Diseño de Bases de Datos Relacionales y Lenguaje SQL

José manuel ruiz pérez
Ingeniería en Sistemas Computacionales
9 años de experiencia laboral
Actualmente dirijo proyectos de software
(Pepe, jose, manuel)
(itc)


OFERTA COMERCIAL

OBJETIVOs
Diseñar correctamente una base de datos relacional
Conocer lo que es una base de datos
Modelar datos en base a una problematica
Realizar las 4 acciones principales de un recurso de datos (Listar, Crear, Actualizar, Eliminar)
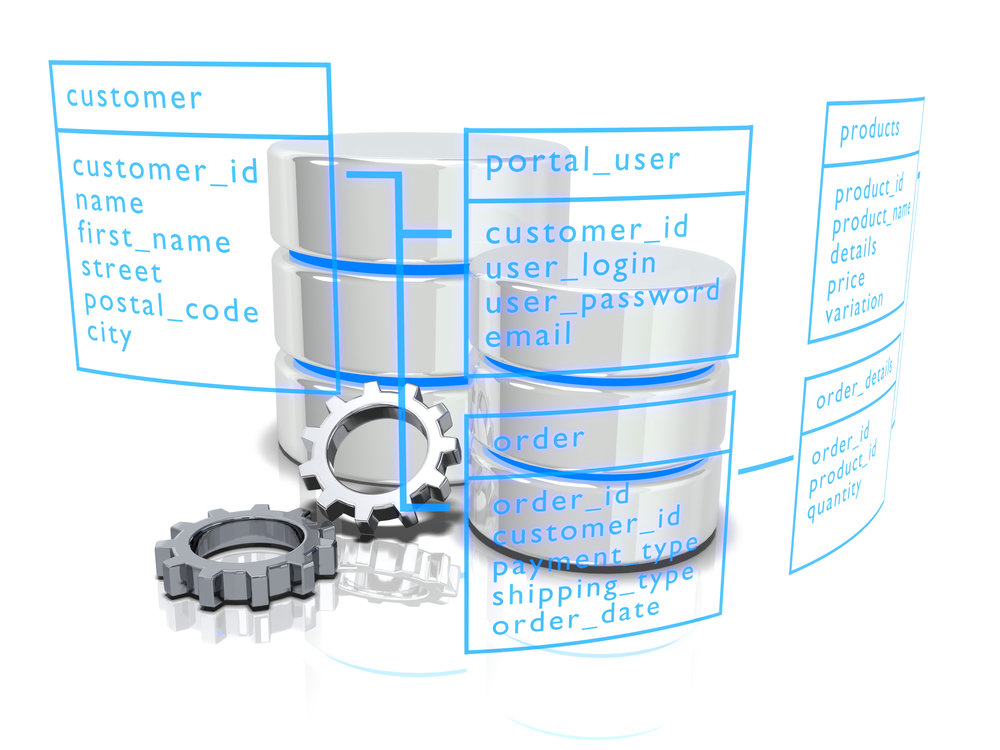
¿Qué es una base de datos?
Se define como una serie de datos organizados y relacionados entre sí, los cuales son recolectados y explotados por los sistemas de información de una empresa o negocio en particular.
¿Qué es un dato?
Un dato es una representación simbólica (numérica, alfabética, algorítmica, espacial, etc.) de un atributo o variable cuantitativa o cualitativa
¿Qué es un metadato?
Los metadatos consisten en información que caracteriza datos, describen el contenido, calidad, condiciones, historia, disponibilidad y otras características de los datos.
(DESCRIPTIVOS, ESTRUCTURALES)
¿Qué es unA ENTIDAD?
Es una grupo de atributos al que se le otorga un contexto para darle sentido a los valores registrados
Un atributo de una entidad es un dato
ENTIDAD => tabla
atributo => encabezado
dato => valor de un atributo
¿Qué es un sgbd?
Es un conjunto de programas (DDL, DML, DCL) que permiten el almacenamiento, modificación y extracción de la información en una base de datos.
