Le modèle d'acteur
Fil rouge
Gestion des documents
Objectifs
- Créer des documents
- Gérer les versions des documents
- Gérer les accès des documents
- Gérer la validation des documents
Gestion des documents
Étape 1 :
Le processus de validation des documents
Étape 1
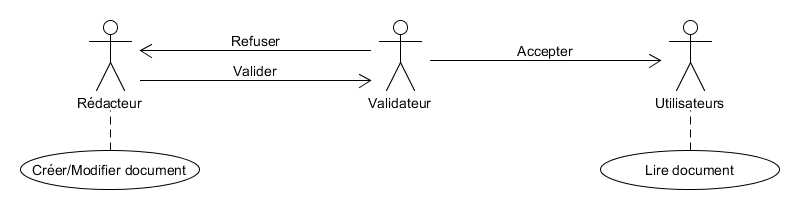
Gestion des documents
Étape 2 :
Comment peut-on modéliser ce fonctionnement ?
Étape 2 :
Version 1 : Par module
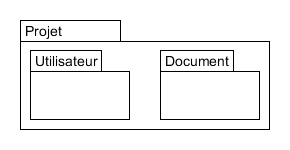
Étape 2 :
Version 2 : Par couche
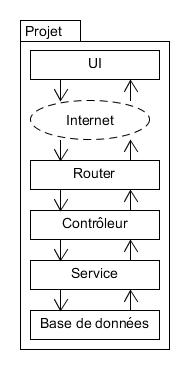
Étape 2 :
Version 3 : Par fonction
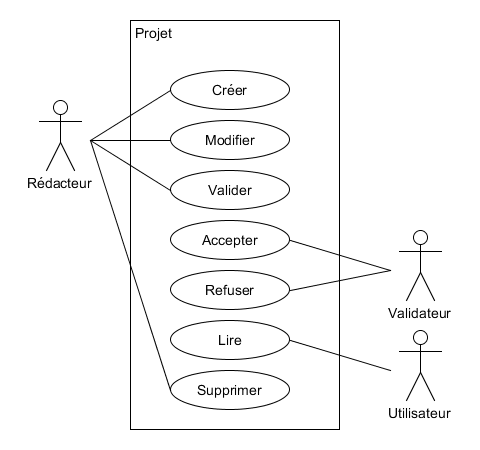
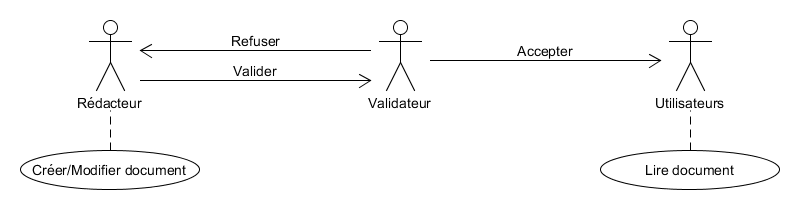
Étape 2 :
Version 4 : Par acteur
Gestion des documents
Étape 3 :
Et la technique dans tout ça ?
Étape 3
L'étape précédente permet de concevoir d'un point de vue fonctionnel le problème, mais comment peut-on le développer ?
La conception se concentrera ici sur l'organisation des acteurs
Étape 3
Version 1 : Par les fonctions

Avantages
- Très facile de savoir ce que peut faire chaque acteur
- Représente souvent l'organisation de l'entreprise
Inconvénients
- Si l'application grossit, il sera difficile de maintenir le système avec des acteurs « atomiques »
- Si un utilisateur a plusieurs rôles, comment combiner les modèles d'acteurs ?
- Peu adapté à un fonctionnement requête client/serveur (l'acteur n'existe que durant la requête ?)
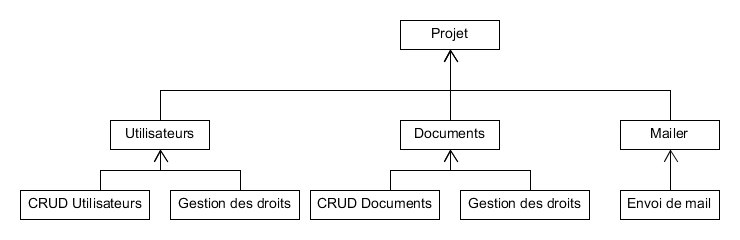
Étape 3
Version 1 : Par les fonctions
Étape 3
Version 2 : Par les services
Avantages
- Approche plus classique permettant un passage progressif sur ce modèle
Inconvénients
- Risques de retomber dans les pièges de la conception classique
- Gestion des autorisations ?
