
Olaya Argüeso Perez
Data Journalism Consultant & Trainer
18 al 22 de diciembre, 2017
Olaya Argüeso @oargueso
¿Qué es?
Una herramienta que nos permite limpiar y organizar datos sucios, y convertirlos de un formato a otro
¿Cómo funciona?
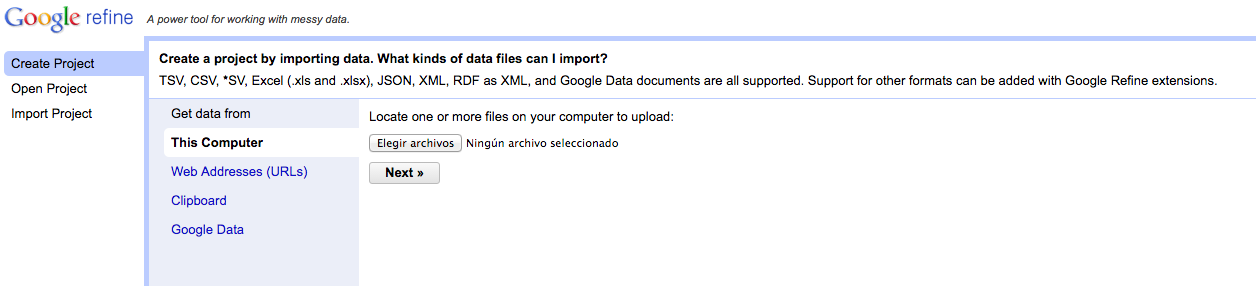
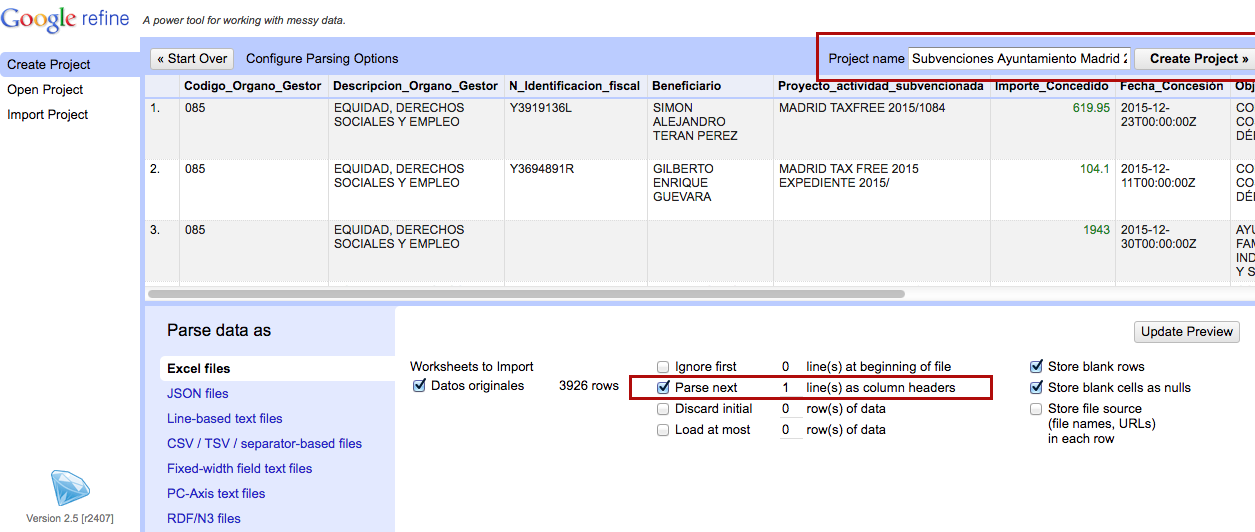
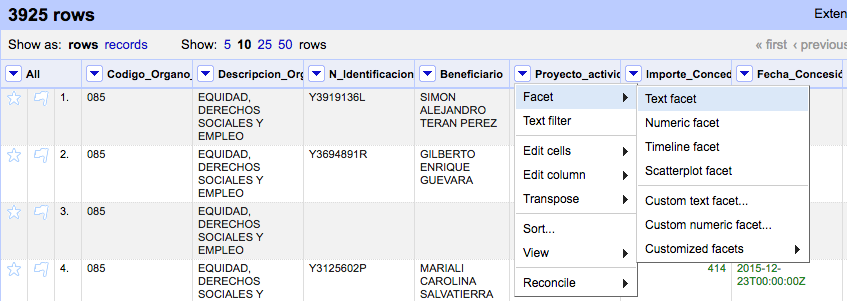
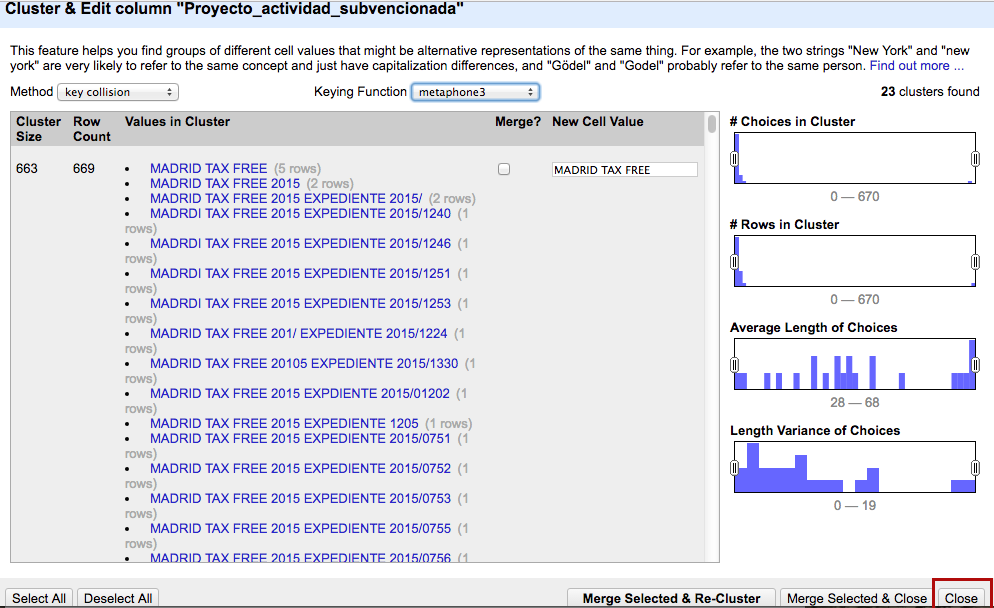
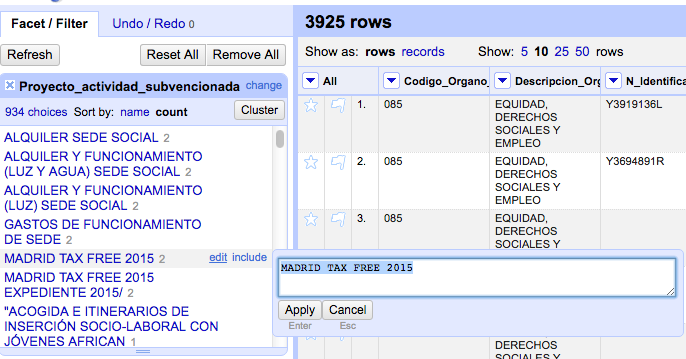
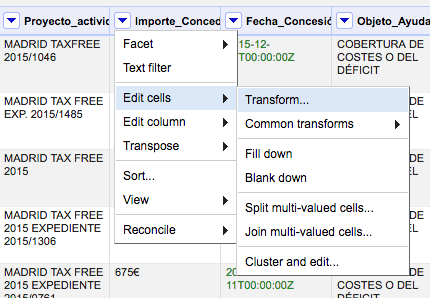
Abrid la base de datos sobre subvenciones del Ayuntamiento de Madrid
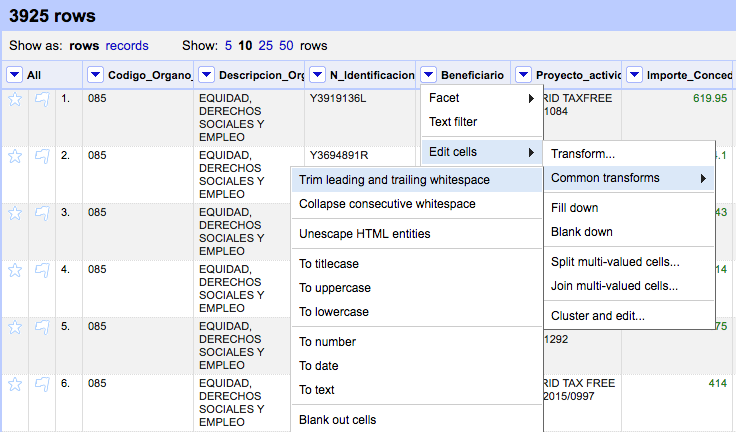
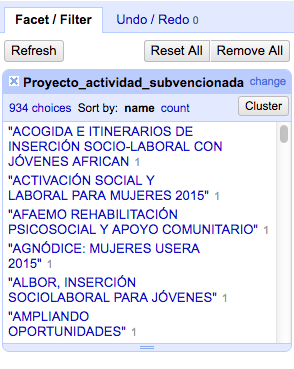
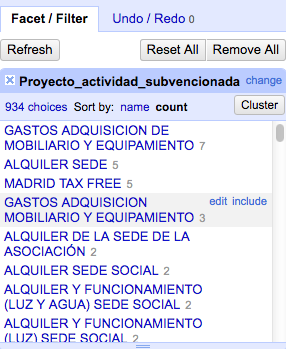
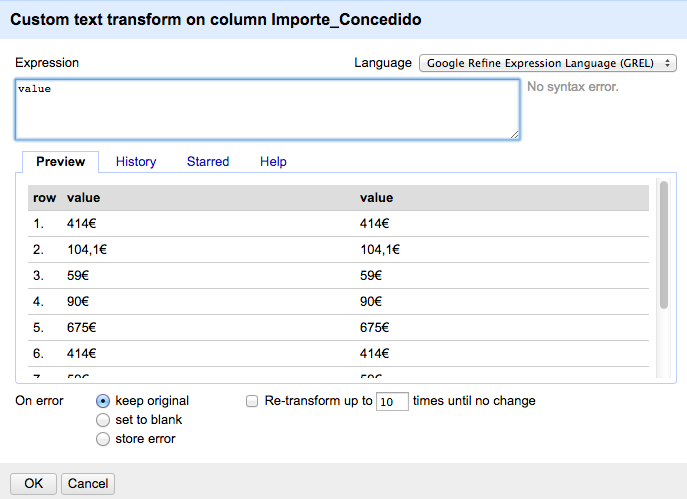
"Cluster" nos ofrece diferentes métodos que comparan el contenido de las celdas y las agrupa en función del resultado de la comparación
