Brush Up Your Evergreen Search
Kathy Lussier
MassLNC Coordinator
2018 Evergreen International Pre-Conference
I could talk about search all day. Some days I do.
-- kmlussier, 11/04/15
What are some frustrations you have with Evergreen search?
Recent Improvements
- 2.12 - Addition of activity metric for ranking search results (more like Amazon)
- 3.0 - eliminate two-stage search - faster and more complete set of search results
- 3.1 - search and display infrastructure project
- Easier to weight specific fields in relevance ranking for keyword searches
- Highlighted search terms
About Evergreen Search
- PostgreSQL full-text search - https://www.postgresql.org/docs/9.4/static/textsearch.html
- QueryParser - builds the SQL query from user's search input
Creating Search Indexes
From the staff client: Administration -> Server Administration -> MARC Search Facet Fields
From the database: config.metabib_field
Title Metabib Fields
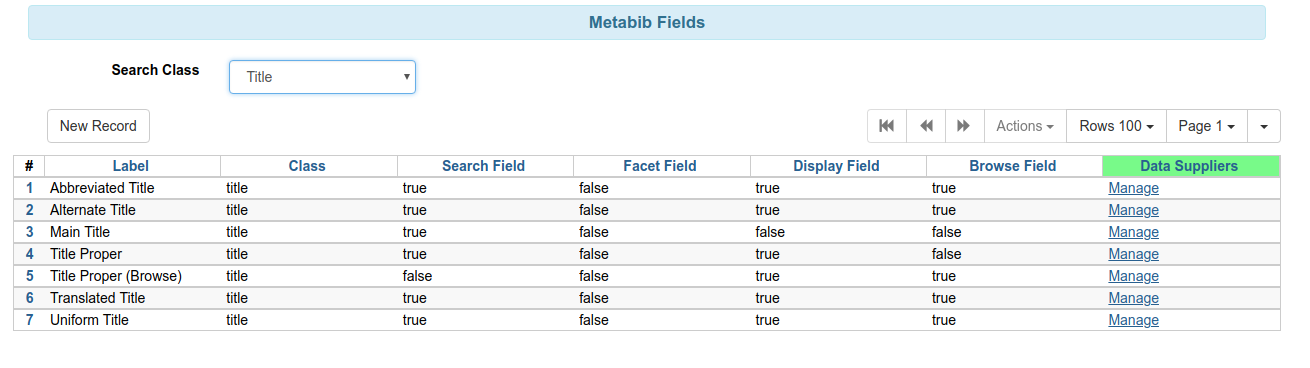
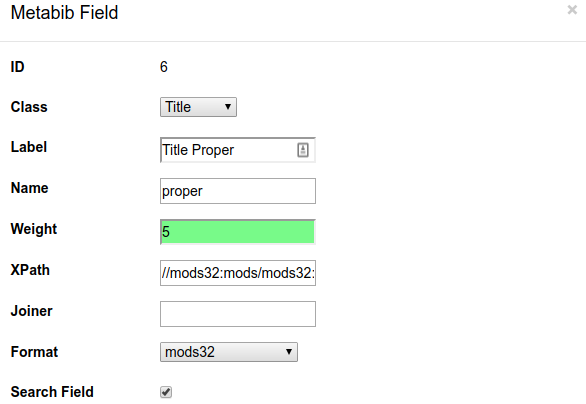
Title Proper Configuration
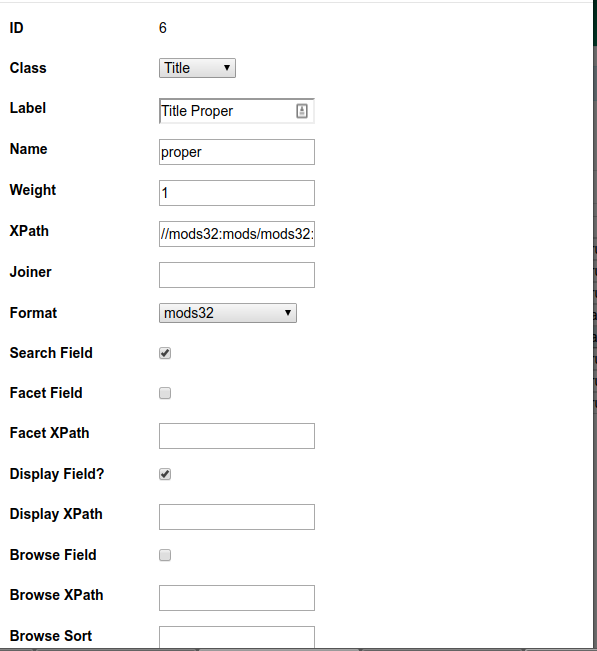
Adding a new index
- Class - select author, keyword, series, subject, title or identifier
- Weight - should this index have a higher (or lower) weight in relevance ranking compared to other indexes in the same class?
- xpath - define the fields that should be included in this index
- Can be expressed in MODS, MARC or MADS (authority data)
- Format - the format of the xpath.
- Can be mods32, mods33, marcxml, marc21expand880, mads21 (authority)
- Enable for search, facet, display, and/or browse.
Why MODS?
"MODS handles the AACR2 interpretation for us; it stitches together the appropriate fields, applies NFI to titles, and the like. Otherwise we would need to invent and implement our own plugin system for all those rules (instead of letting LoC do that work for us via MODS), or hard-code them in the indexing code."
Mike Rylander, 1/29/15, Evergreen general mailing list
Interpreting MODS

Interpreting MODS
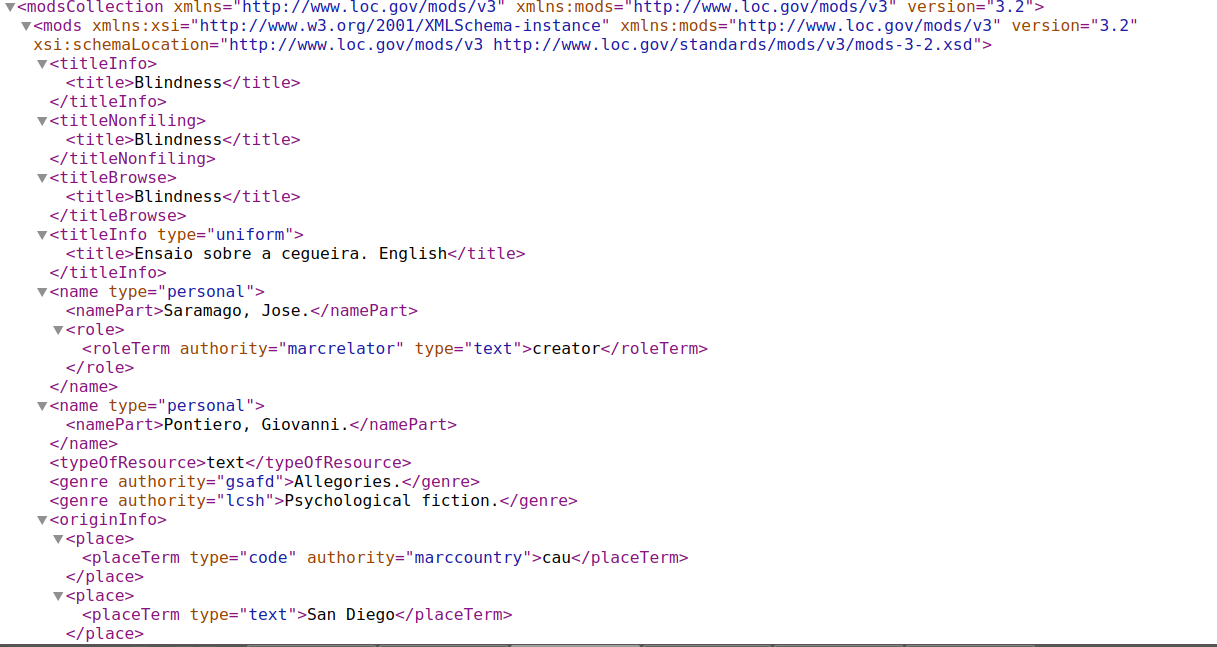
//mods32:mods/mods32:titleNonfiling[mods32:title and not (@type)]
//mods32:mods/mods32:titleInfo[mods32:title and (@type='uniform']
//mods32:mods/mods32:name[mods32:role/mods32:roleTerm[text()='creator']]
//mods32:mods/mods32:name[@type='personal' and not(mods32:role/mods32:roleTerm[text()='creator'])]
marcxml
You don't need to use MODS for your indexes. Using the marcxml format, all of our identifier indexes are based on MARC tags, subfields and/or indicators.
