Markup, XML and the TEI
James Cummings
@jamescummings
http://slides.com/jamescummings/markup-xml-tei
Thanks as ever to many members of the TEI Community
Markup
(How we tell the computer about text)

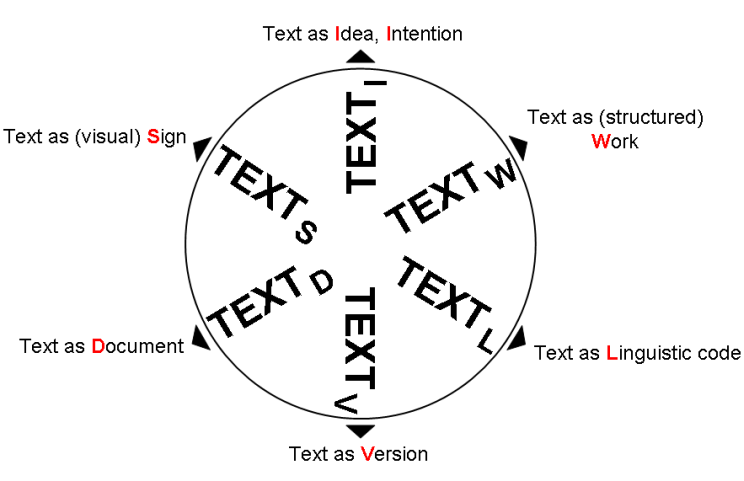
What kind of text? What kind of edition?
Why use markup?
Markup is used in many different fields, for many different purposes: storing data, relating information, encoding understanding, preserving metadata
- Markup is a way of making our knowledge or understanding about a text explicit
- Markup makes strives to make explicit (to a machine) what is implicit (to a person)
- Markup assists us in facilitating re-use of the same material:
- in different formats
- in different contexts
- by different sorts of users
A History of Digital Markup
Procedural Markup:
RED INK ON; print "-£1000"; RED INK OFF
Presentational Markup:
\textcolor{red}{-£1000}
Descriptive Markup:
<
measure
unit="
pounds"
value="
-1000">
One thousand pounds in debt
</
measure>
Descriptive Markup
- It is usually more useful to mark up what we think things represent (in a source text, in our understanding of the data, etc.) rather than what they look like.
- Using descriptive markup enables us to make explicit the distinctions we want to make when processing a string of characters
- It gives us a way of naming, characterising, and annotating textual data in a formalised way and recording this for re-use
- Also called 'Encoding' or 'Annotation'
Descriptive Markup
- Presentational markup cares more about fonts and layout than meaning
- Descriptive markup says what things are, and leaves the rendition or processing of them for a separate step
- Separating the form of something from its content makes its re-use more flexible
- It also allows easy changes of presentation across a large number of documents
Why do we use italic fonts?
Think about the uses for an italic font in any form of printed publication. Why might an author/publisher put some text into italics? What are they signalling about that text?
We can usually tell these types of things apart from context. If we want to use these categories, computers need to be told these things are different.
Some common uses include:
- titles
- emphasis
- foreign phrases
- technical terms
- editorial apparatus, captions, cross references
- quotations, speaker labels in drama
- speech and thought
... and many more


Compare the Markup
<hi rend="dropcap">H</hi>
<g ref="#wynn">W</g>ÆT WE GARDE
<lb/>na in gear-dagum þeod-cyninga
<lb/>þrym gefrunon, hu ða æþelingas
<lb/>ellen fremedon. oft scyld scefing sceaþe<add>na</add>
<lb/>þreatum, moneg<expan>um</expan> mægþum meodo-setl<add>a</add>
<lb/>of<damage><desc>blot</desc></damage>teah ...<lg>
<l>Hwæt! we Gar-dena in gear-dagum</l>
<l>þeod-cyninga þrym gefrunon,</l>
<l>hu ða æþelingas ellen fremedon,</l>
</lg>
<lg>
<l>Oft Scyld Scefing sceaþena þreatum,</l>
<l>monegum mægþum meodo-setla ofteah;</l>
<l>egsode Eorle, syððan ærest wearþ</l>
<l>feasceaft funden...</l>
</lg>
What Should We Mark Up?

