Szybkie wyszukiwanie pełnotekstowe z ElasticSearch'em
Marcin Stachniuk
23 kwietnia 2016

Marcin Stachniuk

Chorąży na chamberconf.pl
Speaker: WrocJUG, dbconf.pl, devcrowd.pl

Recenzent książki: practicalunittesting.com



You Know, for Search…
Agenda
- Instalacja
- Operacje CRUD
- Wyszukiwanie
- Filtrowanie
- Jak to wszystko działa?
- Agregacje
- Sugestie
- ElasticSearch i Java
- Ekosystem
Instalacja ElasticSearch'a
1. Ściągnij i rozpakuj, lub skorzystaj z homebrew
brew install elasticsearch2. Uruchom
bin/elasticsearchbin/elasticsearch.batlub
3. I działaj
curl -X GET http://localhost:9200/{
"status": 200,
"name": "Stiletto",
"cluster_name": "elasticsearch",
"version": {
...
"lucene_version": "4.10.4"
},
"tagline": "You Know, for Search"
}Wersje ElasticSearch'a

28.10.2015
05.04.2016
25.06.2015
Przykłady testowane na: 1.7.2
4. Warto doinstalować Sense (Beta) Chrome plugin

Instalacja ElasticSearch'a
Podstawowe pojęcia
| Elasticsearch | SQL |
|---|---|
| Index | Schema |
| Type | Table |
| Document | Row |
Operacje CRUD
Create
Tworzenie Indexu (opcjonalnie)
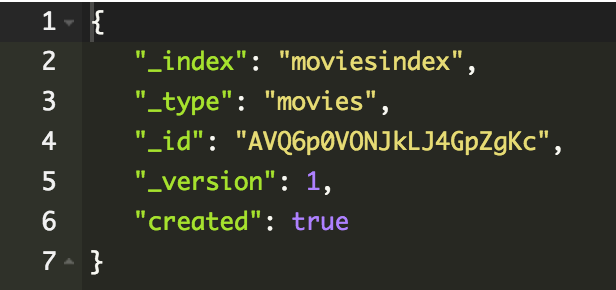
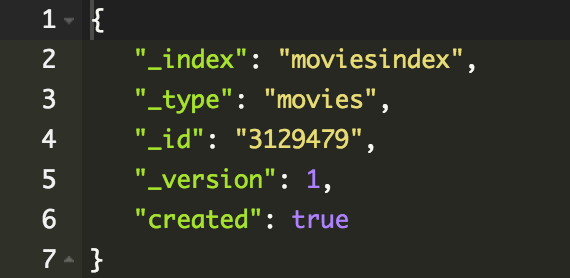
PUT /moviesindexTworzenie dokumentu
POST /moviesindex/movies
{
"movieid": 2761502,
"title": "Pulp Fiction",
"year": "1994",
"imdbid": null
}PUT /moviesindex/movies/3129479
{
"movieid": 3129479,
"title": "Matrix",
"year": "1999",
"imdbid": "tt0133093"
}

