De techniek achter
Open Data
Joost Cassee
Haagse Hogeschool, 21 september 2015
@jcassee
jcassee.com
joost@cassee.net
Van data naar informatie
Nieuwsartikelen van AT5 met geotag
gecombineerd met wijkgrenzen
geanalyseerd op sentiment
door eerst naar het Engels te vertalen
geeft een maat voor de toon van de berichtgeving per wijk
die je zou kunnen vergelijken met de criminaliteitscijfers
Open data is ...
Ruw
Vuil
Processing pipeline
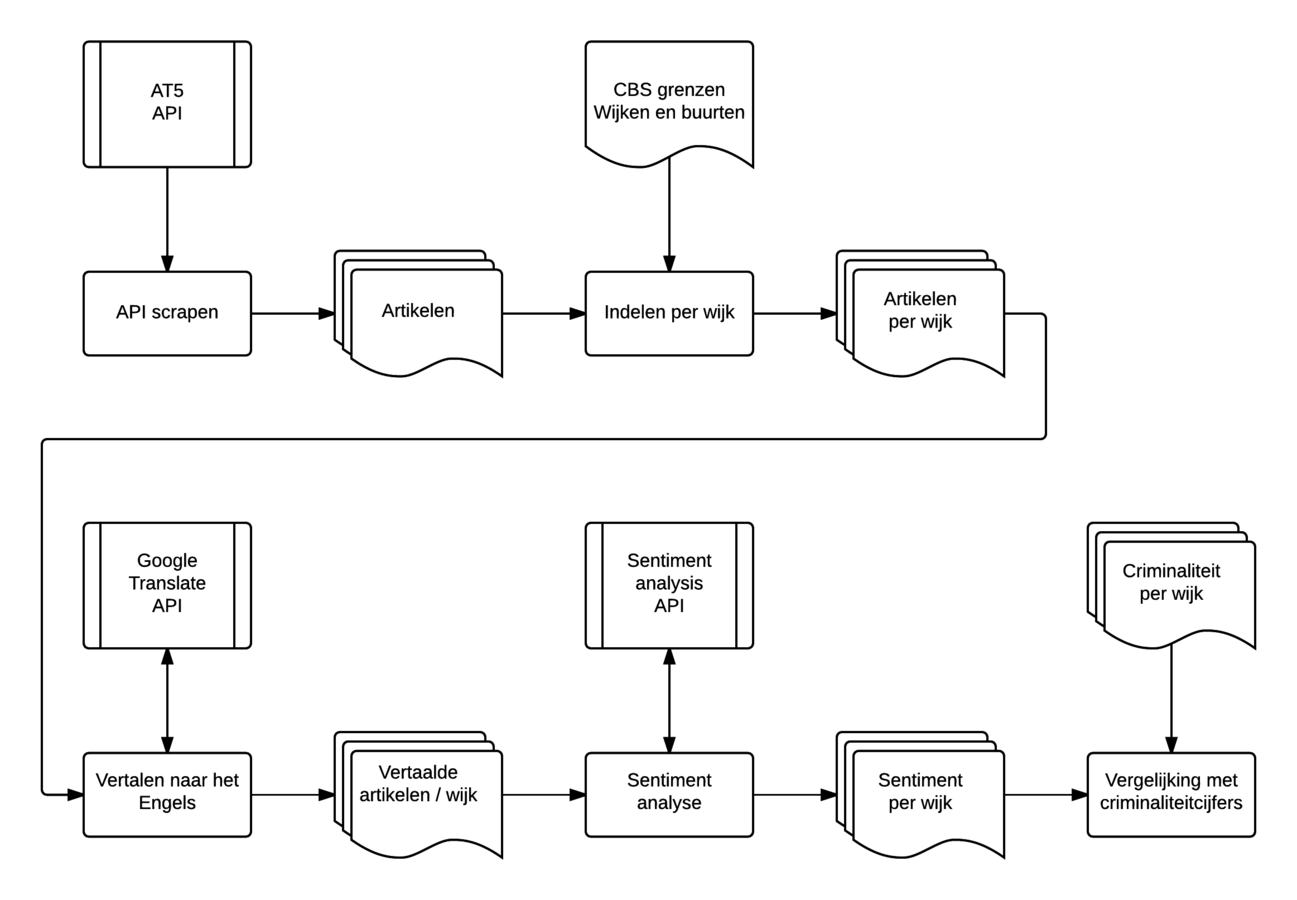
Voorbeeldproces
- Laad de CBS data "Grenzen wijken en buurten" in
- Maak voor iedere wijk een submap aan in de uitvoermap
(noem deze naar het wijknummer in de CBS data) - Voor alle bestanden (artikelen) uit de invoermap:
- Bepaal in welke wijk de gebeurtenis plaatsvond
- Schrijf het artikel weg naar de juiste submap
(gebruik dezelfde bestandsnaam als de invoer)
Indelen per wijk
Tips
- Resultaat tussenstappen opslaan
- Idempotente operaties
- Stabiele identifiers
Tools
Simpel
- Filesystem / MongoDB / CouchDB
- Python
Enterprisy
- Apache Camel
- Java
Big data
- Apache Storm

Verfijnen van informatie
Groeperen op het land van de aanbesteder:
Er zijn veel minder aanbestedingen in Frankrijk dan je zou verwachten?
