
ElasticSearch est un moteur de recherche open source, développé en Java sous licence Apache2. il possède un atout majeur : il suffit de quelques minutes à peine pour disposer d'un moteur de recherche clusterisé, automatiquement sauvegardé et répliqué, interrogeable via une API REST
ElasticSearch est basé sur l'excellente librairie Apache Lucene (500 000 lignes en JAVA).
Cette librairie existe depuis de nombreuses années et est au cœur de nombreux moteurs de recherche open source (le plus connu étant Apache SolR).
Elle fournit toutes les classes Java nécessaires à l'indexation de documents et à l'exécution des requêtes de recherches.
+ Les recherches par mots clés « à la Google »
+ Les recherches par combinaison de critères et de filtres
+ Le tri et la pagination des résultats, la gestion des synonymes, l'extraction de texte à partir de documents binaires, l'analyse et la navigation par facettes...
+ ElasticSearch dispose en plus de son propre système de plugins.
+ Parmi les plugins existants, on peut trouver des analyseurs syntaxiques, des interfaces d'administrations ou encore des connecteurs pour indexer différentes sources de données (bases de données relationnelles ou NoSQL, annuaire LDAP, système de fichiers, flux RSS etc).
ElasticSearch apporte aussi son lot de fonctionnalités innovantes telles que:
- la percolation, qui permet de pré enregistrer des recherches puis d’injecter en document et d’obtenir en retour la liste des recherches correspondants à ce document
- les rivières (“Rivers”), qui sont des connecteurs permettant d’indexer un flot continu de documents issus de sources de données variées
En quelques mots...
Killers Features
Instantané (snapshot) / restauration
La sauvegarde est facilitée par l'apparition de l'API_snapshot. À noter que les snapshots sont incrémentaux et que le stockage peut être un système de fichier local ou distant : S3, Azure ou encore HDFS.
Aggregations API
Puisque les facets ne permettaient pas le regroupement des documents par type puis par date, l'Aggregations API, introduite dans ElasticSearch 1.0.0, propose deux familles d'agrégateur : regroupement (Bucketing) et calculs (Metric).
Percolation distribuée
La percolation, c'est-à-dire la recherche inversée (la possibilité de rechercher les requêtes correspondant à un document), est maintenant distribuée. Les search snippets, les agrégations et la bulk percolation sont maintenant pris en charge.