Operacje CRUD
Read
Odczytywanie dokumentu
GET /moviesindex/movies/3129479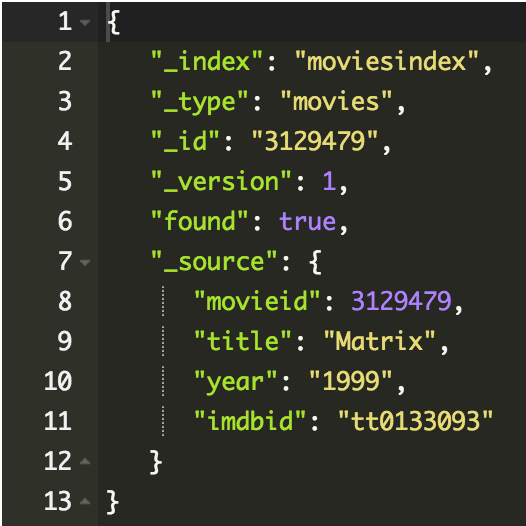
Operacje CRUD
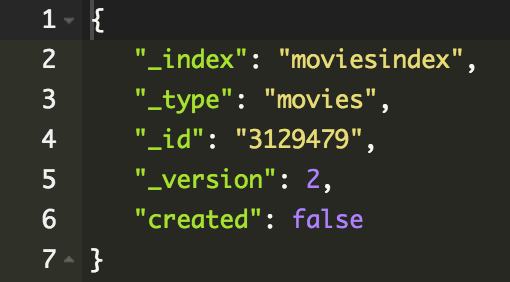
Update
Modyfikacja danego dokumentu (usunięcie i dodanie
na nowo)
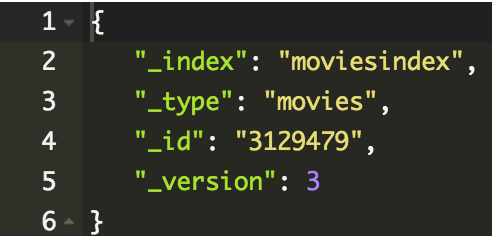
PUT /moviesindex/movies/3129479
{
"movieid": 3129479,
"title": "Matrix Matrix Matrix",
"year": "1999",
"imdbid": "tt0133093"
}Częściowa aktualizacja
POST /moviesindex/movies/3129479/_update
{
"doc" : {
"imdbid": "tt42"
}
}
Operacje CRUD
Delete
Usunięcie
DELETE /moviesindex/movies/3129479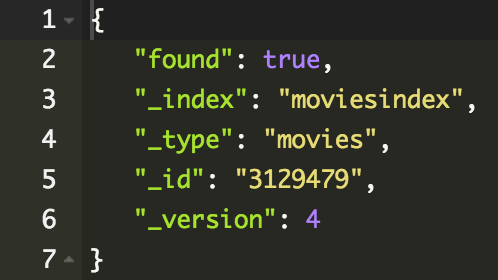
Wyszukiwanie w bazie JMDB
Java Movies Data Base
Wyszukiwanie
URI Search
GET /esmd/movie/_search?q=title:matrixTerm Query
POST /esmd/movie/_search
{
"query" : {
"term" : { "title" : "matrix" }
}
}Term Query, full text search
POST /esmd/movie/_search
{
"query" : {
"term" : { "_all" : "matrix" }
}
}Wyszukiwanie
Match query
POST /esmd/movie/_search
{
"query": {
"match": {
"title": {
"query": "matrix revolution",
"operator": "or"
}
}
}
}Wyszukiwanie
Multi Match Query
POST /esmd/movie/_search
{
"query": {
"multi_match" : {
"query": "2012",
"fields": [ "title", "year" ]
}
}
}Multi Match Query
POST /esmd/movie/_search
{
"query": {
"multi_match" : {
"query": "2012",
"fields" : [ "title^3", "*id" ]
}
}
}Wyszukiwanie
Bool query
POST /esmd/movie/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": {
"query": "american pie",
"operator": "and"
}
}
},
"should": [
{
"term": {
"year": {
"value": "2010"
}
}
}
]
}
}
}Wyszukiwanie
Fuzzy query
POST /esmd/movie/_search
{
"query" : {
"fuzzy" : { "title" : "matrixx" }
}
}Domyślne odległości dla tekstów
- 0..1 - musi pasować dokładnie
- 1..5 - możliwa jedna edycja
- >5 - możliwe dwie edycje
Wyszukiwanie
Query string query
POST /esmd/movie/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "this AND that OR thus"
}
}
}Query string query
POST /esmd/movie/_search
{
"query": {
"query_string": {
"query": "(title:this OR plot:this) AND (title:that OR plot:that)"
}
}
}Wyszukiwanie
Reqexp query
POST /esmd/movie/_search
{
"query": {
"regexp": {
"title": "a.*q"
}
}
}Wyszukiwanie
Poświetlanie znalezionego fragmentu
POST /esmd/movie/_search
{
"query": {
"term": {
"plot": "matrix"
}
},
"highlight": {
"fields": {
"title": {
"type": "plain",
"force_source" : true
},
"plot": {
"type": "plain",
"force_source" : true
}
}
}
}
Wyszukiwanie - wszystkie query
Match Query
Multi Match Query
Bool Query
Boosting Query
Common Terms Query
Constant Score Query
Dis Max Query
Filtered Query
Fuzzy Like This Query
Fuzzy Like This Field Query
Function Score Query
Fuzzy Query
GeoShape Query
Has Child Query
Has Parent Query
Ids Query
Indices Query
Match All Query
More Like This Query
Nested Query
Prefix Query
Query String Query
Simple Query String Query
Range Query
Regexp Query
Span First Query
Span Multi Term Query
Span Near Query
Span Not Query
Span Or Query
Span Term Query
Term Query
Terms Query
Top Children Query
Wildcard Query
Minimum Should Match
Multi Term Query Rewrite
Template Query
Filtrowanie
- szybsze niż zwykłe zapytania (o rząd wielkości)
- nie ma wyliczania punktacji
- większość z nich jest automatycznie cache'owa
- do wyszukiwania gdzie odpowiedzą jest tak/nie
- do zapytań o dokładną wielkość
Kiedy używać?
Filtrowanie
Term Filter
POST /esmd/movie/_search
{
"filter": {
"term": {
"year": "2017"
}
}
}Filtrowanie
Range filter
POST /esmd/movie/_search
{
"filter": {
"range": {
"year": {
"from": 1889,
"to": 1890
}
}
}
}Wszystkie filtry
And Filter
Bool Filter
Exists Filter
Geo Bounding Box Filter
Geo Distance Filter
Geo Distance Range Filter
Geo Polygon Filter
GeoShape Filter
Geohash Cell Filter
Has Child Filter
Has Parent Filter
Ids Filter
Indices Filter
Limit Filter
Match All Filter
Missing Filter
Nested Filter
Not Filter
Or Filter
Prefix Filter
Query Filter
Range Filter
Regexp Filter
Script Filter
Term Filter
Terms Filter
Type Filter
Jak to wszystko działa?
- Standard dla bibliotek wyszukiwania
- Open Source
- Odwrócony index (inverted index)
Odwrócony index
1. The quick brown fox jumped over the lazy dog
2. Quick brown foxes leap over lazy dogs in summer
Analiza tekstu
1. Tokenizacja tekstu do pojedynczych słów:
The quick brown foxes → [The, quick, brown, foxes]2. Zamiana liter na małe
The → the3. Usuwanie "stopwords"
[The, quick, brown, foxes] → [quick, brown, foxes]Domyślne Angielskie stopwords (link)
a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no,
not, of, on, or, such, that, the, their, then, there, these, they,
this, to, was, will, withJak szukać Szekspira? "To be or not to be"
Analiza tekstu
4. Sprowadzanie do form podstawowych
foxes → fox5. Robienie słów bardziej wyszukiwalnych, np.
John's → john- Francuski
l'église → eglis- Niemiecki
äußerst → ausserst- Angielski
Analiza tekstu
Wsparcie dla języków:
Arabic, Armenian, Basque, Brazilian, Bulgarian, Catalan, Chinese, Czech, Danish, Dutch, English, Finnish, French, Galician, German, Greek, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Korean, Kurdish, Norwegian, Persian, Portuguese, Romanian, Russian, Spanish, Swedish, Turkish, and Thai.
Wsparcie do polskiego za pomocą plugina:
Odwrócony index