... en gegunde:
Vooral Duitse bedrijven winnen Griekse aanbestedingen?
... en groepeer onder moederbedrijf:
Philips gebruikt bij aanbestedingen lokale dochterbedrijven?
White board
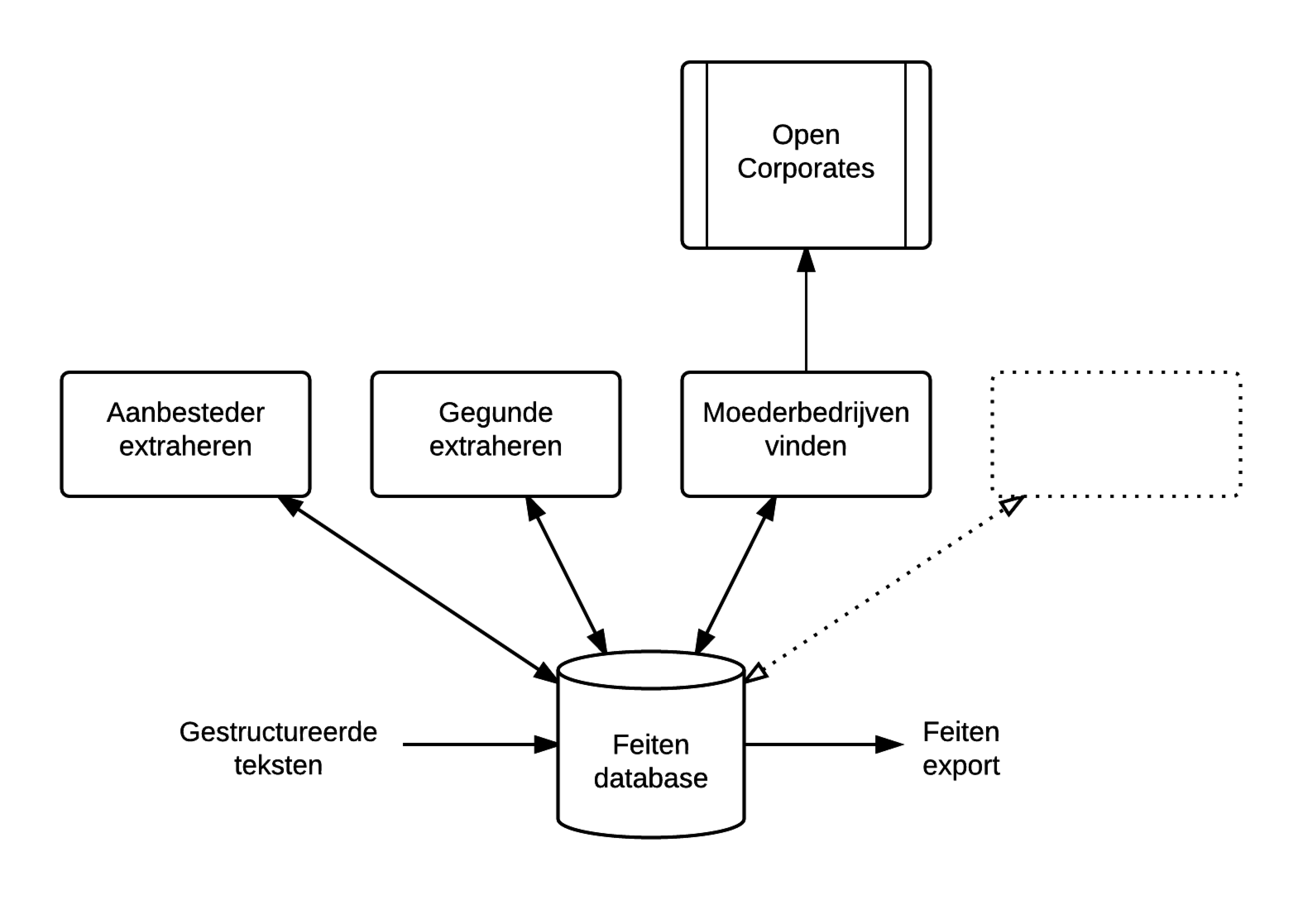
Voorbeeldproces
Voor alle documenten met een gegunde
(die niet zijn verwerkt door dit proces):
- Zoek de moederbedrijven in OpenCorporate
- Sla de moederbedrijven op in het document
- Markeer het document als verwerkt door dit proces
Moederbedrijven vinden
Tips
- Onafhankelijke processen
- Idempotente operaties
- Stabiele identifiers