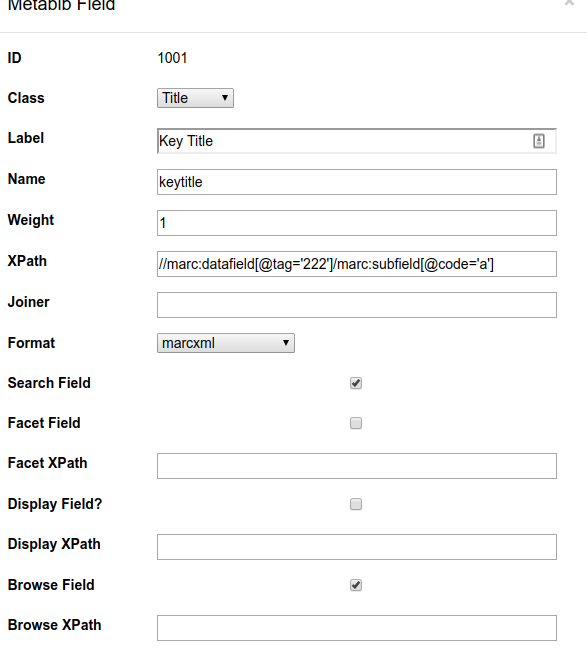
In this example, we add a field for the MARC 222 tag - key title, which is not covered by MODS. In addition to specifying tags and subfields in the xpath, admins can also specify indicator values.
Normalization
Text normalization is the process of transforming text into a single canonical form that it might not have had before. Normalizing text before storing or processing it allows for separation of concerns, since input is guaranteed to be consistent before operations are performed on it.
Text normalization. (n.d.). In Wikipedia. Retrieved April 25, 2018, from https://en.wikipedia.org/wiki/Text_normalization
Does the field need normalization?
- config.index_normalizer contains all of the normalizers used during indexing
- Wiki contains a good description of each of these normalization functions - http://bit.ly/evgils_normalize
- In config.metabib_field_index_norm_map, you need to map your new index definition (by ID) to the ID for the normalizer(s) that should be used.
Search Normalize
- This normalizer is used by most of our non-numeric search indexes.
- Tells the system how to handle leading/trailing spaces, punctuation, diacritics and other special characters.
- An adapted version of the NACO standard.
Normalization Example
We want to map our keyword index (id 15) to the NACO normalizer (id 1)
We would use the following SQL to map it:
INSERT INTO config.metabib_field_index_norm_map (field, norm) VALUES (15, 1);
REINGEST!
- Reingests are required after making many types of changes to search configuration.
- Adding an index requires a reingest
- Try to think of all index changes you need to make before implementing. Reduces the number of required reingests.
Overview of pre-3.1 default indexes
- Author class - personal author, conference author, corporate author, other author, all creators.
- Series class - Series title, series title (browse).
- Subject class - name subject, geographic subject, temporal subject, topic subject, all subjects, topic browse, geographic browse, temporal browse.
- Title class - Abbreviated title, alternate title, translated title, title proper, uniform title, title proper browse.
Overview of pre-3.1 default indexes
-
Identifier index
- Used for numeric identifiers
- Also used for other required indexes that you don't want to add to a specific search class (e.g. genre)
-
Keyword index
- Known as 'the blob.'
- One index - covers everything from MODS except those fields that are part of the originInfo element.
- OriginInfo includes publisher, place of publication, publication date.
-
Adding almost everything from MODS does not mean we are adding all MARC tags.
A look at how words are indexed in the keyword blob
Harry Potter and the half-blood prince Harry Potter and the half-blood prince Harry Potter and the half-blood prince Rowling, J. K. creator Dale, Jim. sound recording-nonmusical fiction eng sound recording sound disc 17 sound discs (ca. 72 min. each) : digital ; 4 3/4 in. Harry Potter and the Half-Blood Prince takes up the story of Harry Potter's sixth year at Hogwarts School of Witchcraft and Wizardry at this point in the midst of the storm of this battle of good and evil. juvenile by J.K. Rowling. Unabridged. Compact disc. Read by Jim Dale. Potter, Harry (Fictitious character) Fiction Wizards Fiction Magic Fiction Schools Fiction Hogwarts School of Witchcraft and Wizardry (Imaginary place) Fiction Potter, Harry (Fictitious character) Juvenile fiction Wizards Juvenile fiction Magic Juvenile fiction Schools Juvenile fiction Hogwarts School of Witchcraft and Wizardry (Imaginary place) Juvenile fiction Audiobooks PZ7.R79835 Harh 2005ab [Fic] 0307283674 YA 760ACD Random House/Listening Library Books on Tape WORP-MAIN WORP-MAIN ROWLING WORP-MAIN WORP-MAIN ROWLING WORP-MAIN WORP-MAIN ROWLING WORP-MAIN WORP-MAIN ROWLING TEFBT 050510 20130418154900.0 412192
New in 3.1: Virtual Index Definitions
- We still create indexes the same way
- We can now take an index from one class and add it to another class simply by mapping it.
- The blob is not yet dead, but it is less important and closer to its demise.
Virtual Index Definitions
- Administration -> Server Administration -> MARC Search / Facet Fields
- Virtual Index Definitions do not require an xpath.
- Click the Manage link to add indexes to the virtual index.
