Webscraping :
enjeux techniques et éthiques
Alexandre Cebeillac (Post-Doc UMR IDEES)
Sébastien Rey-Coyrehourcq (IGR UMR IDEES)
15 nov. 2019 -Paris

Axe SMS - 7 juin
Déroulement de la présentation :
Première partie
* Généralités sur Internet
* Principe de collecte des données
Deuxième partie
exemples d'utilisations avec contexte, méthodes, limite et application
Avec API
* Bing
* Flightradar
* Airbnb
Sans API
* Géocache
* MarineTraffic
Conclusion
Difficulté technique
problèméthique
Cycle des données
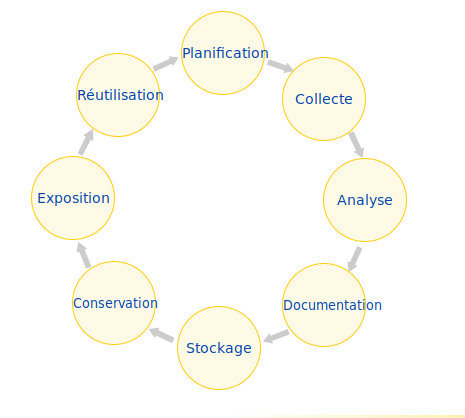
ou ? comment ?
combien de temps ?
comment ?
combien de temps ?
Src : cat.opidor
The Internet

Src : IT Crowd, S03Ep4

Internet n'est pas le Web
Tim bernard lee (gauche), inventor of the WWW (1989)
Vint Cerf (droite), co-inventeur du protocole Tcp/Ip
Internet : 1969 - 2019 (50 ans en octobre)
World Wide Web : 1989 - 2019 (30 ans en octobre)
The Internet
1ère couche : Infrastructures physiques

The Internet
"LOGIN"

ex: TCP/IP
2 ème couche : Protocoles !
The Internet
Résolution DNS

1.2.2.1
2.4.3.1
5.1.1.2



3.4.2.1



2.4.3.1

5.1.1.2
6.1.4.2
DNS
DNS
DNS
en.wikipedia.org = ?
see 2.4.3.1
DNS .org
see 5.1.1.2
DNS
wikipedia.org
see 6.1.4.2
DNS
xxx.wikipedia.org
en.wikipedia.org = 6.1.4.2
The Internet
6.1.4.2
3.4.2.1
HTTP
Résolution HTTP (en théorie)
GET / /HTTP/1.1
Host: en.wikipedia.orgHTTP/1.1 200 OK
...
<html>
<head>
<title>Wikipedia EN</title>
</head>
<body>
<p>Hello World</p>
</body>
</html>

Résolution classique

Synchrone
Page web / scraping
Une page HTML ?

<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<link rel="stylesheet" href="css/style.css">
<title>Test</title>
</head>
<body>
<h1> Ma page web </h1>
<p> Hello World </p>
</body>
<script src="js/script.js"></script>
</html>let d = new Date();
document.body.innerHTML = "<h1>Today's date is " + d + "</h1>"body {
background-color: #0080ff;
}
h1 {
color: #fff;
font-family: Arial, Helvetica, sans-serif;
}
html
head
title
body
h1
p
Extraction
(xPath, CSS, Regex, etc.)
Librairies/Frameworks