API cat
Cette API constitue un ensemble de commandes fournissant des informations lisibles pour un être humain (contrairement au format JSON).
Federated search
Cette nouvelle fonctionnalité permet d'effectuer des requêtes (au sens large) sur plusieurs clusters depuis un nouveau type de nœud tribe se comportant comme nœud client sur tous les clusters enregistrés.
Doc Values
Cette version 1.0.0 introduit une option (à positionner dans le mapping lors de l'indexation), qui permet de stocker la structure fielddata sur disque, une possibilité utile lors des opérations de faceting et de tri impliquant un nombre important de valeurs uniques.
Disjoncteurs
Une fonctionnalité de « disjoncteur » a été mise en place, notamment afin de détecter le chargement d'une trop grande quantité de données de champ dans la mémoire, ce qui risque de causer des exceptions out of memory.
simple_query_string
La syntaxe simple_query_string peut maintenant être utilisée au lieu de la syntaxe query string query, la première étant moins sensible aux erreurs de syntaxe que la seconde.
Vitesse et consommation mémoire
Les performances sont améliorées, de même que la stabilité, et la consommation mémoire est réduite.
Mots vides désactivés par défaut
Les mots vides sont supprimés par défaut grâce à une nouvelle option dans les requêtes match, cutoff_frequency et un nouveau type de requête common.
Clients officiels
Grâce à un jeu de clients officiels maintenus par les développeurs d'Elasticsearch, le moteur de recherche distribué doit être aussi simple à utiliser pour n'importe lequel des langages suivants : JS, Perl, PHP, Python et Ruby.
Dépôt deb et rpm
Par ailleurs, des dépôts deb et rpm ont été mis en place à destination des administrateurs.
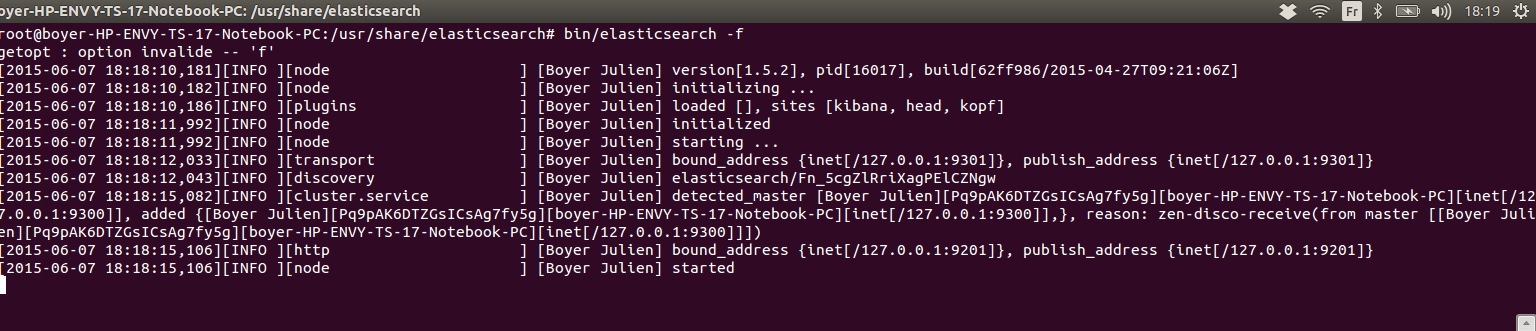
- bin, qui contient le script de lancement elasticsearch et le script d'installation de plugins
- config, qui contient les fichiers de configuration d'ElasticSearch (elasticsearch.yml) et celui des logs (logging.yml)
- lib, qui contient certaines librairies utilisées par ElasticSearch
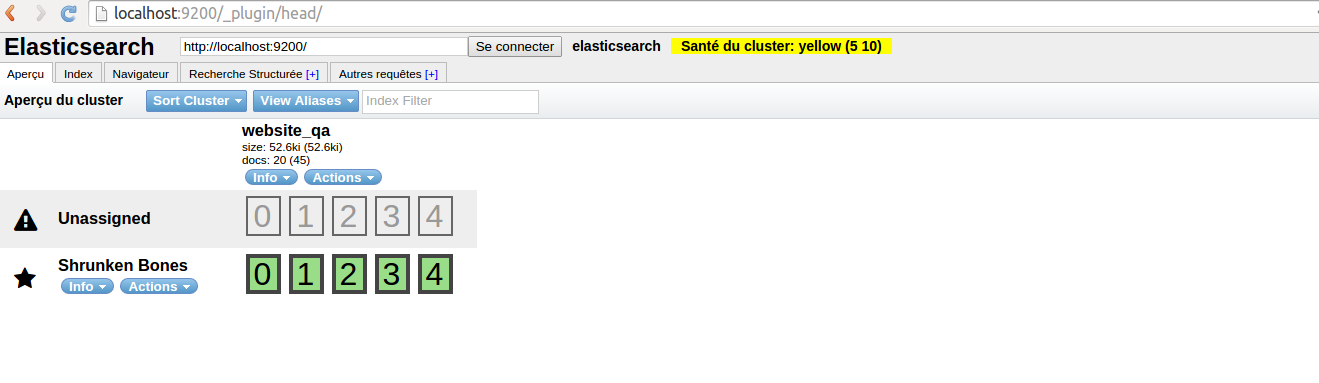
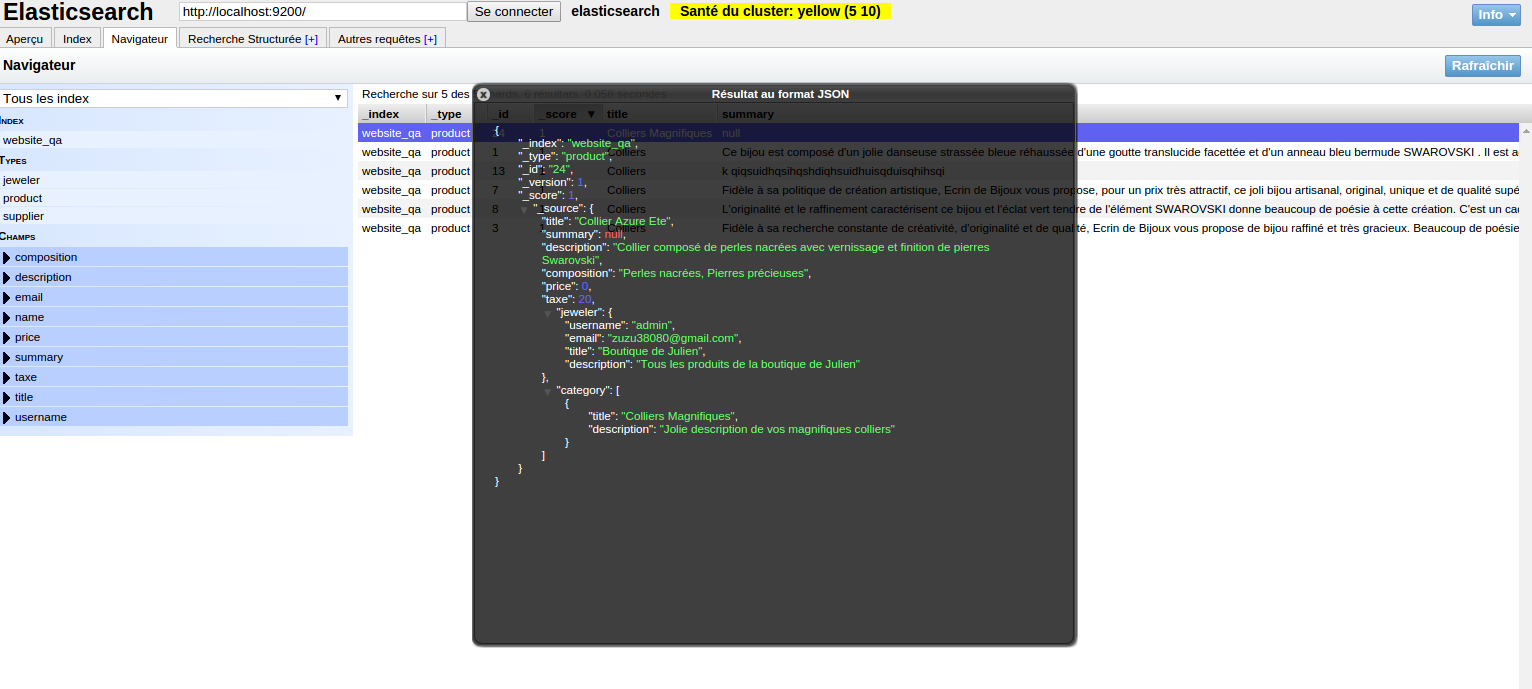
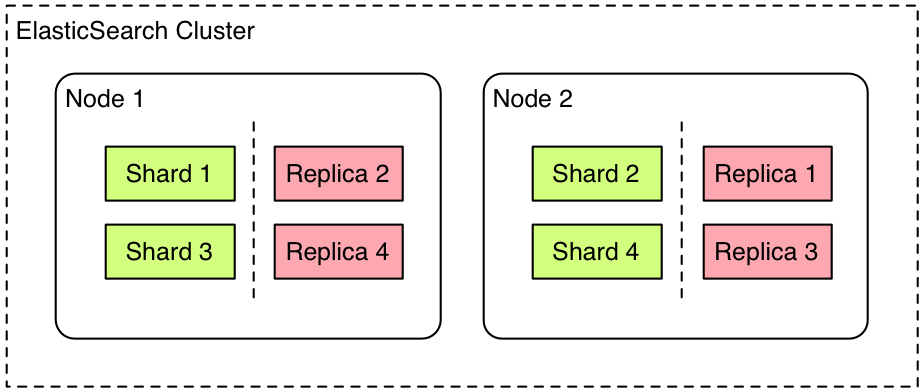
Structure
Une river est un service tournant au sein du cluster Elasticsearch, permettant de tirer ("pull") ou de recevoir ("pushed with data") des données.