(SISTEMA GESTOR DE BASE DE DATOS)
LENGUAJE DE DEFINICIÓN DE DATOS (DDL)
Es un lenguaje de programación para definir estructuras de datos, proporcionado por los sistemas gestores de bases de datos.
(CREATE, ALTER, DROP)
Lenguaje de Manipulación de Datos (DML)
Utilizando instrucciones de SQL, permite a los usuarios introducir datos para posteriormente realizar tareas de consultas o modificación de los datos que contienen las Bases de Datos.
(INSERT, UPDATE, SELECT, DELETE)
Lenguaje de Control de Datos (DCL)
Es un lenguaje que incluye una serie de comandos SQL que permiten controlar el acceso a los objetos, es decir, podemos otorgar o denegar permisos a uno o más roles para realizar determinadas tareas.
(GRANT, REVOKE)
¿Qué es SQL?
Es un tipo de lenguaje de programación que ayuda a solucionar problemas específicos o relacionados con la definición, manipulación e integridad de la información representada por los datos almacenados.
Integra conceptos de cálculo y álgebra relacional
(Structured query language)
CREATE DATABASE curso_db;CREATE TABLE `curso_db`.`clientes` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB CHARSET=utf8mb4 COLLATE=utf8mb4_general_ciALTER TABLE `curso_db`.`clientes`
CHANGE COLUMN `id` `id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
ADD COLUMN `nombre` VARCHAR(100) NOT NULL AFTER `id`,
ADD COLUMN `notas` TEXT NULL AFTER `nombre`SELECT * FROM clientesGRANT ALL ON curso_db.* TO 'usuario'@'localhost'
IDENTIFIED BY 'contra';¿Qué es un modelo de datos?
Es un tipo de modelo de datos que determina la estructura lógica de una base de datos y de manera fundamental determina el modo de almacenar, organizar y manipular los datos
(jerarquico, red, relacional...)
análisis de requerimientos
Una base de datos es tan buena como lo es su modelado de datos, es decir, requiere de un análisis profundo sobre la aplicación que tendrá, los actores y acciones involucradas así como la implementación de reglas de negocio.
EJERCICIO
Se necesita modelar la información para unas conferencias.
Es necesario tener un registro de las conferencias y sus ponentes, así como los asistentes a cada conferencia
identificar: entidades y atributos
EJERCICIO
Se necesita modelar la información para una tienda que necesita mantener un registro de sus ventas
Demos saber: ¿quién realizo la venta?, ¿cuántos productos se vendieron?, ¿cuánto se vendió por día?, ¿qué vendedor vendió mas?, ¿qué producto fue el mas vendido?, ¿quién fue el mejor cliente?
identificar: entidades y atributos
EJERCICIO
Se necesita modelar la información para un hospital, el cual necesita llevar un registro detallado de los doctores agrupados por especialidad, de los pacientes agrupados según el área de atención (especialidad del doctor), un listado de las enfermedades que tiene el paciente y un histórico de las citas junto al doctor que atendió y su diagnostico
identificar: entidades y atributos
¡Gracias!
jmanuel@apdevs.com
José Manuel Ruiz Pérez
MODELOS DE BASES DE DATOS
archivos planos
MODELO JERARQUICO
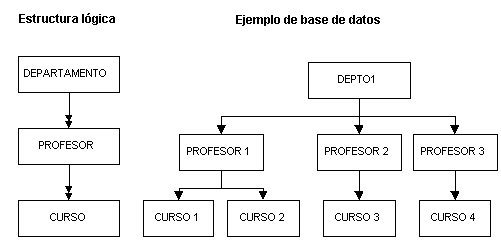
Un modelo de datos jerárquico es un modelo de datos en el cual los datos son organizados en una estructura parecida a un árbol. La estructura permite a la información que se repite y usa relaciones padre/Hijo: cada padre puede tener muchos hijos pero cada hijo sólo tiene un padre.
MODELO DE RED

Este es un modelo de bases de datos ligeramente distinto del jerárquico. Su diferencia fundamental es la modificación del concepto de un nodo, permitiendo que un mismo nodo tenga varios padres (algo no permitido en el modelo jerárquico).
