Deep Learning Code Fragments for Code Clone Detection
Martin White, Michele Tufano, Christopher Vendome, and Denys Poshyvanyk

Code Clones
A code fragment is a contiguous segment of source code. Code clones are two or more fragments that are similar with respect to a clone type.
Type I Clones
Identical up to variations in comments, whitespace, or layout [Roy'07]
if (a >= b) {
c = d + b; // Comment1
d = d + 1;}
else
c = d - a; //Comment2if (a>=b) {
// Comment1'
c=d+b;
d=d+1;}
else // Comment2'
c=d-a;if (a>=b)
{ // Comment1''
c=d+b;
d=d+1;
}
else // Comment2''
c=d-a;Type II Clones
Identical up to variations in names and values, comments, etc. [Roy'07]
if (a >= b) {
c = d + b; // Comment1
d = d + 1;}
else
c = d - a; //Comment2if (m >= n)
{ // Comment1'
y = x + n;
x = x + 5; //Comment3
}
else
y = x - m; //Comment2'A parameterized clone for this fragment is
Type III Clones
Modifications include statement(s) changed, added, or deleted [Roy'07]
public int getSoLinger() throws SocketException {
Object o = impl.getOption(SocketOptions.SO_LINGER);
if (o instanceof Integer) {
return((Integer) o).intValue();
}
else return -1;
}public synchronized int getSoTimeout() // This statement is changed
throws SocketException {
Object o = impl.getOption(SocketOptions.SO_TIMEOUT);
if (o instanceof Integer) {
return((Integer) o).intValue();
}
else return -0;
}Type IV Clones
Syntactically dissimilar fragments with similar functionality [Roy'07]
int i, j=1;
for (i=1; i<=VALUE; i++)
j=j*i;int factorial(int n) {
if (n == 0) return 1 ;
else return n * factorial(n-1) ;
}
Now consider a recursive function that calculates the factorial
Code Clone Detection
- An important problem for software maintenance and evolution
- Detecting library candidates
- Aiding program comprehension
- Detecting malicious software
- Detecting plagiarism or copyright infringement
- Detecting context-based inconsistencies
- Searching for refactoring opportunities
- Different techniques for detecting code clones
Code Clone Detection Techniques
Techniques can be classified by their source code representation
- Text. Apply slight transformations; compare sequences of text
- Token. Lexically analyze the code; compare subsequences of tokens
- Metrics. Gather different metrics for fragments; compare them
- Tree. Measure similarity of subtrees in syntactical representations
- Graph. Consider the semantic information of the source code
Motivation
- Many approaches consider either structure or identifiers but none of the existing techniques model both sources of information
public int getSoLinger() throws SocketException {
Object o = impl.getOption(SocketOptions.SO_LINGER);
if (o instanceof Integer) {
return((Integer) o).intValue();
}
else return -1;- They depend on generic, handcrafted features to represent code
- Frequency of keywords
- Indentation pattern
- Length of source code line
- Number of shared/different AST nodes
- q-Level atomic tree patterns in parse trees
- Frequency of semantic node types in PDGs
- Geometry characteristics of CFGs
Our new set of techniques fuse and use
Learning-based Paradigm
- Learn. Induce compositional representations of code; compare
- Distinguished from token-based techniques; maps terms to continuous-valued vectors and uses context
- Distinguished from tree-based techniques; operates on identifiers and learns discriminating features
Why deep learning?