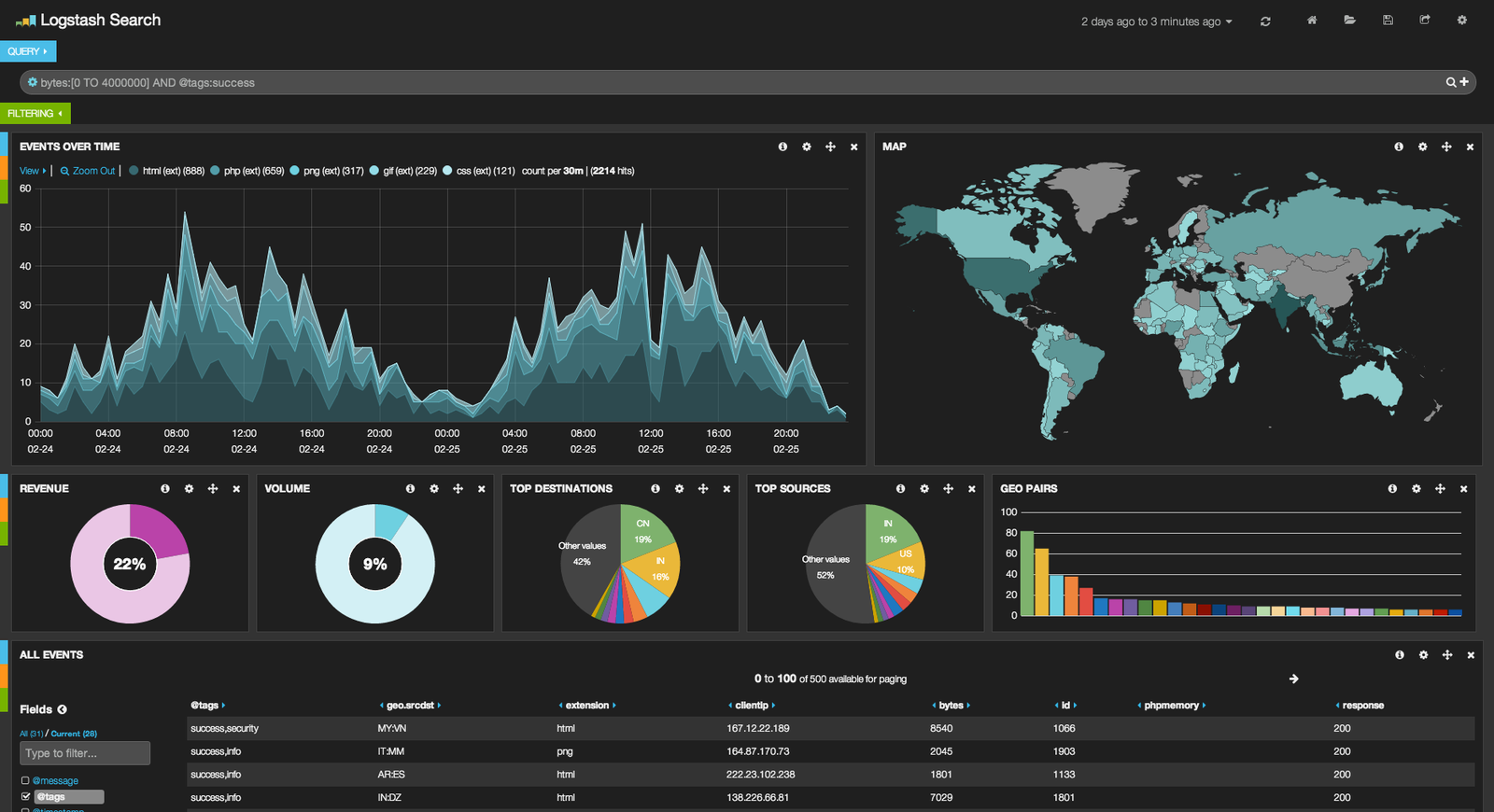
Kibana offre 4 dashboards par défaut :
- un dashboard générique Logstash
- un dashboard générique Elasticsearch
- un dashboard non configuré
- un dashboard vide
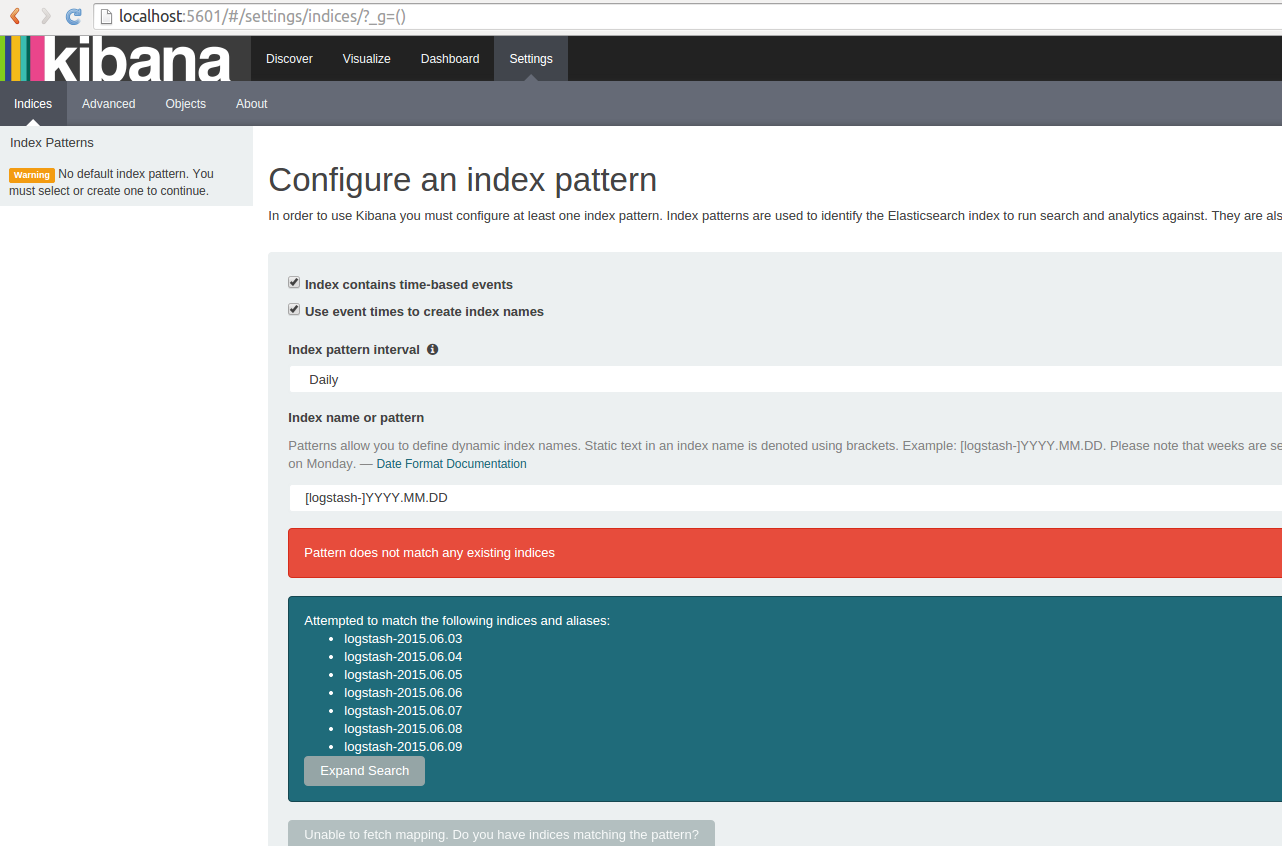
Un dashboard se "branche" sur tous les index de votre cluster Elasticsearch, un index, ou les index dont le nom match un pattern (cas de logstash notamment).
