
Olaya Argüeso Perez
Data Journalism Consultant & Trainer
18 al 22 de diciembre, 2017
Olaya Argüeso @oargueso
Existen dos tipos de PDF:
1. Escaneados
2. Generados electrónicamente
Escaneados:
Generados electrónicamente:
Generados electrónicamente:
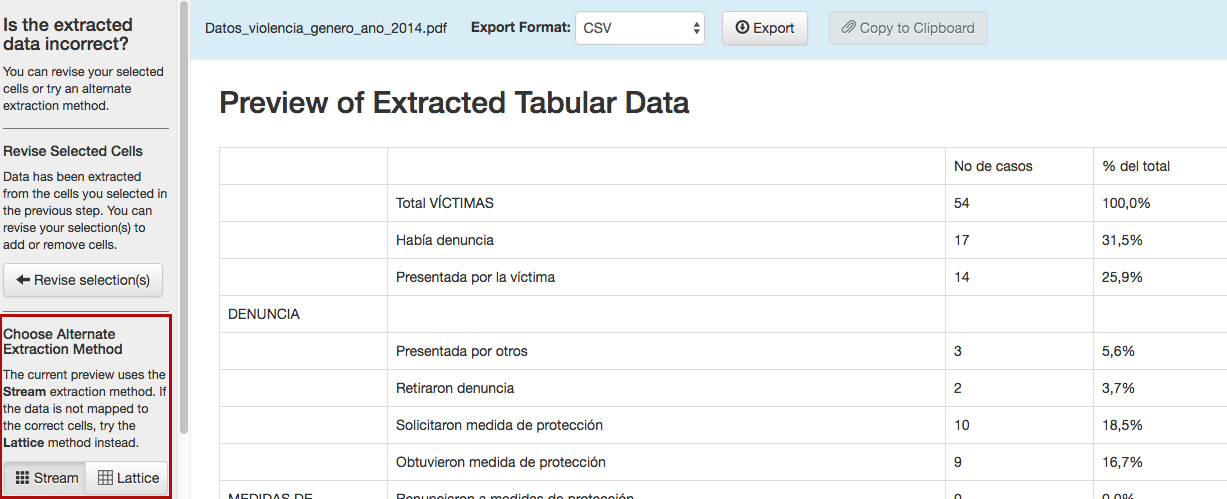
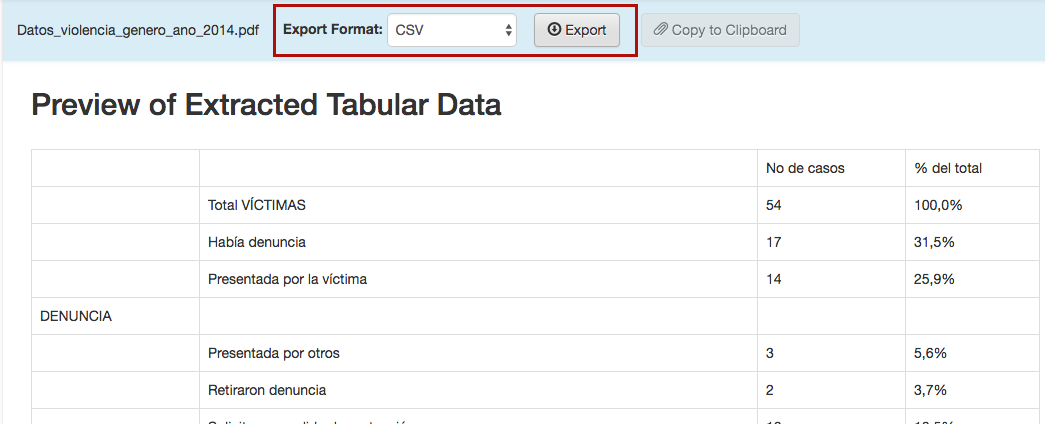
Tabula
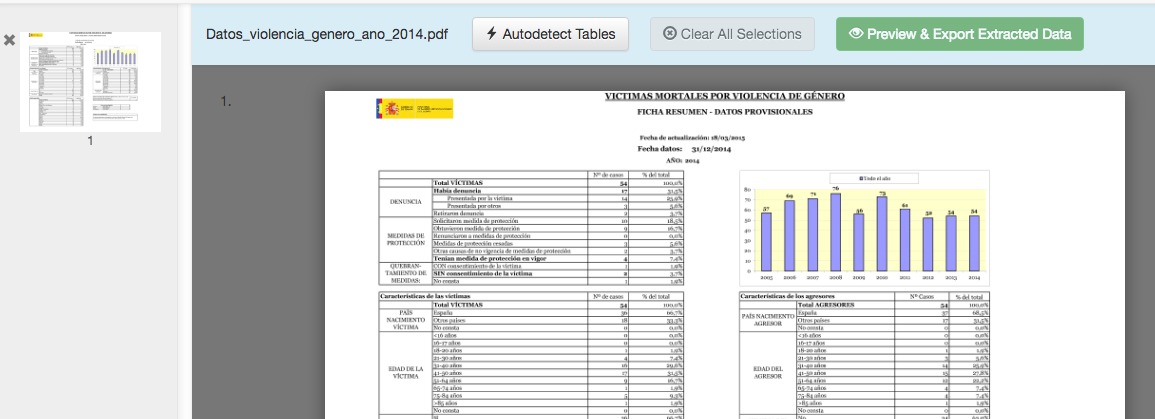