- Synchronizes the source code representation with the manner in which the code is conceptually organized
- Deep learning algorithms are compositional
- Source code is compositional
- Three apparent advantages over Latent Semantic Analysis
- Autoencoders are nonlinear dimensionality reducers
- Operates with several nonlinear transformations
- Recursion considers the order of terms
- Can recognize similarities among terms
Learning-based Code Clone Detection
Our approach couples deep learners to front end compiler stages
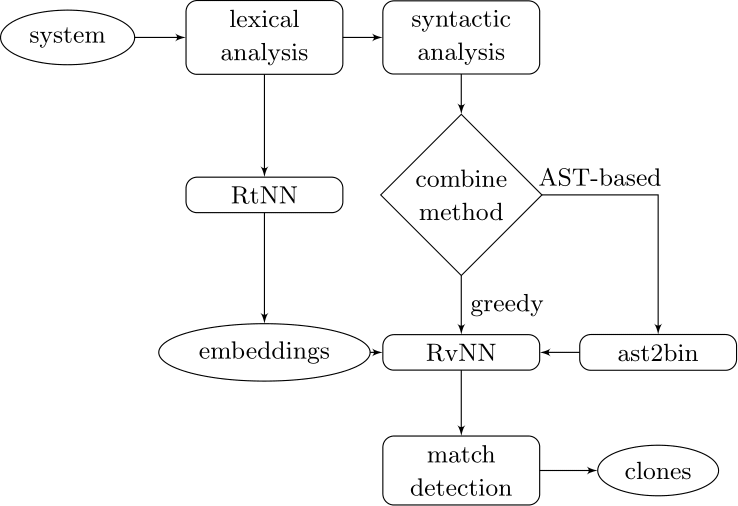
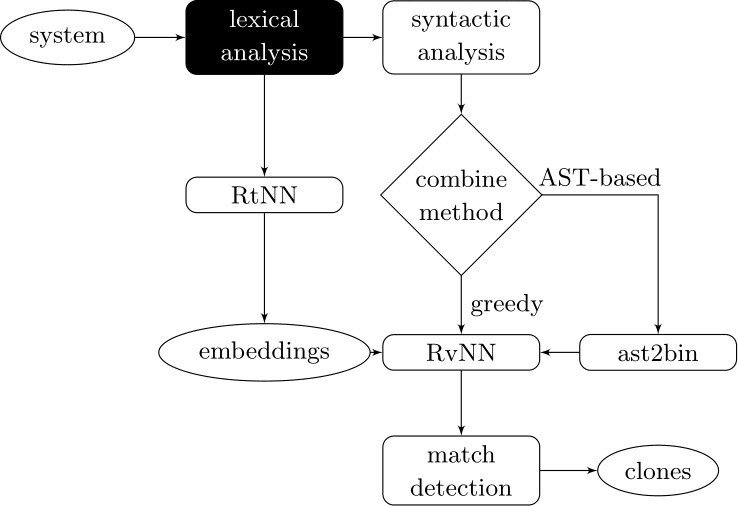
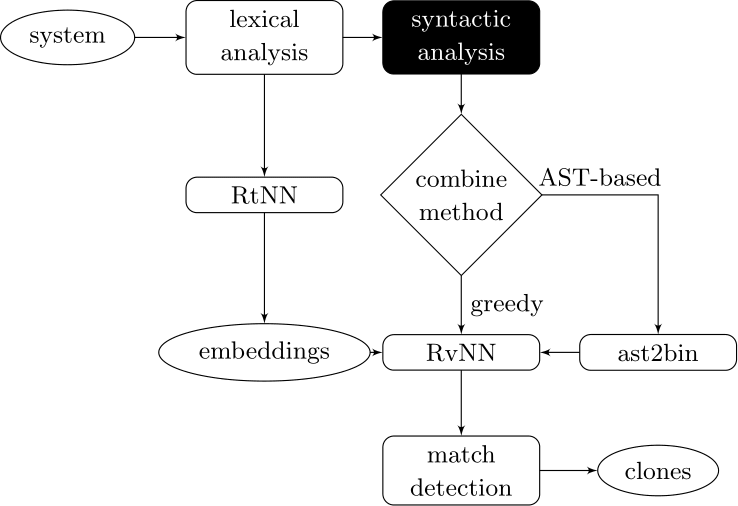
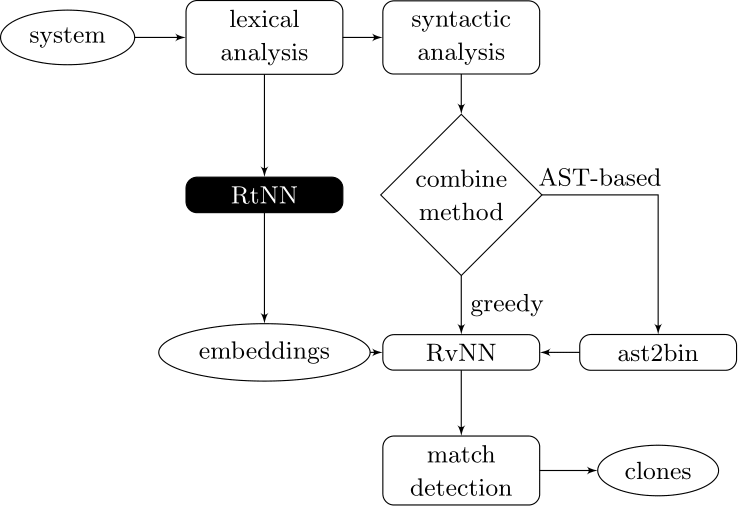
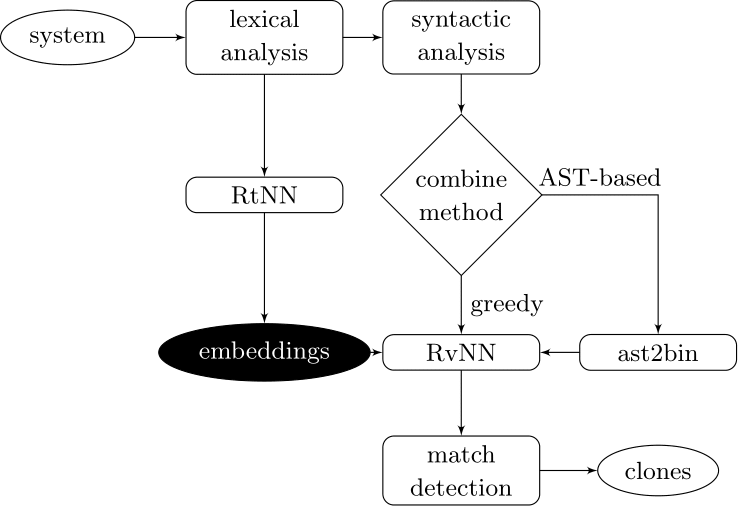
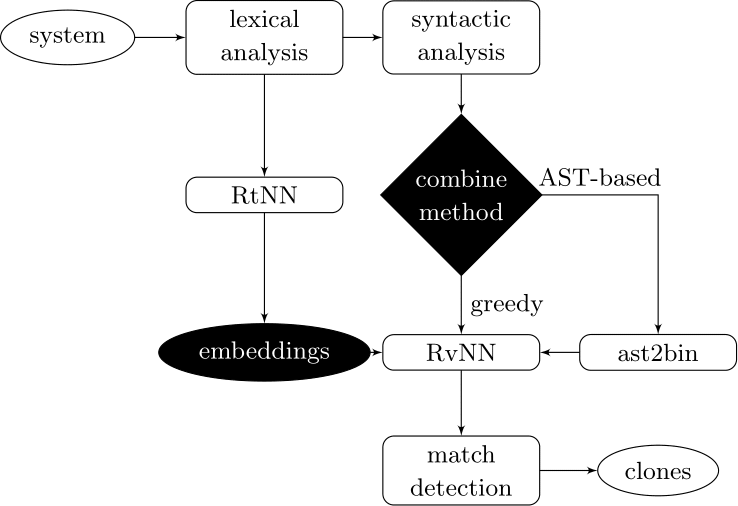
