Deep Learning
&
Content-Based Image Retrieval
presented by:
Saeid Balaneshinkordan
based on:
Wan, Ji, Dayong Wang, Steven Chu Hong Hoi, Pengcheng Wu, Jianke Zhu, Yongdong Zhang, and Jintao Li.
"Deep learning for content-based image retrieval: A comprehensive study."
In Proceedings of the ACM International Conference on Multimedia, pp. 157-166. ACM, 2014.
Content-based Image Retrieval (CBIR) System
definition
ref: http://www.cse.unsw.edu.au/~jas/talks/curveix/notes.html
Content-based Image Retrieval (CBIR) System
definition
Image Retrieval
concept based
content based
use text-based image retrieval techniques
use computer vision techniques
use content of image
use metadata of image
Content-based Image Retrieval (CBIR) System
Learning effective feature representations and similarity measures
challenge
semantic gap
low-level image pixels captured by machines
high-level semantic concepts perceived by human
Deep Learning
for
Content-based Image Retrieval (CBIR) System
b. examining Convolutional Neural Networks
1- Is deep learning a solution for bridging the semantic gap in CBIR
2- How much improvements can be achieved by exploring the deep learning techniques?
3- Which framework of deep learning to apply?
a. an extensive set of empirical studies
Deep Learning
for
Content-based Image Retrieval (CBIR) System
Shallow CBIR
System
Deep CBIR
System
Features from DB
Features from Query
DB raw data
Query raw data
similar images
similar images
instead: learn features at multiple level of abstracts from data automatically

no human-crafted features
Distance metric Learning
definition
what is "metric"?
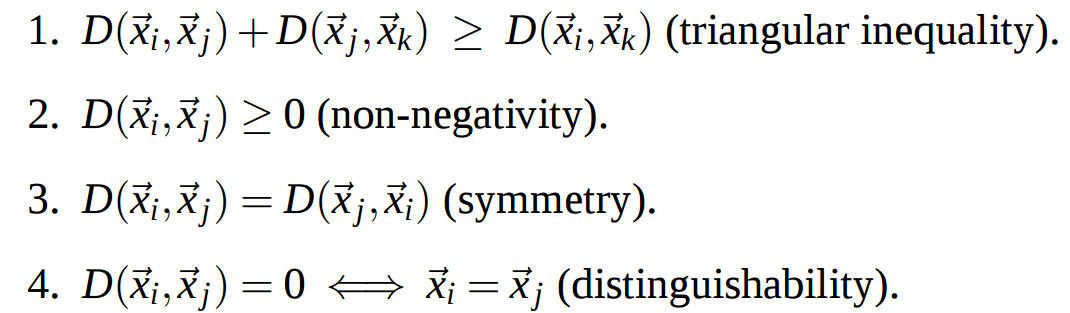
is a metric if it satisfies the following properties:
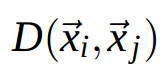
Distance metric is a family of metrics that compute
squared distances as:
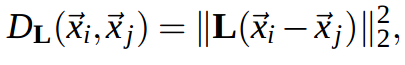
linear transformation
ref: Weinberger, Kilian Q., and Lawrence K. Saul. "Distance metric learning for large margin nearest neighbor classification." The Journal of Machine Learning Research 10 (2009): 207-244.