L’interface HTML5 basé sur Twitter Bootstrap se décompose en lignes de 12 colonnes (pliables ou non) contenant des panels.
Il existe plusieurs types de panels à ajouter et configurer (recherche, période de temps, histogramme, camembert, carte, Markdown, …)
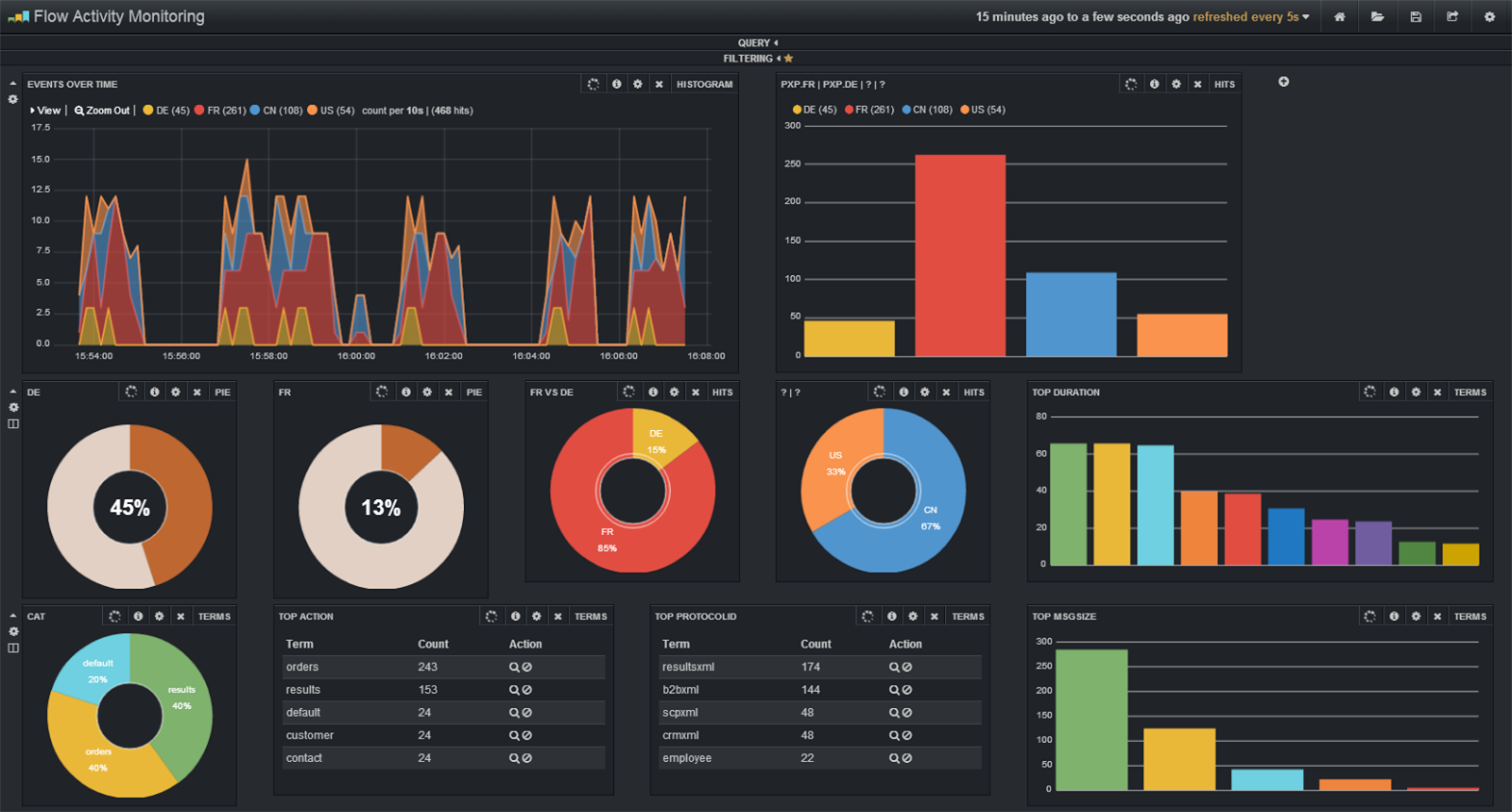

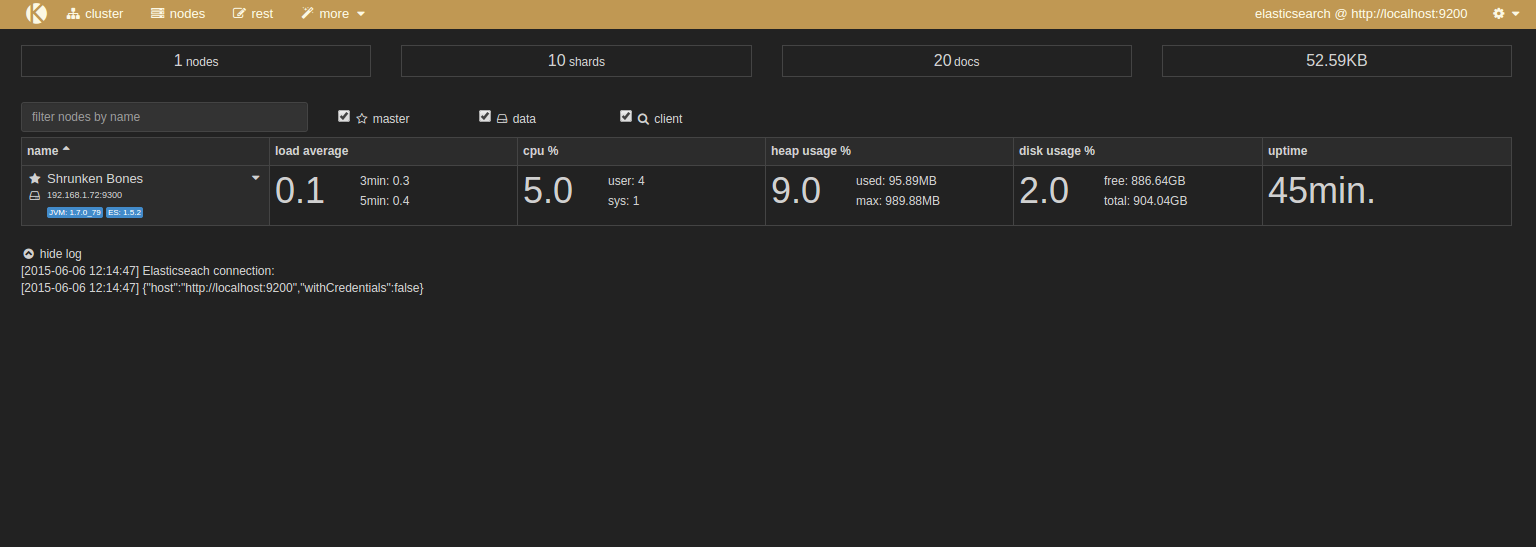
Démonstration
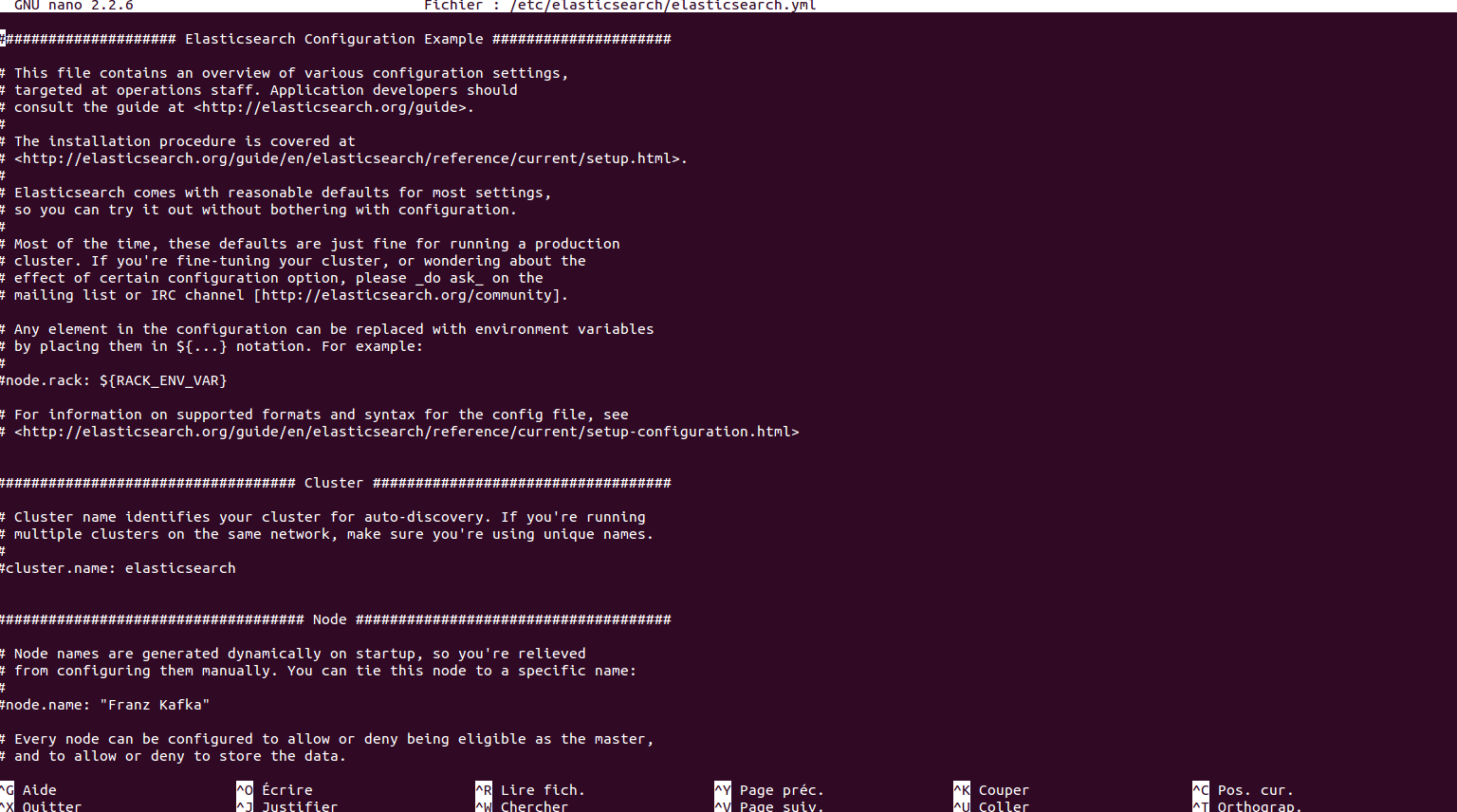
/etc/elasticsearch
- cluster.name
- node.name
- network.host
- discovery.zen.ping.unicast.host
- path.conf
- path.work
- path.log
- path.plugins
- node.master