SGBD
Navigateurs
wrapper
selenium
python
R
Xml
Curl
SSL
choisir la bonne entrée en fonction des usages
Librairies/Frameworks
rtweet
WikipediR
Collect lib.
Extract lib.
lxml
bs4
html5lib
urllib3
requests
selenium
pyCurl
Collect lib.
Extract lib.
xml2
selectr
stringr
httr
selenium
curl
rvest
scrapy
PYTHON
R
choisir la bonne entrée en fonction des usages
Tweepy
Applications
Évacuations massives
ANR Escape (2016 - 2020) / Eric Daudé
"Contribuer à la conception de systèmes d’aide à la décision dans le cas d’évacuations massives"
Un des objectifs :
Simuler les mobilités en cas de catastrophes (industrielles ou naturelles). Multisites
Comment ?
Simulation à base d'agents
Préalable :
Connaître les comportements de mobilités en condition "normale"
==> Intérêt des conditions de trafic
(en plus des EMD)
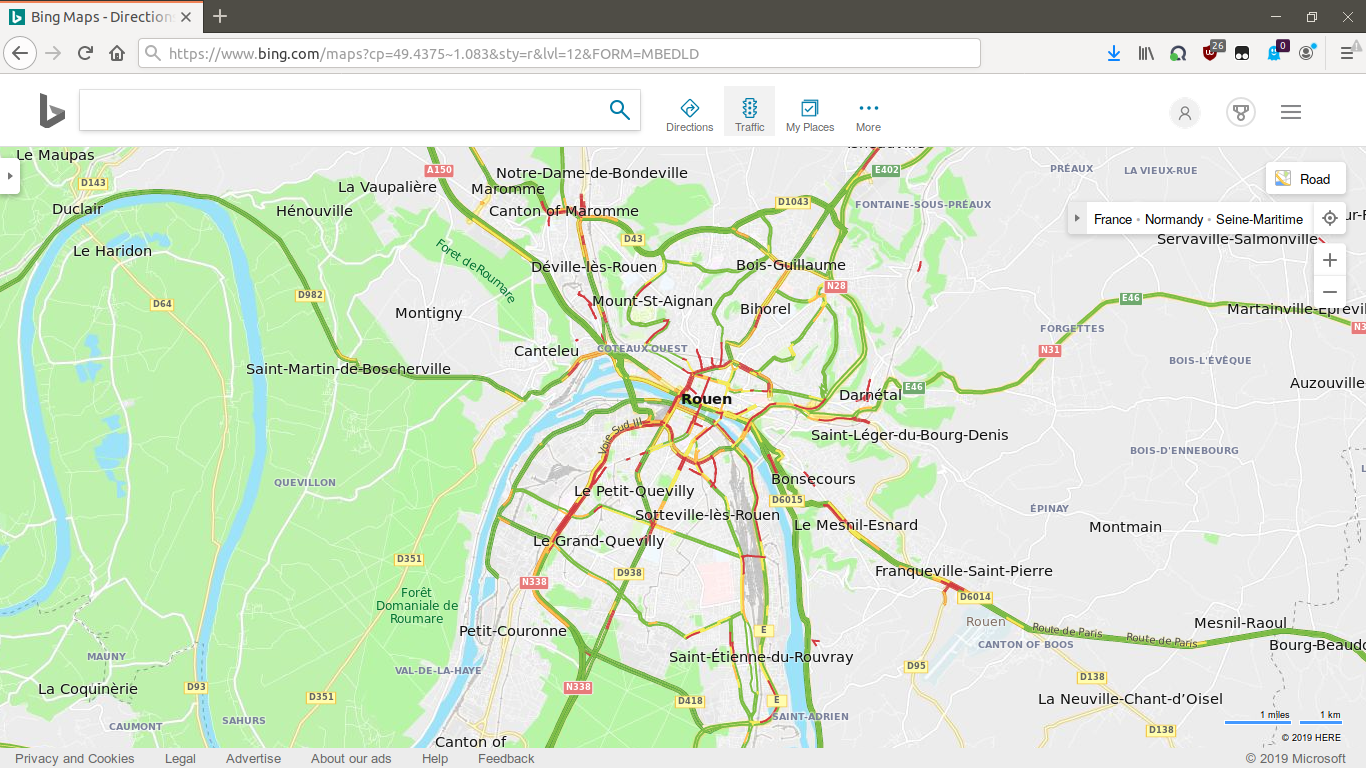

