Data science for lazy people... genetics will work for you!
Diego Hueltes
About me
- Python engineer at RavenPack in Marbella, Málaga (we're hiring)
- Big Data teacher and mentor at EOI (Escuela de Organización Industrial)
- Data science enthusiast





lazy Oxford dictionary
Unwilling to work or use energy
in repetitive tasks
Diego dictionary
Original image from https://github.com/rhiever/tpot

Automated Machine Learning
TPOT is a Python tool that automatically creates and optimizes machine learning pipelines using genetic programming.
Scikit-learn pipelines
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.svm import LinearSVC
count_vectorizer = CountVectorizer(ngram_range=(1, 4), analyzer='char')
X_train = count_vectorizer.fit_transform(train)
X_test = count_vectorizer.transform(test)
linear_svc = LinearSVC()
model = linear_svc.fit(X_train, y_train)
y_test = model.predict(X_test)from sklearn.feature_extraction.text import CountVectorizer
from sklearn.svm import LinearSVC
pipeline = Pipeline([
('count_vectorizer', CountVectorizer(ngram_range=(1, 4), analyzer='char')),
('linear_svc', LinearSVC())
])
model = pipeline.fit(train)
y_test = model.predict(test)
feature_selection.GenericUnivariateSelect([...])
feature_selection.SelectPercentile([...])
feature_selection.SelectKBest([score_func, k])
feature_selection.SelectFpr([score_func, alpha])
feature_selection.SelectFdr([score_func, alpha])
feature_selection.SelectFromModel(estimator)
feature_selection.SelectFwe([score_func, alpha])
feature_selection.RFE(estimator[, ...])
feature_selection.RFECV(estimator[, step, ...])
feature_selection.VarianceThreshold([threshold])
feature_selection.chi2(X, y)
feature_selection.f_classif(X, y)
feature_selection.f_regression(X, y[, center])
feature_selection.mutual_info_classif(X, y)
feature_selection.mutual_info_regression(X, y)Feature selectors
preprocessing.Binarizer([threshold, copy])
preprocessing.FunctionTransformer([func, ...])
preprocessing.Imputer([missing_values, ...])
preprocessing.KernelCenterer
preprocessing.LabelBinarizer([neg_label, ...])
preprocessing.LabelEncoder
preprocessing.MultiLabelBinarizer([classes, ...])
preprocessing.MaxAbsScaler([copy])
preprocessing.MinMaxScaler([feature_range, copy])
preprocessing.Normalizer([norm, copy])
preprocessing.OneHotEncoder([n_values, ...])
preprocessing.PolynomialFeatures([degree, ...])
preprocessing.RobustScaler([with_centering, ...])
preprocessing.StandardScaler([copy, ...])
preprocessing.add_dummy_feature(X[, value])
preprocessing.binarize(X[, threshold, copy])
preprocessing.label_binarize(y, classes[, ...])
preprocessing.maxabs_scale(X[, axis, copy])
preprocessing.minmax_scale(X[, ...])
preprocessing.normalize(X[, norm, axis, ...])
preprocessing.robust_scale(X[, axis, ...])