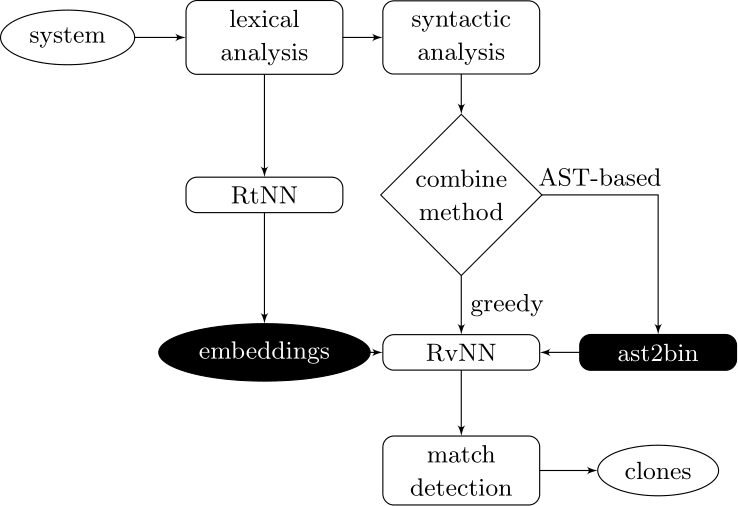
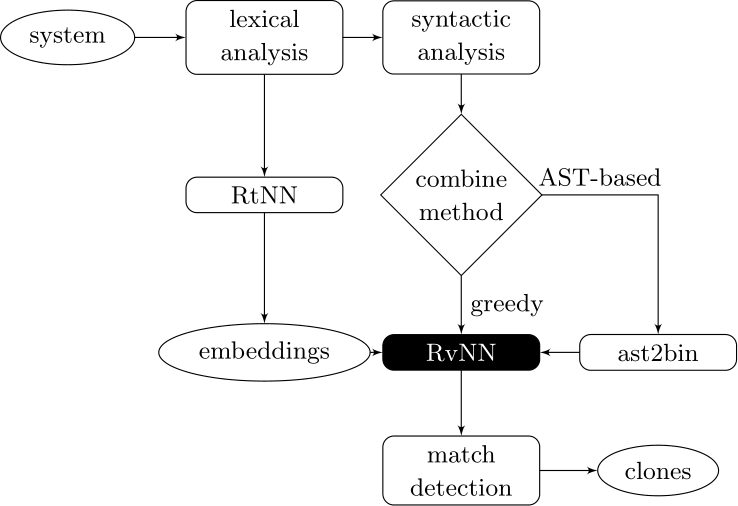
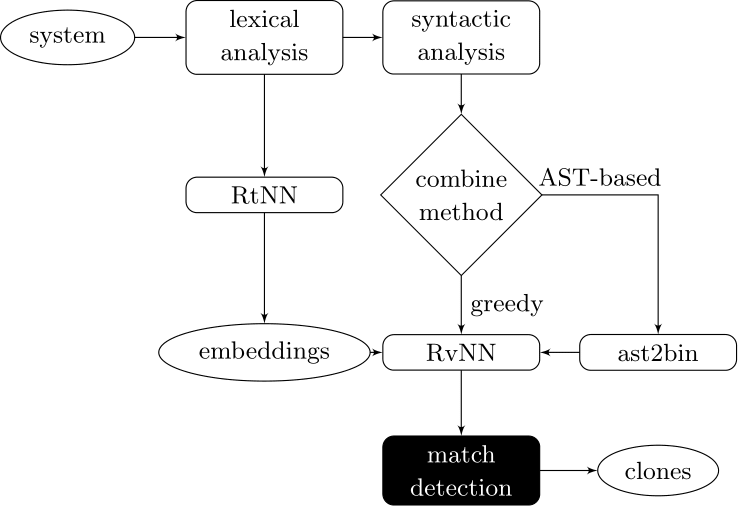
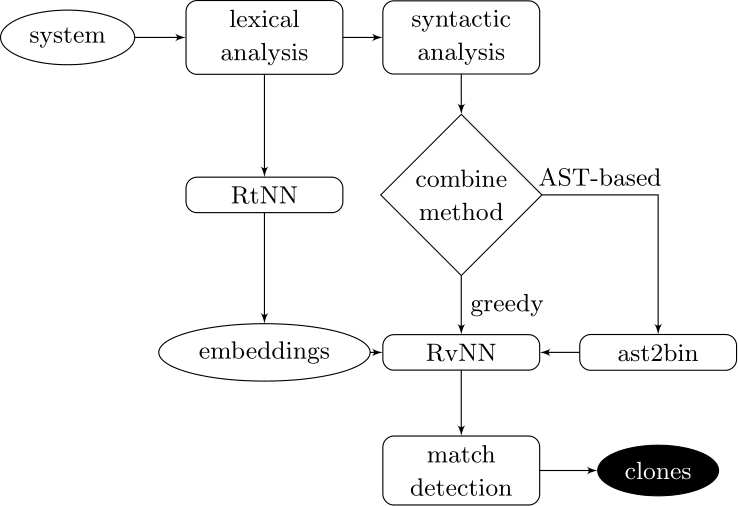
ast2bin
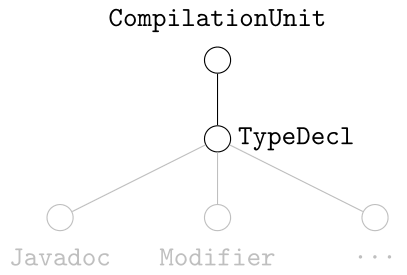
ASTs can have any number of levels comprising nodes with arbitrary degree. ast2bin fixes the size of the input, and recursion models different levels.