Query: quick brown
Obliczanie punktacji
Częstość słów (term frequency)
tf(\text{t in d}) = \sqrt{frequency}
Odwrotna częstość w dokumentach (inverse document frequency)
idf(t) = 1 + log ( \frac{numDocs} {docFreq + 1})
Norma długości pola (field-length norm)
norm(d) = \frac{1} {\sqrt{numTerms}}
Ostatecznie:
Score = \text{ ? } tf() \text{ ? } idf() \text{ ? } norm() \text{ ? }
Obliczanie punktacji
Podgląd punktacji
POST /esmd/movie/_search?explain
{
"query": {
"term": { "title": "matrix" }
}
} "_explanation": {
"value": 4.9666376,
"description": "weight(title:matrix in 21100) [PerFieldSimilarity], result of:",
"details": [
{
"value": 4.9666376,
"description": "fieldWeight in 21100, product of:",
"details": [
{
"value": 1,
"description": "tf(freq=1.0), with freq of:",
"details": [
{
"value": 1,
"description": "termFreq=1.0"
}
]
},
{
"value": 11.352315,
"description": "idf(docFreq=1, maxDocs=62659)"
},
{
"value": 0.4375,
"description": "fieldNorm(doc=21100)"
}
]
}
]
}Trochę o architekturze
Klaster (Cluster) - identyfikowany przez nazwę
- Węzły (Node) - osobny server
- Skorupy ? (Shard) - indeks Lucynki
Typy węzłów:
- Data - przechowują dane
- Client - load balancer
- Master - zarządzanie klastrem
Typy shard'ów:
- primary
- replica
Architektua ElasticSearch'a