preprocessing.scale(X[, axis, with_mean, ...])Preprocessors
sklearn.ensemble.GradientBoostingClassifier
sklearn.tree.DecisionTreeClassifier
sklearn.neighbors.KNeighborsClassifier
sklearn.ensemble.ExtraTreesClassifier
xgboost.XGBClassifier
sklearn.ensemble.RandomForestClassifier
sklearn.linear_model.LogisticRegression
sklearn.svm.LinearSVC
sklearn.neighbors.KNeighborsRegressor
sklearn.linear_model.RidgeCV
sklearn.linear_model.ElasticNetCV
sklearn.tree.DecisionTreeRegressor
sklearn.ensemble.AdaBoostRegressor
sklearn.ensemble.GradientBoostingRegressor
sklearn.svm.LinearSVR
sklearn.linear_model.LassoLarsCV
sklearn.ensemble.ExtraTreesRegressor
sklearn.ensemble.RandomForestRegressor
xgboost.XGBRegressorClassifiers & Regressors
Genetic programming

Source: http://www.genetic-programming.org/gpbook4toc.html
Photo: Diego Hueltes

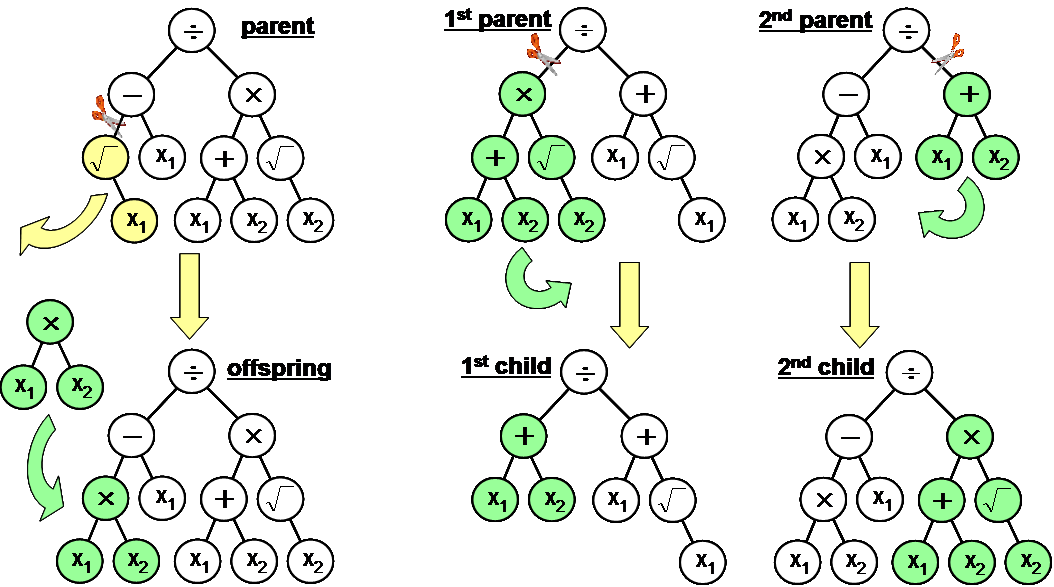
Crossover
Mutation
Source http://w3.onera.fr/smac/?q=tracker

TPOT
from tpot import TPOTClassifier, TPOTRegressor
tpot = TPOTClassifier()
tpot.fit(X_train, y_train)
tpot = TPOTRegressor()
tpot.fit(X_train, y_train)
Basic usage
$ tpot data/mnist.csv -is , -target class -o tpot_exported_pipeline.py -g 5 -p 20Parameters
class TPOTBase(BaseEstimator):
def __init__(self, generations=100, population_size=100, offspring_size=None,
mutation_rate=0.9, crossover_rate=0.1,
scoring=None, cv=5, n_jobs=1,
max_time_mins=None, max_eval_time_mins=5,
random_state=None, config_dict=None, warm_start=False,
verbosity=0, disable_update_check=False):Config dict
classifier_config_dict = {
# Classifiers
'sklearn.naive_bayes.GaussianNB': {
},
'sklearn.naive_bayes.BernoulliNB': {
'alpha': [1e-3, 1e-2, 1e-1, 1., 10., 100.],
'fit_prior': [True, False]
},
'sklearn.naive_bayes.MultinomialNB': {
'alpha': [1e-3, 1e-2, 1e-1, 1., 10., 100.],
'fit_prior': [True, False]
},
'sklearn.tree.DecisionTreeClassifier': {
'criterion': ["gini", "entropy"],
'max_depth': range(1, 11),
'min_samples_split': range(2, 21),
'min_samples_leaf': range(1, 21)
},
'sklearn.ensemble.ExtraTreesClassifier': {
'n_estimators': [100],
'criterion': ["gini", "entropy"],
'max_features': np.arange(0.05, 1.01, 0.05),
'min_samples_split': range(2, 21),
'min_samples_leaf': range(1, 21),
'bootstrap': [True, False]
},
'sklearn.ensemble.RandomForestClassifier': {
'n_estimators': [100],
'criterion': ["gini", "entropy"],
'max_features': np.arange(0.05, 1.01, 0.05),
'min_samples_split': range(2, 21),
'min_samples_leaf': range(1, 21),
'bootstrap': [True, False]
},
'sklearn.ensemble.GradientBoostingClassifier': {
'n_estimators': [100],
'learning_rate': [1e-3, 1e-2, 1e-1, 0.5, 1.],
'max_depth': range(1, 11),
'min_samples_split': range(2, 21),
'min_samples_leaf': range(1, 21),
'subsample': np.arange(0.05, 1.01, 0.05),
'max_features': np.arange(0.05, 1.01, 0.05)
},
'sklearn.neighbors.KNeighborsClassifier': {
'n_neighbors': range(1, 101),
'weights': ["uniform", "distance"],
'p': [1, 2]
},
'sklearn.svm.LinearSVC': {
'penalty': ["l1", "l2"],
'loss': ["hinge", "squared_hinge"],
'dual': [True, False],
'tol': [1e-5, 1e-4, 1e-3, 1e-2, 1e-1],
'C': [1e-4, 1e-3, 1e-2, 1e-1, 0.5, 1., 5., 10., 15., 20., 25.]