- Stock data has just one virtual index - All searchable fields
All searchable fields index
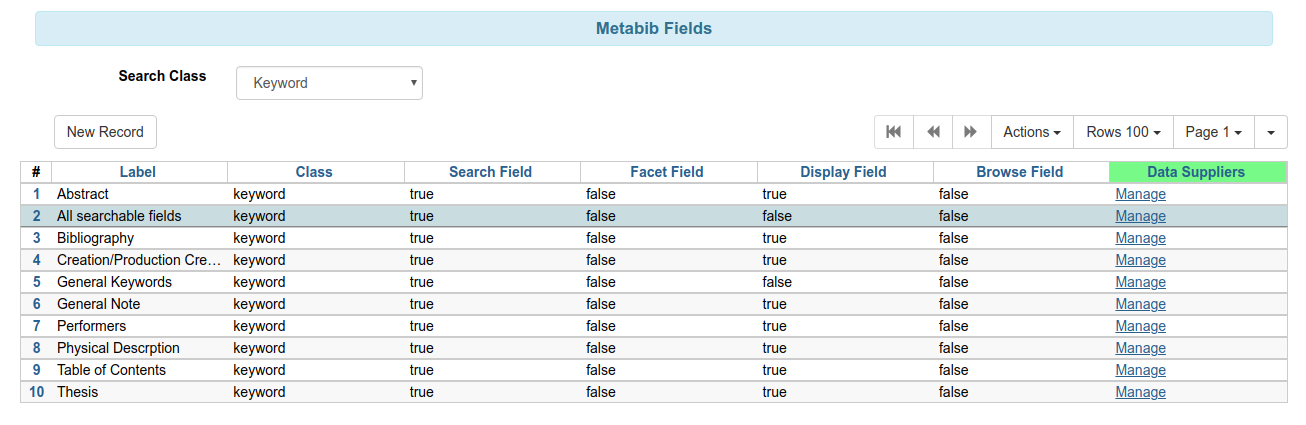
Adding existing indexes to all searchable fields
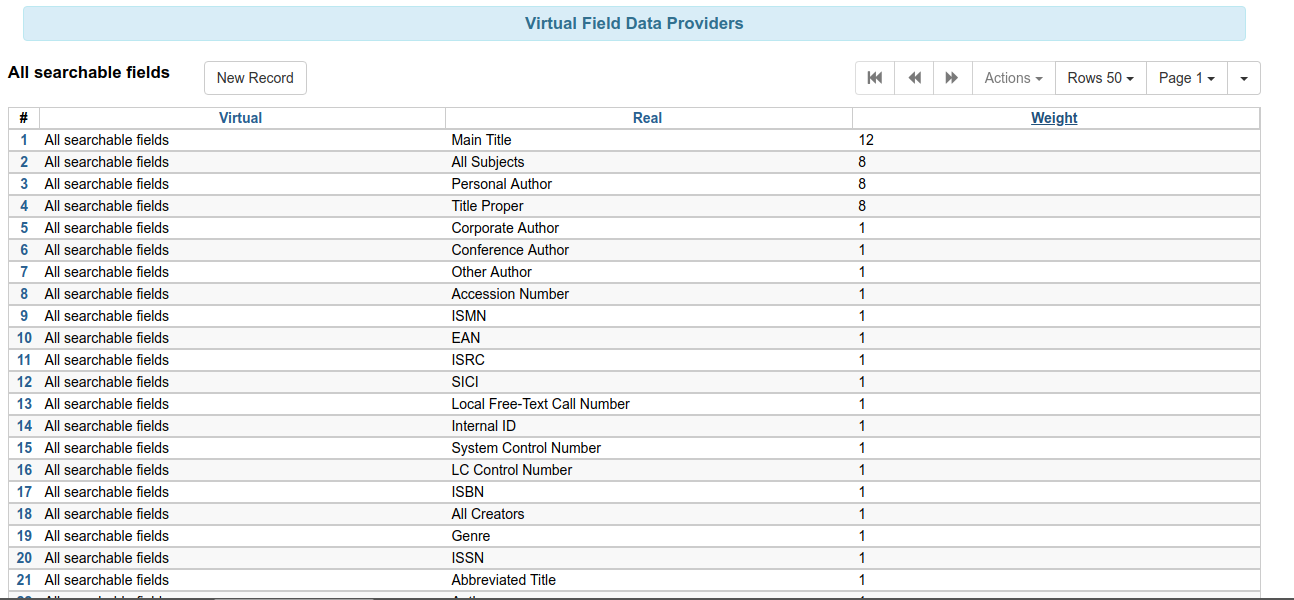
New Identifier Indexes for 3.1
- Will not be part of keyword searches by default, but can easily be added.
- Can also be easily added as a separate search field in the catalog.
- New indexed fields include publisher, edition, and other origin info.
See how records are indexed
- The metabib contains several tables that store index terms for each record in the database.
- Each search class has its own metabib table:
- metabib.author_field_entry
- metabib.identifier_field_entry
- metabib.keyword_field_entry
- metabib.subject_field_entry
- metabib.title_field_entry
Metabib Entries
To see how the title is indexed for record 412192, run the following SQL:
SELECT * FROM metabib.title_field_entry WHERE source = 412192
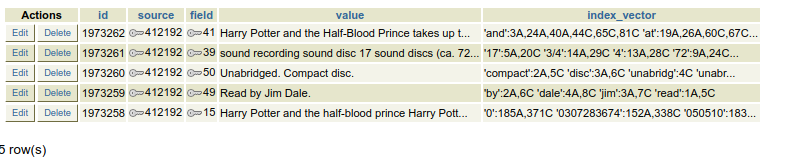
Metabib values and index vectors
- The value stores the full value of the field(s) that are indexed.
- The index vector stores distinct lexemes that are words that have gone through our index normalizers and, in some cases, have been stemmed.
- The numbers indicate the location of the lexemes in the original string.
- The A and C refer to a weight based on whether the lexeme came from an index using a non-stemmed simple dictionary or one using a dictionary that stems the lexeme.
Index Vector
'and':3A,24A,40A,44C,65C,81C 'at':19A,26A,60C,67C 'battl':78C 'battle':37A 'blood':7A,48C 'evil':41A,82C 'good':39A,80C 'half':6A,47C 'half-blood':5A,46C 'harri':42C,55C 'harry':1A,14A 'hogwart':61C 'hogwarts':20A 'in':29A,70C 'midst':31A,72C 'of':13A,22A,32A,35A,38A,54C,63C,73C,76C,79C 'point':28A,69C 'potter':2A,15A,43C,56C 'princ':49C 'prince':8A 's':16A,57C 'school':21A,62C 'sixth':17A,58C 'stori':53C 'storm':34A,75C 'story':12A 'take':50C 'takes':9A 'the':4A,11A,30A,33A,45C,52C,71C,74C 'this':27A,36A,68C,77C 'up':10A,51C 'witchcraft':23A,64C 'wizardri':66C 'wizardry':25A 'year':18A,59C
The apostrophe problem

Finnegans Wake
or
Finnegan's Wake?
Search Normalize Function
- The Search Normalize function, used to normalize most of our non-numeric indexes, is a modified version of a normalizer based on the NACO standard.
- The primary difference between the two normalizers is in how it handles apostrophes:
- Search Normalize replaces the apostrophe with a space.
- NACO Normalize removes the apostrophe.
- The modification was made to better handle French language searches:
- l'histoire can be retrieved with a search term of 'histoire'
Midsummer night's dream example

Query 1: User enters 'midsummer night's dream'
- Search replaces apostrophe with space. 'midsummer' 'night' 's' and 'dream' are sent as query. record is retrieved.
Query 2: User enters 'midsummer nights dream'
- Search stems nights to night. 'midsummer', 'night' and 'dream' are sent as query, record is retrieved.
Finnegans wake example

Query 1: User enters 'finnegans wake'
- Search stems finnegans to finnegan. 'finnegan' and 'wake' are sent as query. Record is retrieved.
Query 2: User enters 'finnegan's wake'
- Search replaces apostrophe with space. 'finnegan', 's' and 'wake' are sent as query. Record is NOT retrieved because there is no 's' in the index vector.