Existen dos métodos básicos:
"Key collision" busca coincidencias entre las palabras principales de cada cadena de texto
"Key collision" se subdivide en cuatro funciones:
Key collision + Fingerprint:
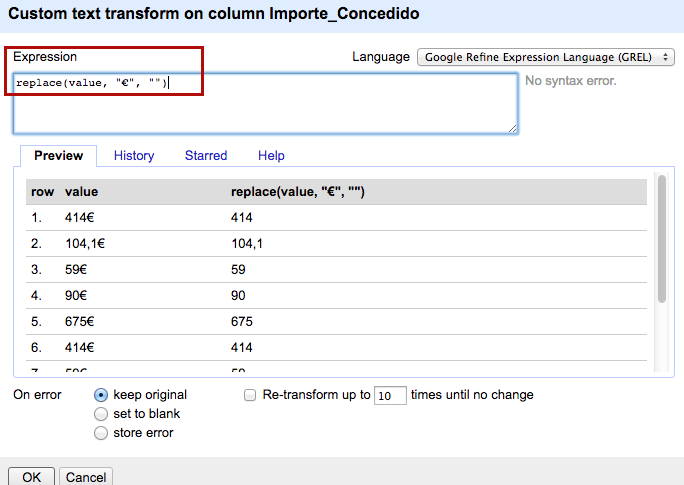
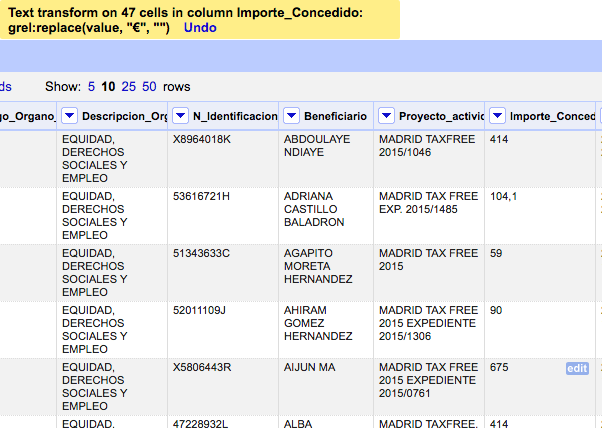
Busca caracteres idénticos, elimina caracteres especiales (&,%,$, ñ), lo pone todo en minúsculas, elimina duplicados. Ejemplos: une "new york", "New York" y "NEW YORK"
Key collision + N-gram fingerprint:
Utiliza los mismos principios que "Fingerprint", pero permite un cierto número de variaciones, marcado por el valor de "n". Cuanto mayor es el valor de "n", mayor es la diferencia entre las palabras, y mayores son los falsos positivos. Encuentra muchos typos
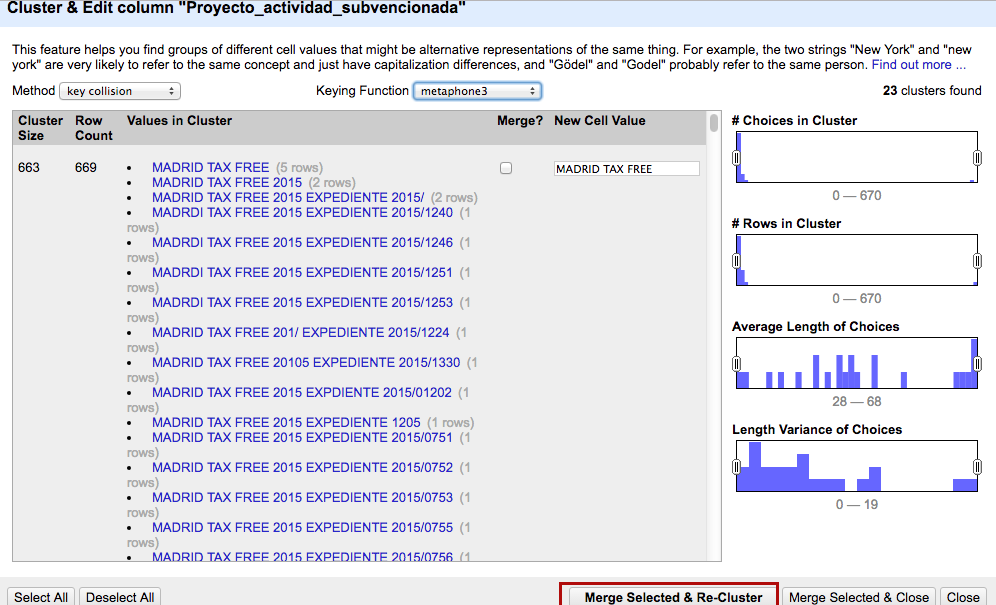