},
'sklearn.linear_model.LogisticRegression': {
'penalty': ["l1", "l2"],
'C': [1e-4, 1e-3, 1e-2, 1e-1, 0.5, 1., 5., 10., 15., 20., 25.],
'dual': [True, False]
},
'xgboost.XGBClassifier': {
'n_estimators': [100],
'max_depth': range(1, 11),
'learning_rate': [1e-3, 1e-2, 1e-1, 0.5, 1.],
'subsample': np.arange(0.05, 1.01, 0.05),
'min_child_weight': range(1, 21),
'nthread': [1]
},
# Preprocesssors
'sklearn.preprocessing.Binarizer': {
'threshold': np.arange(0.0, 1.01, 0.05)
},
'sklearn.decomposition.FastICA': {
'tol': np.arange(0.0, 1.01, 0.05)
},
'sklearn.cluster.FeatureAgglomeration': {
'linkage': ['ward', 'complete', 'average'],
'affinity': ['euclidean', 'l1', 'l2', 'manhattan', 'cosine', 'precomputed']
},
'sklearn.preprocessing.MaxAbsScaler': {
},
'sklearn.preprocessing.MinMaxScaler': {
},
'sklearn.preprocessing.Normalizer': {
'norm': ['l1', 'l2', 'max']
},
'sklearn.kernel_approximation.Nystroem': {
'kernel': ['rbf', 'cosine', 'chi2', 'laplacian', 'polynomial', 'poly', 'linear', 'additive_chi2', 'sigmoid'],
'gamma': np.arange(0.0, 1.01, 0.05),
'n_components': range(1, 11)
},
'sklearn.decomposition.PCA': {
'svd_solver': ['randomized'],
'iterated_power': range(1, 11)
},
'sklearn.preprocessing.PolynomialFeatures': {
'degree': [2],
'include_bias': [False],
'interaction_only': [False]
},
'sklearn.kernel_approximation.RBFSampler': {
'gamma': np.arange(0.0, 1.01, 0.05)
},
'sklearn.preprocessing.RobustScaler': {
},
'sklearn.preprocessing.StandardScaler': {
},
'tpot.built_in_operators.ZeroCount': {
},
# Selectors
'sklearn.feature_selection.SelectFwe': {
'alpha': np.arange(0, 0.05, 0.001),
'score_func': {
'sklearn.feature_selection.f_classif': None
} # read from dependencies ! need add an exception in preprocess_args
},
'sklearn.feature_selection.SelectKBest': {
'k': range(1, 100), # need check range!