But we do get some results
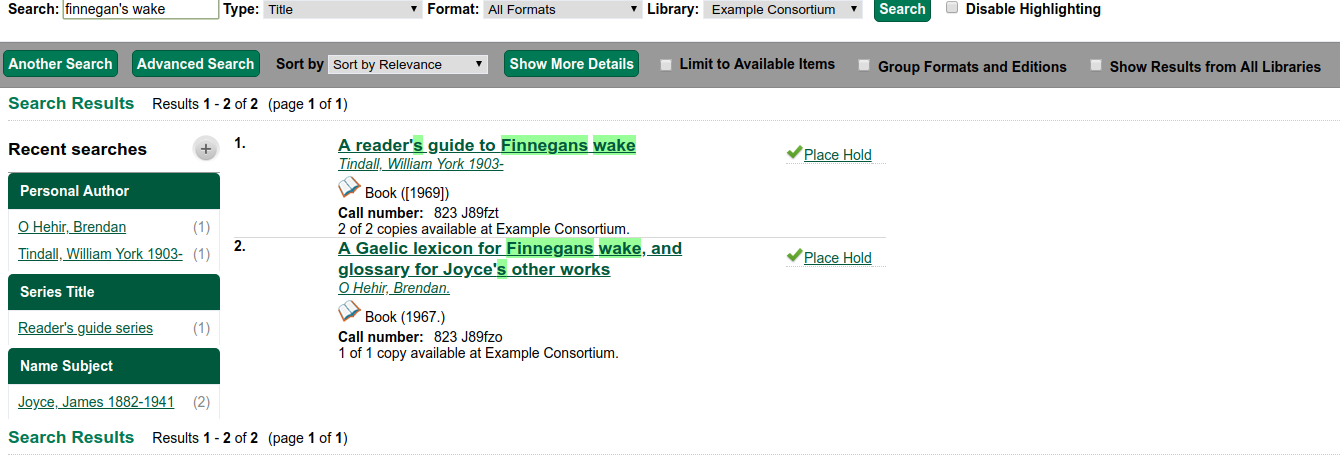
Let's try this with the NACO Normalizer
Midsummer night's dream example
Query 1: User enters 'midsummer night's dream'
- Search removes apostrophe and stems nights to night. 'midsummer' 'night' and 'dream' are sent as query. record is retrieved.
Query 2: User enters 'midsummer nights dream'
- Search stems nights to night. 'midsummer', 'night' and 'dream' are sent as query. record is retrieved.

Finnegans wake example

Query 1: User enters 'finnegans wake'
- Search stems finnegans to finnegan. 'finnegan' and 'wake' are sent as query. Record is retrieved.
Query 2: User enters 'finnegan's wake'
- Search removes apostrophe and stems finnegans to finnegan. 'finnegan' and 'wake' are sent as query. record is retrieved.
But we're back to our l'histoire problem

There is no perfect solution that will do the right thing for both languages.
Considerations before moving to NACO normalizations
- Do you serve a large French-speaking population?
- If so, you'll probably stick with Search Normalize
- Have you disabled stemming?
- If so, strongly consider moving to NACO.
Making the change to NACO
UPDATE config.metabib_field_index_norm_map a SET norm = 1 FROM (SELECT id,norm FROM config.metabib_field_index_norm_map) AS subquery WHERE subquery.norm = 17 AND a.id = subquery.id;
Reingest!
Let's Talk About Relevance
Cover Density
- Cover Density is the primary determinant of how results will be ranked
- It looks at the portion of the metabib entry that contains search terms:
- Five search terms in a 100 word metabib entry are seen as more relevant than five search terms in a 500 word metabib entry.
- It also considers term proximity and the ABCD weights that we saw in the index vector.
Title Search for Gone Girl
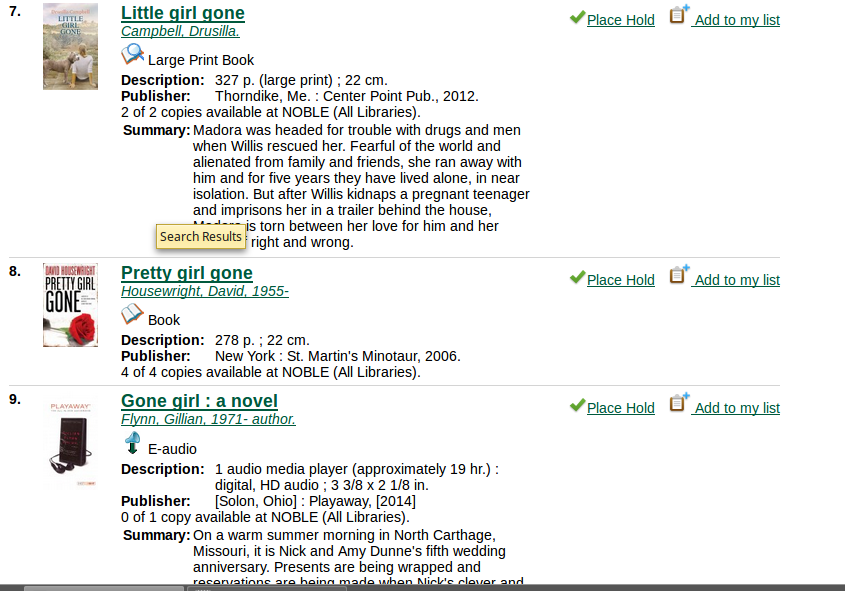
Title Search for Gone Girl


Adjusting weighting for specific fields
When configuring a search index, there is a weight field where you can specify how important this field is in relation to other fields of the same class.
The pre-3.1 keyword weighting problem
- Because there was just one default index in the keyword class, there wasn't an easy way to weight specific fields.
- The solution was to add specific indexes to the keyword class (Title Proper, Personal Author, etc.) to weight those fields.
- Cover density would then weight those fields more heavily without the need of adjusting the weight setting.
- Led to many duplicate indexes.
Ease of 3.1 field weighting
In the All Searchable Fields Virtual Index, adjust the weights for fields that have been added.
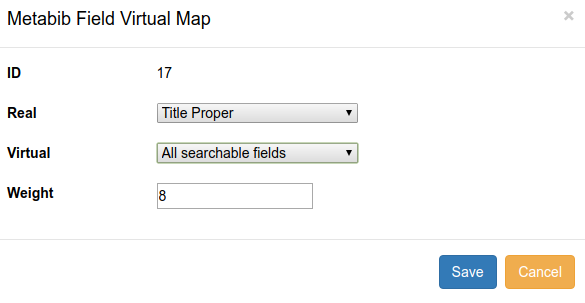
Comes with reasonable defaults
- Weight of 12
- Main title (245$a)
- Weight of 8
- All Subjects
- Personal Author
- Title Proper
- Weight of 0
- Any note fields
- Weight of -1
- Physical description
All other fields are set to 1.