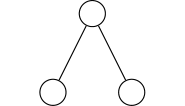
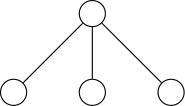
Case I
Case II
Case II
Use a grammar to handle nodes with degree greater than two
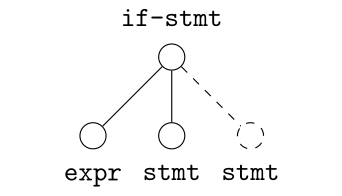
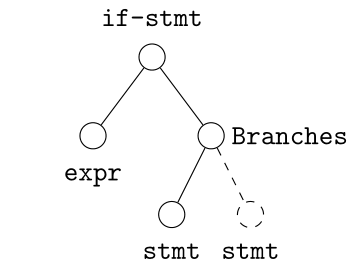
Case I
- TypeDeclaration
- MethodDeclaration
- OtherType
- ExpressionStatement
- QualifiedName
- SimpleType
- SimpleName
- ParenthesizedExpression
- Block
- ArtificialType
Establish a precedence to handle nodes with degree one
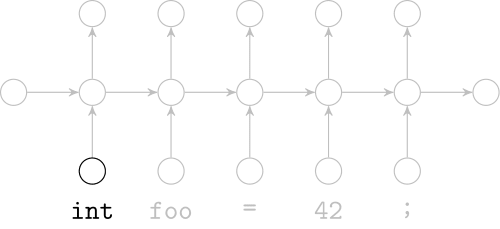
Recurrent Neural Networks
Effectively model sequences of terms in a source code corpus
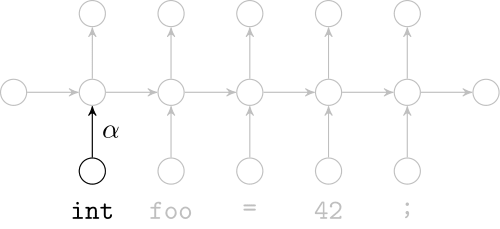
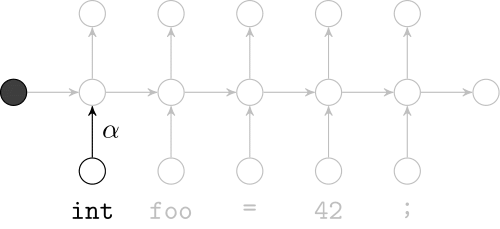
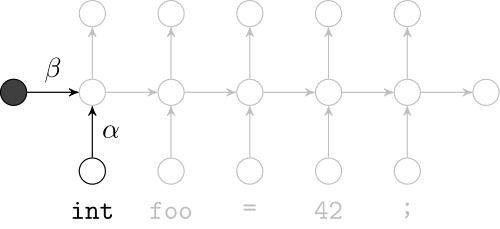
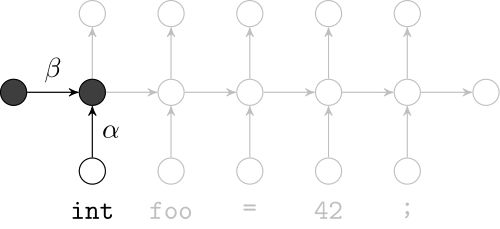
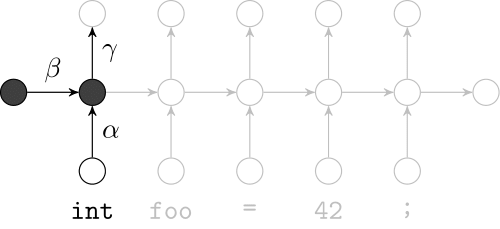
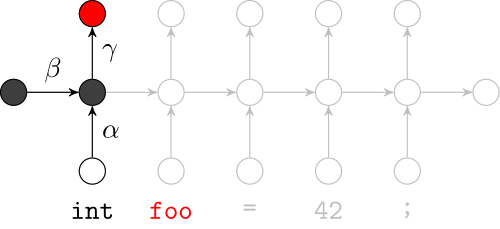
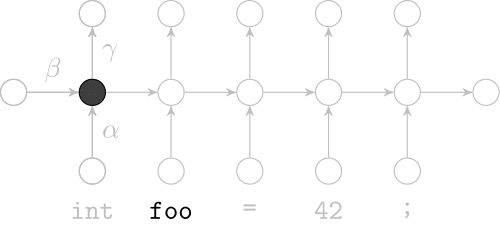
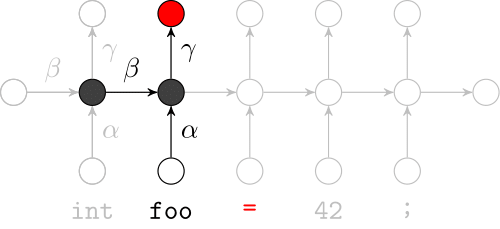
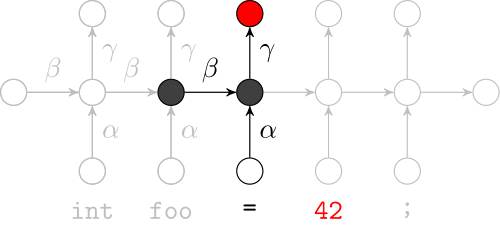
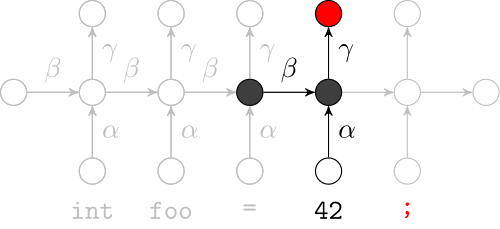
Deep Learning Code at the Lexical Level
We use a recurrent neural network to map terms to embeddings
y(i)=g(\gamma f({\color{red}\alpha} t(i)+\beta z(i-1)))
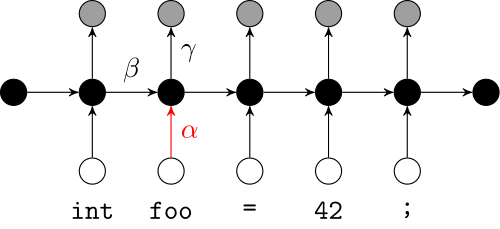
What we would like to have is not only embeddings for terms but also embeddings for fragments
\color{white}{y(i)=g(\gamma f({\alpha}} t(i)\color{white}{+\beta z(i-1)))}