'score_func': {
'sklearn.feature_selection.f_classif': None
}
},
'sklearn.feature_selection.SelectPercentile': {
'percentile': range(1, 100),
'score_func': {
'sklearn.feature_selection.f_classif': None
}
},
'sklearn.feature_selection.VarianceThreshold': {
'threshold': np.arange(0.05, 1.01, 0.05)
},
'sklearn.feature_selection.RFE': {
'step': np.arange(0.05, 1.01, 0.05),
'estimator': {
'sklearn.ensemble.ExtraTreesClassifier': {
'n_estimators': [100],
'criterion': ['gini', 'entropy'],
'max_features': np.arange(0.05, 1.01, 0.05)
}
}
},
'sklearn.feature_selection.SelectFromModel': {
'threshold': np.arange(0, 1.01, 0.05),
'estimator': {
'sklearn.ensemble.ExtraTreesClassifier': {
'n_estimators': [100],
'criterion': ['gini', 'entropy'],
'max_features': np.arange(0.05, 1.01, 0.05)
}
}
}
}
'sklearn.ensemble.GradientBoostingClassifier': {
'n_estimators': [100],
'learning_rate': [1e-3, 1e-2, 1e-1, 0.5, 1.],
'max_depth': range(1, 11),
'min_samples_split': range(2, 21),
'min_samples_leaf': range(1, 21),
'subsample': np.arange(0.05, 1.01, 0.05),
'max_features': np.arange(0.05, 1.01, 0.05)
},
'sklearn.neighbors.KNeighborsClassifier': {
'n_neighbors': range(1, 101),
'weights': ["uniform", "distance"],
'p': [1, 2]
},
'sklearn.svm.LinearSVC': {
'penalty': ["l1", "l2"],
'loss': ["hinge", "squared_hinge"],
'dual': [True, False],
'tol': [1e-5, 1e-4, 1e-3, 1e-2, 1e-1],
'C': [1e-4, 1e-3, 1e-2, 1e-1, 0.5, 1., 5., 10., 15., 20., 25.]
},
'sklearn.linear_model.LogisticRegression': {
'penalty': ["l1", "l2"],
'C': [1e-4, 1e-3, 1e-2, 1e-1, 0.5, 1., 5., 10., 15., 20., 25.],
'dual': [True, False]
},
'xgboost.XGBClassifier': {
'n_estimators': [100],
'max_depth': range(1, 11),
'learning_rate': [1e-3, 1e-2, 1e-1, 0.5, 1.],
'subsample': np.arange(0.05, 1.01, 0.05),
'min_child_weight': range(1, 21),
'nthread': [1]
},
# Preprocesssors
'sklearn.preprocessing.Binarizer': {
'threshold': np.arange(0.0, 1.01, 0.05)
},
'sklearn.decomposition.FastICA': {
'tol': np.arange(0.0, 1.01, 0.05)
},
'sklearn.cluster.FeatureAgglomeration': {
'linkage': ['ward', 'complete', 'average'],
'affinity': ['euclidean', 'l1', 'l2', 'manhattan', 'cosine', 'precomputed']
},
'sklearn.preprocessing.MaxAbsScaler': {
},
'sklearn.preprocessing.MinMaxScaler': {
},
'sklearn.preprocessing.Normalizer': {
'norm': ['l1', 'l2', 'max']
},
'sklearn.kernel_approximation.Nystroem': {
'kernel': ['rbf', 'cosine', 'chi2', 'laplacian', 'polynomial', 'poly', 'linear', 'additive_chi2', 'sigmoid'],
'gamma': np.arange(0.0, 1.01, 0.05),
'n_components': range(1, 11)
},
'sklearn.decomposition.PCA': {
'svd_solver': ['randomized'],
'iterated_power': range(1, 11)
},
'sklearn.preprocessing.PolynomialFeatures': {
'degree': [2],
'include_bias': [False],
'interaction_only': [False]
},
'sklearn.kernel_approximation.RBFSampler': {
'gamma': np.arange(0.0, 1.01, 0.05)
},
'sklearn.preprocessing.RobustScaler': {
},
'sklearn.preprocessing.StandardScaler': {
},
'tpot.built_in_operators.ZeroCount': {
},
# Selectors
'sklearn.feature_selection.SelectFwe': {
'alpha': np.arange(0, 0.05, 0.001),
'score_func': {
'sklearn.feature_selection.f_classif': None
} # read from dependencies ! need add an exception in preprocess_args
},
'sklearn.feature_selection.SelectKBest': {
'k': range(1, 100), # need check range!