MODELO RELACIONAL

Modelo de organización y gestión de bases de datos consistente en el almacenamiento de datos en tablas compuestas por filas, o tuplas, y columnas o campos. Se distingue de otros modelos, como el jerárquico, por ser más comprensible y por basarse en la teoría de conjuntos para establecer relaciones entre distintos datos.
RELACIONES
UNO A MUCHOS
En una relación de uno a muchos, un registro de una tabla se puede asociar a uno o varios registros de otra tabla
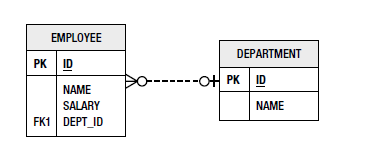
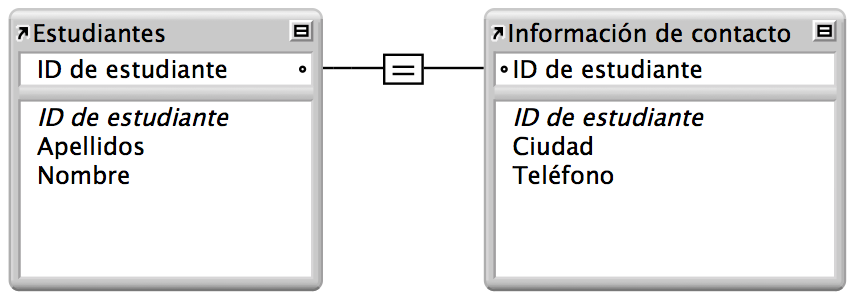
UNO A uno
En una relación de uno a uno, un registro de una tabla se asocia a uno y solo un registro de otra tabla
muchos a muchos
Una relación de muchos a muchos se produce cuando varios registros de una tabla se asocian a varios registros de otra tabla

Por lo general, los sistemas de bases de datos relacionales no permiten implementar una relación directa de muchos a muchos entre dos tablas
autounion
Una relación de autounión (o autounión) es una relación en la que los dos campos de coincidencia se definen en la misma tabla
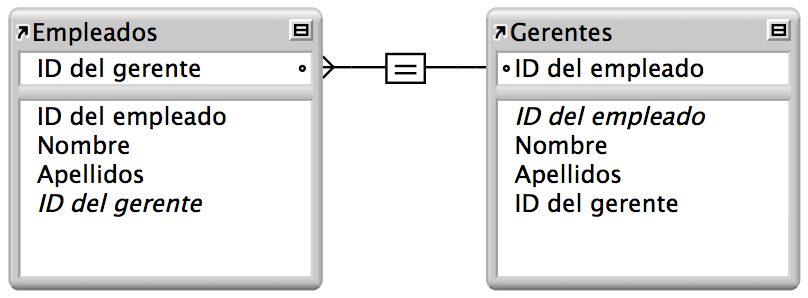
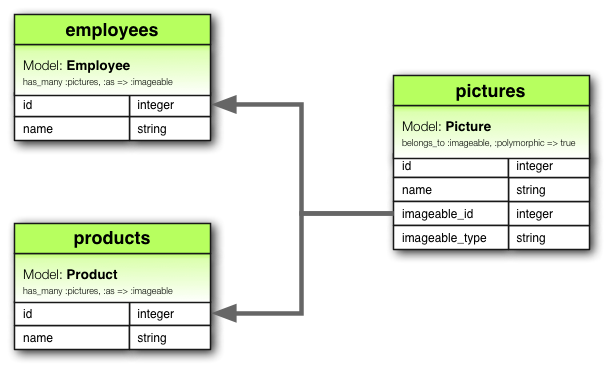
polimórfica
Es una forma de relacionar muchas tablas con una sola mediante una única relación
NO hay un Manejador de Bases de Datos Relacionales que tenga un una restricción de integridad referencial para las relaciones polimórficas
metadatos estructurales
numericos
- INT (INTEGER): Ocupación de 4 bytes con valores entre -2147483648 y 2147483647 o entre 0 y 4294967295.