Condition de circulation
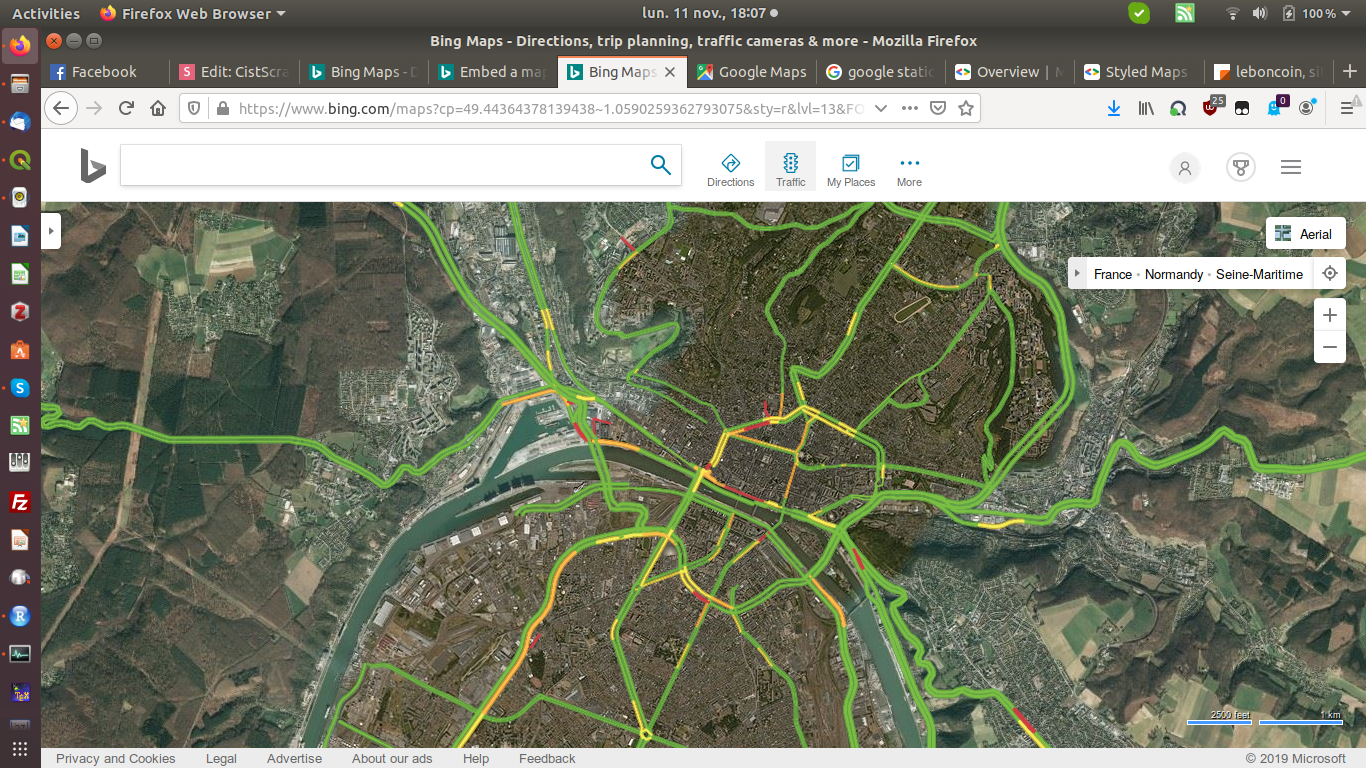
Site web : /www.bing.com/maps
Langage : R
Type de récolte : Campagne
Format : Raster (image)
Avantages & limites :
- Collecter et reprojecter des images
- Extraire les conditions de circulation
Principe :
- Trafic en temps réel
- Disponible dans 55 pays
- Méthodologie de Bing inconnue
Bing Map (Microsoft)
Collecte en temps réel des conditions de circulation
Condition de circulation
Exemple : Bing Map (Microsoft)
Collecte en temps réel des conditions de circulation
"As part of efforts on learning about traffic flows from data, researchers at Microsoft Research explored methods that enhance the safety and privacy of people who wish to help with the “crowdsourcing” of real-time flows of road data from their mobile GPS data. Principles of community sensing have been developed. These principles center on working with people under a “privacy budget” based on the use of the computations of the value of information for understanding flows over time on the road network"
