





Nikita Zhiltsov
Research fellow at Kazan Federal University (Russia)
Лекция 5
Оценивание результатов поиска
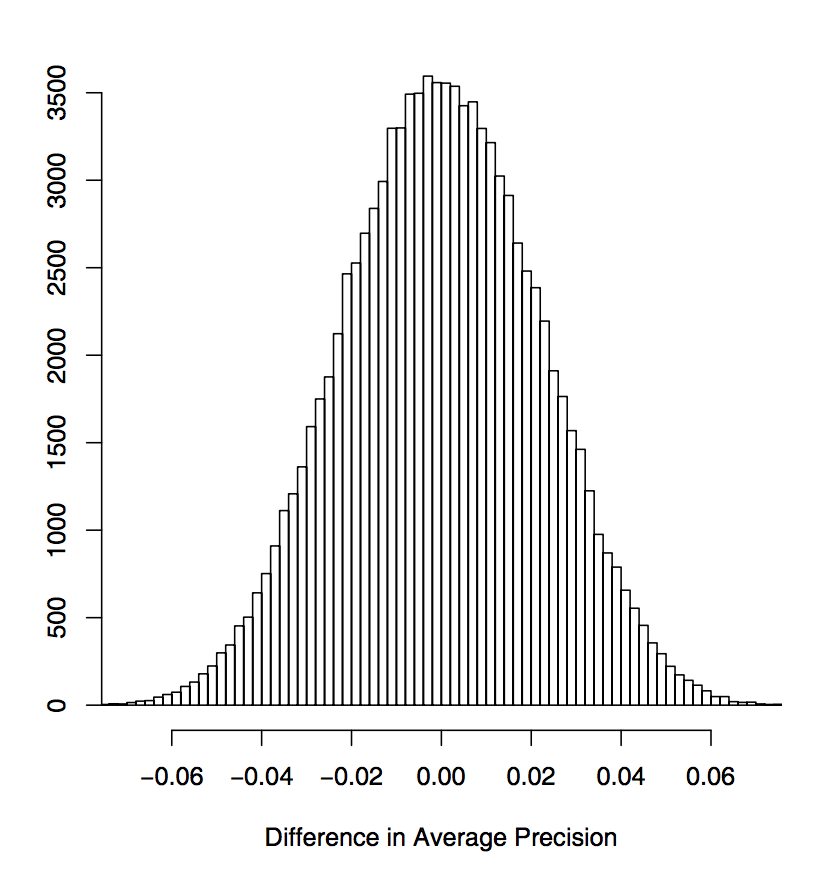
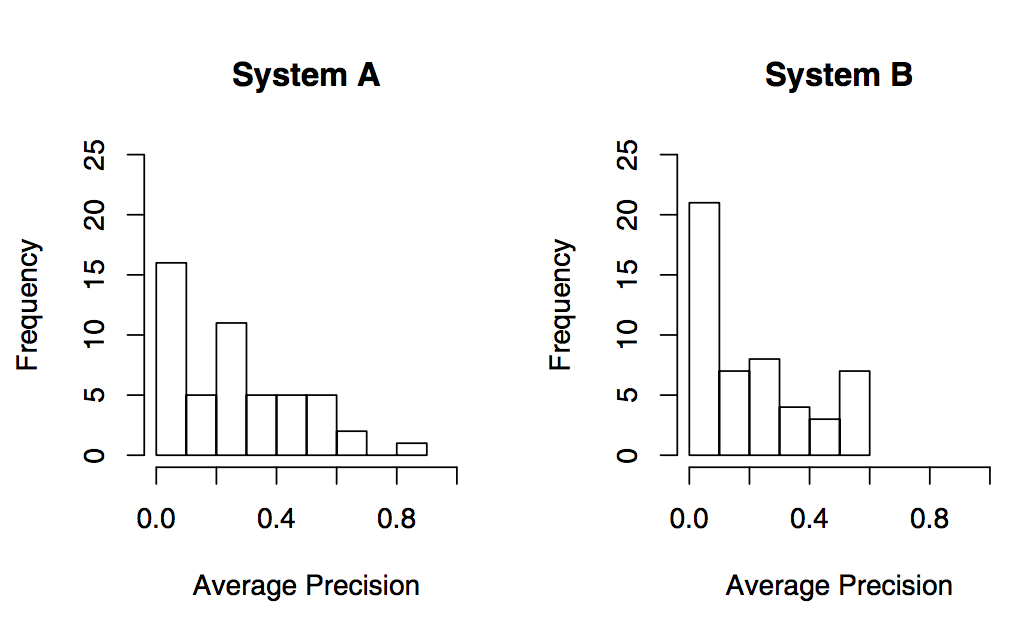
Разность MAP на перестановках
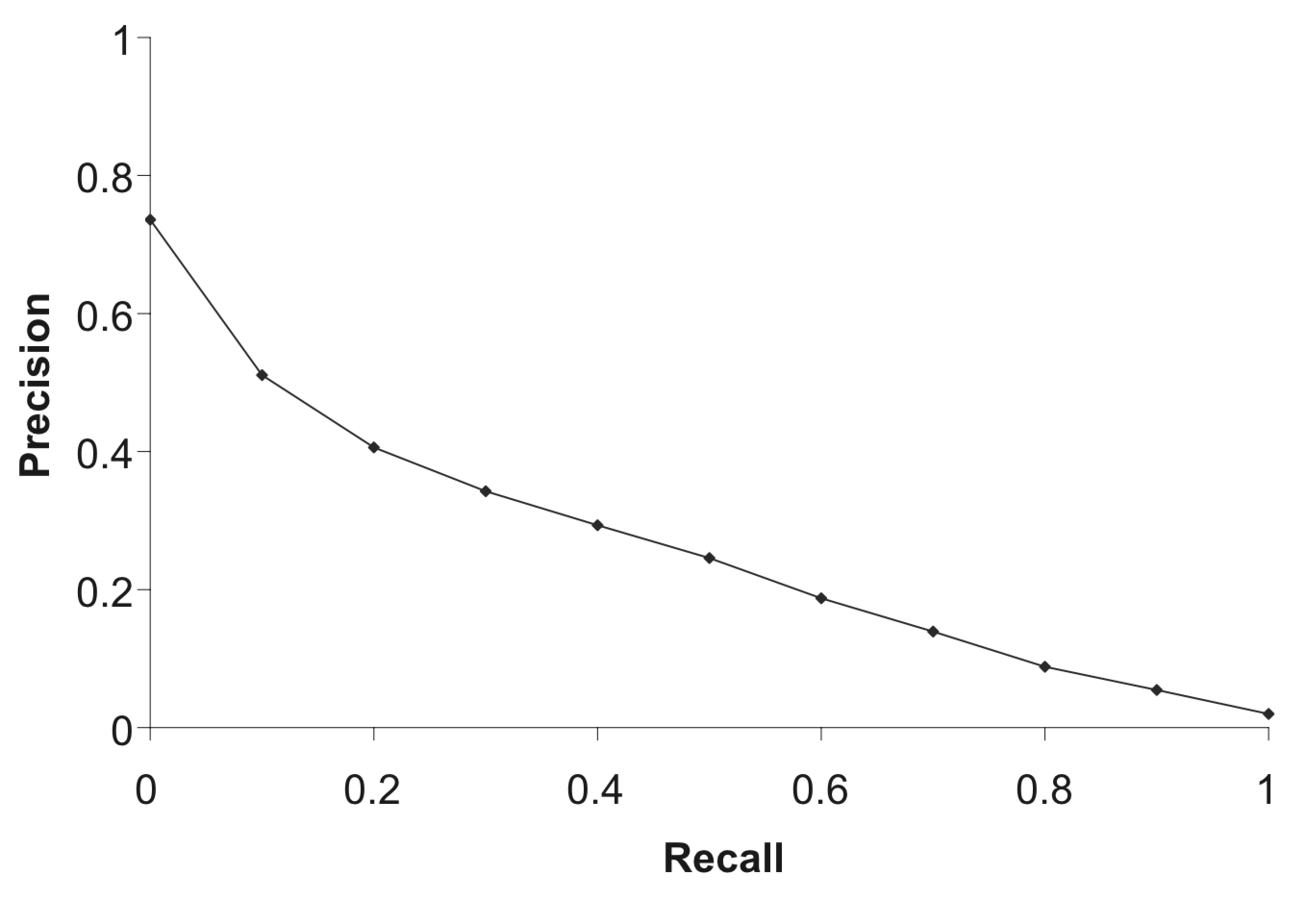