- SMALLINT: Ocupación de 2 bytes con valores entre -32768 y 32767 o entre 0 y 65535.
- TINYINT: Ocupación de 1 bytes con valores entre -128 y 127 o entre 0 y 255.
- MEDIUMINT: Ocupación de 3 bytes con valores entre -8388608 y 8388607 o entre 0 y 16777215.
- BIGINT: Ocupación de 8 bytes con valores entre -8388608 y 8388607 o entre 0 y 16777215.
- DECIMAL (NUMERIC): Almacena los números de coma flotante como cadenas o string.
- FLOAT (m,d): Almacena números de coma flotante, donde ‘m’ es el número de dígitos de la parte entera y ‘d’ el número de decimales.
- DOUBLE (REAL): Almacena número de coma flotante con precisión doble. Igual que FLOAT, la diferencia es el rango de valores posibles.
- BIT (BOOL, BOOLEAN): Número entero con valor 0 o 1.
FECHA
- DATE: Válido para almacenar una fecha con año, mes y día, su rango oscila entre ‘1000-01-01′ y ‘9999-12-31′.
- DATETIME: Almacena una fecha (año-mes-día) y una hora (horas-minutos-segundos), su rango oscila entre ‘1000-01-01 00:00:00′ y ‘9999-12-31 23:59:59′.
- TIME: Válido para almacenar una hora (horas-minutos-segundos). Su rango de horas oscila entre -838-59-59 y 838-59-59. El formato almacenado es ‘HH:MM:SS’.
- TIMESTAMP: Almacena una fecha y hora UTC. El rango de valores oscila entre ‘1970-01-01 00:00:01′ y ‘2038-01-19 03:14:07′.
- YEAR: Almacena un año dado con 2 o 4 dígitos de longitud, por defecto son 4. El rango de valores oscila entre 1901 y 2155 con 4 dígitos. Mientras que con 2 dígitos el rango es desde 1970 a 2069 (70-69).
CADENAS DE TEXTO
- CHAR: Ocupación fija cuya longitud comprende de 1 a 255 caracteres.
- VARCHAR: Ocupación variable cuya longitud comprende de 1 a 255 caracteres.
- TINYBLOB: Una longitud máxima de 255 caracteres. Válido para objetos binarios como son un fichero de texto, imágenes, ficheros de audio o vídeo. No distingue entre minúculas y mayúsculas.
- BLOB: Una longitud máxima de 65.535 caracteres. Válido para objetos binarios como son un fichero de texto, imágenes, ficheros de audio o vídeo. No distingue entre minúculas y mayúsculas.
- SET: Almacena 0, uno o varios valores una lista con un máximo de 64 posibles valores.
- ENUM: Igual que SET pero solo puede almacenar un valor.
- TEXT:Una longitud máxima de 65.535 caracteres. Sirve para almecenar texto plano sin formato. Distingue entre minúculas y mayúsculas.
- LONGTEXT: Una longitud máxima de 4.294.967.298 caracteres. Sirve para almecenar texto plano sin formato. Distingue entre minúculas y mayúsculas.
NORMALIZACIóN
PRIMERA FORMA NORMAL
(1NF)
REGLAS
- Atributos atómicos
- No importa el orden de los datos
- No debe haber registros duplicados
- Debe existir una llave primaria
- No debe haber grupos de atributos
SEGUNDA FORMA NORMAL
(2NF)
reglas
- Esta en primera forma normal
- Todos los atributos dependen de la llave primera completa
tercera FORMA NORMAL
(3NF)
REGLAS
- Esta en segunda forma normal
- Ningún atributo no "determinante" depende transitivamente de la llave primaria
¡Gracias!
jmanuel@apdevs.com
José Manuel Ruiz Pérez
sql
(structured query language)
Create / Delete Database
CREATE DATABASE dbNameYouWant
CREATE DATABASE dbNameYouWant CHARACTER SET utf8
DROP DATABASE dbNameYouWant
ALTER DATABASE dbNameYouWant CHARACTER SET utf8Browsing
SHOW DATABASES
SHOW TABLES
SHOW FIELDS FROM table / DESCRIBE table
SHOW CREATE TABLE table
SHOW PROCESSLIST
KILL process_numberINSERT
INSERT INTO table1 (field1, field2, ...)
