ODO
Shapeshifting for your data
A library for turning things into other things
Factored out from the blaze project
"Oh, so it's a set of converters"
So is LLVM

Say "converter" one more time

Handles a huge variety of conversions
>>> odo([1, 2, 3], tuple)
(1, 2, 3)
list » tuple
Simple things ...
>>> odo('hive://hostname/default::users_csv',
... 'hive://hostname/default::users_parquet',
... stored_as='PARQUET', external=False)
<an eternity later ...
sqlalchemy.Table repr>Hive CSV » Hive Parquet
More complex things ...
odo is cp with types, for data
How do I go from X to Y in the most efficient way ...
... without explicitly writing down each conversion?
DataFrame » Hive
For example ...
I know how to do this:
DataFrame » CSV
df.to_csv('/path/to/file.csv')... and this:
CSV » Hive
load data
local infile '/path/to/file.csv'
into table mytable;Odo gives you this:
DataFrame » CSV » Hive
automatically
... and with uniform syntax
>>> odo(df,
... 'hive://hostname/default::tablename')How about something more involved?
JSON in S3 » postgres
How would we do this?
- JSON S3 » Local temp file
boto.get_bucket().get_contents_to_filename()
- Local temp file » DataFrame
pandas.read_json()
- DataFrame » CSV
DataFrame.to_csv()
- CSV » postgres
copy t from '/path/to/file.csv'
with
delimiter ','
header TRUE

The odo way
>>> odo('s3://mybucket/path/to/data.json',
... 'postgresql://user:passwd@localhost:port/db::data')Each step is usually easy
... but the whole thing

How does it work?
Through a network of conversions
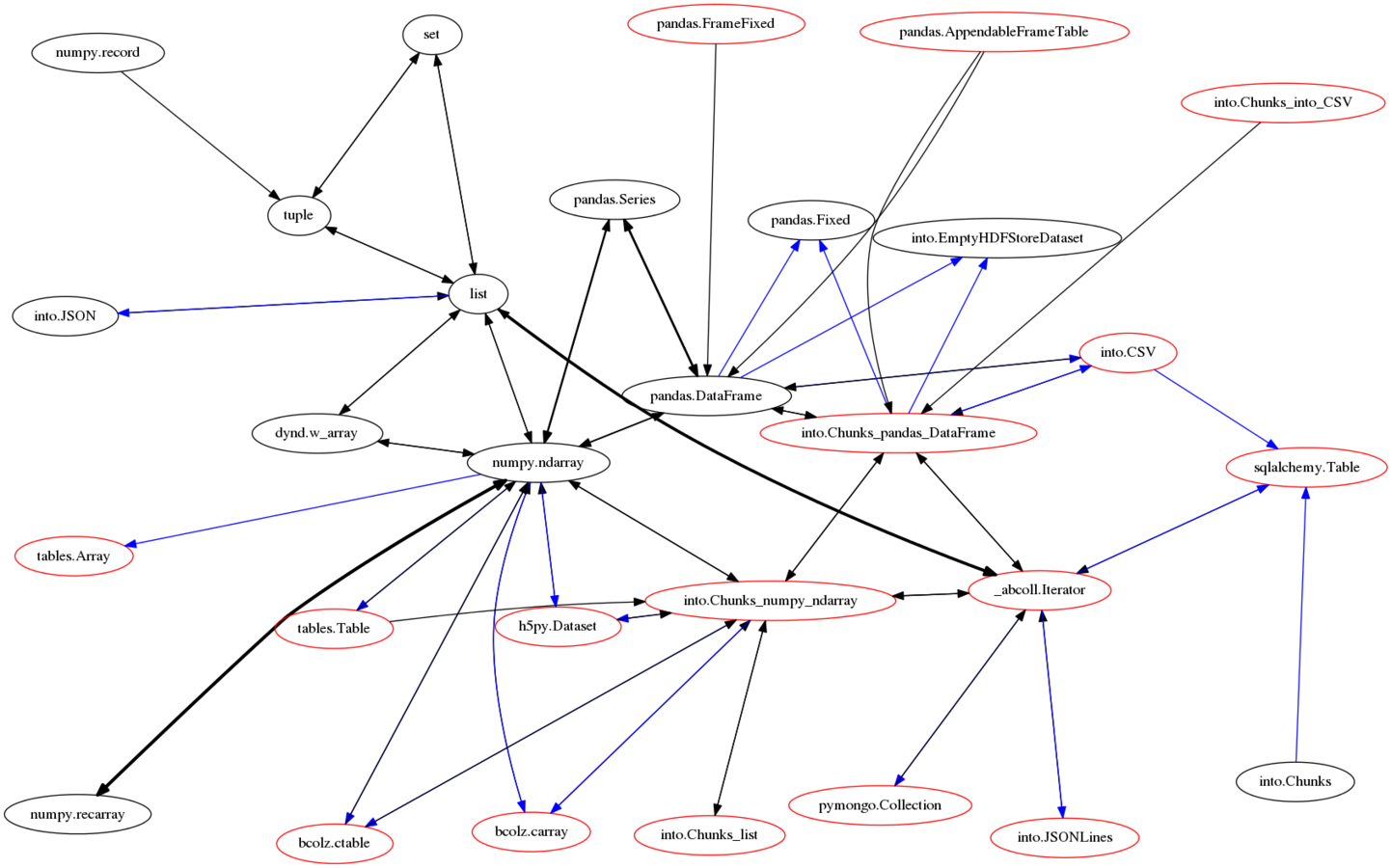
Each node is a type (DataFrame, list, sqlalchemy.Table, etc...)
Each edge is a conversion function
The full monty ...

It's extensible!
from odo import convert
from pyspark.sql import DataFrame as SparkDataFrame
@convert(pd.DataFrame, SparkDataFrame)
def frame_to_frame(spark_frame, **kwargs):
return spark_frame.toPandas()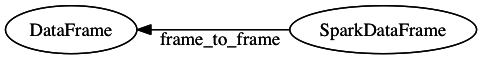
Docs
Thanks!
Source
Get it
-
conda install odo -
pip install odo

ODO
By Phillip Cloud