Architektua ElasticSearch'a
Zapis

Architektua ElasticSearch'a
Wyszukiwanie


Agregacje
2 typy agregacji:
- metryki - liczenie czegoś na zbiorze dokumentów
- wiaderkowanie? ("Bucketing") - wrzucanie do różnych worków
- Lepsze "facet's" (strony, aspekty?)
- Mogą być zagnieżdżane
Agregacje
Sum Aggregation
POST /esmd/movie/_search
{
"size": 0,
"aggregations" : {
"ammount of votes" : {
"sum" : {
"field": "rating.votes"
}
}
}
}Agregacje
Stats Aggregation
POST /esmd/movie/_search
{
"size": 0,
"aggregations": {
"stats of votes": {
"stats": {
"field": "rating.votes"
}
}
}
}Agregacje
Terms Aggregation
POST /esmd/movie/_search
{
"size": 0,
"aggregations": {
"possible years of movies": {
"terms": {
"field": "year"
}
}
}
}POST /esmd/movie/_search
{
"size": 0,
"aggregations": {
"possible years of movies": {
"terms": {
"field": "year",
"size": 100
}
}
}
}Agregacje
Zagnieżdżone aggregacje
POST /esmd/movie/_search
{
"size": 0,
"aggregations": {
"possible years of movies": {
"terms": {
"field": "year"
},
"aggregations": {
"rank": {
"terms": {
"field": "rating.rank"
}
}
}
}
}
}
Agregacje mogą kłamać
Jak sobie z tym radzić?
Błędy:
- "doc_count_error_upper_bound": 46 (2 + 15 + 29),
- "sum_other_doc_count": 81 (suma pod kreską)
Zwiększenie parametru "size"
- wydajność
Wszystkie agregacje
Min Aggregation
Max Aggregation
Sum Aggregation
Avg Aggregation
Stats Aggregation
Extended Stats Aggregation
Value Count Aggregation
Percentiles Aggregation
Percentile Ranks Aggregation
Cardinality Aggregation
Geo Bounds Aggregation
Top hits Aggregation
Scripted Metric Aggregation
Global Aggregation
Filter Aggregation
Filters Aggregation
Missing Aggregation
Nested Aggregation
Reverse nested Aggregation
Children Aggregation
Terms Aggregation
Significant Terms Aggregation
Range Aggregation
Date Range Aggregation
IPv4 Range Aggregation
Histogram Aggregation
Date Histogram Aggregation
Geo Distance Aggregation
GeoHash grid Aggregation
Sugestie


Sugestie
Term suggester
POST /esmd/_suggest
{
"sugest in title": {
"text": "matri",
"term": {
"field": "title"
}
}
}Wszystkie podpowiadaczki:
- Term suggester
- Phrase Suggester
- Completion Suggester
- Context Suggester
"sugest in title": [
{
"text": "matri",
"offset": 0,
"length": 5,
"options": [
{
"text": "matrix",
"score": 0.8,
"freq": 26
},
{
"text": "materi",
"score": 0.8,
"freq": 18
},
{
"text": "matti",
"score": 0.8,
"freq": 11
}, ...ElasticSearch i Java
Różne biblioteki:
Wyszukiwanie
SearchResponse searchResponse = client.prepareSearch("esmd")
.setTypes("movie")
.setQuery(QueryBuilders.matchAllQuery())
.addSort(SortBuilders.fieldSort("movieid").order(SortOrder.DESC))
.setFrom(0)
.setSize(1)
.execute()
.actionGet();Zapisywanie
Movie movie = ...
IndexResponse response =
client.prepareIndex("esmd", "movie", String.valueOf(movie.getMovieid()))
.setSource(jacksonObjectMapper.writeValueAsString(movie))
.execute()
.actionGet();
Odczytywanie
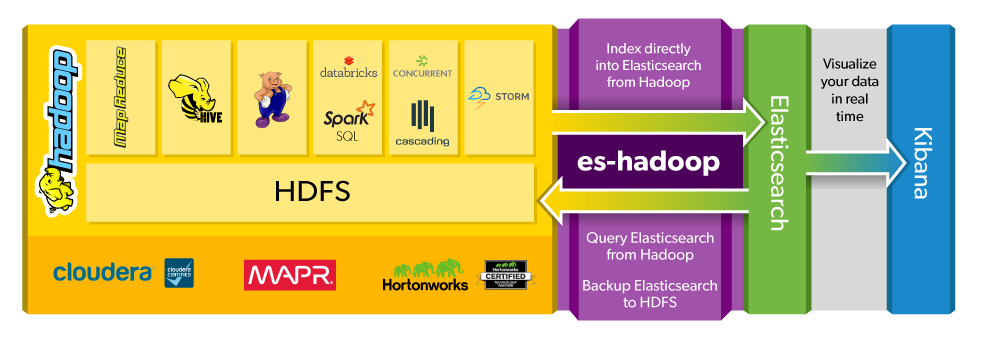
GetResponse response = client.prepareGet("esmd", "movie", "3129479").get();Ekosystem
Jak żyć z ElasticSearchem?
Monitoring Marvel

Monitoring Marvel

Monitoring Kopf


Monitoring Elastic HQ

Monitoring Bigdesk

Analytics and search dashboard for Elasticsearch


Elastic Cloud (dawniej Found)
Elasticsearch as a Service


alarmowanie i zawiadamianie o zmianach w danych


?
Linki
Szybkie wyszukiwanie z ElasticSearch'em
Marcin Stachniuk
23 kwietnia 2016
Dziękuję!
Copy of Szybkie wyszukiwanie pełnotekstowe z ElasticSearch'em - DevCrowd 2016
By Marcin Stachniuk