- "Audit trail" voor feiten
Tools
Simpel
- MongoDB / CouchDB
- Python
Enterprisy
- RDF triplestore
- SPARQL
Big data
- Hadoop
- Mapreduce
Architectuur OpenTED
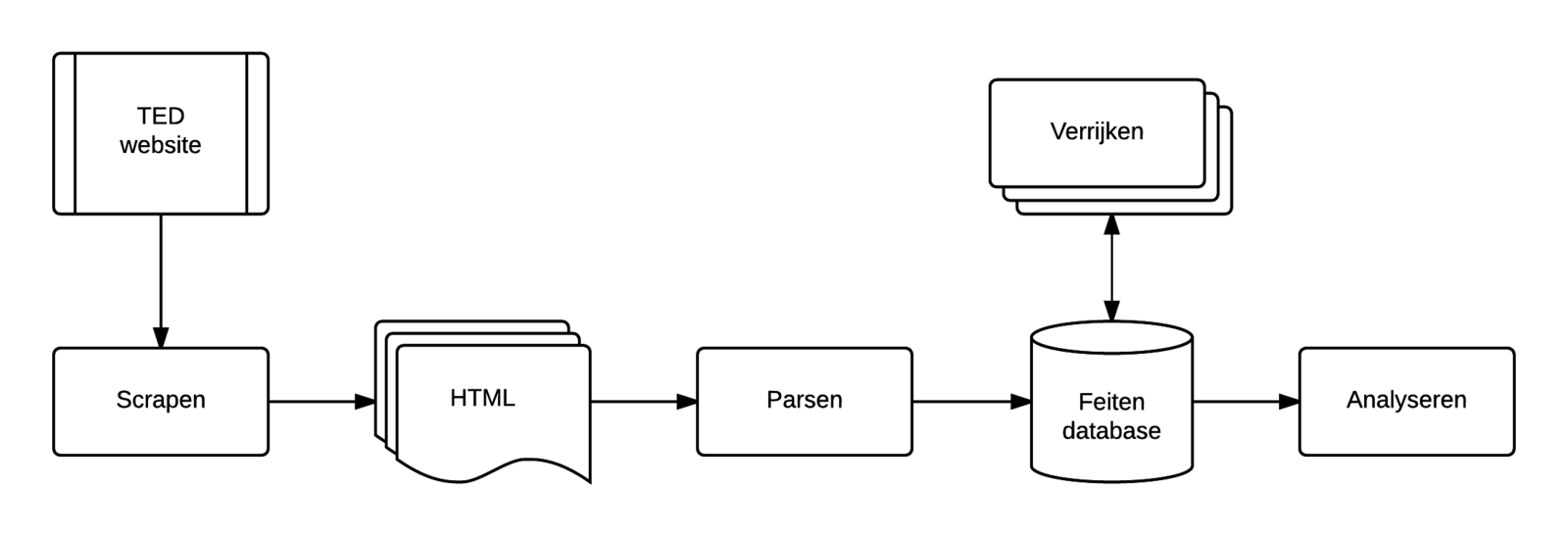
Processing pipeline
White board
Samenvatting
Open data is ruw en vuil
Gebruik een processing pipeline en/of white board architectuur om het schoon en relevant te maken
De techniek achter open data
By Joost Cassee
De techniek achter open data
Gastcollege gegeven op 21 september 2015 voor de Open Data Course van de Haagse Hogeschool.