Keyword search for the list in 3.0
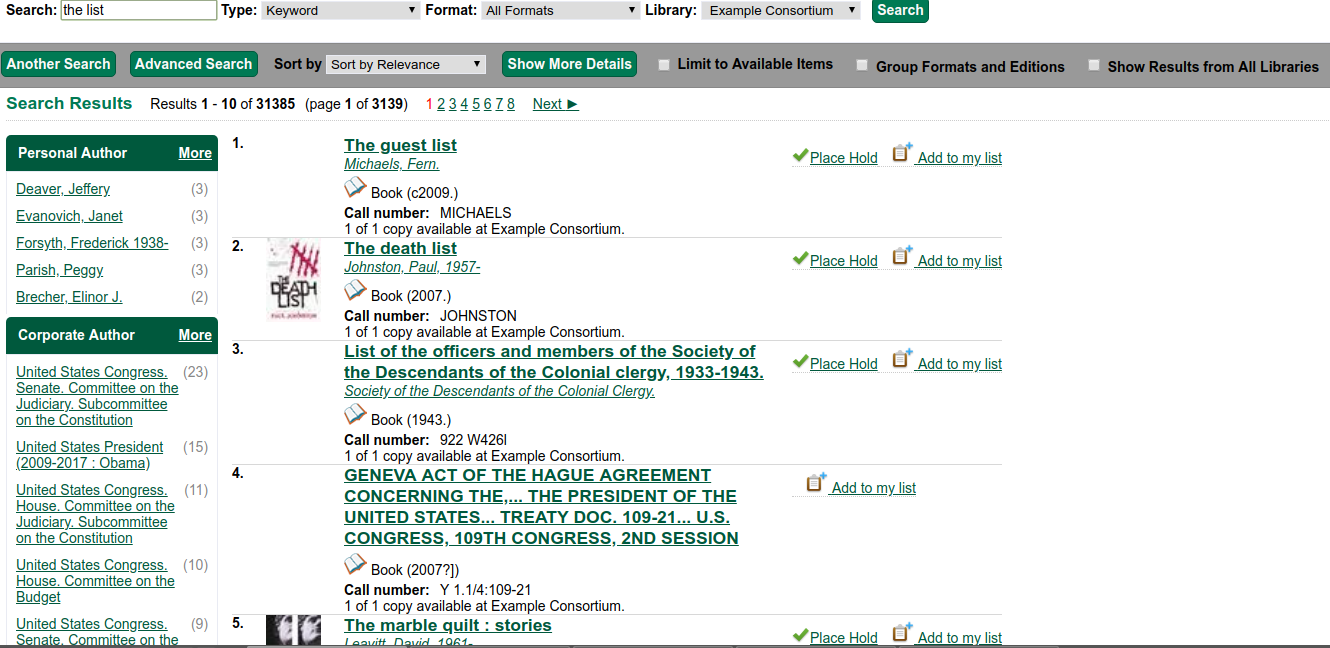
Keyword search for the list in 3.1
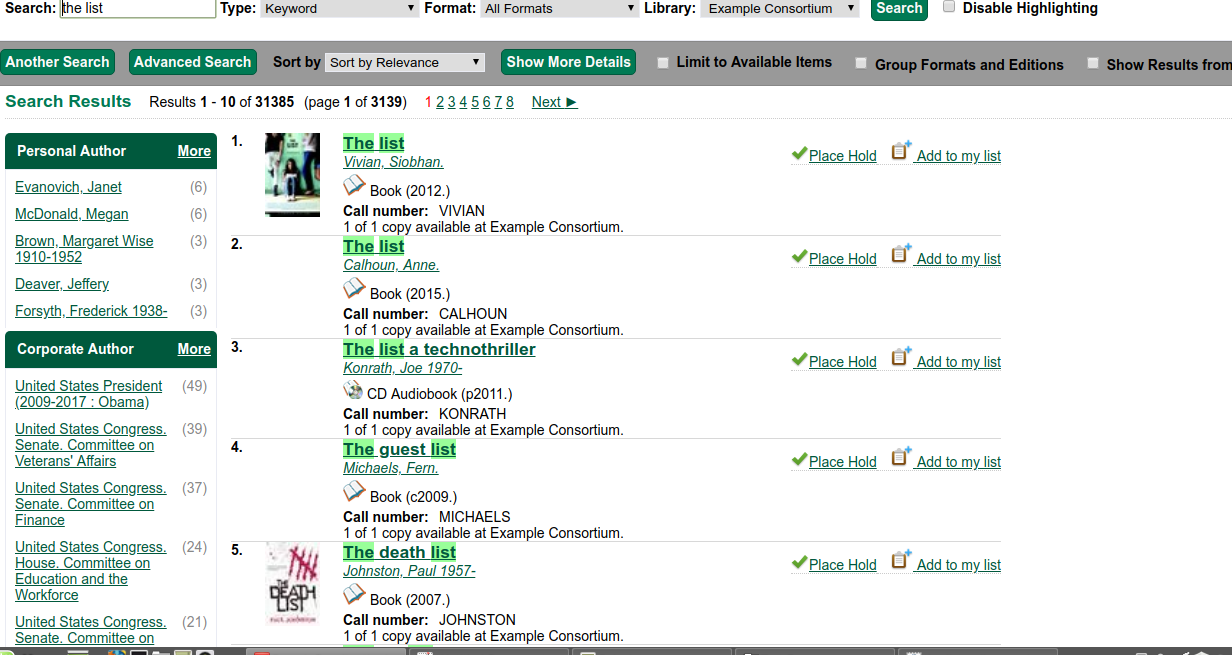
NO REINGEST REQUIRED
It may take time for weight changes to appear due to the cache
Beyond Bib Relevance
- Bibliographic data is important, but our systems have so much more data that could help us determine which records should be sorted at the top of the list.
- Many search sites, like Amazon, use sales and other activity data to determine that a title should be boosted higher than others.
- We also have useful holds, circulation and other activity data that can be used to boost titles.
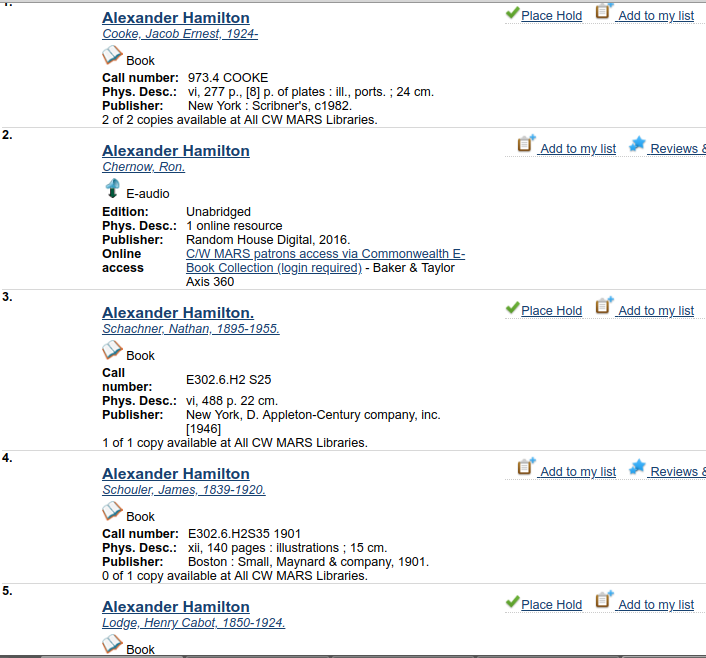
How many titles about Alexander Hamilton are in your collection?
If there are 20 with the title Alexander Hamilton and a subject of Alexander Hamilton, how does the system decide which comes first?
Bib ranking for alexander hamilton keyword search
Popularity/ bib relevance ranking for alexander hamilton keyword search
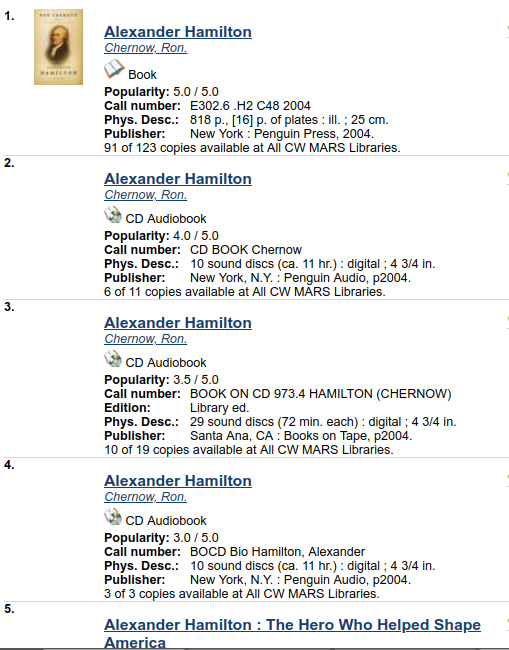
Statistically generated record ratings
- Tell the system how you define popularity for your collection.
- Run a regular cron job where the system finds record that meet your criteria.
- Public catalog displays these ratings, on a scale of 1 to 5, to users.
- Records with higher popularity score can sort to the top of results.
With a starter badge for top holds requested, it's easy to turn on.
Add the following to your crontab:
30 4 * * * . ~/.bashrc && $EG_BIN_DIR/badge_score_generator.pl $SRF_CORE
Badges will begin calculating overnight!