contains a similar pair and a dissimilar pair
Distance metric Learning
1- pairwise constraints
2- triplet constraints
must-link constraints and cannot-link constraints are given
types of training data
3- class labels
directly using the class labels, following a typical machine learning scheme
Distance metric Learning
1- pairwise constraints
must-link constraints and cannot-link constraints are given
types of training data
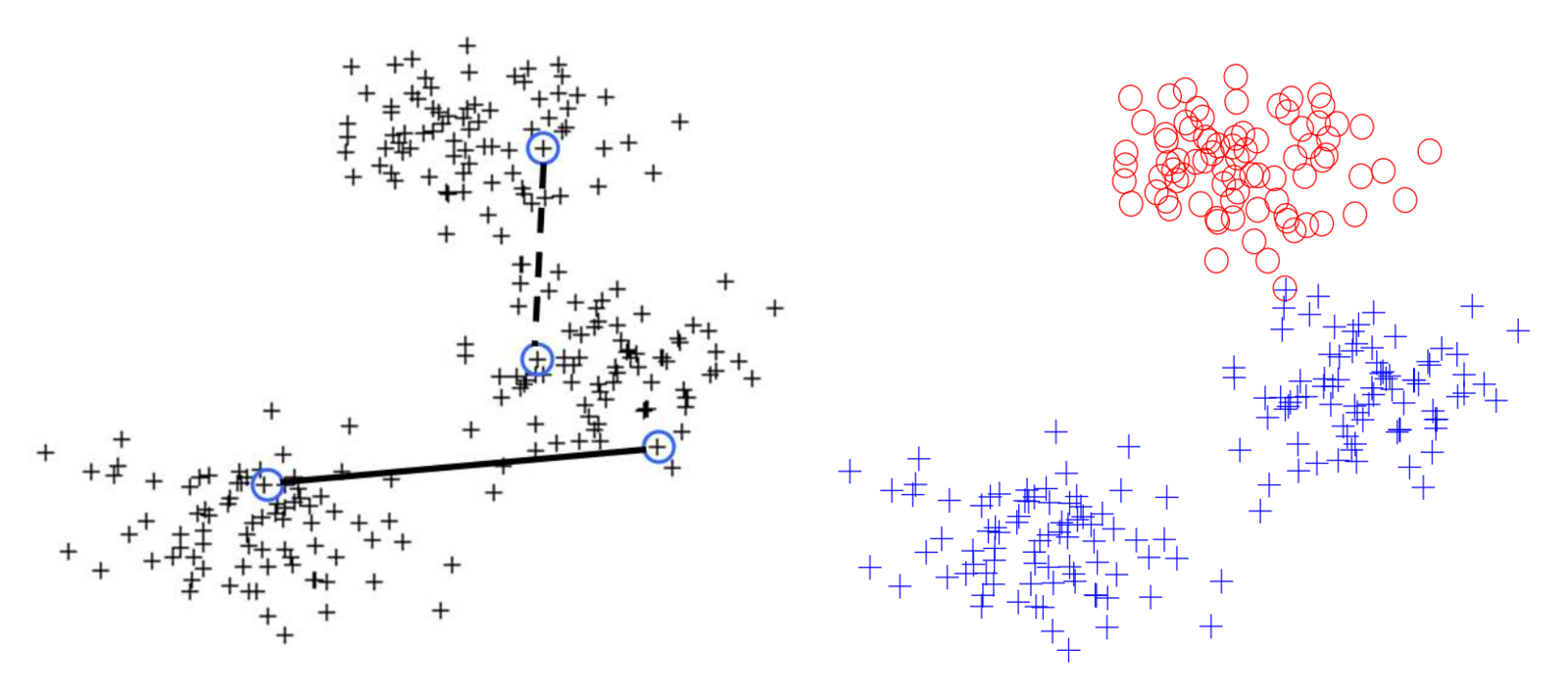
must-link
cannot-link
ref: Lu, Zhengdong. "Semi-supervised clustering with pairwise constraints: A discriminative approach." In International Conference on Artificial Intelligence and Statistics, pp. 299-306. 2007.