Tabula
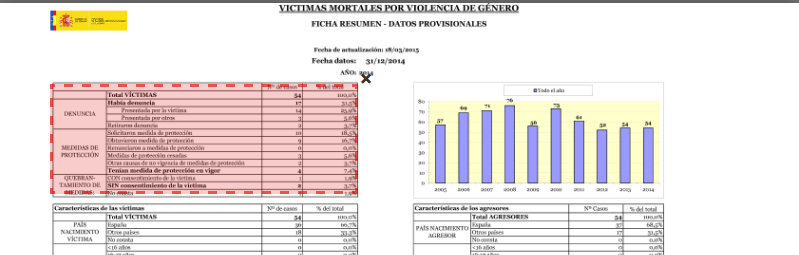
Tabula
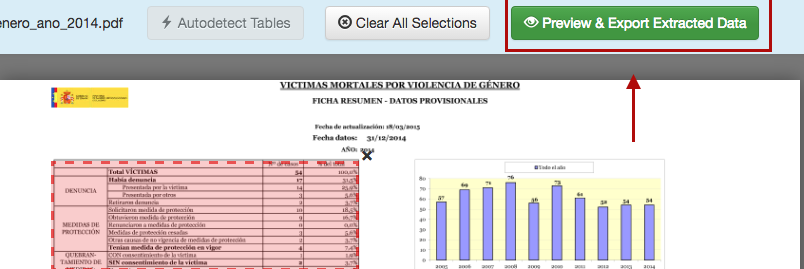
Tabula
Tabula
Tabula
Otras herramientas gratuitas:
+
Mailinator
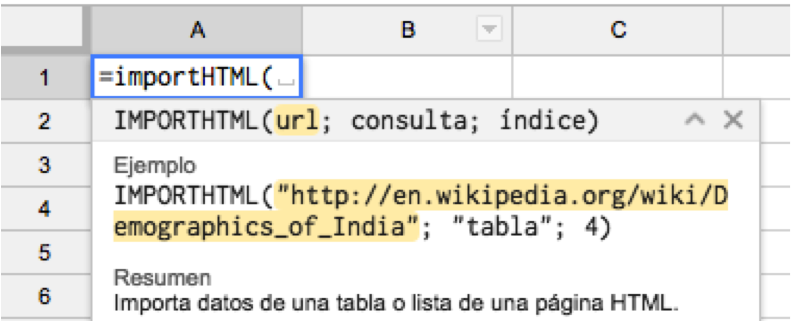
Herramientas para extraer tablas de páginas web:
Herramientas para extraer tablas de páginas web:
Herramientas para extraer tablas de páginas web:
By Olaya Argüeso Perez
Máster EFE