Configuration Options
Admin interfaces are available in the web client
Local Admin ->
Statistical Popularity Badges
If you don’t have the web client running, you can add the badges directly in the database. All activity metric settings are located in the rating schema.
-
rating.popularity_parameter is where available parameters are stored.
-
rating.badge is where you configure badges that can be applied to records.
-
rating.record_badge_score is where the scores for each record are stored after the calculations are run.
Calculating scores
-
A script is available - badge_score_generator.pl - to calculate all badge scores. Add this script to your crontab to run the script nightly.
-
You can also manually run a calculation for an individual badge by running the recalculate_badge_score(id) database function.
Notes on some badge fields
-
Name: This is the name that will display on the record detail page to the public.
-
Scope: If you select a branch or system here, the badges will only be applied to titles with copies owned by the selected branch or system. This badge will only affect results for searches that are scoped to that system or branch.
-
Weight: The weight a specific badge carries in relation to other badges that may be applied to the record. It will affect the total badge score that is calculated when two or more badges are earned for the record. It has no impact on records that earn 1 badge.
Horizon & importance settings
- The age horizon is the total period of time that should be considered to earn a particular badge.
- The importance horizon is the period of time when the circs should get an extra boost to their score because that circulation activity was more recent than other circ activity.
- The importance interval identifies the chunks of time that should be used to apply that boost.
-
The importance scale identifies how much of a boost recent circs should get.
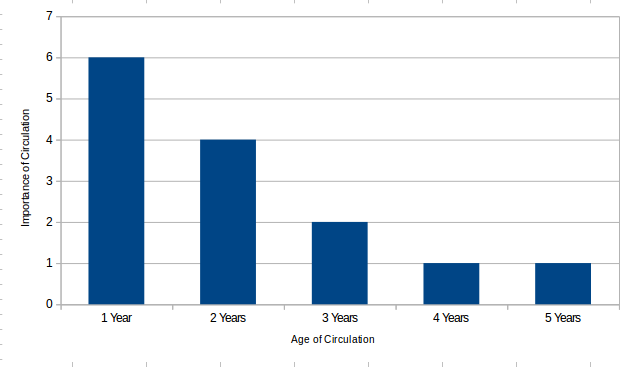
For Example
- Horizon age 5 years
- Importance horizon of 3 years
- Importance interval of 1 year
- Importance scale - 2
More Configuration Fields
- Percentile: In what percentile should the record land in the top circ count or top holds count in order to earn this badge?
- Recalculation Interval: tells the system how often the system should recalculate this badge.
- Location Filters (Record Attribute, Bib Source, Location Group, etc) - With the filters, we can apply the badge to a select set of records depending on its format, its audience level, or other properties.
Even more configuration fields
-
Fixed rating - used to apply a rating to any material that matches filter. This field should only be used for popularity parameters that have the require_percentile field set to False.
-
Discard count - drops records with the lowest values before the percent is applied.
Metrics that worked well in testing
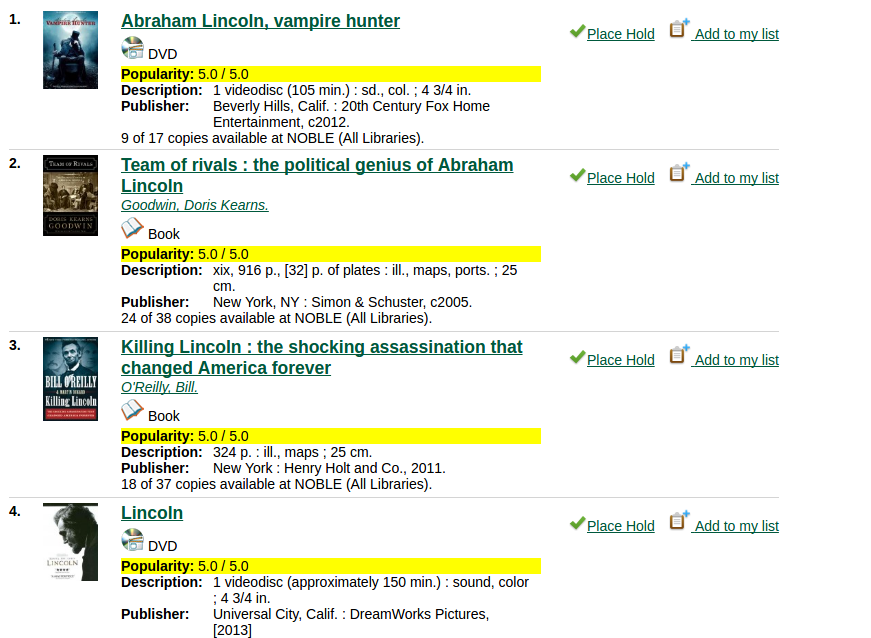
Holds Requested Over Time Holds Filled Over TIme
- Holds metrics is that it highlights titles that people have taken the effort to look up in the catalog to place a hold.
- If choosing between the two, go with holds requested over holds filled because the requested holds will capture activity for on-order and newly-popular materials.
'abraham lincoln' search, sorted by popularity, holds requested metric
Current Holds
-
Carries the same advantages as the holds over time metrics, but captures things that are currently popular.
-
You will not capture activity for things that were popular a couple of years ago or those that are consistently popular over time.
-
May want to use in place of a Holds Requested Over Time metric.
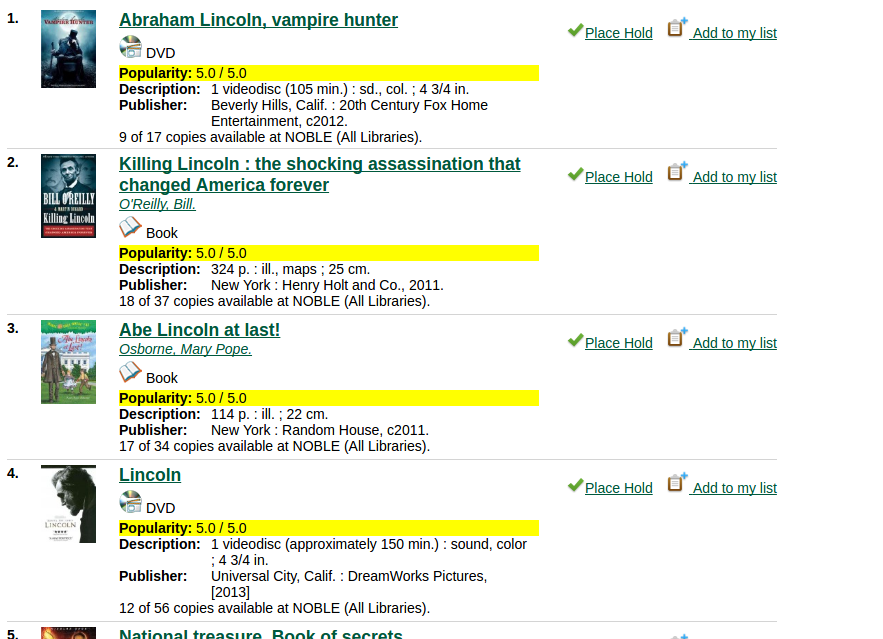
Circulations Over Time
- This metric will capture titles that circulate well, even if people aren’t placing holds on them ahead of time.
- Magazines and juvenile materials often float to the top when using this metric.
- Most useful when used in a targeted fashion.
'abraham lincoln' search, sorted by popularity, top circs
Current Circs
- Provide badges for materials that are currently popular, not ones that have been popular over time.
- The metric considers materials that are currently checked out. It will not include materials that were changed to Lost, Claims Returned, Claims Never Checked Out because, at that point, the patron no longer considers them to be checked out.
Circulation Library Count
- We thought total # of copies would be a good measure, but there were too many anomalies.