- node.data


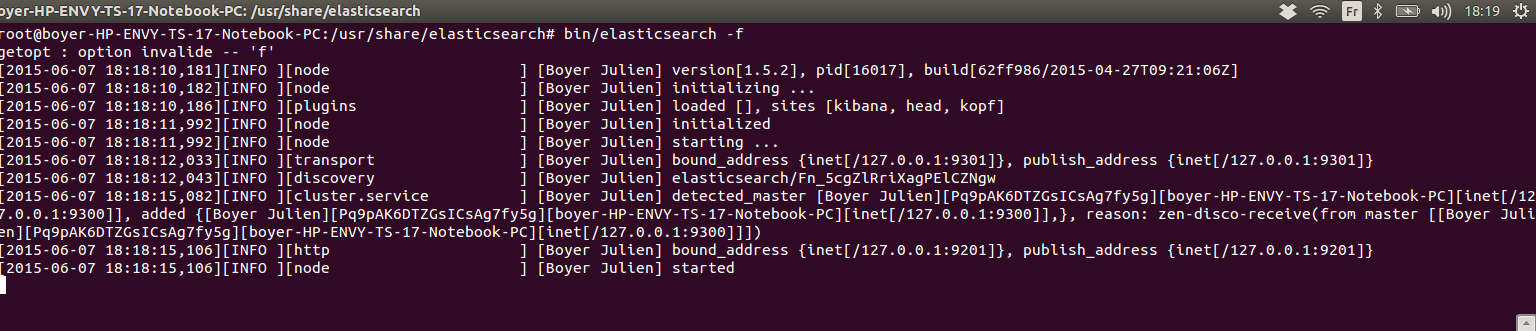
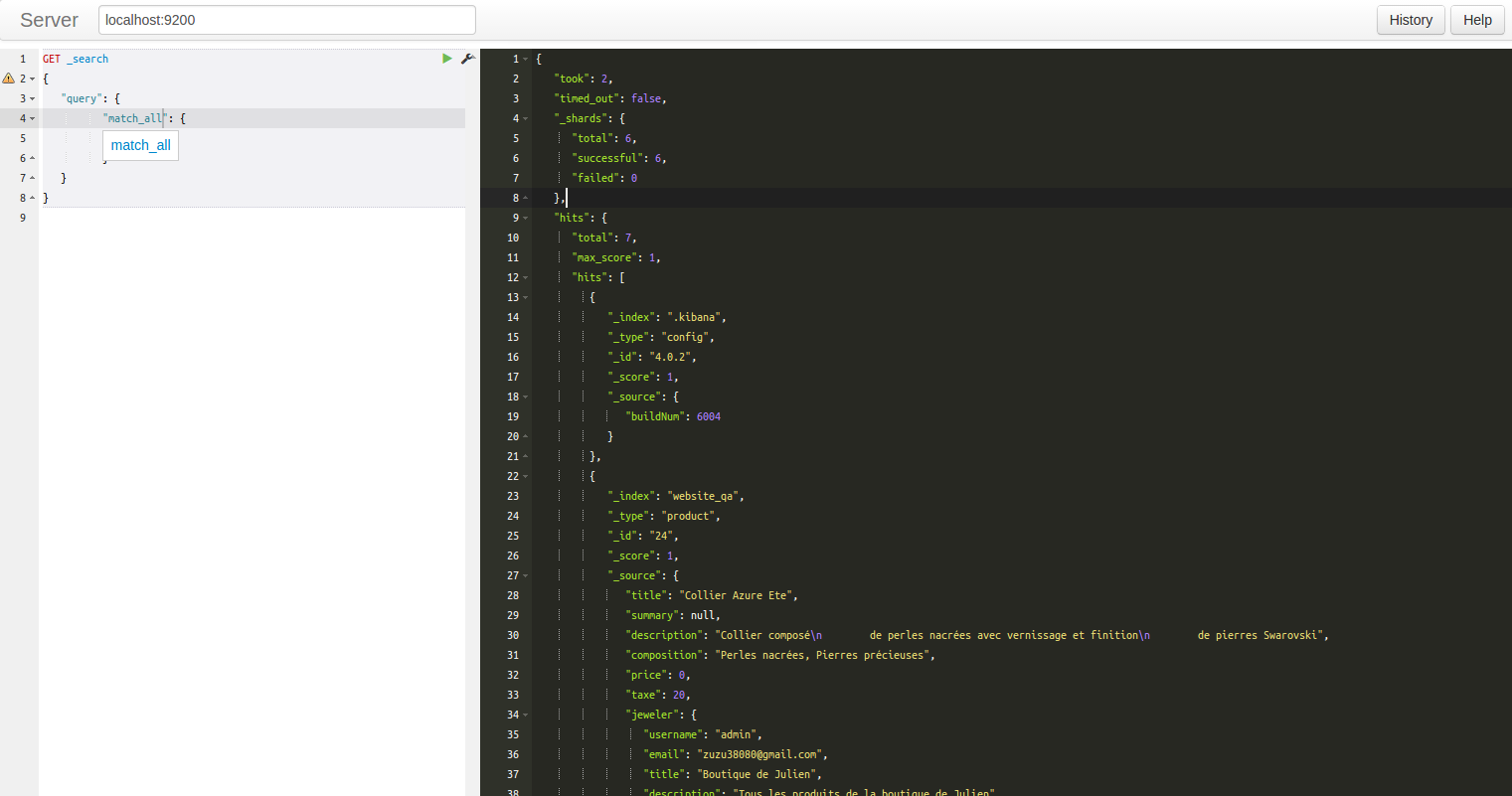
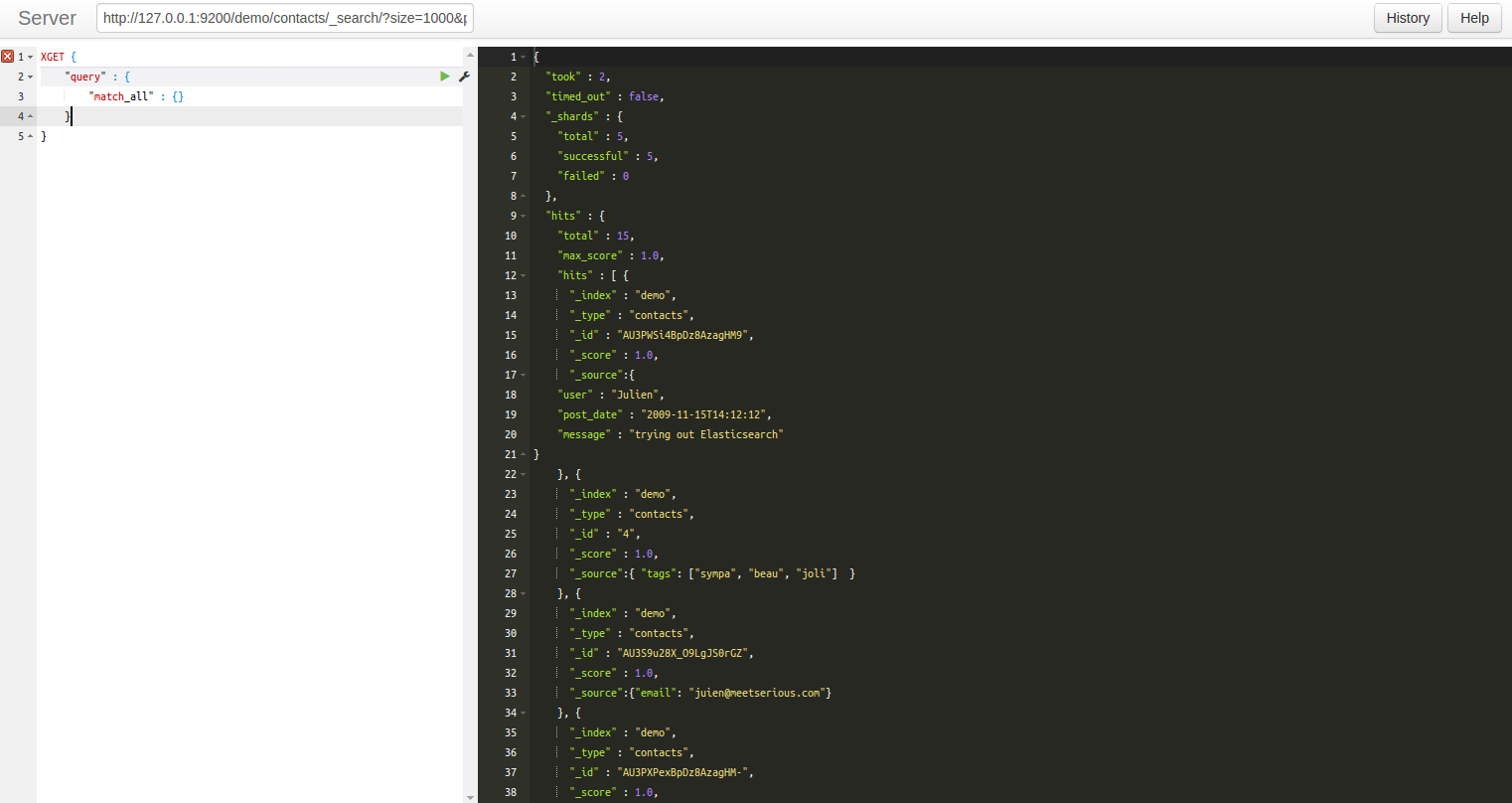
- curl -XPUT http://127.0.0.1:9200/demo
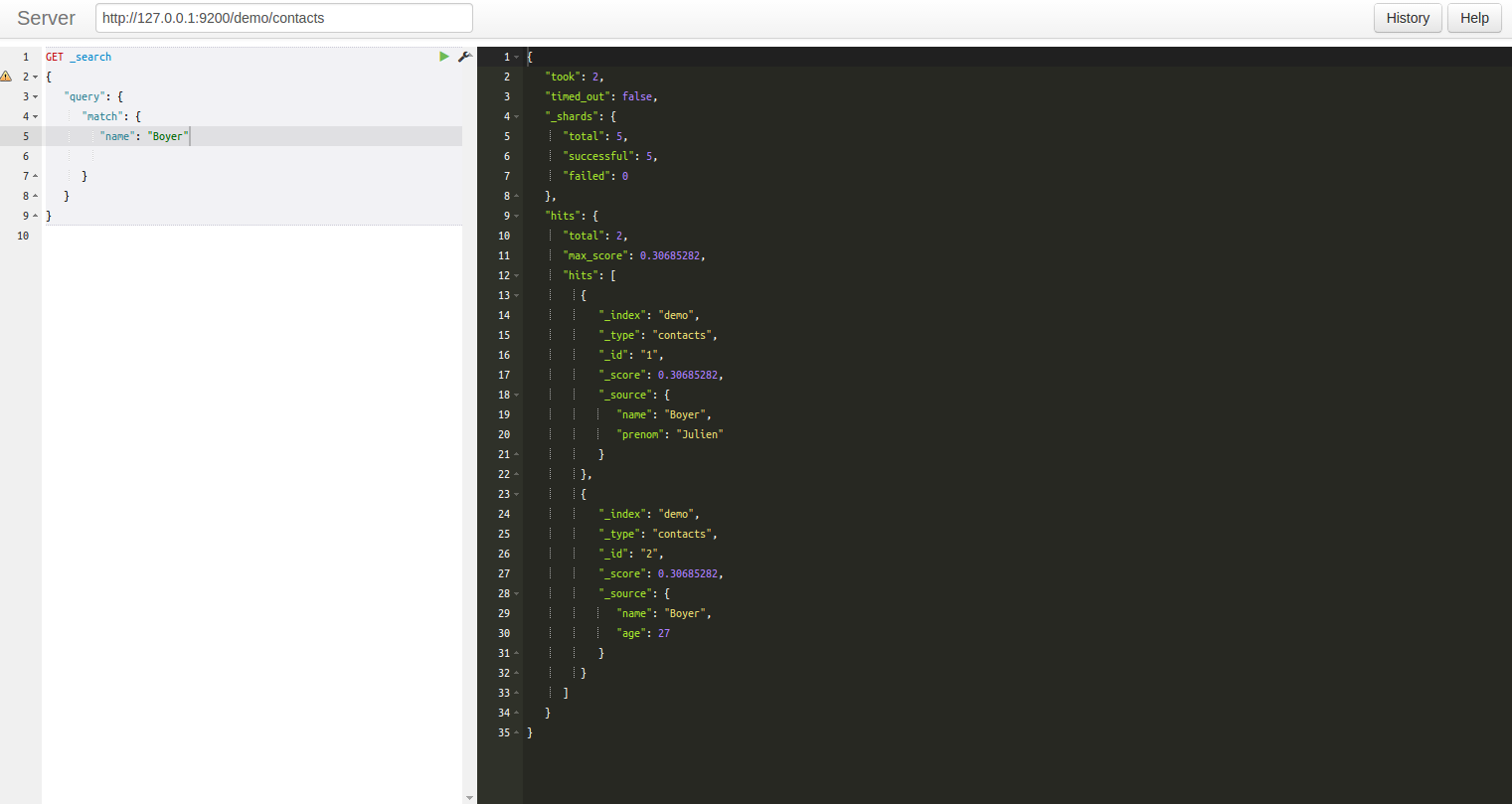
- curl -XGET http://127.0.0.1:9200/demo
