

Ronie Uliana
Software Architect and journeyman Data Scientist
Ronie Uliana | @ronie
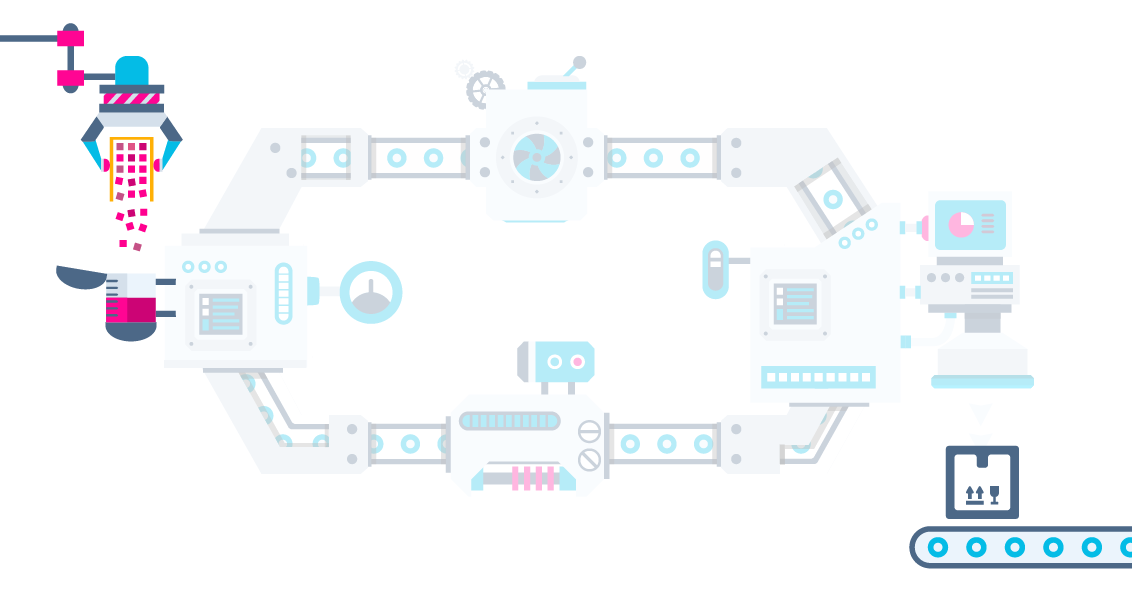
Nosso experimento com uma arquitetura distribuída para processar um grande volume de dados.
O resultado foi muito bom,
e talvez a experiência dê ideias interessantes.

Escovando bits desde "faz tempo" (~1990)
Não temos chefes
Raul Seixas & Papai Noel :p
Sidney Monreal & Mário Kaphan ^_^
Fundadores e ótimos amigos!
Nosso negócio é...
Empresas encontrando as melhores pessoas,
Pessoas encontrando as melhores empresas.
...processando esses milhões de dados.
Panorama do Mercado de Trabalho
Não é o opinião de algum especialista.
É o que as pessoas escrevem.
Não importa...
É mais do que cabe na memória da minha máquina >_<
É mais do que minha paciência aguenta esperar :p
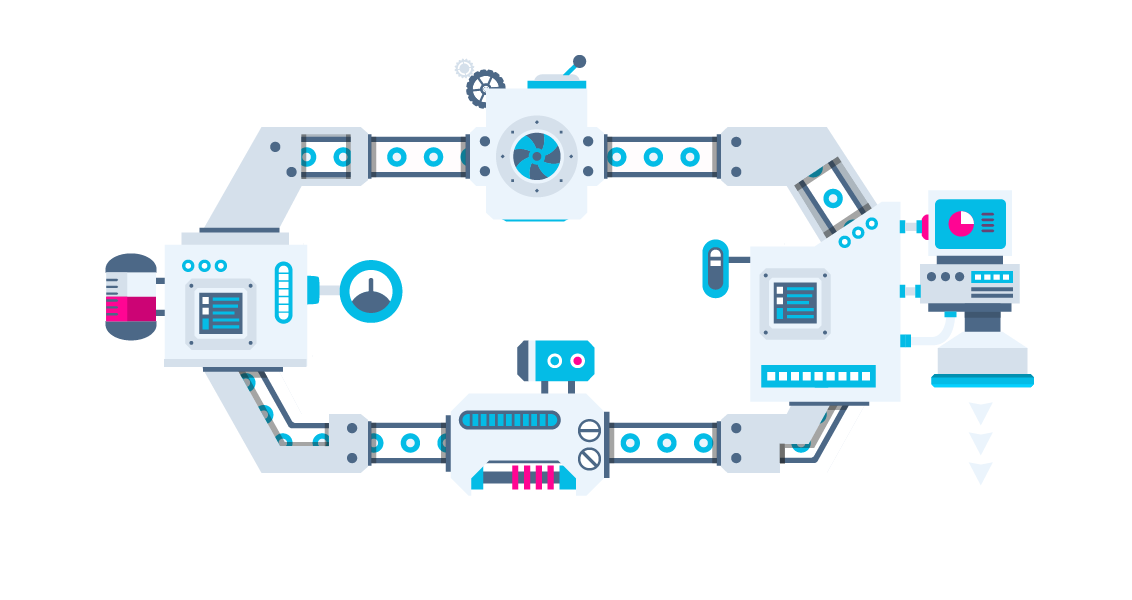
Scheduler, Processos, Pipes, Sockets
"Pipes and Filters"
github.com/VAGAScom/deadly_serious
Só para facilitar o trabalho ^_^
6 horas de processamento em um i7 (8 cores) 16Gb RAM
Salários: ~6.000.000 salários x bootstrap(1.000)
=
~6.000.000.000 operações
Ruby 2.0: Copy-on-Write Memory on Fork
Varia de acordo com o tamanho da mensagem
Maior nos acumuladores (como cálculo de TF-IDF)
Cada componente:
...roda no seu próprio tempo
...pode habitar outras máquinas
Raras as situações de deadlock
(peguei só uma até agora)
Dá para usar qualquer coisa que leia e grave em arquivos
Qualquer linguagem
Qualquer comando linux
Qualquer programa (MCL, por exemplo)
Qualquer componente pode ser substituído
Qualquer "subpipeline" pode ser substituída
Muito fácil testar cada componente
Fácil processar "por partes"
http://www.jpaulmorrison.com/fbp/
"This is the Unix philosophy: Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface." - Doug McIlroy
"...often people use Hadoop and other so-called Big Data (tm) tools for real-world processing and analysis jobs that can be done faster with simpler tools and different techniques."
http://aadrake.com/
command-line-tools-can-be-235x-faster-than-your-hadoop-cluster.html
>_<
Se tiver dúvidas, perguntas, vontade de trabalhar conosco ou só quiser trocar uma idéia:
@ronie | +RonieUliana
ronie.uliana@vagas.com.br
By Ronie Uliana
Como usamos o estilo arquitetural de Pipes and Filter e o Sistema Operacional para processar milhões de dados e gerar o Mapa VAGAS de Carreiras