- Risques de blocage inutile du système
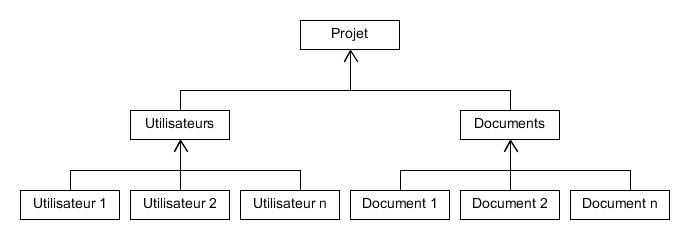
Étape 3
Version 2 : Par les services
Étape 3
Version 3 : Par les données
Avantages
- Très facile de comprendre la modélisation des données
- Gestion des contraintes sur les données aisée
- Gestion des états des données simplifiée
Inconvénients
- Difficile de visualiser les opérations de chacun des utilisateurs
- Gestion des autorisations ?
Étape 3
Version 3 : Par les données
Avis personnel : Conception recommandée pour débuter
Étape 3
Le mieux, c'est de mixer
le tout selon les besoins
Gestion des documents
Étape 4 :
Système de workflow : Les FSM
Étape 4

Étape 4
// How this code is usually written with classic services?
class documentService {
create(document) {
// persist document
}
update(id, newDocument) {
const document = this._find(id);
if (!document.isValidating && !document.isBroadcasted) {
// persist newDocument
}
}
validate(id) {
const document = this._find(id);
if (!document.isValidating && !document.isBroadcasted) {
document.isValidating = true;
// persist document
}
}
accept(id) {
const document = this._find(id);
if (document.isValidating && !document.isBroadcasted) {
document.isBroadcasted = true;
// persist
}
}
refuse(id) {
const document = this._find(id);
if (document.isValidating && !document.isBroadcasted) {
document.isValidating = false;
// persist
}
}
read(id) {
const document = this._find(id);
if (document.isBroadcasted) {
return document;
}
}
delete(id) {
const document = this._find(id);
if (document.isBroadcasted) {
// remove document
}
}
_find(id) {/*…*/}
}Étape 4
// How this code should be written?
// Use of my personal FSM library (https://github.com/kneelnrise/fms-js)
function getFSM(id) {
const fsm = k.fsm.create((fsm) => {
fsm.when("draft", (state) => {
state.on("update", (data, newDocument) => {
return ["draft", newDocument];
});
state.on("validate", (data) => {
return ["validating", data];
});
});
fsm.when("validating", (state) => {
state.on("accept", (data) => {
return ["broadcast", data];
});
state.on("refuse", (data) => {
return ["draft", data];
});
});
fsm.when("broadcast", (state) => {
state.on("read", (data) => {
return ["broadcast", data];
});
});
// Currently, this function does not exist in the library, but keep the logic in mind
fsm.afterEachEvent((data, state) => {
db.persist({data: data, state: state});
});
// We initialize our FSM from saved item
const saved = db.find(id);
fsm.startWith(saved.state, saved.data);
});
}Avantages
- Plus grande maîtrise des états de la données
- Conception et code proche
- Facilité de maintenance
Inconvénients
- La donnée doit vivre pour pouvoir utiliser ce design pattern (inadapté aux requêtes client/serveur basiques)
Étape 4
Gestion des documents
Étape 5 :
Communication entre les acteurs
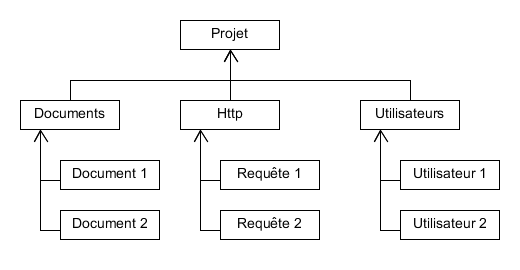
Étape 5
Organisation des acteurs
Étape 5
Messages échangés
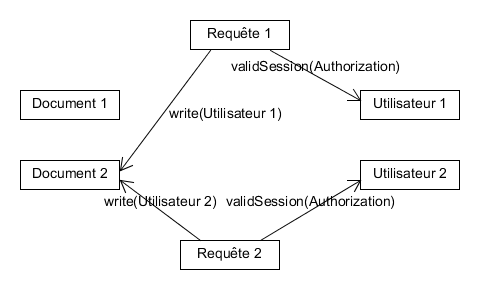
Étape 5
Comment contacter l'acteur
- Boite à lettres
- Adresse logique de l'acteur
- Adresse physique de l'acteur
- => Répartition sur plusieurs serveurs
Gestion des documents
Étape 6 :
Une opération à la fois
Étape 6
Cas d'étude
- Nom de document unique
- Transaction (traitements) longue avant la diffusion
- La transaction peut échouer en raison de contraintes métiers
- La transaction dure entre 1s et 10s
Étape 6
Cas 1 : Nom de document unique
Quel serait votre code ?