https://www.microsoft.com/en-us/research/project/predictive-analytics-for-traffic/?from=http%3A%2F%2Fresearch.microsoft.com%2Fen-us%2Fprojects%2Fclearflow%2F
Condition de trafic
Projeter l'image connaissant :
Centre de l'image :
Longitude =1.083
Latitude = 49.4375
Niveau de zoom : 12
Projection Bing :
ici UTM 31N
Résolution d'un pixel (m) :
156543.04 * cos(lat) / (2 ^ zoom)
Première approche : capture d'écran
Condition de trafic
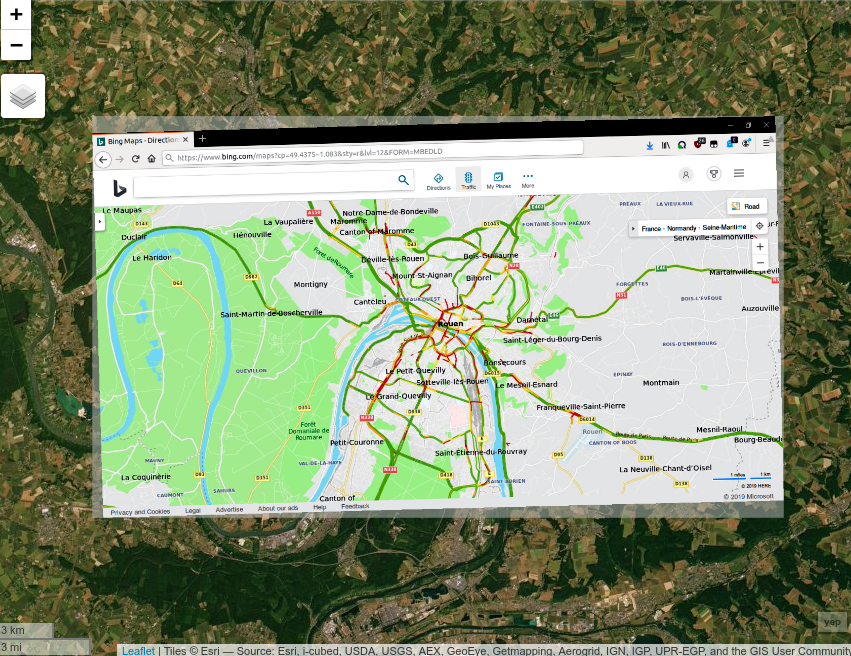
Prochaine étape : extraire les conditions de trafic
Condition de trafic
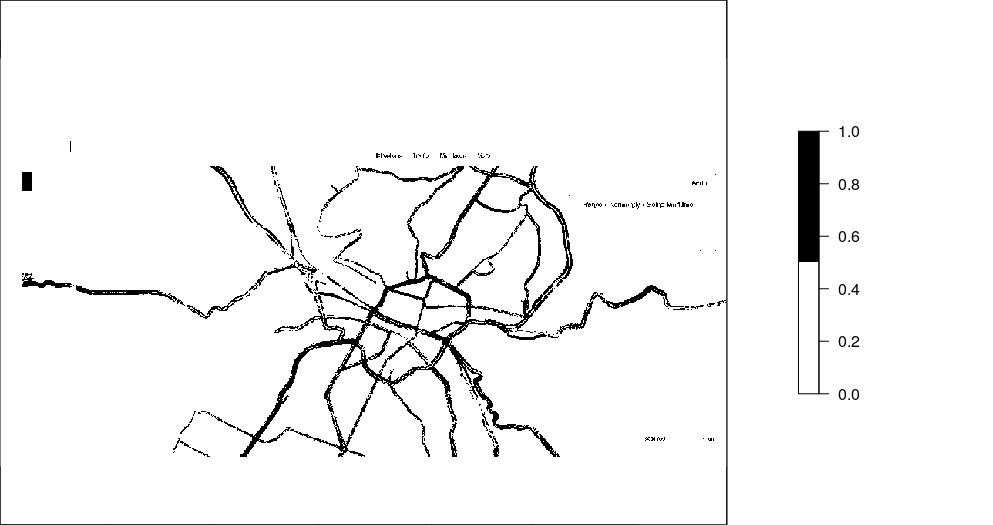
-
image avec trafic
image avec sans trafic
Masque
Condition de trafic
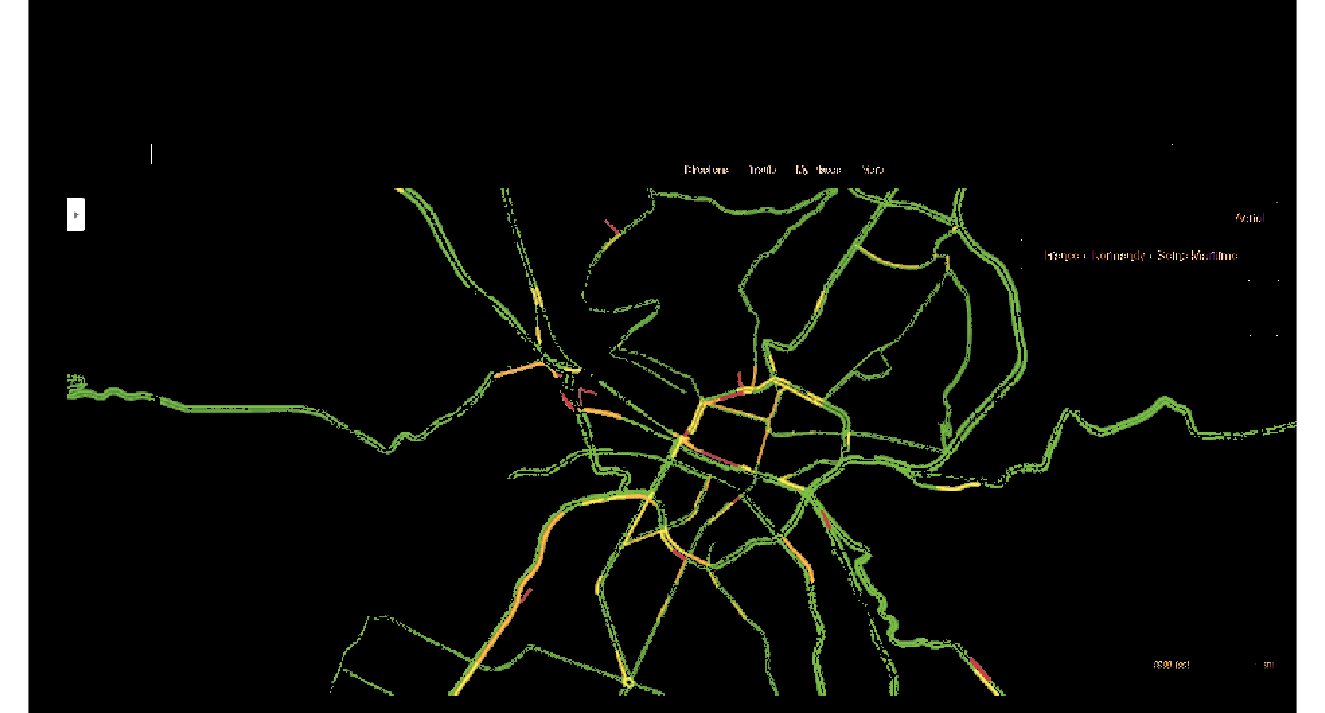
X
image avec trafic
Masque
(H) API !
Application Programming Interface
[ ...] is a set of features and rules that exist inside a software program (the application) enabling interaction with it through software - as opposed to a human user interface. The API can be seen as a simple contract (the interface) between the application offering it and other items, such as third party software or hardware.




