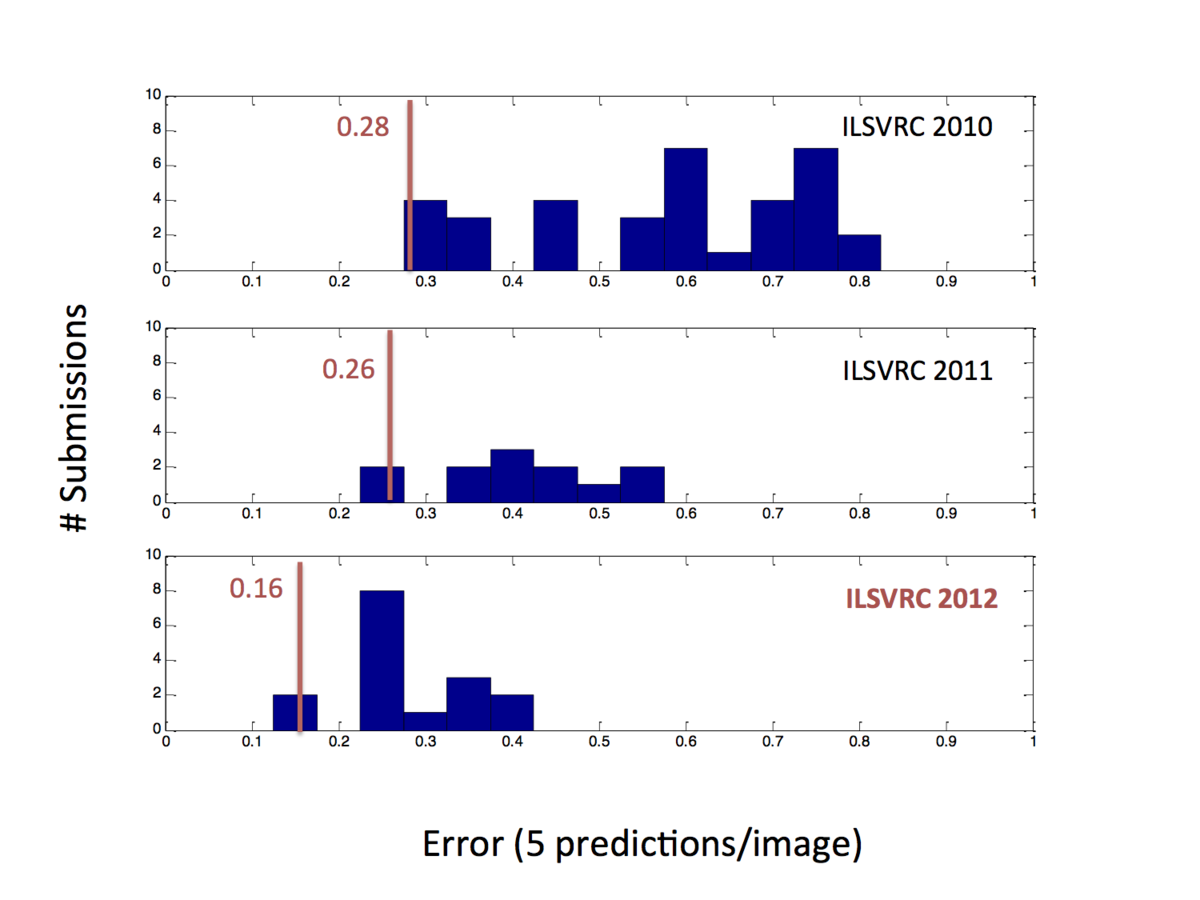
2012年のLSVRCにてディープラーニングを使ったチームがダントツで(エラー率1%で競っている中で10%の大差で)優勝した。
LSVRC(Large Scale Visual Recognition Challenge 2012) は画像認識を競うコンテストで、他のチームはほぼSVMを使っていた。その後、数々のコンテストでディープラーニングを使ったチームが優勝する自体になり、現在のブームが始まった。
同じ時期にGoogleがYoutubeの画像を元に学習させたところ、猫を識別できるニューロンができたと話題になったりした。
http://googleblog.blogspot.jp/2012/06/using-large-scale-brain-simulations-for.html
ディープラーニングの特徴
- 7層や8層といった多層のニューラルネットワークを使う。
バックプロパゲーションでの多層ではうまく学習できない問題は、1層づつ入力と同じものを正解とする学習を行うことで克服した(単純に学習を行うだけでは恒等写像になってしまうが、ノード数を減らしたり、ノイズを足したり、入力データを平行移動したり、ランダムに一部のノードを止めたり、することで特徴をうまく抽出できる)。 - 畳み込みニューラルネットワークを使うことで、特徴を不変量として認識できる。画像認識の場合には、画像内のどこにあっても特徴を認識できることになる。
←イマココ
そもそも機械学習とは

-
機械学習とは
-
機械学習の重要な5概念
-
機械学習の応用例
-
まとめ
機械学習とは
明示的にプログラミングすることなく,
コンピュータに行動させるようにする科学by Andrew Ng
機械学習とは
- 大量の条件を元にした判断
→全ての条件を人が設定するのが難しい
さらに設定した結果の整合性を確認するのが大変 - 判断のためのデータが大量にある場合
→データが多すぎて人が見た時に、
どのデータを使うべきなのか取捨選択が難しい
しかし、絞りこまないと現実的な時間で処理できない
これらの問題を