-
Contraintes pour ce cas :
- Le SGBD n'a aucune notion de transaction
- Le SGBD n'a aucune notion de contraintes sur les données (ex : colonne UNIQUE)
Java / JEE
Étape 6
Cas 1 : Nom de document unique
Javascript / ES-2015
@Local
class DocumentService {
@PersistentContext
private EntityManager em;
public void create(Document document) {
List<Document> existing = em.createQuery(
"SELECT d FROM Document d WHERE d.name = :name",
Document.class
)
.setParameter("name", document.getName())
.getResultList();
if (existing.size() > 0) {
em.persist(document);
}
}
}// global db
class DocumentService {
create(document) {
db.find({name: document.name}).then((existing) => {
if (!existing) {
em.persist(document);
}
});
}
}Étape 6
Cas 1 : Nom de document unique
Problème :
Ce code fonctionne, mais dans le cas ou deux documents sont insérés en base en même temps ?
- Vérification 1 : Le document n'existe pas
- Vérification 2 : Le document n'existe pas
- Insertion 1 : Le document n'existe pas
- Insertion 2 : Le document existe…
Le problème survient dès qu'il y a parallélisme, réparti sur un ou plusieurs serveur(s).
Étape 6
Cas 1 : Nom de document unique
Solution :
Ne réaliser qu'une seule opération d'insertion à la fois.
Bloquer les autres tant qu'elle n'est pas terminée.
Attention à ne pas bloquer le système !
Remarque : Cette gestion devrait être gérée par le framework ou langage, pas par le développeur
Étape 6
Cas 2 : Transaction longue avant la diffusion
- Rappel des contraintes :
- La transaction peut échouer en raison de contraintes métiers
- La transaction dure entre 1s et 10s
Pour ce cas, nous pouvons avoir un SGBD avec la notion de transaction (ex: Oracle).
Étape 6
Cas 2 : Transaction longue avant la diffusion
- Transaction SGBD :
- Risque de bloquer une table entière pour ne traiter qu'un document
- Modifier le document et revenir sur la version précédente en cas d'échec ?
- Risques que les autres opérations impacte le document en cours ?
Étape 6
Cas 2 : Transaction longue avant la diffusion
Solution :
Chaque document est un acteur : Une seule opération à la fois par document (on ne bloque qu'un document)
Correct du point de vue métier : Deux utilisateurs ne devraient pas modifier le même document à la fois
Remarque : pour la persistence, se renseigner sur la notion de « insert only » (CR).
Gestion des documents
Étape 7 :
Supervision
Étape 7
Let it crash!
Fait inéluctable : L'application va crasher
Comment faire pour que notre application continue de répondre, même quand elle crash ?
Avantages
- Si un serveur tombe, un autre prend le relais
Inconvénients
- Gestion des erreurs dues aux ressources (DB, API externe) ?
- Comment redémarrer le serveur ?
- Gestion des requêtes en cours ?
- Parallélisme des tâches (Cf. étape 6)
Étape 7
Solution 1 : Duplication
Étape 7
Solution 2 : Supervision
La supervision consiste à déléguer les cas que notre acteur ne sait pas gérer à son supérieur.
- Gestion des erreurs
- Gestion des exceptions
- Gestion des crashes
Un supérieur racine : Se doit de maintenir le système en vie !
Avantages
- Centralisation des erreurs
- Le supérieur a un aperçu global de ses subordonnés :
- Recul
- Peut choisir la meilleure stratégie selon le contexte
- Avantages du système d'acteurs gardés
Inconvénients
- Plus difficile à réaliser
- Définir la/les stratégie(s)
- Les implémenter
Étape 7
Solution 2 : Supervision
Gestion des documents
Étape 8 :
Distributivité
Étape 8
Rappels
- Les acteurs sont atomiques
- Indépenance directe des autres acteurs
- Les acteurs communiquent par message
- Adresse logique
- Les acteurs sont supervisés par un autre acteur
- Avec le même système de communication
Conclusion
Le modèle même est par nature distribuable !
Gestion des documents
Conclusion
Avantages
- Isolation des composants
- Gestion de la concurrence
- Capacité d'auto-guérison
- Faible couplage
- Distributivité
- Parfait pour les DevOps
- Utilisé par des gros acteurs comme Twitter
- Akka, framework basé sur ce modèle, en scala, java et C#
- Erlang, language basé sur ce modèle.
Inconvénients
- Peu de langages et frameworks
- Assez opposé aux conceptions apprises dans les centres de formation
- Très bas niveau
- Non adaptés aux développements UI
Conclusion
Conclusion
Webographie
- (fr) https://fr.wikipedia.org/wiki/Mod%C3%A8le_d%27acteur
- (en) https://en.wikipedia.org/wiki/Actor_model
- (en) http://akka.io
- (en) https://rocketeer.be/articles/concurrency-in-erlang-scala
- (en) http://ijcai.org/Past%20Proceedings/IJCAI-73/PDF/027B.pdf
- (en) https://www.typesafe.com/blog/7-ways-washing-dishes-and-message-driven-reactive-systems
- (en) http://www.brianstorti.com/the-actor-model/
- Et Twitter pour tous les articles partagés sur le sujet
Le modèle d'acteur
By Gaëtan Rizio
Le modèle d'acteur
Ce diaporama permet de présenter le modèle d'acteur en partant des conceptions classiques.