- Instead, we're now looking at the breadth of ownership. How many libraries own a particular title?
- Only useful in consortia.
General Badge Recommendations
- Start with a metric that gauges popularity without targeting a particular collection or format.
- If you use this metric over a long period of time, give a boost to more recent activity.
-
A holds metric is ideal for this starter badge.
General recommendations
-
If you think specific materials are not going to get a boost from the starter badge, create targeted badges for those collections.
-
Non-fiction materials (using either record attributes or copy location groups) may be one area that you need to focus on.
- It might also be useful to have badges for top circulating children’s materials, YA materials or DVDs. For collections that tend to get high activity, such as children’s and DVDs, you might want to set the percentile higher.
- A circulation metric over a long period of time may be a good choice for these targeted badges.
-
General recommendations
-
In multi-type consortia, for libraries that are a bit different than the majority of your libraries, consider badges for that specific org unit.
-
In an academic library, for example, you might target a particular high-use collection, like reserves, or use one of the circulation metrics or in-house use as a way to capture the activity in those libraries.
Ranking methods
-
The 'most popular' ranking method sorts the results by badge score. Within results that have the same badge score, the ranking method will be by relevance.
- The popularity-adjusted relevance method blends popularity with bib relevance.
Settings for ranking methods
-
A new global flag allows you to set the default sort method used by the catalog. If unset, the default sort will be relevance.
-
A new global flag allows you to determine how much weight (1.0 to 2.0) should be given to popularity in the popularity-adjusted relevance ranking method.
Search for 'dogs' by popularity

Search for 'dogs' by popularity relevance
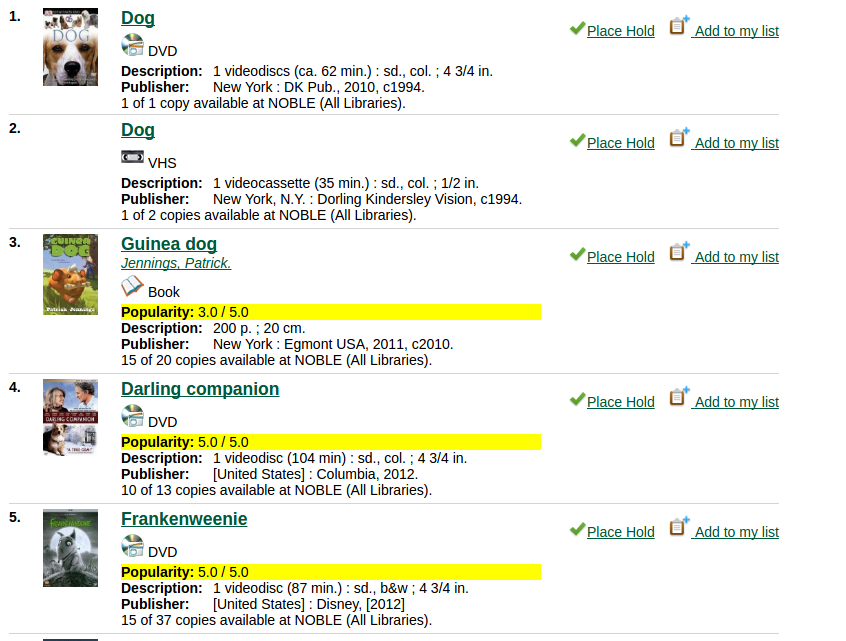
Two popularity options could confuse patrons
-
Remove a ranking method by editing the filtersort.tt2 file. Pick the method you think will work best for your users.
- If you aren't using badges yet, remove both options.
- Another option: remove relevance, rename popularity-adjusted relevance as relevance, keep the most popular option for true popularity ranking.
Share Your Configuration!
No Reingest Required
PostgreSQL Dictionaries
Dictionaries are used to eliminate words that should not be considered in a search (stop words), and to normalize words so that different derived forms of the same word will match. A successfully normalized word is called a lexeme.
“12.6. Dictionaries.” PostgreSQL Documentation, www.postgresql.org/docs/9.5/static/textsearch-dictionaries.html.
Accessed 3/28/18
Default Dictionaries in Evergreen
- Simple Dictionary (Non-Stemmed)
- English No Stop Stemmed
Evergreen Dictionaries
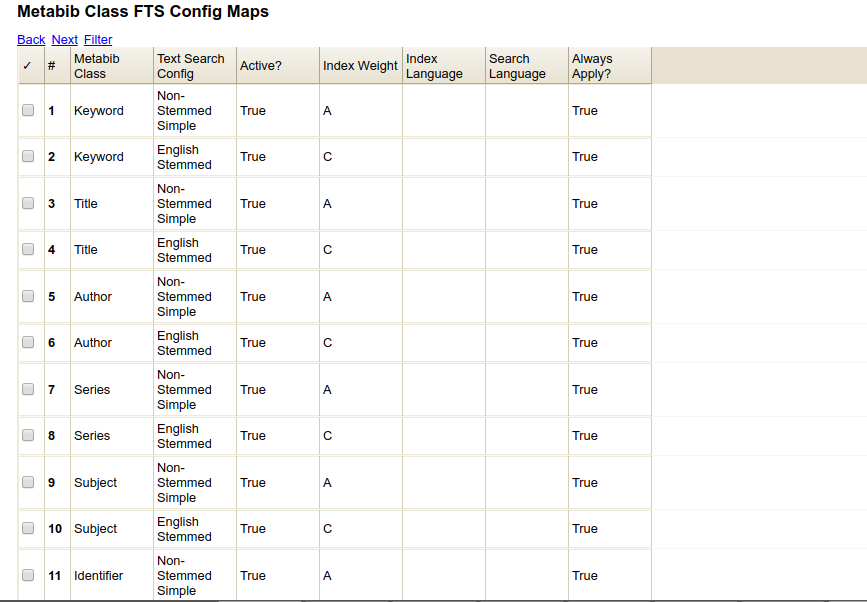
- Terms from each dictionary are stored in the metabib tables.
- By default, non-stemmed terms get a weight of A (1.0). Stemmed terms get a weight of C (.2).
- Adjustments to these dictionaries on a per-class basis can be made at Server Administration -> MARC Search/Facet Class FTS Maps (config.metabib_class_ts_map)
About Stemming
- Evergreen uses the Snowball Stemmer - http://snowballstem.org/
- The algorithm uses word patterns to determine where a word should be stemmed.
- Try the demo at http://snowballstem.org/demo.html to see how specific words are stemmed.