VALUES (value1, value2, ...)update
UPDATE table1 SET field1=new_value1 WHERE condition
UPDATE table1, table2 SET field1=new_value1, field2=new_value2, ...
WHERE table1.id1 = table2.id2 AND conditioncreate table
CREATE TABLE table (field1 type1, field2 type2, ...)
CREATE TABLE table (field1 type1, field2 type2, ..., INDEX (field))
CREATE TABLE table (field1 type1, field2 type2, ..., PRIMARY KEY (field1))
CREATE TABLE table (field1 type1, field2 type2, ..., PRIMARY KEY (field1,
field2))
CREATE TABLE table1 (fk_field1 type1, field2 type2, ...,
FOREIGN KEY (fk_field1) REFERENCES table2 (t2_fieldA))
[ON UPDATE|ON DELETE] [CASCADE|SET NULL]
CREATE TABLE table1 (fk_field1 type1, fk_field2 type2, ...,
FOREIGN KEY (fk_field1, fk_field2) REFERENCES table2 (t2_fieldA, t2_fieldB))
CREATE TABLE table IF NOT EXISTS (...)update table
ALTER TABLE table MODIFY field1 type1
ALTER TABLE table MODIFY field1 type1 NOT NULL ...
ALTER TABLE table CHANGE old_name_field1 new_name_field1 type1
ALTER TABLE table CHANGE old_name_field1 new_name_field1 type1 NOT NULL ...
ALTER TABLE table ALTER field1 SET DEFAULT ...
ALTER TABLE table ALTER field1 DROP DEFAULT
ALTER TABLE table ADD new_name_field1 type1
ALTER TABLE table ADD new_name_field1 type1 FIRST
ALTER TABLE table ADD new_name_field1 type1 AFTER another_field
ALTER TABLE table DROP field1
ALTER TABLE table ADD INDEX (field);DELETE
DELETE FROM table1 / TRUNCATE table1
DELETE FROM table1 WHERE condition
DELETE FROM table1, table2 FROM table1, table2
WHERE table1.id1 = table2.id2 AND conditionSELECT
SELECT * FROM table
SELECT * FROM table1, table2, ...
SELECT field1, field2, ... FROM table1, table2, ...
SELECT ... FROM ... WHERE condition
SELECT ... FROM ... WHERE condition GROUPBY field
SELECT ... FROM ... WHERE condition GROUPBY field HAVING condition2
SELECT ... FROM ... WHERE condition ORDER BY field1, field2
SELECT ... FROM ... WHERE condition ORDER BY field1, field2 DESC
SELECT ... FROM ... WHERE condition LIMIT 10
SELECT DISTINCT field1 FROM ...