contains a similar pair and a dissimilar pair
Distance metric Learning
2- triplet constraints
types of training data
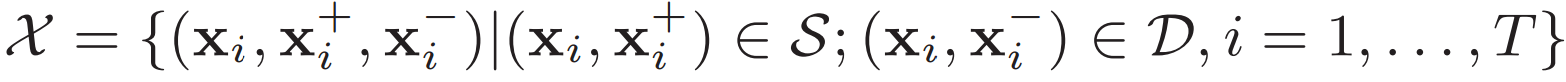
relevant pairs
set
irrelevant pairs
set
triplet constraint set
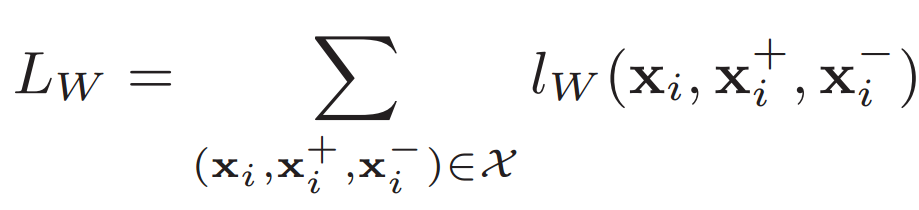
overall loss:
loss for a triplet
Distance metric Learning
types of training data
directly using the class labels, following a typical machine learning scheme
example: using Linear Discriminant Analysis (LDA)
maximizes
between-class variance
within-class variance
(
)
ref: Weinberger, Kilian Q., and Lawrence K. Saul. "Distance metric learning for large margin nearest neighbor classification." The Journal of Machine Learning Research 10 (2009): 207-244.
3- Class Labels
learn a metric on the local sense by only satisfying the given local constraints from neighboring information
Distance metric Learning
global supervised approaches:
local supervised approaches:
learn a metric on a global setting by satisfying all the constraints
learning approaches
1- data is usually locally “well-behaved,” simpler region-classifiers often suffice for controlling local empirical error.
2- complex boundaries for partitions can be approximated by piecewise linear functions
ref: Wang, Joseph, and Venkatesh Saligrama. "Local supervised learning through space partitioning." InAdvances in Neural Information Processing Systems, pp. 91-99. 2012.
learning is done in a sequential order
can handle large-scale data
Distance metric Learning
batch learning methods:
online learning methods:
assume the whole collection of training data must be given before the learning task and train a model from scratch.
learning methodology
CNN implementation

(a) Training deep CNN models in an existing domain (ImageNet)
(b) Adopting trained model for CBIR in a new domain
CNN implementation
cuda-convnet:
- fast C++/CUDA implementation of convolutional neural networks
- Training is done using the back-propagation algorithm.
- Fermi-generation GPU (GTX 4xx, GTX 5xx, or Tesla equivalent) required
- training dataset: “ILSVRC-2012” (from ImageNet with 1,000 categories and more than 1 million training images.)
CNN implementation

training dataset
ILSVRC2012: ImageNet Large Scale Visual Recognition Challenge 2012
estimate the content of photographs for the purpose of retrieval and automatic annotation
using a subset of the large hand-labeled ImageNet dataset (10,000,000 labeled images depicting 10,000+ object categories) as training.
The goal of this competition:
CNN implementation
Training deep CNN models in an existing domain (ImageNet)
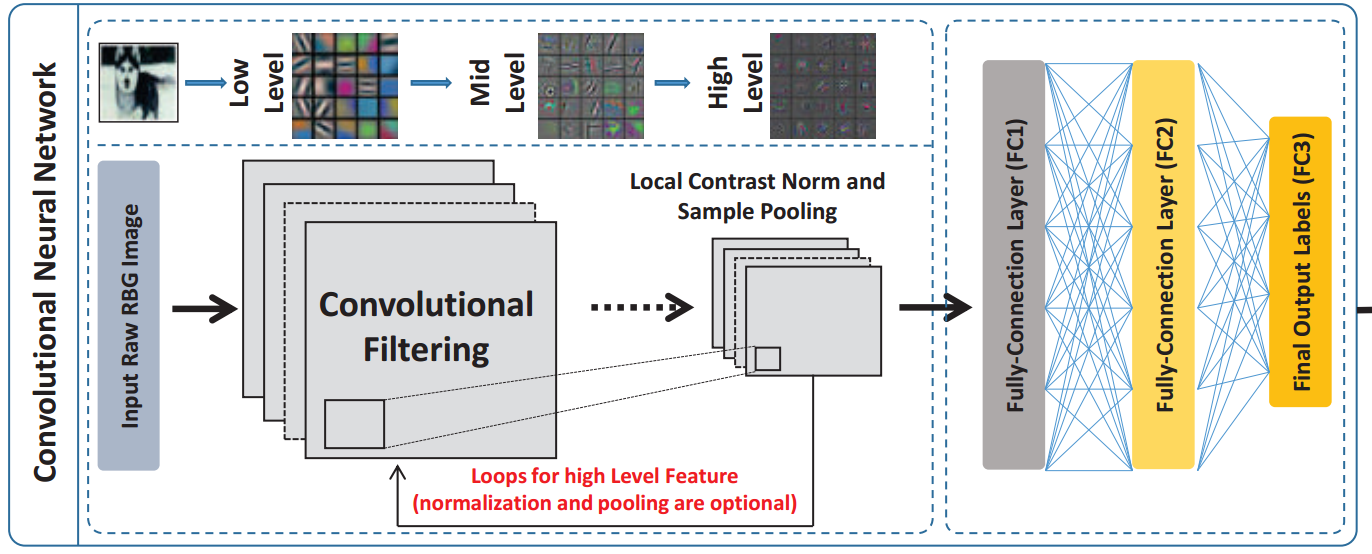
deep convolutional network consists of two parts:
1) the convolution layers and maxpooling layers, and
2) the fully connection layers and the output layers.
