OSSクローラの
ロボット排除規約
従い度
2015/09/23 中野 豊 @ 株式会社カカクコム
クロール/クローラ とは
-
クロール
インターネット上の情報を機械的に収集する行為 -
クローラ
クロールを行うソフトウェア。別名Bot, Spider
クロールの際に気を付ける点
著作権
ライセンス
-
マナー
- User-Agentで何者か名乗る
- 迷惑をかけないようゆっくりゆっくり
- ロボット排除規約に従う
ロボット排除規約?
- Webサイトをクロールしに来るbotに対し、
クロールの仕方を指示するための規約 - 紳士協定。強制力はない
- とはいえ、まともなクローラはこの規約を守る。Googlebotとか
- robots.txtまたはrobots meta tagに記載する
robots.txt
- クローラに対する命令を記述するファイル
- ホストのルートに置く
http://your.host.name/robots.txt - 記載例
User-Agent: * # 全てのクローラは
Disallow: /admin # /admin以下にアクセスしないこと
Crawl-Delay: 5 # 5秒以上リクエスト間隔をあけること
User-Agent: BadBot # BadBotだけは
Disallow: / # アクセス禁止robots meta tag
- クローラに対する命令を記述するHTMLタグ
- 各HTMLのhead要素内、またはa要素に記述する
- 記載例
<!-- head内で、このページの全リンクを辿らないよう指示 -->
<meta name="robots" content="nofollow"/>
<!-- 個別のaタグで、リンクをたどらないよう指示 -->
<a href="/path/to/some/page" rel="nofollow">xxx</a>ロボット排除規約に従うには
- 自分でクローラを作るなら、自分で実装
- クローラ製品のロボット排除規約サポートを
使うなら、本当に動くか確認しておきたい
今回調べた製品
-
Apache Nutch 1.10
- Javaで書かれたOSSクローラ
- データはHDFS、ジョブはMapReduce -> スケール!!
- プラグインによる拡張性
- 豊富なデフォルトプラグイン: HTMLパーサ, Solrインデクサなど
-
Scrapy 1.0
- Python(2系)で書かれたOSS
クロール&スクレイピングフレームワーク - パーサは基本自前実装
- Pythonは楽 + Scrapyに便利ツール付属 -> 開発効率高
- Python(2系)で書かれたOSS
調査項目
-
考え方
サイト側がクロールを拒否・遅延するための機能に絞って調査 -
robots.txt
- User-Agent: クローラ、BotのUA指定
- Disallow: クロール対象外ディレクトリの指定
- Crawl-Delay: 最短リクエスト間隔指定
-
robots meta tag
- head要素内のnofollow: ページ内の全リンクを辿らせない指定
調査方法
- robots.txt
- テスト用サイト
- リクエスト間隔1秒設定でクロール
- Webサーバのログを確認
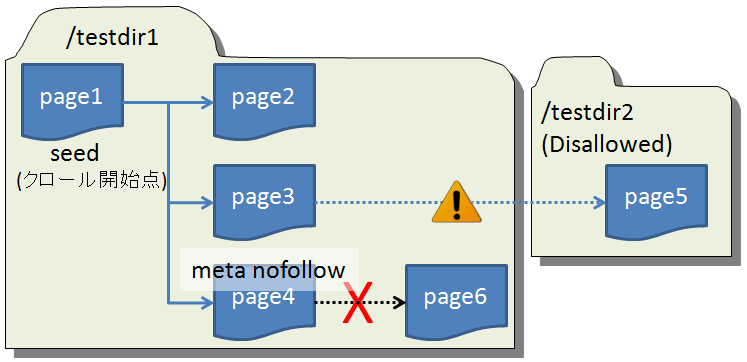
User-Agent: * または クローラのUA
Disallow: /testdir2
Crawl-Delay: 3調査結果: Nutch
-
全項目OK!
- User-Agent: OK
- Disallow: OK
- Craw-Delay: OK
- meta nofollow: OK
-
備考
robots.txtへのアクセスと、Seed URLのクロールが前後することがあった。 最初のページに限り、robots.txtを無視する可能性あり
調査結果: Scrapy
-
Crawl-Delayを無視
- User-Agent: OK
- Disallow: OK
- Craw-Delay: NG
- meta nofollow: ?(parser実装時に利用者が自前で)
-
備考
- 設定ファイルに以下を記載しないと、全項目NG
ROBOTSTXT_OBEY = True - Scrapyがrobots.txtの取扱いに利用しているPython標準の robotparser が、Crawl-Delayを未サポート。
GitHub上のissueは1年放置されたまま
- 設定ファイルに以下を記載しないと、全項目NG
ScrapyにCraw-Delayを守らせる
- robots.txtを見てリクエスト間隔の設定値を変更するコードを追加すればよい?
