Fachprojekt:
Reproduzierbare Datenanalyse mit Snakemake am Beispiel der Bioinformatik
Johannes Köster
University of Duisburg-Essen


Data Analysis
Data analysis
dataset
results
Steps:
- aggregation
- transformation
- filtration
- visualization
Via:
- command line tools
- small scripts
Data analysis
dataset
results
dataset
dataset
dataset
dataset
dataset
Data analysis
dataset
results
dataset
dataset
dataset
dataset
dataset
From raw data to final figures:
- document parameters, tools, versions
- execute without manual intervention
automation
Data analysis
dataset
results
dataset
dataset
dataset
dataset
dataset
scalability
Handle parallelization:
execute for tens to thousands of datasets
Avoid redundancy:
- when adding datasets
- when resuming from failures
automation
dataset
results
dataset
dataset
dataset
dataset
dataset
Handle deployment:
be able to easily execute analyses on a different system/platform/infrastructure
portability
scalability
automation
Reproducible data analysis
Bioinformatics
www.copdri.com 2016

Cells
www.austincc.edu 2016
Chromosomes
www.medicalxpress.com 2016
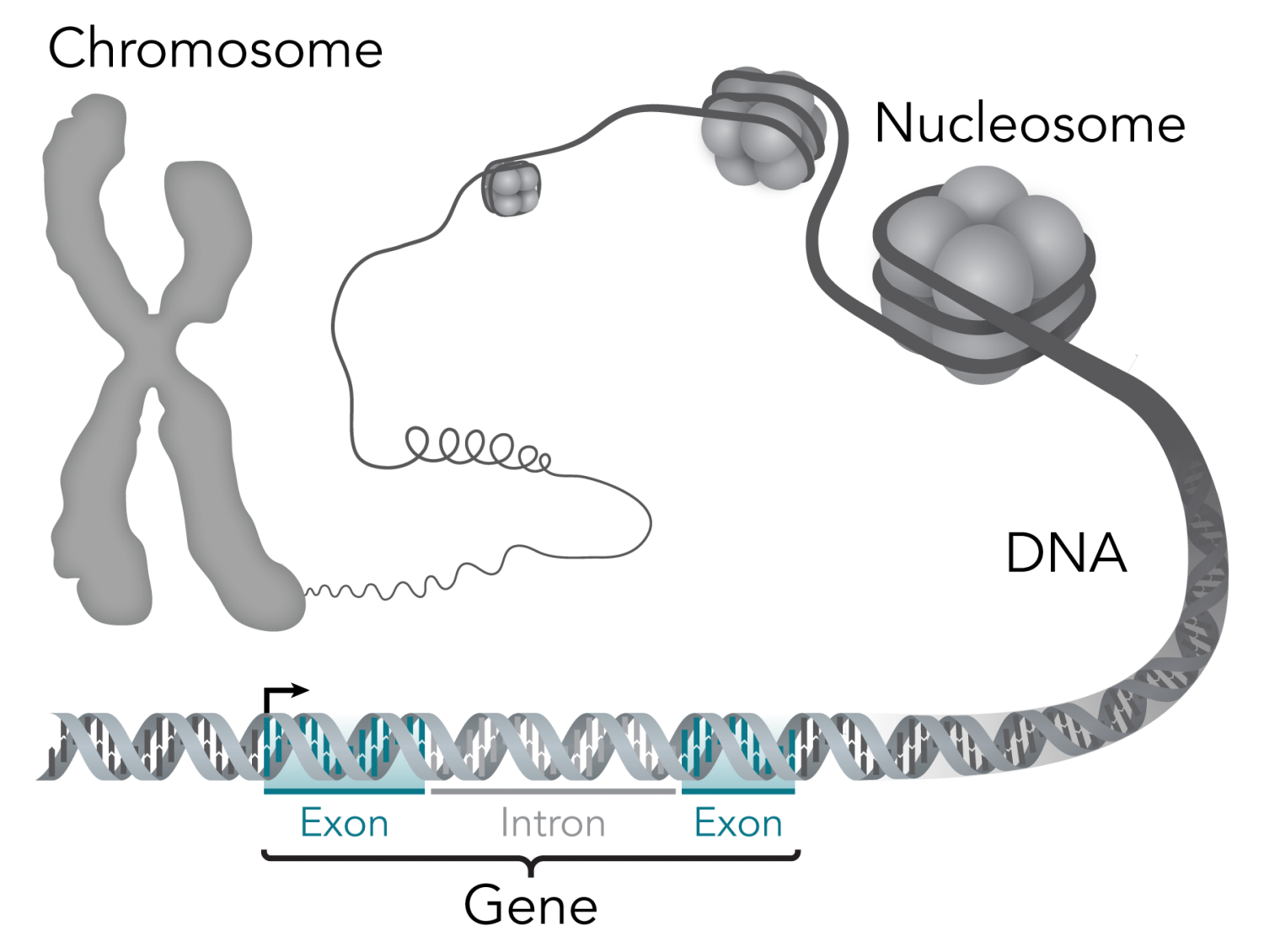
Genes
biosocialmethods.isr.umich.edu 2016
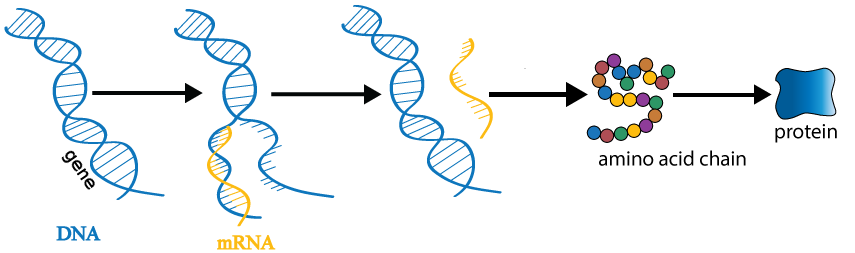
From genes to proteins
Transcript activity/expression:
the more RNA, the more protein
transcript
DNA:
- made of 4 nucleotides: Adenine, Guanine, Cytosine, Thymine
- a text over the alphabet \(\{A, C, G, T \}\)
Questions
- Which mutations does the genome of a patient contain?
- Which transcripts are particularly active/inactive with a certain disease?
- Which bacteria appear in a sample?
- Who is the murder?
Methods
- statistical modelling
- algorithm and data structure engineering
- machine learning
- data analysis
Here: Analysis of RNA-sequencing data

Illumina Inc. 2018
Illumina sequencing
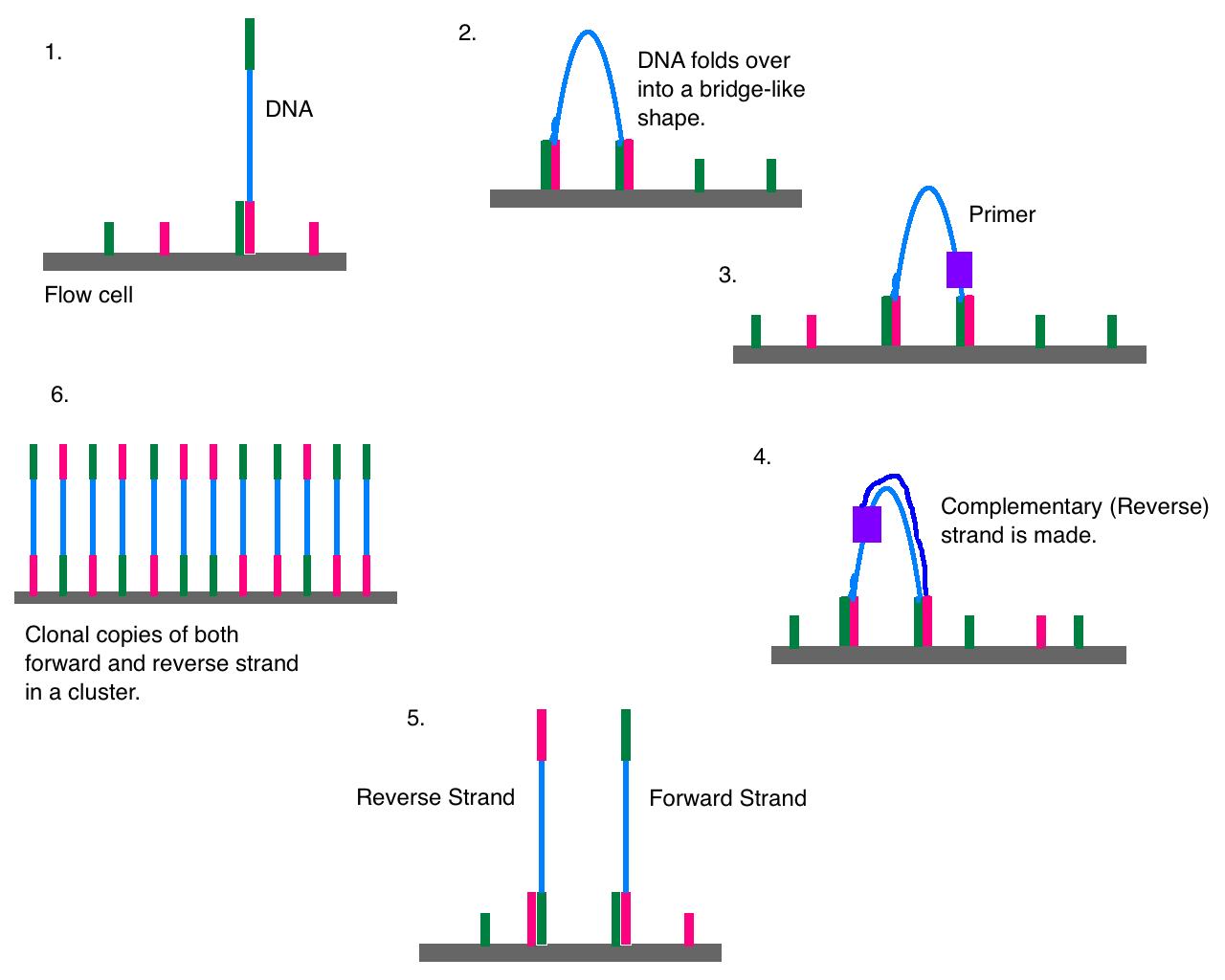
en.wikipedia.org 2018
Illumina sequencing
en.wikipedia.org 2018
Illumina sequencing
en.wikipedia.org 2018
Result:
short, (paired-end) Reads

Transcript quantification with RNA-sequencing
en.wikipedia.org 2018
- obtain many short reads from RNA (50-100 million)
- map them against a reference genome