five convolutional layers:
The first and the second convolution layers are following with a response normalization layers and a max pooling layers
The third, fourth, and fifth convolution layers are connected to one another without any intervening pooling or normalization.
1- a nonlinear function: Rectified Linear units (ReLUs)
2- can reduce the training time of the deep convolutional neural networks several times than the equivalents with “tanh”’ units.
neuron output function f:
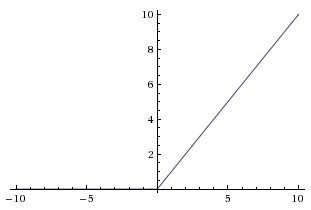
ref: http://cs231n.github.io/neural-networks-1/
- "FC1" and "FC2": two fully connected layers with 4, 096 neurons.
- "FC3": 1000-way softmax layer which produces a distribution over the 1, 000 class labels in ImageNet.
- 60 million parameters in total in the whole deep convolutional neural network
- training set: ImageNet’s ILSVRC-2012, with 1.2 million images.
- It takes about 200 hours to train a model
- error rate: 0.424 over the validation set (50, 000 images)
experimental setup:
- Linux server
- NVIDIA Tesla K20 GPUs.
- 13 active SMXes (Streaming Multiprocessor)
- 5 memory controllers
- 1.25MB of L2 cache,
- 5GB of GDDR5 (Double Data Rate type five synchronous Graphics random access memory).
CNN implementation
Adopting trained model for CBIR in a new domain
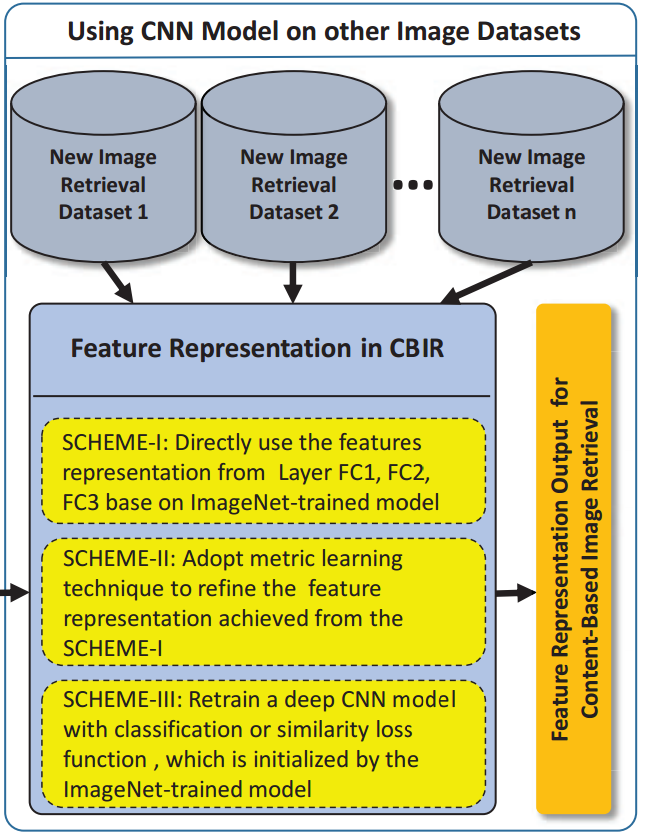
feature generalization schemes
scheme I:
DF.FC3: the feature taken from the final output layer,
DF.FC2: the features taken from the final hidden layer,
DF.FC1: the activations of the layer before DF.FC2.
adopt one of the activation features DF.FC1, DF.FC2, and DF.FC3, directly.