Condition de trafic
2ème approche : Utiliser l'API pour récupérer une carte statique
https://dev.virtualearth.net/REST/V1/Imagery/Mapstyle/ lat,lon/zoom/?mapLayer=TrafficFlow&key=Token&autresparamètres
Adapter les paramètres pour obtenir une carte avec fond noir, sans texte :
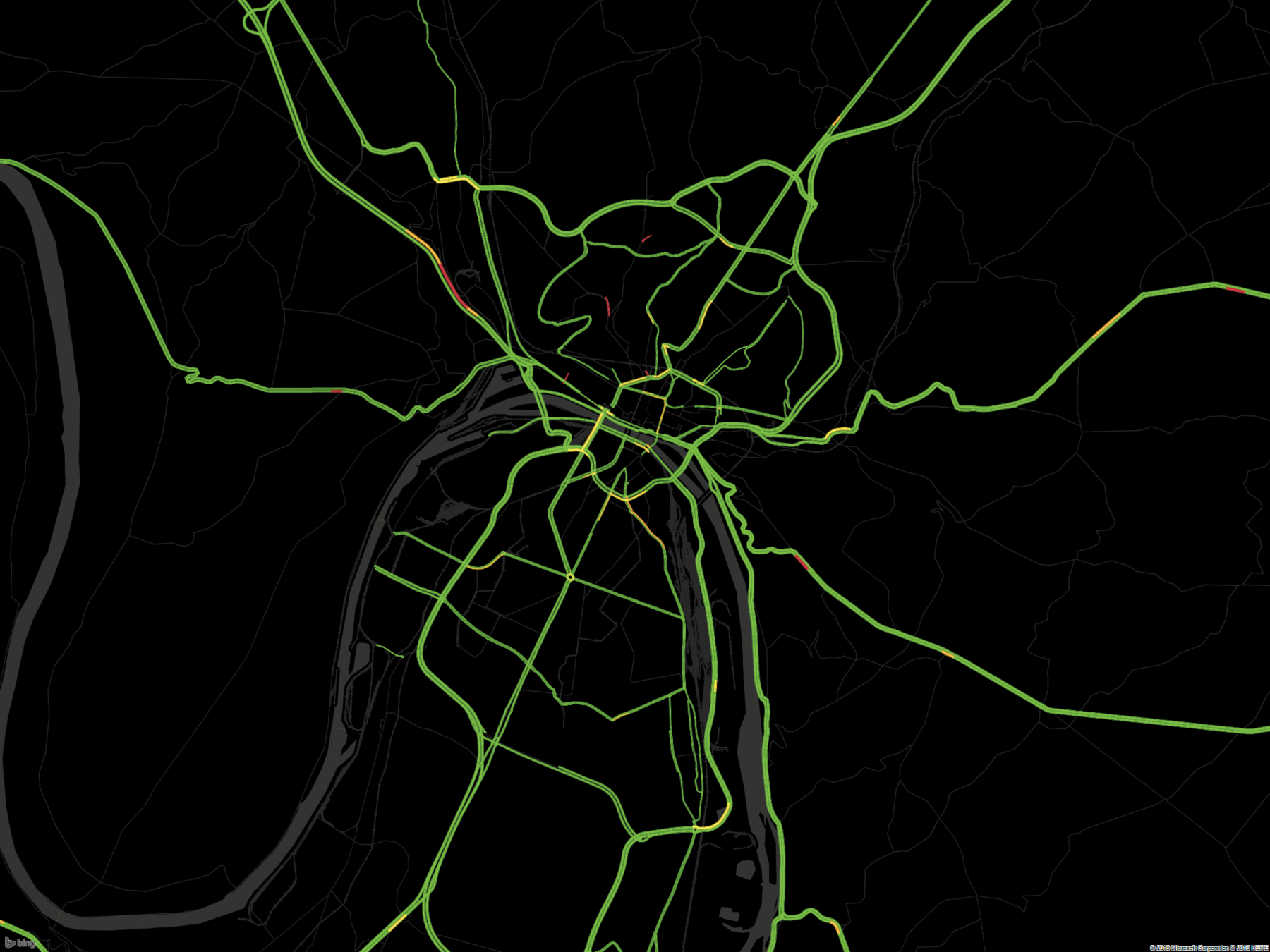
Sélection des pixels vert, jaune et rouge
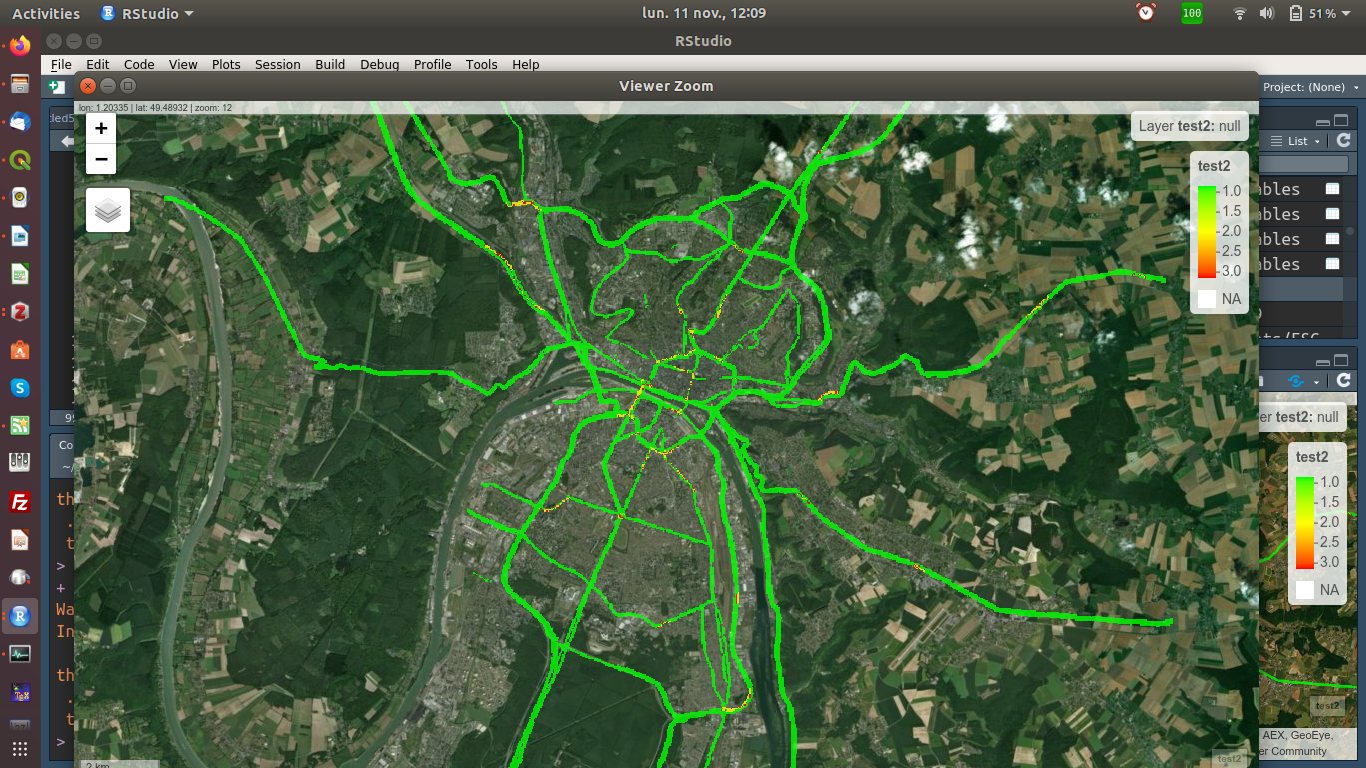
Condition de trafic
+ données comptages & enquêtes EMD
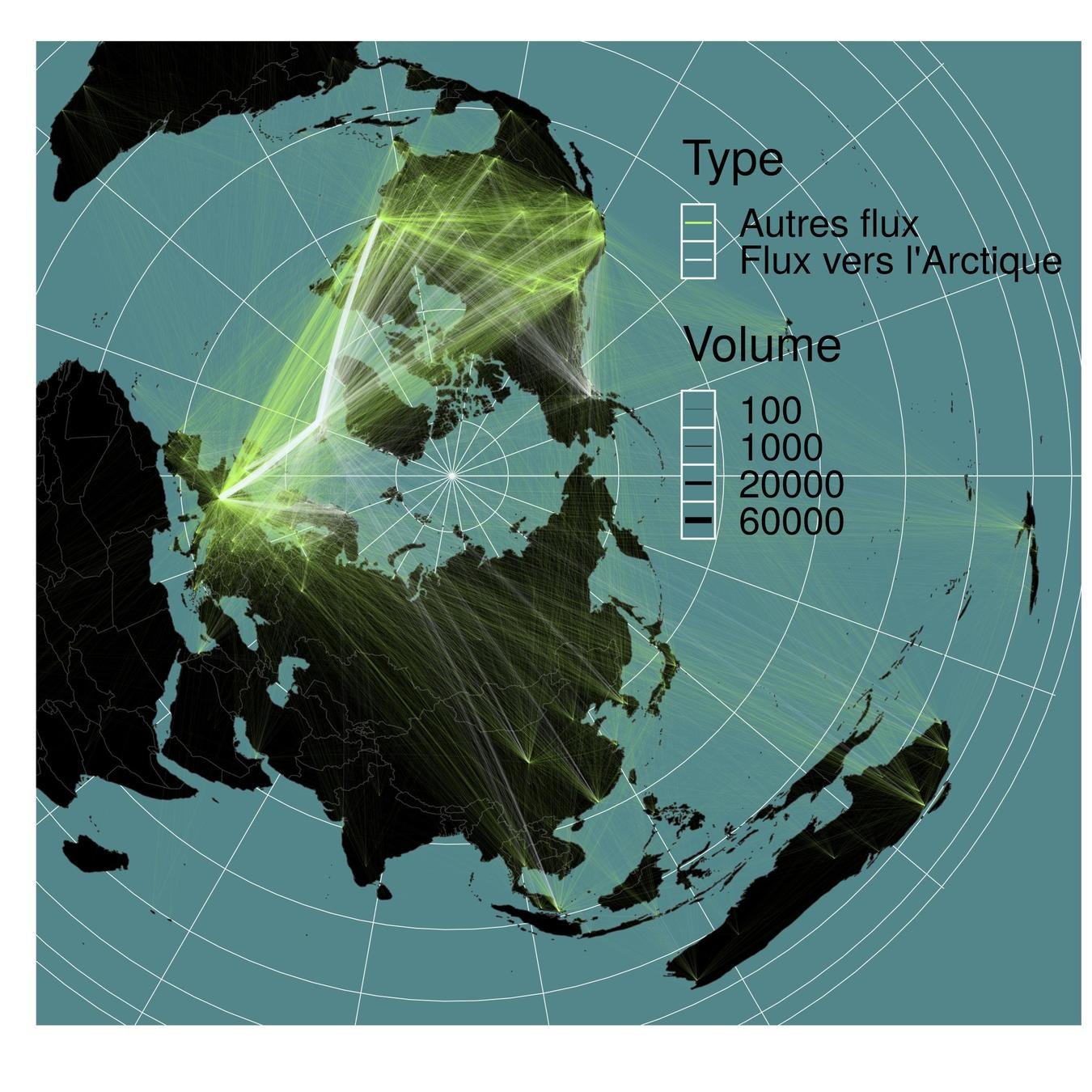
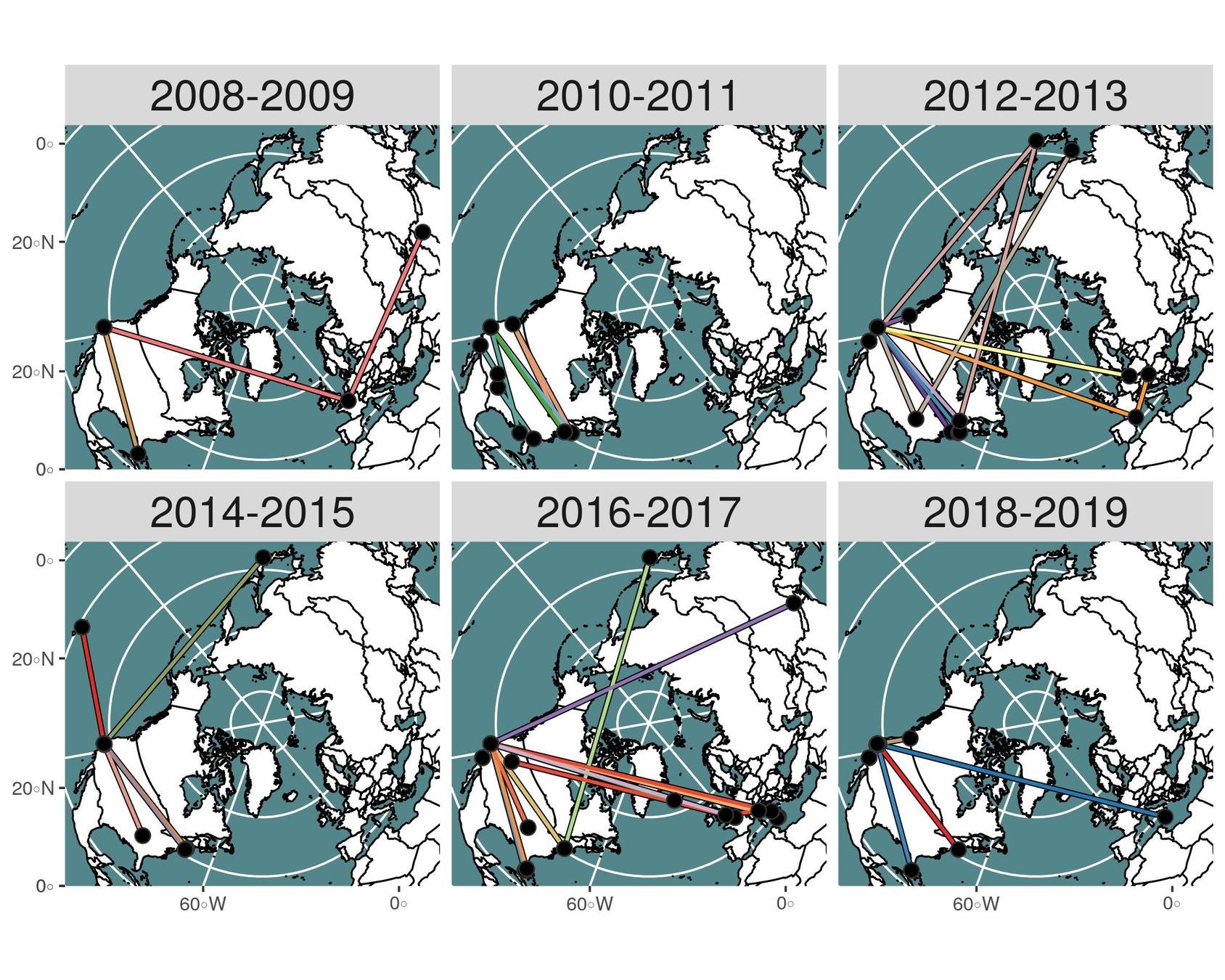
Arctique & système monde
ANR PUR (2016 - 2020) / Yvette Vaguet
Intégration des zones urbaines arctiques dans le système monde
Un des objectifs :
Analyser temporellement les flux affectant les zones arctiques, notamment les flux aériens.
Comment ?
En créant des réseaux à partir des données les plus appropriées et accessibles