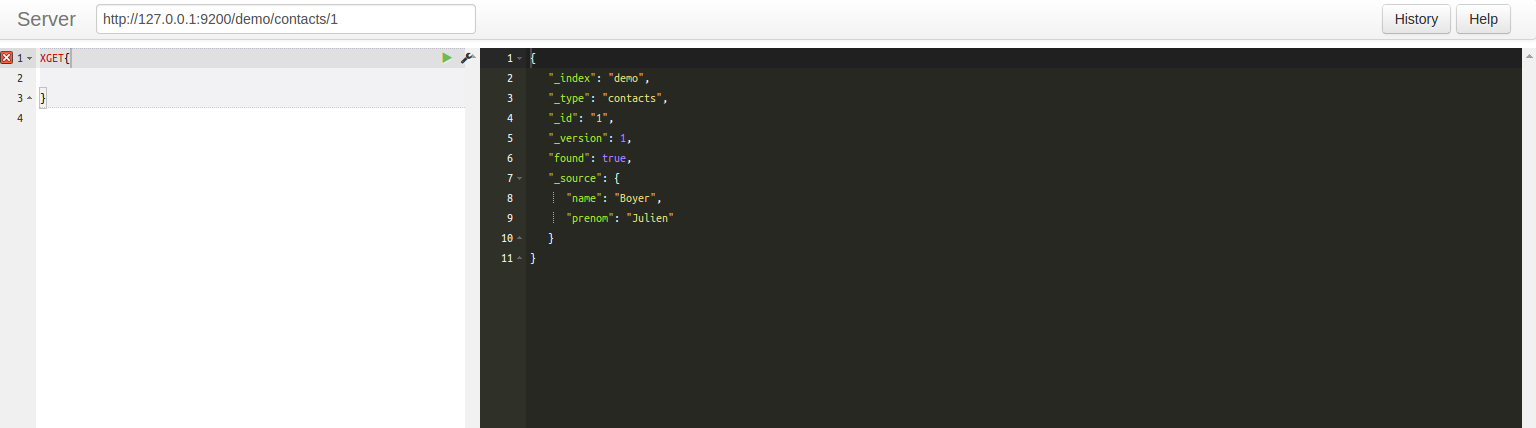
- curl -XPUT http://127.0.0.1:9200/demo/contacts/1 -d '{"name": "Boyer", "prenom": "Julien"}'
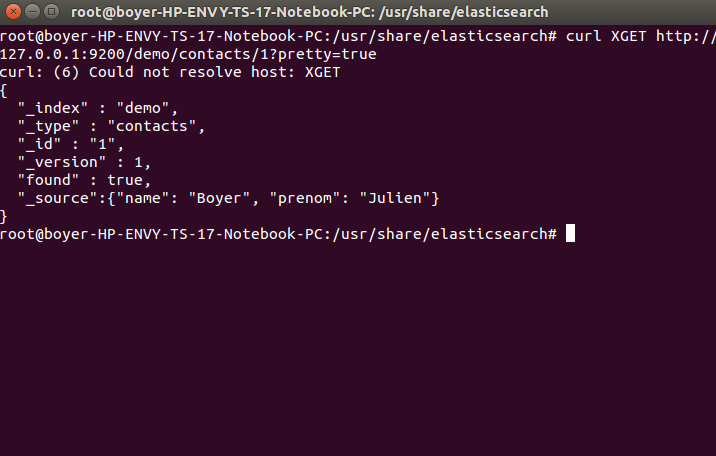
- curl XGET http://127.0.0.1:9200/demo/contacts/1
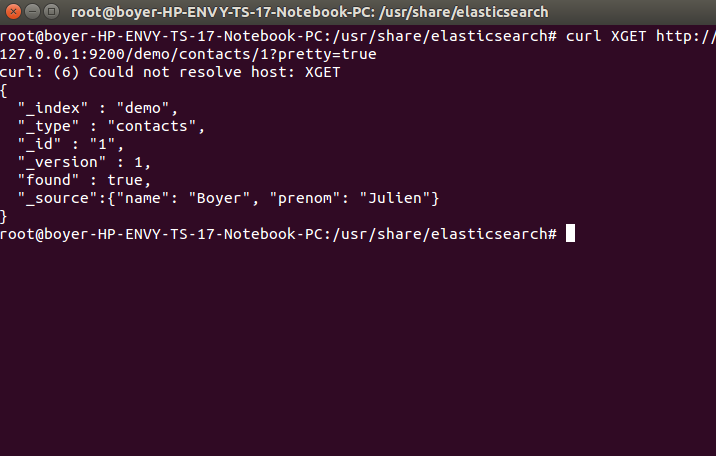