解決するためのツール
機械学習の重要な5概念
特徴表現
汎化・過学習
正則化
次元の呪い
BiasとVariance
特徴表現
入力データから特徴を抽出して、
学習に使える特徴ベクトルで表すこと
入力データ例:テキスト、画像、音声、数値、等
このお陰で入力データがどんなものであれ、
同じアルゴリズムが使えるようになった
汎化・過学習
「未知のデータを正しく予測できるような、
ルールを学習する」こと
教師事例を 100%正しく分類できても、
未知のデータを正しく分類できるとは限らない
正則化
学習時に「教師事例を正しく分類する」
以外の目標を導入すること
例1:単純なモデルを選ぶような制約を追加する(過学習を防ぐ)
例2:問題に対する事前知識を組み込む
次元の呪い
高次元データを扱う場合に、様々な困難が付き纏う
- 対象の次元の増加に伴って必要なサンプル数が急増する
- 1辺の長さが10の超立方体中の単位立方体の数
3次元の場合 1000だけど、10次元で10000000000
- 1辺の長さが10の超立方体中の単位立方体の数
- 高次元中においては、ほとんどの点が中心から遠い
- 1辺の長さ1の超立方体の中で、1辺が0.9の超立方体が占める体積は、3次元の場合 72%、100次元の場合 0.002%
BiasとVariance
学習結果による推定の誤差は次の2つに分類される
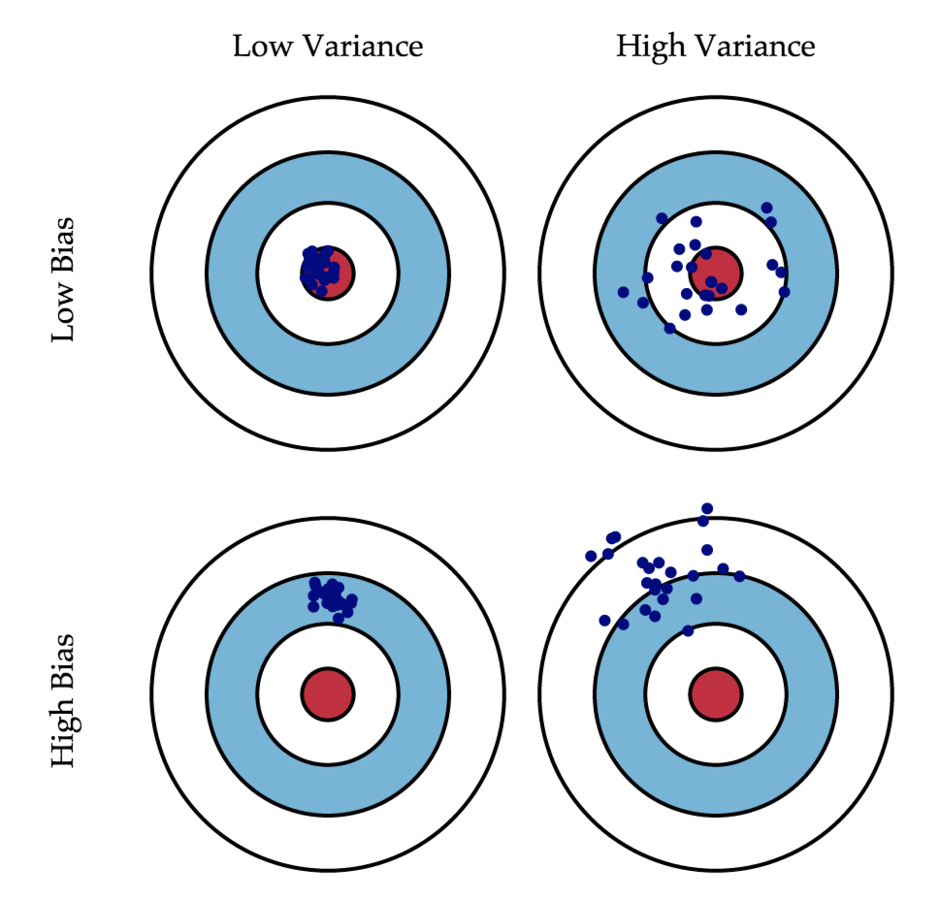
- Bias:
学習モデルの期待値と、
真のモデルとの差 - Variance:
各推定結果のぶれぐあい
この2つの値はトレードオフ
機械学習の応用例
- スパムフィルタ:ベイジアンフィルタ(ナイーブベイズ)
- 検索エンジン(Google):ページランク(マルコフ連鎖)
- お勧め(Amazon等):協調フィルタリング
- ダイレクトマーケティング:ロジスティック回帰
- 音声認識、手書き文字認識:隠れマルコフモデル
- 日本語の文字認識: 2次識別関数
- 画像認識:ディープラーニング
- 今までは、3層パーセプトロンやSVMが使われていた
なんでこんなに色々あるの?