'score_func': {
'sklearn.feature_selection.f_classif': None
}
},
'sklearn.feature_selection.SelectPercentile': {
'percentile': range(1, 100),
'score_func': {
'sklearn.feature_selection.f_classif': None
}
},
'sklearn.feature_selection.VarianceThreshold': {
'threshold': np.arange(0.05, 1.01, 0.05)
},
'sklearn.feature_selection.RFE': {
'step': np.arange(0.05, 1.01, 0.05),
'estimator': {
'sklearn.ensemble.ExtraTreesClassifier': {
'n_estimators': [100],
'criterion': ['gini', 'entropy'],
'max_features': np.arange(0.05, 1.01, 0.05)
}
}
},
'sklearn.feature_selection.SelectFromModel': {
'threshold': np.arange(0, 1.01, 0.05),
'estimator': {
'sklearn.ensemble.ExtraTreesClassifier': {
'n_estimators': [100],
'criterion': ['gini', 'entropy'],
'max_features': np.arange(0.05, 1.01, 0.05)
}
}
}
}
# Preprocesssors
'sklearn.preprocessing.Binarizer': {
'threshold': np.arange(0.0, 1.01, 0.05)
},
'sklearn.decomposition.FastICA': {
'tol': np.arange(0.0, 1.01, 0.05)
},
'sklearn.cluster.FeatureAgglomeration': {
'linkage': ['ward', 'complete', 'average'],
'affinity': ['euclidean', 'l1', 'l2', 'manhattan', 'cosine', 'precomputed']
},
'sklearn.preprocessing.MaxAbsScaler': {
},
'sklearn.preprocessing.MinMaxScaler': {
},
'sklearn.preprocessing.Normalizer': {
'norm': ['l1', 'l2', 'max']
},
'sklearn.kernel_approximation.Nystroem': {
'kernel': ['rbf', 'cosine', 'chi2', 'laplacian', 'polynomial', 'poly', 'linear', 'additive_chi2', 'sigmoid'],
'gamma': np.arange(0.0, 1.01, 0.05),
'n_components': range(1, 11)
},
'sklearn.decomposition.PCA': {
'svd_solver': ['randomized'],
'iterated_power': range(1, 11)
},
'sklearn.preprocessing.PolynomialFeatures': {
'degree': [2],
'include_bias': [False],
'interaction_only': [False]
},
'sklearn.kernel_approximation.RBFSampler': {
'gamma': np.arange(0.0, 1.01, 0.05)
},
'sklearn.preprocessing.RobustScaler': {
},
'sklearn.preprocessing.StandardScaler': {
},
'tpot.built_in_operators.ZeroCount': {
},
# Selectors
'sklearn.feature_selection.SelectFwe': {
'alpha': np.arange(0, 0.05, 0.001),
'score_func': {
'sklearn.feature_selection.f_classif': None
} # read from dependencies ! need add an exception in preprocess_args
},
'sklearn.feature_selection.SelectKBest': {
'k': range(1, 100), # need check range!
'score_func': {
'sklearn.feature_selection.f_classif': None
}
},
'sklearn.feature_selection.SelectPercentile': {
'percentile': range(1, 100),
'score_func': {
'sklearn.feature_selection.f_classif': None
}
},
'sklearn.feature_selection.VarianceThreshold': {
'threshold': np.arange(0.05, 1.01, 0.05)
},
'sklearn.feature_selection.RFE': {
'step': np.arange(0.05, 1.01, 0.05),
'estimator': {
'sklearn.ensemble.ExtraTreesClassifier': {
'n_estimators': [100],
'criterion': ['gini', 'entropy'],
'max_features': np.arange(0.05, 1.01, 0.05)
}
}
},
'sklearn.feature_selection.SelectFromModel': {
'threshold': np.arange(0, 1.01, 0.05),
'estimator': {
'sklearn.ensemble.ExtraTreesClassifier': {
'n_estimators': [100],
'criterion': ['gini', 'entropy'],
'max_features': np.arange(0.05, 1.01, 0.05)
}
}
}
}
Basic example
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64),
iris.target.astype(np.float64), train_size=0.8, test_size=0.2)
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, n_jobs=-1)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
Optimization Progress: 33%|███▎ | 100/300 [00:25<02:36, 1.28pipeline/s]
Generation 1 - Current best internal CV score: 0.9833333333333334
Optimization Progress: 50%|█████ | 150/300 [00:39<00:58, 2.57pipeline/s]
Generation 2 - Current best internal CV score: 0.9833333333333334
Optimization Progress: 67%|██████▋ | 200/300 [00:52<00:28, 3.48pipeline/s]
Generation 3 - Current best internal CV score: 0.9833333333333334
