






Olaya Argüeso Perez
Data Journalism Consultant & Trainer
8 al 11 de mayo, 2017
Olaya Argüeso @oargueso
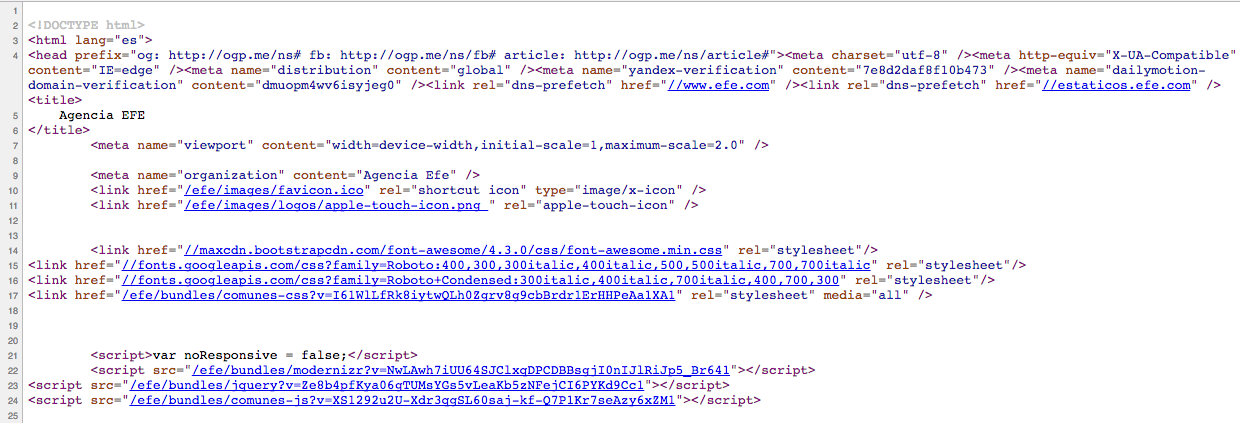
Fórmula de Google Spreadsheets (hojas de cálculo de Google) que nos permite extraer información de páginas web
Xpath recibe su nombre de la palabra "ruta" en inglés
C:\user\documentos\cv.doc
C:
user
documentos
cv.doc
Hyper Text Markup Language
<html>
<title> Agencia EFE </title>
<body>
<div>
<h3> Esto es un titular mediano </h3>
<p> Esto es un párrafo </p>
<p> Esto es otro párrafo </p>
</div>
</body>
Imprescindible: conocer la estructura de la página web de la que queremos extraer información y localizar la información que nos interesa dentro de esta estructura
Ejemplos de etiquetas o "tags":
Xpath se basa en esas etiquetas de HTML para localizar la información que nos interesa
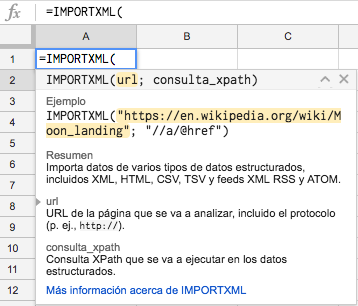
¿Cómo funciona IMPORTXML?
=IMPORTXML("url";"path")
La información que buscamos tiene la siguiente estructura:
li
h4
a
La información que buscamos tiene la siguiente estructura:
li
h4
a
hijo/child de "li"
hijo/child de "h4"
En lenguaje Xpath, esa estructura se traduce así:
li/h4/a
Es decir, / es el marcador para "hijo"
Vamos a ponerlo en práctica:
"//" le indica a Xpath que busque ese elemento dentro de la página web, independientemente de dónde se encuentre
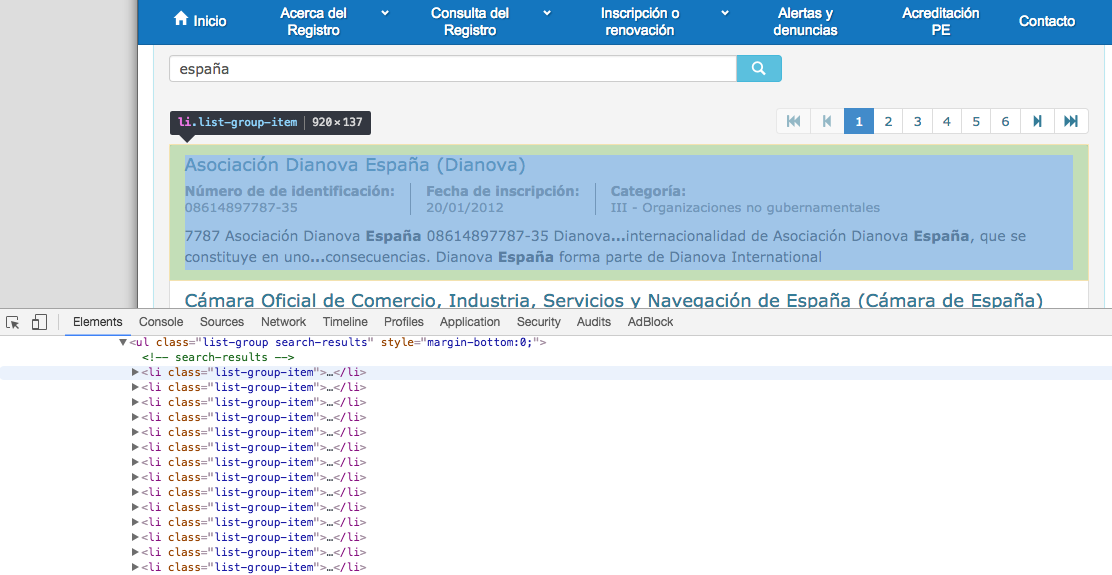
=IMPORTXML("url registro lobbies ue";"//a")
Si detallamos más la ruta, podemos ser más precisos en la extracción de información
li
h4
a
hijo/child de "li"
hijo/child de "h4"
=IMPORTXML("url registro lobbies ue";"//h4/a")
=IMPORTXML("url premios Nobel";"//h3/a")
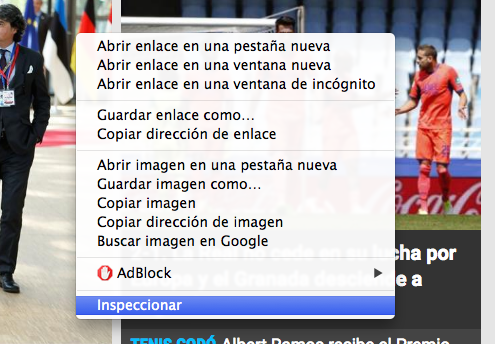
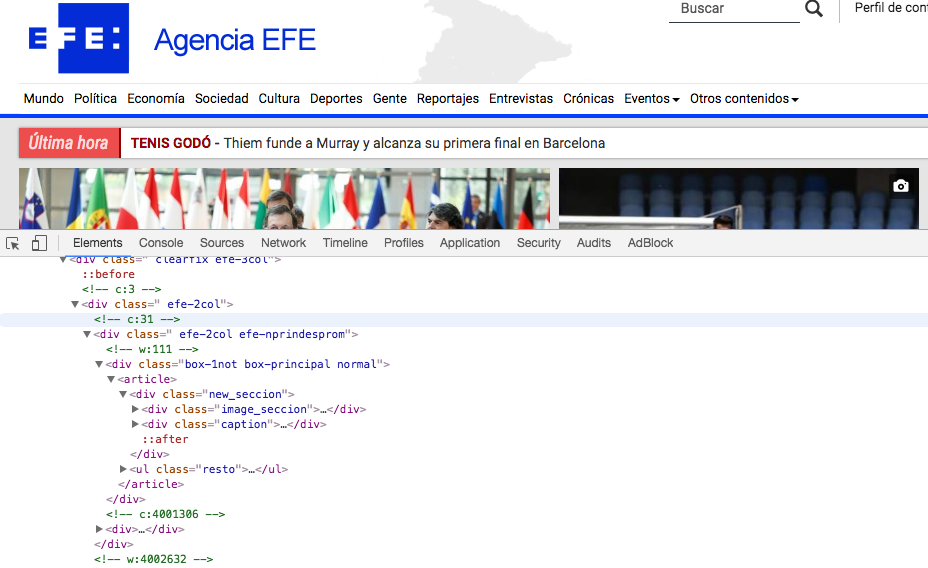
2. Abrid el inspector de Google Chrome
3. ¿Cómo extraeríais los nombres de las diputadas?
=IMPORTXML("url Congreso";"//li/a") extrae todos los enlaces que están incluidos en una lista
¿Podemos afinar la búsqueda?
"class" es un atributo
Los atributos se utilizan para identificar determinadas etiquetas y distinguirlas de otras iguales a ellas, puesto que el número de etiquetas es limitado y se repiten a lo largo de una página web
En Xpath, los atributos se identifican así:
[@class]
Para extraer los nombres de las diputadas:
=IMPORTXML("url Congreso";"//li/a[@class])"
¿Y para extraer el grupo parlamentario al que pertenecen?
=IMPORTXML("url Congreso";"//li/span[@class='dorado']")
Muy importante: las comillas del nombre que identifica al atributo son simples
By Olaya Argüeso Perez