Key collision + Metaphone3:
Busca coincidencias basadas en la similitud fonética de las palabras. Basado en el inglés.
Key collision + Cologne-phonetic:
Busca coincidencias basadas en la similitud fonética de las palabras. Basado en el alemán.
"Nearest neighbour" permite afinar más la limpieza de los datos. Desventaja: es mucho más lento que "Key collision"
"Nearest neighbour" se subdivide en dos funciones:
Nearest neighbour + Levenshtein:
Busca cuántos cambios se necesitan para conseguir que dos cadenas de texto coincidan. Cuenta con dos parámetros: "radius" y "block chars"
Nearest neighbour + Levenshtein:
"Radius" indica el número de cambios que son necesarios para que dos cadenas de texto coincidan. Ejemplo: "Paris" y "paris" están a una distancia ("radius") de 1, porque hay que cambiar un solo carácter para que la coincidencia sea exacta
Nearest neighbour + Levenshtein:
"Block chars" analiza las cadenas de texto que componen la base de datos y genera "bloques" de caracteres que son comunes a todas ellas. Por defecto, la extensión de esos bloques de caracteres es 6
Nearest neighbour + PPM:
Mediante análisis estadísticos, trata de predecir cuánta diferencia hay entre dos cadenas de texto. También utiliza los parámetros "radius" y "block chars"
Nearest neighbour + PPM:
Jugando con los dos parámetros, intentamos saber cuántas diferencias entre dos cadenas de texto aceptaría OpenRefine antes de dejar de considerarlas coincidentes
Nearest neighbour + PPM:
Desventaja: es un método muy laxo y genera muchos falsos positivos. Debe usarse solo como último recurso
By Olaya Argüeso Perez
Máster EFE