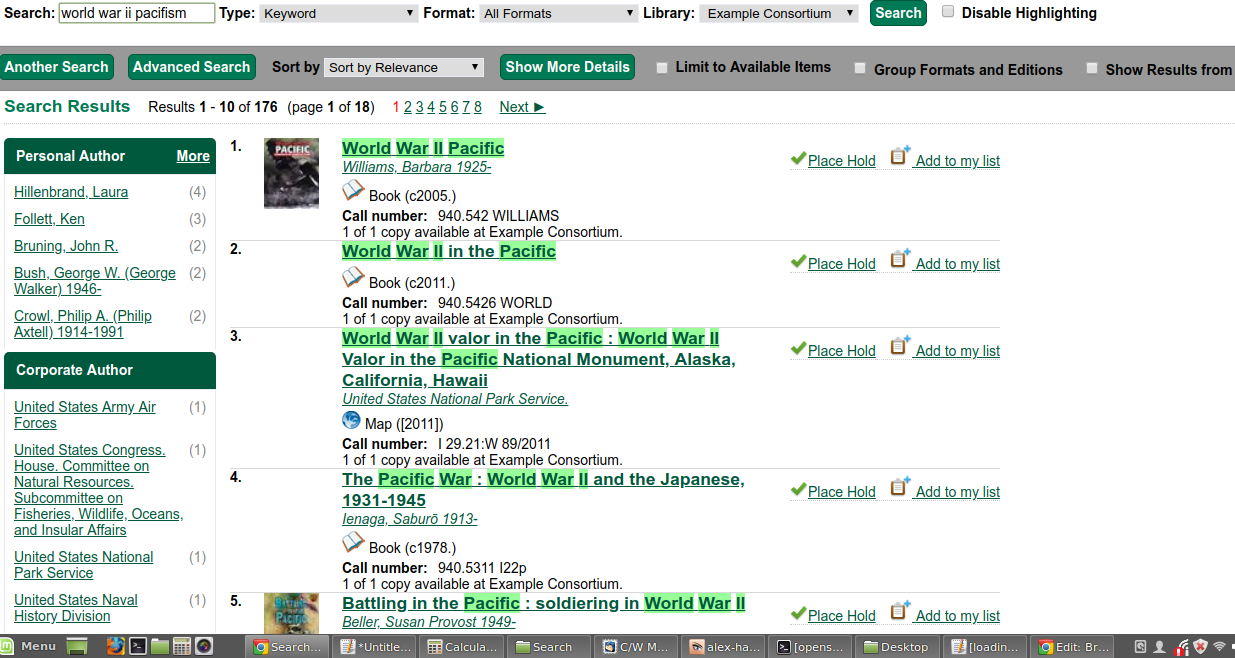
Stemming can help users find records they otherwise wouldn't have found because they entered the wrong variation of a word.
But it also has its drawbacks...
Keyword search for World War II Pacifism
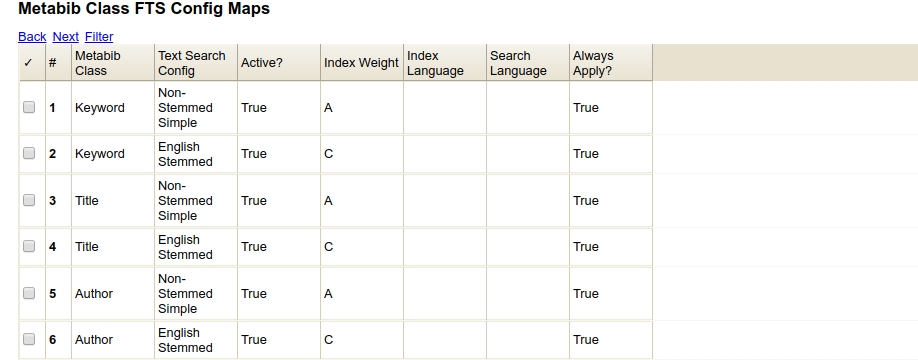
Adusting Stemming
- You can disable stemming for a specific class (e.g. author class) or for all classes by removing the active flag for the English Stemmed dictionary for that class.
Pros of Disabling Stemming
No longer retrieve false hits as a result of questionable variants
Cons of Disabling Stemming
User may not find what they are looking for because they entered singular form of work instead of plural or otherwise entered the wrong variant.
If you decide to disable stemming...
- Strongly consider changing to NACO normalization for non-stemmed classes.
- Strongly consider building a synonym list.
Reingest
Synonym and Thesaurus Dictionaries
Is it a Donut or Doughnut?
Archeology or Archaeology?
Synonym and Thesaurus Dictionaries
- A synonym dictionary allows sites to identify synonyms that can replace a word in a search.
- Phrases are not supported.
- By designating a word as a synonym of itself, you can also stop specific words from stemming.
- A thesaurus dictionary is similar to a synonym list, but also supports phrases.
- It also includes information about relationships of words and phrases, such as broader terms, narrower terms, preferred terms, non-preferred terms, related terms, etc.
Instructions for creating a synonym dictionary, with a sample dictionary, are available at
https://wiki.evergreen-ils.org/doku.php?id=scratchpad:brush_up_search
Creating a thesaurus dictionary
From the command line:
cd /usr/share/postresql/9.x/tsearch_data
sudo cp thesaurus_sample.ths thesaurus_masslnc.ths
psql -U evergreen -h localhost
CREATE TEXT SEARCH DICTIONARY public.thesaurus_masslnc (
TEMPLATE = thesaurus,
DictFile = thesaurus_masslnc,
Dictionary = public.english_nostop
);
Creating a thesaurus dictionary
CREATE TEXT SEARCH CONFIGURATION public.thesaurus_masslnc (copy=DEFAULT);
ALTER TEXT SEARCH CONFIGURATION public.thesaurus_masslnc
ALTER MAPPING FOR asciiword, asciihword, hword_asciipart
WITH thesaurus_masslnc;
Tell Evergreen about the dictionaries and use for indexing
INSERT INTO config.ts_config_list VALUES ('thesaurus_masslnc', 'MassLNC Thesaurus List');
I
NSERT INTO config.metabib_class_ts_map (field_class, ts_config, index_weight) VALUES
('keyword', 'thesaurus_masslnc', 'C'),
('title', 'thesaurus_masslnc', 'C'),
('subject', 'thesaurus_masslnc', 'C');
Test thesaurus dictionary
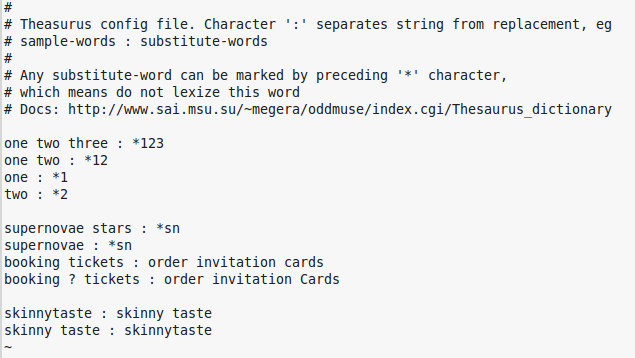
Skinnytaste
If you search skinnytaste, the system will find any records with skinnytaste or skinny taste.
skinny taste does not need to be a phrase for the record to be retrieved.
Searching skinny taste will find the Skinnytaste title. Searching "skinny taste" as a phrase will not retrieve that record.
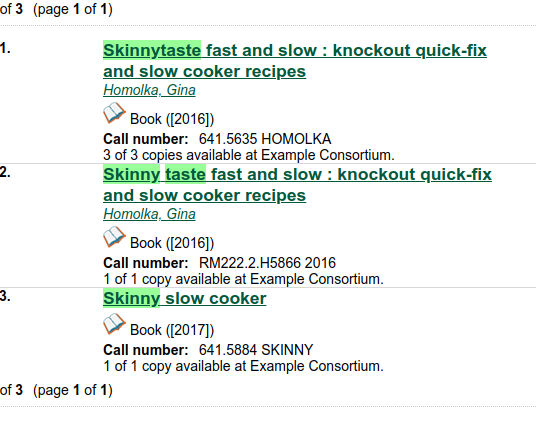
Some issues I found with thesaurus dictionaries
- When doing a thesaurus dictionary to allow a one-word term (skinnytaste) to be searched as two words (skinny taste), a match may be retrieved even if one of the search words is outside the class that is searched.
- There was some inconsistent highlighting that I'm still trying to nail down.
Reingest
More on dictionaries
- Other Postgres dictionaries can be created following similar instructions as the ones to implement a thesaurus.
- Synonym dictionary
- Stop words - USE WITH CAUTION
- It
- A is for Alibi
- The the
- https://www.postgresql.org/docs/9.5/static/textsearch-dictionaries.html
Questions?
Brush Up Your Evergreen Search
By Kathy Lussier