SELECT DISTINCT field1, field2 FROM ...condicionales
field1 = value1
field1 <> value1
field1 LIKE 'value _ %'
field1 IS NULL
field1 IS NOT NULL
field1 IS IN (value1, value2)
field1 IS NOT IN (value1, value2)
condition1 AND condition2
condition1 OR condition2FUNCIONES AGREGADAS
AVG() Return the average value of the argument
BIT_AND() Return bitwise AND
BIT_OR() Return bitwise OR
BIT_XOR() Return bitwise XOR
COUNT() Return a count of the number of rows returned
COUNT(DISTINCT) Return the count of a number of different values
GROUP_CONCAT() Return a concatenated string
JSON_ARRAYAGG() Return result set as a single JSON array
JSON_OBJECTAGG()Return result set as a single JSON object
MAX() Return the maximum value
MIN() Return the minimum value
STD() Return the population standard deviation
STDDEV() Return the population standard deviation
STDDEV_POP() Return the population standard deviation
STDDEV_SAMP() Return the sample standard deviation
SUM() Return the sum
VAR_POP() Return the population standard variance
VAR_SAMP() Return the sample variance
VARIANCE() Return the population standard varianceSELECT - JOIN
SELECT ... FROM t1 JOIN t2 ON t1.id1 = t2.id2 WHERE condition
SELECT ... FROM t1 LEFT JOIN t2 ON t1.id1 = t2.id2 WHERE condition
SELECT ... FROM t1 JOIN (t2 JOIN t3 ON ...) ON ...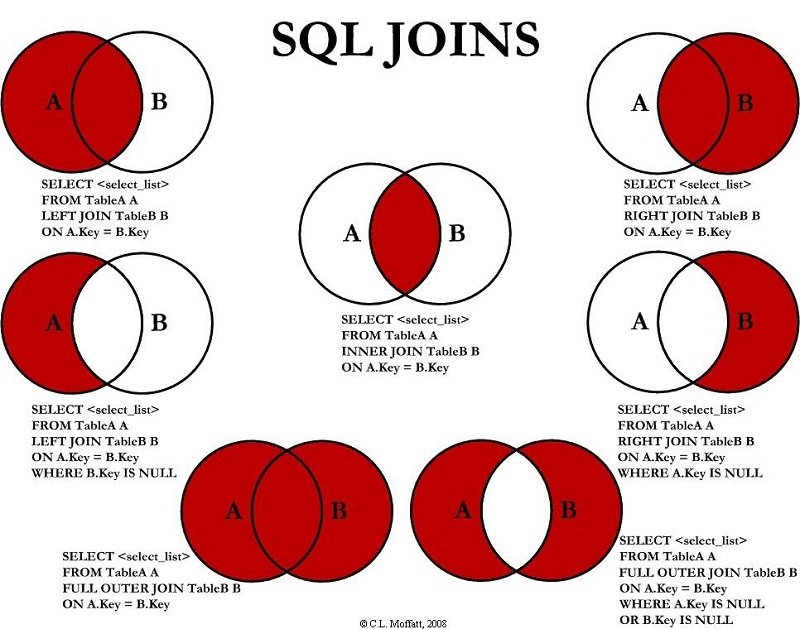
ejercicios
LISTAR LOS CLIENTES CON SU TOTAL DE VENTA
SELECT
clientes.nombre as Cliente,
SUM(ventas.total) as Venta
FROM clientes
JOIN ventas ON clientes.id = ventas.cliente_id
GROUP BY clientes.id
ORDER BY nombre;
LISTAR LOS CLIENTES CON SU TOTAL DE VENTA y con su venta maxima (El total mas alto del cliente)
SELECT
clientes.nombre as Cliente,
SUM(ventas.total) as Venta,
MAX(ventas.total) as VentaMaxima
FROM clientes
JOIN ventas ON clientes.id = ventas.cliente_id
WHERE ventas.estatus = 'pagada'
GROUP BY clientes.id
ORDER BY VentaMaxima DESC;
LISTAR LOS CLIENTES CON SU TOTAL DE VENTA, solo de las ventas del 2019
SELECT
clientes.nombre as Cliente,
SUM(ventas.total) as Venta,
MAX(ventas.total) as VentaMaxima
FROM clientes
JOIN ventas ON clientes.id = ventas.cliente_id
WHERE (ventas.fecha BETWEEN '2019-01-01' AND '2019-12-31')
AND ventas.estatus = 'pagada'
GROUP BY clientes.id
ORDER BY VentaMaxima DESC;
OBTENER LOS CLIENTES QUE SE LES DEJO DE VENDER, ORDENADO DESDE EL MAS VIEJO Y LIMITADO A 10
SELECT
clientes.nombre AS Cliente,
MAX(ventas.fecha) as FechaUltimaVenta
FROM clientes
INNER JOIN ventas ON clientes.id = ventas.cliente_id
GROUP BY clientes.id
ORDER BY FechaUltimaVenta
LIMIT 10(Listar nombre y fecha de ultima venta)
LISTAR LOS CLIENTES CON SU TOTAL DE VENTA, solo de la primer ruta
SELECT
clientes.nombre as Cliente,
SUM(ventas.total) as Venta,
MAX(ventas.total) as VentaMaxima
FROM clientes
JOIN ventas ON clientes.id = ventas.cliente_id
JOIN rutas ON ventas.ruta_id = rutas.id
WHERE ventas.ruta_id = 3
AND ventas.estatus = 'pagada'
GROUP BY clientes.id