Optimization Progress: 83%|████████▎ | 250/300 [01:05<00:10, 4.66pipeline/s]
Generation 4 - Current best internal CV score: 0.9833333333333334
Generation 5 - Current best internal CV score: 0.9916666666666668
Best pipeline: KNeighborsClassifier(Nystroem(input_matrix, Nystroem__gamma=0.4, Nystroem__kernel=linear, Nystroem__n_components=DEFAULT), KNeighborsClassifier__n_neighbors=12, KNeighborsClassifier__p=1, KNeighborsClassifier__weights=DEFAULT)
0.933333333333Exporting
tpot.export('tpot_exported_pipeline.py')import numpy as np
from sklearn.kernel_approximation import Nystroem
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
# NOTE: Make sure that the class is labeled 'class' in the data file
tpot_data = np.recfromcsv('PATH/TO/DATA/FILE', delimiter='COLUMN_SEPARATOR', dtype=np.float64)
features = np.delete(tpot_data.view(np.float64).reshape(tpot_data.size, -1), tpot_data.dtype.names.index('class'), axis=1)
training_features, testing_features, training_classes, testing_classes = \
train_test_split(features, tpot_data['class'], random_state=42)
exported_pipeline = make_pipeline(
Nystroem(gamma=0.4, kernel="linear"),
KNeighborsClassifier(n_neighbors=12, p=1)
)
exported_pipeline.fit(training_features, training_classes)
results = exported_pipeline.predict(testing_features)
Titanic example
def load_and_clean(filename, encoders=None):
"""Read csv and perform basic labeling encoding"""
df = pd.read_csv(filename)
if not encoders:
encoders = {'Sex': LabelEncoder(),
'Cabin': LabelEncoder(),
'Embarked': LabelEncoder()}
for column, encoder in encoders.items():
encoder.fit(list(df[column].astype(str)) + ['UnknownLabel'])
df[column] = encoder.transform(df[column].astype(str))
else:
for column, encoder in encoders.items():
df.loc[~df[column].isin(encoder.classes_), column] = 'UnknownLabel'
df[column] = encoder.transform(df[column].astype(str))
df = df.fillna(-999)
passenger_ids = df['PassengerId']
df = df.drop(['PassengerId', 'Name', 'Ticket'], axis=1)
return df, encoders, passenger_ids
train, encoders, _ = load_and_clean('titanic/train.csv')Titanic example
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2,n_jobs=-1,
scoring='accuracy', )
tpot.fit(train.drop('Survived', axis=1), train['Survived'])
Optimization Progress: 33%|███▎ | 100/300 [00:21<01:37, 2.05pipeline/s]
Generation 1 - Current best internal CV score: 0.8306115674694577
Optimization Progress: 50%|█████ | 150/300 [00:45<01:01, 2.43pipeline/s]
Generation 2 - Current best internal CV score: 0.8306115674694577
Optimization Progress: 67%|██████▋ | 200/300 [01:02<00:30, 3.32pipeline/s]
Generation 3 - Current best internal CV score: 0.8306115674694577
Optimization Progress: 83%|████████▎ | 250/300 [01:25<00:20, 2.38pipeline/s]
Generation 4 - Current best internal CV score: 0.8306115674694577
Generation 5 - Current best internal CV score: 0.8306115674694577
Best pipeline:
XGBClassifier(RandomForestClassifier(input_matrix, RandomForestClassifier__bootstrap=True,
RandomForestClassifier__criterion=entropy,
RandomForestClassifier__max_features=0.85,
RandomForestClassifier__min_samples_leaf=4,
RandomForestClassifier__min_samples_split=13,
RandomForestClassifier__n_estimators=100),
XGBClassifier__learning_rate=0.5, XGBClassifier__max_depth=6, XGBClassifier__min_child_weight=20,
XGBClassifier__n_estimators=DEFAULT, XGBClassifier__nthread=1, XGBClassifier__subsample=0.9)Titanic example
from copy import copy
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.pipeline import make_pipeline, make_union
from sklearn.preprocessing import FunctionTransformer
from xgboost import XGBClassifier
exported_pipeline = make_pipeline(
make_union(VotingClassifier([("est", RandomForestClassifier(bootstrap=True, criterion="entropy",
max_features=0.8500000000000001, min_samples_leaf=4,