\color{white}{y(i)=g(\gamma f(}{\color{red}\alpha} t(i)\color{white}{+\beta z(i-1)))}
\color{white}{y(i)=g(\gamma f(}{\color{red}\alpha} t(i)\color{white}{+\beta} z(i-1)\color{white}{))}
\color{white}{y(i)=g(\gamma f(}{\color{red}\alpha} t(i)\color{white}{+}\beta z(i-1)\color{white}{))}
\color{white}{y(i)=g(\gamma f(}{\color{red}\alpha} t(i)+\beta z(i-1)\color{white}{))}
\color{white}{y(i)=g(\gamma} f({\color{red}\alpha} t(i)+\beta z(i-1))\color{white}{)}
\color{white}{y(i)=g(}\gamma f({\color{red}\alpha} t(i)+\beta z(i-1))\color{white}{)}
\color{white}{y(i)=}g(\gamma f({\color{red}\alpha} t(i)+\beta z(i-1)))
y(i)=g(\gamma f({\color{red}\alpha} t(i)+\beta z(i-1)))
Recursive Autoencoders
Generalize recurrent neural networks by modeling structures
Deep Learning Code at the Syntax Level
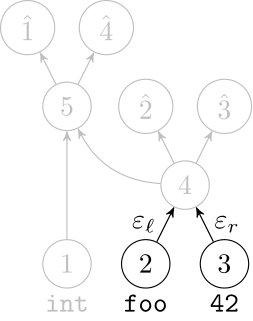
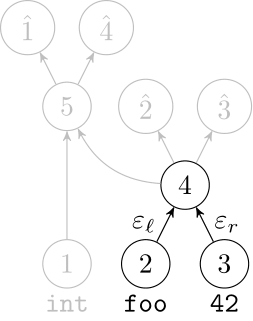
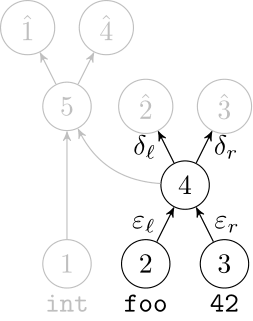
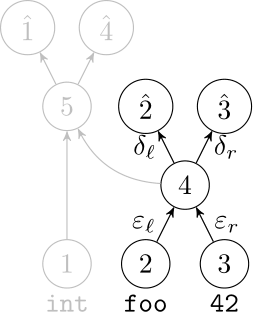
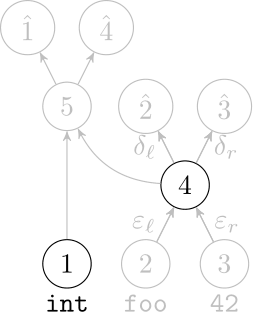
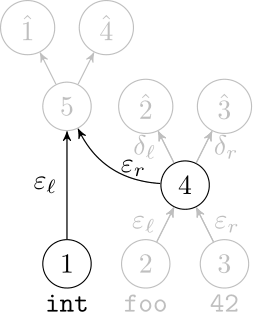
We use a recursive autoencoder to encode sequences of embeddings
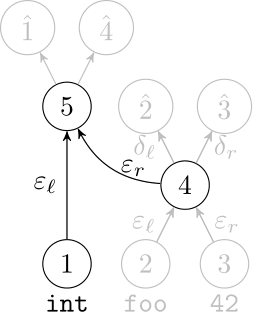
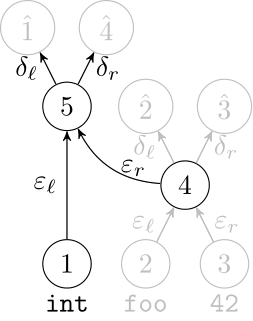
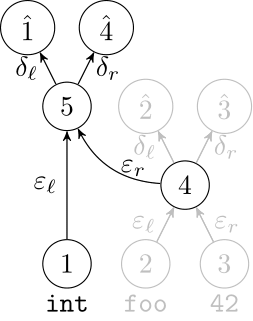
y=[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r] f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r]))
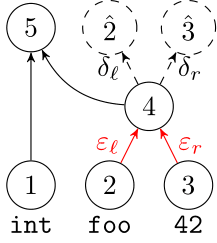
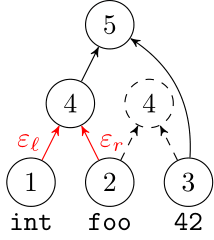