ORDER BY VentaMaxima DESC;LISTAR LOS CLIENTES QUE NO HAN TENIDO VENTAS
SELECT
clientes.nombre
FROM clientes
LEFT JOIN ventas
ON clientes.id = ventas.cliente_id
WHERE ventas.id IS NULLlistar el total de prospecciones que ha hecho un REPARTIDOR (1)
SELECT
repartidores.nombre,
rutas.nombre,
SUM(prospectos.no_visitas) as TotalVisitas
FROM repartidores
JOIN rutas ON rutas.id = repartidores.ruta_id
JOIN prospectos ON prospectos.ruta_id = rutas.id
GROUP BY repartidores.id
(Repartidor, Ruta, SumaVisitas)
listar el total de prospecciones que ha hecho un REPARTIDOR (2)
SELECT
repartidores.nombre,
SUM(prospectos.no_visitas) as TotalVisitas
FROM repartidores
JOIN prospectos
ON prospectos.ruta_id = repartidores.ruta_id
GROUP BY repartidores.id
(Repartidor, Ruta, SumaVisitas)
LISTAR LOS PRODUCTOS PARA la venta a un cliente
(que esta dentro de una lista de precios)
SELECT
productos.id as Clave,
productos.nombre as Producto,
IF(precios_productos.precio IS NULL,
productos.precio,
precios_productos.precio
) as Precio,
productos.precio as Original,
precios_productos.precio as Preferencial
FROM productos
LEFT JOIN precios_productos
ON precios_productos.producto_id = productos.id
AND precios_productos.lista_id IN (
SELECT lista_id FROM clientes WHERE id=5
)
OR precios_productos.id IS NULL
Probar cliente ID=5 y ID=6
listar los productos que no tienen ningun cambio de precio
(join)
SELECT productos.id, productos.nombre
FROM productos
LEFT JOIN precios_listas
ON productos.id = precios_listas.producto_id
WHERE precios_listas.id IS NULLlistar los productos que no tienen ningun cambio de precio
(sub consulta)
SELECT id, nombre
FROM productos
WHERE id NOT IN (
SELECT producto_id FROM precios_listas
)de mis 3 productos mas vendidos, conocer el total de venta por producto
SELECT producto_id
FROM detalle_venta
GROUP BY producto_id
ORDER BY SUM(cantidad) DESC
LIMIT 3de mis 3 productos mas CAROS, conocer el total de venta por producto
SELECT id
FROM productos
GROUP BY id
ORDER BY precio DESC
LIMIT 3TOTAL DE VENTAS POR RUTA
triggers
CREATE
[DEFINER = user]
TRIGGER trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
[trigger_order]
trigger_body
trigger_time: { BEFORE | AFTER }
trigger_event: { INSERT | UPDATE | DELETE }
trigger_order: { FOLLOWS | PRECEDES } other_trigger_nameActualizar numero de visitas al insertar visita de prospecto
delimiter $$
CREATE TRIGGER update_visits
AFTER INSERT ON visitas
FOR EACH ROW
BEGIN
UPDATE prospectos
SET no_visitas = no_visitas + 1
WHERE id = NEW.prospecto_id;
END;
$$
delimeter ;NO PERMITIR CREAR PRODUCTOS CON PRECIO NEGATIVO
delimiter $$
CREATE TRIGGER realPricesOnProducts
AFTER INSERT ON productos
FOR EACH ROW
BEGIN
IF NEW.precio < 0 THEN
signal sqlstate '45000'
set message_text = 'Product price cannot be less than 0';
END IF;
END;
$$
delimeter ;Diseño de bases de datos relacionales
By JManuel Ruiz
Diseño de bases de datos relacionales
Curso Diseño de bases de datos relacionales y lenguaje SQL