- quantify transcript expression by counting reads on each transcript
...ACGCTAGCAGCGTAGCGGAGCTATTGCGGAGCTGAGCGTATCGGAGAGATCGGATCTGGATCGAGATCTGAGCTGAGCTAGCTGGCTAGCGATCGGAGGAGCTAGCGATATTCGAGGAGGCGTATCGTAGC...
Gene and transcript sequence
CGGAGCTATTGCGG
GGAGCTATTGCGGA
GGATCGAGATCT
GGATCGAGATCT
CGGAGGAGCTAG
CGGAGGAGCTAG
TCGGAGGAGCTA
Semesterplan
Phase 1
Phase 2
Phase 3
| 11.10.2018 | Einführung, Snakemake-Tutorial |
| 18.10.2018 | Snakemake-Tutorial |
| 25.10.2018 | Snakemake-Tutorial |
| 01.11.2018 | Vorbereitung der Vorträge |
| 08.11.2018 | Vorbereitung der Vorträge |
| 15.11.2018 | Vorträge (je 30min) |
| 22.11.2018 | Implementierung des Workflows |
| 29.11.2018 | Implementierung des Workflows |
| 06.12.2018 | Implementierung des Workflows |
| 13.12.2018 | Implementierung des Workflows |
| 20.12.2018 | Implementierung des Workflows |
| 10.01.2019 | Implementierung des Workflows |
| 17.01.2019 | Implementierung des Workflows |
| 24.01.2019 | Vorbereitung der Abschlusspräsentationen |
| 31.01.2019 | Abschlusspräsentationen |
Phase 4
Fachprojekt: Reproduzierbare Datenanalyse mit Snakemake
By Johannes Köster