min_samples_split=13, n_estimators=100))]),
FunctionTransformer(copy)),
XGBClassifier(learning_rate=0.5, max_depth=6, min_child_weight=20, nthread=1, subsample=0.9000000000000001)
)
TPOT accuracy: 0.8306
Kaggle accuracy: 0.7895
House prices example
def load_and_clean(filename, encoders=None):
df = pd.read_csv(filename)
if not encoders:
encoders ={column: LabelEncoder()
for column, column_type in df.dtypes.items()
if str(column_type) == 'object'}
for column, encoder in encoders.items():
encoder.fit(list(df[column].astype(str)) + ['UnknownLabel'])
df[column] = encoder.transform(df[column].astype(str))
else:
for column, encoder in encoders.items():
df.loc[~df[column].isin(encoder.classes_), column] = 'UnknownLabel'
df[column] = encoder.transform(df[column].astype(str))
df = df.fillna(-999)
ids = df['Id']
df = df.drop(['Id'], axis=1)
return df, encoders, idsHouse prices example
tpot = TPOTRegressor(generations=5, population_size=50, verbosity=2,
n_jobs=-1, scoring=rmserror_log)
tpot.fit(train.drop('SalePrice', axis=1), train['SalePrice'])def rmserror_log(predictions, targets):
return np.sqrt(((np.log(predictions) - np.log(targets)) ** 2).mean())exported_pipeline = make_pipeline(
make_union(VotingClassifier([("est", RidgeCV())]), FunctionTransformer(copy)),
make_union(VotingClassifier([("est", ElasticNetCV(l1_ratio=0.4, tol=0.0001))]),
FunctionTransformer(copy)),
XGBRegressor(max_depth=4, min_child_weight=1, nthread=1, subsample=0.9000000000000001)
)
exported_pipeline.fit(train.drop('SalePrice', axis=1), train['SalePrice'])
results = exported_pipeline.predict(test)With custom dict
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, n_jobs=-1,
scoring='accuracy', cv=10, config_dict={
'sklearn.ensemble.RandomForestClassifier': {
'n_estimators': [100],
'criterion': ["entropy"],
'max_features': [0.85],
'min_samples_split': [13],
'min_samples_leaf': [4],
'bootstrap': [True]
},
'xgboost.XGBClassifier': {
'n_estimators': [100],
'max_depth': [6],
'learning_rate': [0.5],
'subsample': [0.9],
'min_child_weight': [20],
'nthread': [1]
},
# Preprocesssors
'sklearn.preprocessing.Binarizer': {
'threshold': np.arange(0.0, 1.01, 0.05)
},
'sklearn.decomposition.FastICA': {
'tol': np.arange(0.0, 1.01, 0.05)
},
'sklearn.cluster.FeatureAgglomeration': {
'linkage': ['ward', 'complete', 'average'],
'affinity': ['euclidean', 'l1', 'l2', 'manhattan', 'cosine', 'precomputed']
},
'sklearn.preprocessing.MaxAbsScaler': {
},
'sklearn.preprocessing.MinMaxScaler': {
},
'sklearn.preprocessing.Normalizer': {
'norm': ['l1', 'l2', 'max']
},
'sklearn.decomposition.PCA': {
'svd_solver': ['randomized'],
'iterated_power': range(1, 11)
},
'sklearn.preprocessing.PolynomialFeatures': {
'degree': [2],
'include_bias': [False],
'interaction_only': [False]
},
'sklearn.kernel_approximation.RBFSampler': {
'gamma': np.arange(0.0, 1.01, 0.05)
},
'sklearn.preprocessing.RobustScaler': {
},
'tpot.built_in_operators.ZeroCount': {
},
# Selectors
'sklearn.feature_selection.SelectFwe': {
'alpha': np.arange(0, 0.05, 0.001),
'score_func': {
'sklearn.feature_selection.f_classif': None
}
},Automated Machine Learning — A Paradigm Shift That Accelerates Data Scientist Productivity @ Airbnb
Questions?


Data science for lazy people... genetics will work for you!
By J. Diego Hueltes Vega
Data science for lazy people... genetics will work for you!
Data science is fun... right? Data cleaning, feature selection, feature preprocessing, feature construction, model selection, parameter optimization, model validation... oh wait... are you sure? What about automating 80% of the work using genetic algorithms that can make better choices than you? TPOT is a tool that automatically creates and optimizes machine learning pipelines.