Наблюдаемые MAP
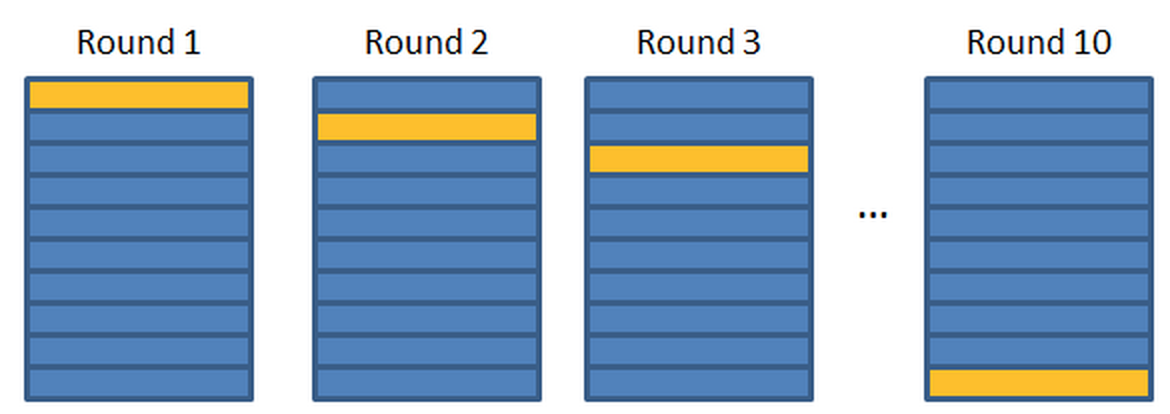
На практике обычно k=5 или k=10
k-fold cross validation
qrels
run
> trec_eval -q -c -m map qrels run
* означает значимость по тесту Фишера с p<0.05
By Nikita Zhiltsov