To obtain the feature representation:
- directly feed the images in new datasets into the input layer of the pre-trained CNN model
- take the activation values from the last three layers.
feature generalization schemes
scheme II:
DF.FC3+SL: the feature taken from the final output layer,
DF.FC2+SL: the features taken from the final hidden layer,
DF.FC1+SL: the activations of the layer before DF.FC2+SL.
- Construct the triplets by simply considering relationships of instances in same class as relevant (positive), and relationships of instances belonging to different classes as irrelevant (negative).
- Classifier training: LogReg or SVM algorithm and by focusing on object recognition
feature generalization schemes
scheme III:
ReCLS.FC3 & ReDSL.FC3 : the feature taken from the final output layer,
ReCLS.FC2 & ReDSL.FC2: the features taken from the final hidden layer,
ReCLS.FC1 & ReDSL.FC1: the activations of the layer before ReCLS.FC2 & ReDSL.FC2.
Initializing the CNN model with the parameters of the ImageNet-trained models.
Two approaches to retrain the CNN model:
1) Refining with class labels.
2) Refining with side information.
Image Datasets

general image database: “ImageNet”
object image database: “Caltech256”
landmark image datasets: “Oxford” and “Paris”
facial image dataset: “Pubfig83LFW”.


Results
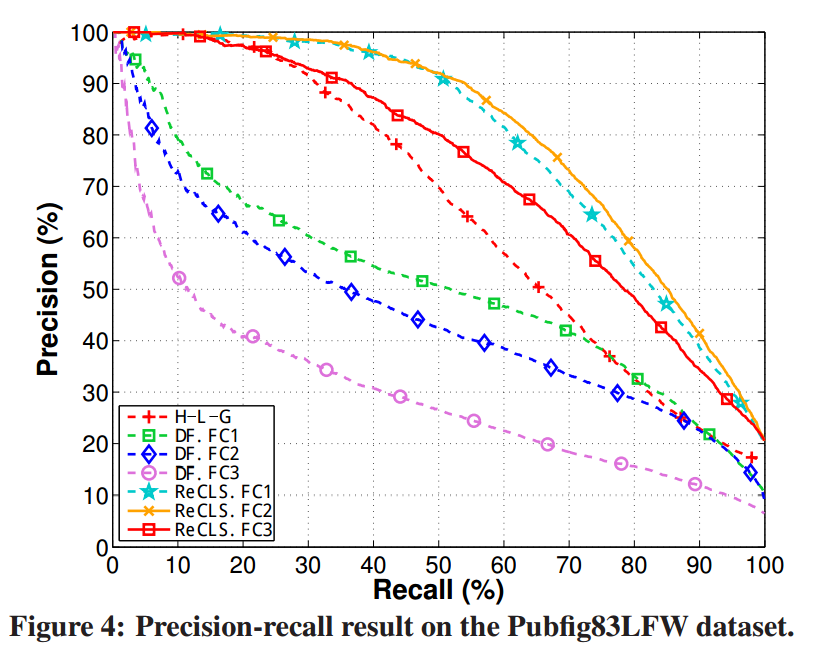
ReCLS: Refining with class labels (Scheme III)
DF: Direct Representation (Scheme I)
H-L-G: Hog-LBP-Gabor: fuses three kinds of famous facial image representation features
Pubfig83LFW: is an open-universe web facial image dataset, which combines two widely used face databases: PubFig83 and LFW
Thank You!
Deep Learning&Content-Based Image Retrieval
By Saeid Balaneshin Kordan