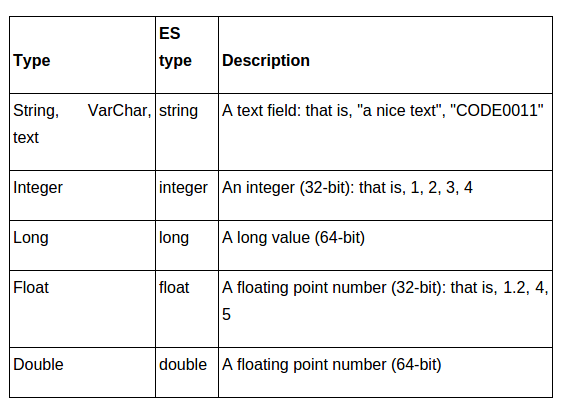
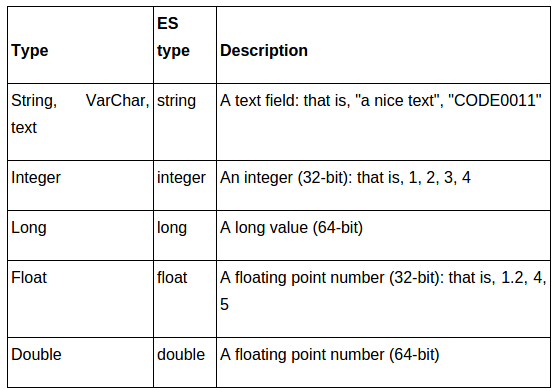

Chaque item
- store: store in separate index
- index: field indexed
- null_value: if the field is null
- boost: importance of field
- index_analyzer
- search_analyzer
- include_in_all


deck
By Julien Boyer