XML
(A language for marking up texts)
About XML
XML is structured data represented as strings of text
XML looks like HTML, except that:
- XML is extensible
- XML must be well-formed
- XML can be validated
- XML is application-, platform-, and vendor- independent
- XML empowers the content provider and facilitates data integration and migration
- It is one of the best plain text long-term preservation formats for textual data that we have
About XML
<element> Text </element>
<element attribute="value">
Text or child elements here
</element>
<element attribute="value"/>
"Opening Tag"
"Closing Tag"
"Empty Element"
About XML
<?xml version="1.0" ?>
<root xmlns="http://namespace/">
<element attribute="value">
content
<childElement type="empty"/>
content
</element>
<!-- comment -->
</root><?xml version="1.0" encoding="utf-8" ?>
<div n="1">
<head>SCENE I. On a ship at sea: a
tempestuous noise of thunder and lightning heard.</head>
<stage>Enter a Master and a Boatswain</stage>
<sp>
<speaker>Master</speaker>
<ab>Boatswain!</ab>
</sp>
<sp>
<speaker>Boatswain</speaker>
<ab>Here, master: what cheer?</ab>
</sp>
<sp>
<speaker>Master</speaker>
<ab>Good, speak to the mariners: fall to't, yarely,</ab>
<ab>or we run ourselves aground: bestir, bestir.</ab>
</sp>
<stage>Exit</stage>
</div>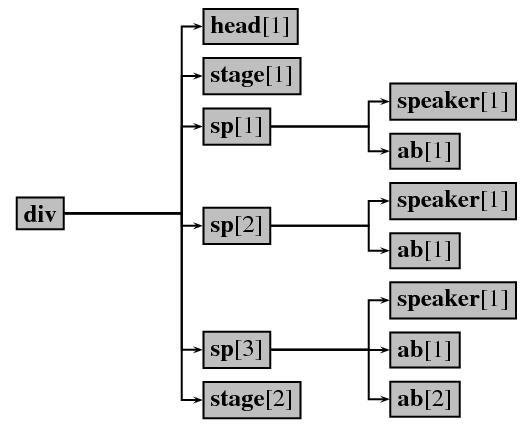
More About XML
- An XML document is encoded as a linear string of characters
- It begins with a special processing instruction
- Element occurrences are marked by start and end-tags
- The characters < and & are Magic and must always be "escaped" using < or & if you want to use them as themselves
- Comments are delimited by <!-- and -->
- Attribute name/value pairs are supplied on the start-tag and may be given in any order
- There are special attributes in the XML namespace like xml:id and xml:lang
- Attribute values are always quoted
- Everything is case-sensitive
Being Well-Formed
- There is a single root node containing the whole of an XML document
- Each subtree is properly nested within the root node
- Element/attribute names and values are always case sensitive
- Start-tags and end-tags are always mandatory (except there are combined start-and-end tags called 'empty elements' like <pb/> <gap/>)
- Attribute values are always quoted
You can also be 'valid' which means you obey additional rules about elements and attributes and where they can go.
XML Test
- <seg>some text</seg>
-
<seg> <w>some</w> <hi>text</hi> </seg>
- <seg> <w>some <hi></w> text</hi> </seg>
- <seg type="text">some text</seg>
- <seg type=text>some text</seg>
- <seg type="text"> some text <seg/>
- <seg type="text"> some text<gap/> </seg>
- <seg type="text">some text</Seg>


TEI
(A markup vocabulary for digital texts)
The TEI (The Text Encoding Initiative) is:
- An international consortium of institutions, projects and individual members
- A community of users and volunteers
- A freely available manual of set of regularly maintained and updated recommendations: 'The Guidelines' with definitions, examples, and discussion of over 560 markup distinctions
- A mechanism for producing customized schemas for validating your project's digital texts
- A set of free and openly licensed, customizable tools and stylesheets for transformations to many formats (e.g. HTML, Word, PDF, Databases, RDF/LinkedData, Slides, ePub, etc.)
- A simple consensus-based way of organizing and structuring textual (and other) resources
- An archival, well-understood, format for long-term preservation of digital data and metadata
- Whatever you make it! It is a community-driven standard


TEI Scope
(What kinds of texts is the TEI good for?)
What Kinds of Documents Can The TEI Cope With?
The TEI takes a generalistic approach to overall text structure and this means it should be able to cope with texts of any size, language, date, complexity, writing system, or media.
This could be in any form: books, journals, manuscripts, postcards, letters, rolls of papyrus, clay tablets, web pages, gravestones, etc. and contain any type of text.

Punch Magazine: a variety of content forms

Holinshed's Chronicles: columns, marginal notes, woodcuts

First Folio:
forme-work, catchwords, decorative initials, etc.


Wilfred Owen: manuscripts, corrections, multiple versions

George Herbert: Graphic text layout, poetry

William Godwin's Diary: diary structure, abbreviated texts


Wilfred Owen: Letters, codewords

Print and Digital Dictionaries: entries, sense, etymologies, quotations, etc.

Epigraphical Texts: partial letters, supplied text, physical description


WW1 Propaganda: font, colour, glyph substitution, image classification and metadata


Various writing systems: Unicode/non-Unicode characters, right-to-left, reversing lines, etc.


English Civil War Petitions: handwritten petitions, formal legal aspects, boilerplate
A Mental Exercise
Thinking about this material, and indeed your own, what do you think are the things you would like to mark up?
- Make a list of textual phenomena and metadata that are important to capture
- How likely is it that you can mark these up reliably and consistently?
- Could any of these potentially be marked up automatically by a cleverly crafted script?
Pretend an authoritarian anti-intellectual government has come to power and, through a series of bad decisions, has to slash your project funding by 50%. What do you do?
- Do you do half the amount of material in the same depth?
- Markup less?
- Invest in more semi-automatic markup?
- Something else?
Repeat the exercise.
An Introduction to XML, Markup and the TEI
By James Cummings
An Introduction to XML, Markup and the TEI
A workshop presentation on the Markup, XML, and the TEI



