




Piotr Żelasko
Research scientist at CLSP, John's Hopkins University. PhD @ AGH-UST in Cracow. My interests are automatic speech recognition, natural language processing, C++ and Python, machine learning and deep learning, and jazz music.
Piotr Żelasko
Zespół Przetwarzania Sygnałów AGH, Techmo
Kraków, 17.05.2017
Gramatyki (Sarmata)
Model językowy (Dictation)
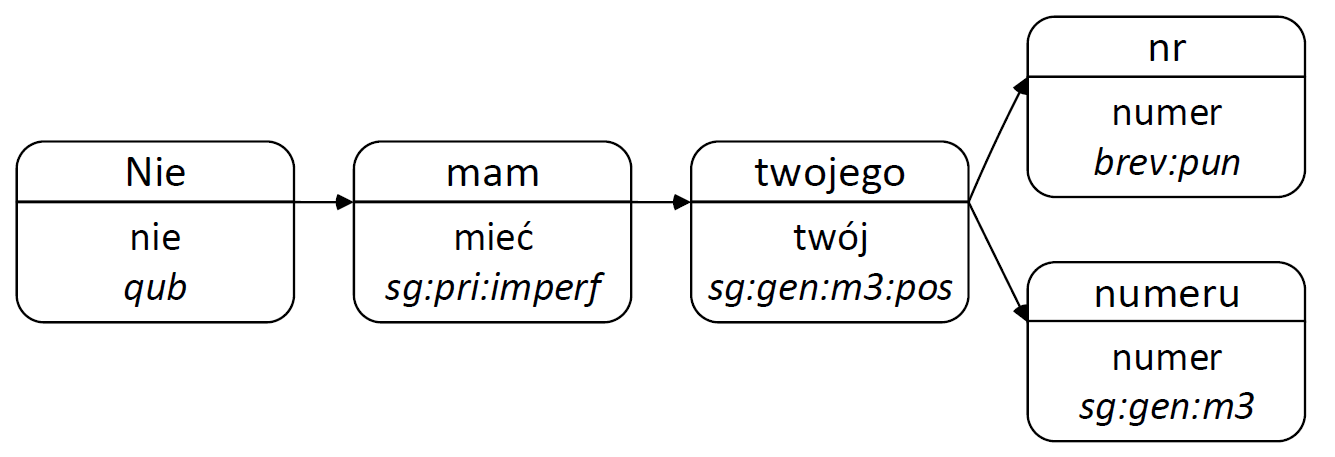
Dnia 15 marca 2003 r. odbyła się narada zgodnie z art. 5 § 3 k.p.c.
Dnia piętnastego marca dwa tysiące trzeciego roku odbyła się narada zgodnie z artykułem piątym pragrafu trzeciego kodeksu prawa cywilnego.
zestaw znaczników NKJP
Poprawność (accuracy)
i proszę o pytania.
By Piotr Żelasko