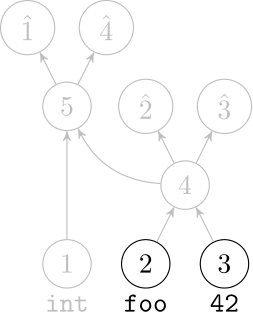
AST-based encoding
Greedy encoding
y=[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r] f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r]))
\color{white}{y=[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r] f([{\varepsilon_{\ell}},{\varepsilon_{r}}]} [x_{\ell};x_r]\color{white}{))}
\color{white}{y=[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r] f(}[\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r]\color{white}{))}
\color{white}{y=[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r]} f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r])\color{white}{)}
\color{white}{y=[\hat{x_{\ell}};\hat{x_{r}}]=g(}[\delta_{\ell};\delta_r] f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r])\color{white}{)}
\color{white}{y=[\hat{x_{\ell}};\hat{x_{r}}]=}g([\delta_{\ell};\delta_r] f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r]))
\color{white}{y=}[\hat{x_{\ell}};\hat{x_{r}}]=g([\delta_{\ell};\delta_r] f([\color{red}{\varepsilon_{\ell}},\color{red}{\varepsilon_{r}}] [x_{\ell};x_r]))
Empirical Validation
- Research Questions
- Are our representations suitable for detecting fragments that are similar with respect to a clone type?
- Is there evidence that our learning-based approach is capable of recognizing clones that are undetected or suboptimally reported by a structure-oriented technique?