全部ディープラーニングで良いじゃん?
なんでこんなに色々あるの?
全部ディープラーニングで良いじゃん?
ノーフリーランチ定理
There ain't no such thing as a free lunch.
― The Moon Is a Harsh Mistress by Robert Heinlein (1966)
ノーフリーランチ定理
……コスト関数の極値を探索するあらゆるアルゴリズムは、全ての可能なコスト関数に適用した結果を平均すると同じ性能となる
— Wolpert and Macready、1995年

ノーフリーランチ定理
万能なアルゴリズムは存在しえない
しかし、必要なのは目の前の問題を解決するためのツール
問題に対応するために最適なアルゴリズムを用意し、
問題の事前知識を使った最適化を施すのが最良ということ
結局、ディープラーニングも万能ではない
何が凄くて、
何が画期的なのか?
ディープラーニングの
醜いアヒルの子の定理
醜いアヒルの子と普通のアヒルの子の類似性は、
任意の二匹の普通のアヒルの子の間の類似性と等しい

どの特徴に注目するかが重要
醜いアヒルの子の定理
どの特徴を使うか(特徴選択・特徴抽出)が本質的に重要
今までの機械学習では
ヒューリスティックな手法で解決(?)していた。
しかし、ディープラーニングではこの特徴抽出を
ニューラルネットワークで自動で行えるようになった。
だから、画期的だったんです
参考資料

ディープラーニング、
ビッグデータ、
機械学習
あるいはその心理学
個人的に購入。
今までの歴史や研究の背景などが書かれていて、とても参考になった。
機械学習のアルゴリズムなどはさらっと書かれているので、ちゃんと勉強するには別の本が必要
本
- 機械学習チュートリアル (slideshare)
まずはチュートリアル - 機械学習の理論と実践 (pdf, slideshare)
この資料を作るに当たって参考にさせて頂きました
SACSIS2013でチュートリアル講演に使われた資料 -
パターン認識と機械学習入門 (slideshare)
入門資料と見せかけて読み物的なスライド
ページ数が多い - 結局どのアルゴリズムが良いのか? (pdf)
ノーフリーランチ定理と醜いアヒルの子の定理について - 一般向けの Deep Learning (slideshare)
- Deep Learning (slideshare)
この2つを読めば、Deep Learningをなんとなくわかった気になれる
参考にした資料
- 機械学習とは何か? (html)
機械学習って何?という質問の答えを探す記事 - 日常にある機械学習の応用例 (html)
機械学習の様々な応用例と分類について - 機械学習アルゴリズムまとめ (html)
機械学習で使われるアルゴリズムの紹介 - RBMから考えるDeep Learning ~黒魔術を添えて~ (html)
Deep Learningで必ず出てくるRBM(Restricted Boltzmann Machine)とDBN(Deep Belief Network)について書きつつ、Deep Learningに対する疑問点などが書かれている - Theano で Deep Learning (html)
TheanoというPythonの機械学習フレームワークの説明記事だが、機械学習のアルゴリズム自体も説明されている良記事
参考にしたページ
リンク集など
first Deep-Learning study session
By Hiroki Horiuchi
first Deep-Learning study session
第0回 ディープラーニング勉強会