- 追加した。動いた
- もっと良い方法をご存じの方、
バグを見つけた方は教えてくださいm(__)m - 掲載したコードは利用しても構いませんが、
何が起きても責任は取りません
サンプルコード 1/3
- robots.txtからCrawl-Delayを取得する処理
from urllib2 import urlopen, Request
DEFAULT_DELAY = 0
def get_delay(spider_ua, hostname, port=80):
"""spiderのUAに対し、ホストのrobots.txtでリクエスト間隔が指定されていればその値を返す"""
robotstxt = _get_robotstxt(spider_ua, hostname, port)
ua_name = spider_ua.split('/')[0].lower()
delay_instrucstions = _parse_delay(robotstxt)
delay = delay_instrucstions.get(ua_name, delay_instrucstions.get('*', DEFAULT_DELAY))
return delay
def _get_robotstxt(ua, hostname, port):
"""与えられたホストのrobots.txtの文字列を取得する"""
url = 'http://{}:{}/robots.txt'.format(hostname, port)
try:
p = urlopen(Request(url, headers={'User-Agent': ua}))
robotstxt = p.read()
p.close()
except:
robotstxt = None
return robotstxt
def _parse_delay(robotstxt):
"""
robots.txtの内容を文字列で受け取り、User-Agentごとのリクエスト間隔指定を
{User-Agent: そのUAに対するDelay, User-Agent, そのUAに対するDelay, ...}
の形で返す
"""
delay_instructions = {}
if not robotstxt:
return delay_instructions
uas = []
for line in robotstxt.splitlines():
item = line.lower().split('#')[0].strip()
if item.startswith('user-agent:'):
uas.append(item.split(':', 1)[1].strip())
elif item.startswith('crawl-delay:'):
delay = item.split(':', 1)[1].strip()
try:
delay = int(delay)
if uas and delay >= 0:
for ua in uas:
delay_instructions[ua] = delay
except:
pass
finally:
uas = []
return delay_instructionsサンプルコード 2/3
- ホストごとにダウンロード間隔を変えられるようDownloaderを拡張
import re
from scrapy.core.downloader import Slot, Downloader, _get_concurrency_delay
from robotsdelay import get_delay
class CrawlDelayConsciousSlot(Slot):
"""リクエスト先ホストのrobots.txtに合わせて、ダウンロード間隔を調節するSlot"""
def __init__(self, concurrency, delay, settings):
super(CrawlDelayConsciousSlot, self).__init__(concurrency, delay, settings)
self.default_delay = delay
self.crawl_delay_cache = {}
self.ua = settings.get('USER_AGENT')
self.url_pattern = re.compile('^http[s]{0,1}://([^:/]+)[:]{0,1}([0-9]{0,5}).*$')
def download_delay(self):
"""override
次にリクエストするホストに合わせ、delayを設定し直す
"""
if self.queue:
req_host, req_port = self._get_hostport(self.queue[0][0])
if req_host:
self.delay = self._delay_for_host(self.ua, req_host, req_port)
return super(CrawlDelayConsciousSlot, self).download_delay()
def _get_hostport(self, request):
"""リクエストURLから、リクエスト先のホスト名orIPアドレスとポート番号を返す"""
url_match = self.url_pattern.match(request.url)
if not url_match:
return (None, None)
host_name, port_num = url_match.groups()
port_num = int(port_num) if port_num else 80
return (host_name, port_num)
def _delay_for_host(self, ua, host, port):
"""
リクエスト先ホストに応じたdownload delayを返す。
ホストへの初回リクエスト時のみrobots.txtを確認する。
2回目以降はキャッシュから返す
"""
if host not in self.crawl_delay_cache:
crawl_delay = get_delay(ua, host, port)
self.crawl_delay_cache[host] = max(self.default_delay, crawl_delay)
return self.crawl_delay_cache[host]
class CrawlDelayConsciousDownloader(Downloader):
"""SlotをCrawlDelayConsciousSlotに差し替えたDownloader"""
def _get_slot(self, request, spider):
key = self._get_slot_key(request, spider)
if key not in self.slots:
conc = self.ip_concurrency if self.ip_concurrency else self.domain_concurrency
conc, delay = _get_concurrency_delay(conc, spider, self.settings)
self.slots[key] = CrawlDelayConsciousSlot(conc, delay, self.settings)
return key, self.slots[key]サンプルコード 3/3
- setting.pyでDownloaderを差し替え
# robots.txtのCrawl-Delayをリクエスト間隔に反映するDownloaderを使う
import sys
sys.path.append('上記コードを置いたパス')
DOWNLOADER = 'downloader.CrawlDelayConsciousDownloader'調査結果まとめ
Nutchはロボット排除規約に
だいたい従うScrapyはCrawl-Delayを無視
->自前実装で対応しましょう
おまけ
エンジニア募集!
研究素材のログとクチコミがたくさんある会社です

ご静聴
ありがとう
ございました
OSSクローラのロボット排除規約従い度
By nakano_yutaka