- Estimated precision at different levels of granularity to answer RQ1; synthesized qualitative data across two techniques for RQ2
- Data Collection Procedure
- ANTLR, RNNLM Toolkit, Eclipse JDT
- Generated both file- and method-level corpora
-
Analysis Procedure
- Two Ph.D. students evaluated file- and method-level samples
- We adapted a taxonomy of editing scenarios [Roy'09]
| System | Files | LOC | Tokens | |V| |
| ANTLR 4 | 514 | 104,225 | 701,807 | 5,826 |
| Apache Ant 1.9.6 | 1,218 | 136,352 | 888,424 | 16,029 |
| ArgoUML 0.34 | 1,908 | 177,493 | 1,172,058 | 17,205 |
| CAROL 2.0.5 | 184 | 12,022 | 80,947 | 2,210 |
| dnsjava 2.0.0 | 196 | 24,660 | 169,219 | 3,012 |
| Hibernate 2 | 555 | 51,499 | 365,256 | 5,850 |
| JDK 1.4.2 | 4,129 | 562,120 | 3,512,807 | 45,107 |
| JHotDraw 6 | 984 | 58,130 | 377,652 | 4,803 |
Subject Systems
| System | Files | LOC | Tokens | |V| |
| ANTLR 4 | 514 | 104,225 | 701,807 | 5,826 |
| Apache Ant 1.9.6 | 1,218 | 136,352 | 888,424 | 16,029 |
| ArgoUML 0.34 | 1,908 | 177,493 | 1,172,058 | 17,205 |
| CAROL 2.0.5 | 184 | 12,022 | 80,947 | 2,210 |
| dnsjava 2.0.0 | 196 | 24,660 | 169,219 | 3,012 |
| Hibernate 2 | 555 | 51,499 | 365,256 | 5,850 |
| JDK 1.4.2 | 4,129 | 562,120 | 3,512,807 | 45,107 |
| JHotDraw 6 | 984 | 58,130 | 377,652 | 4,803 |
| System | Files | LOC | Tokens | |V| |
| ANTLR 4 | 514 | 104,225 | 701,807 | 5,826 |
| Apache Ant 1.9.6 | 1,218 | 136,352 | 888,424 | 16,029 |
| ArgoUML 0.34 | 1,908 | 177,493 | 1,172,058 | 17,205 |
| CAROL 2.0.5 | 184 | 12,022 | 80,947 | 2,210 |
| dnsjava 2.0.0 | 196 | 24,660 | 169,219 | 3,012 |
| Hibernate 2 | 555 | 51,499 | 365,256 | 5,850 |
| JDK 1.4.2 | 4,129 | 562,120 | 3,512,807 | 45,107 |
| JHotDraw 6 | 984 | 58,130 | 377,652 | 4,803 |
Empirical Results - RQ1
- Are our representations suitable for detecting fragments that are similar with respect to a clone type?
- Sampled 398 from 1,500+ file pairs, 480 from 60,000+ method pairs
| System | AST-based | Greedy | AST-based | Greedy |
| ANTLR | 97 | 100 | 100 | 100 |
| Apache Ant | 92 | 93 | 100 | 100 |
| ArgoUML | 90 | 100 | 100 | 100 |
| CAROL | 100 | 100 | 100 | 100 |
| dnsjava | 47 | 100 | 73 | 87 |
| Hibernate | 100 | 100 | 53 | 70 |
| JDK | 90 | 100 | 100 | 100 |
| JHotDraw | 100 | 100 | 100 | 100 |
File-level
Method-level
Precision Results (%)
Empirical Results - RQ2
- Is there evidence that our compositional, learning-based approach is capable of recognizing clones that are undetected or suboptimally reported by a traditional, structure-oriented technique?
- For a structure-oriented technique, we selected the prominent tool Deckard [Jiang'07]
- Suboptimally reported: jhotdraw0
- Undetected: hibernate0
- We posted more examples in our online appendix
Conclusion
- Learning-based Clone Detection
- structure + identifiers =
Handcrafted features
- Deep Learning Code Fragments
- Language modeling
- Recursive learning
- Empirical Study
- 93% evaluated true positives
- Undetected, suboptimally reported
- Key Findings
- Reordered decls and stmts, etc.
- Lessons learned
Recurrent Neural Network
AST-based
Greedy
clones
By martingwhite
clones
ASE 2016