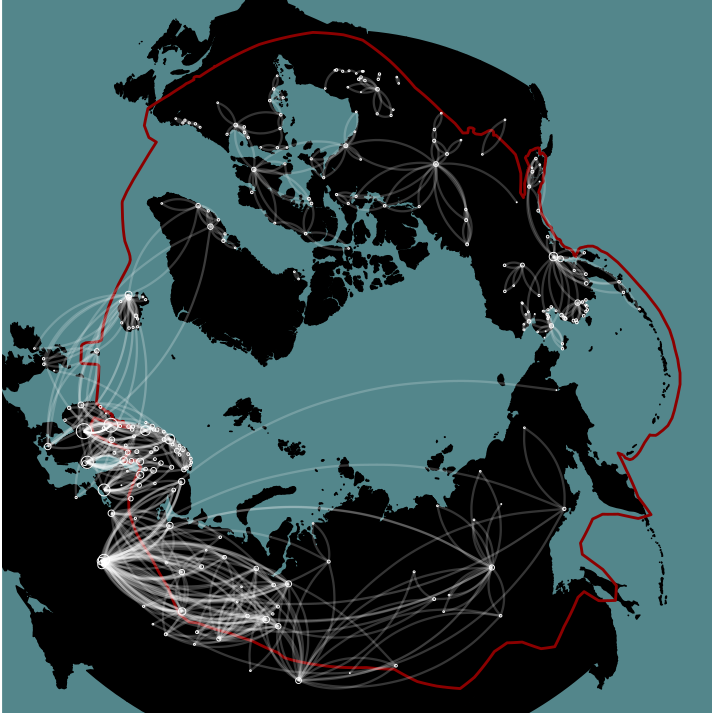
FlightRadar
ANR PUR (2015 - 2019) / Yvette Vaguet
Récuperer les départs et arrivées d'avions pour les aéroports mondiaux pendant plus d'un an
Site web : flightradar24.com
Langage : Python
Framework : Scrapy
Type de récolte : Continue (depuis le 2018/06/10)
Format : mongoDB / Json
Difficultés :
- architecture technique pour une récolte continue
- gestion des timezones
- intégration/consolidation des données SGBD (work in progress)
flightradar
24
FlightRadar
API REST via appel XHR

json
limité à 100 départs/arrivées
query = 'https://api.flightradar24.com/common/v1/airport.json?code= &plugin\[\]=&plugin-setting\[schedule\]\[mode\]=&plugin-setting\[schedule\]\[timestamp\]= &page= &limit=100&token='
{code} = code aéroport IATA
{page} = numéro de la page
{code}
{timestamp}
{page}
{timestamp} = date de la requête
h24 & 7j/7
Focus sur les données ...
src : tom gauld

1 req. ~2 secondes
~ 4 heures de collecte
2 jours en échecs
json non structuré
~ 20 Go / an
800Mo / jour
SGBD
Variabilité +/- grande des sources !
intégration : vérification,
consolidation
+ bonus RPGD
impacte
Structuration des données

h24 & 7j/7
Time / TimeZone Nightmare !

Les jours font 24 h
... Heure d'été ....
Un jour fait 86400 secondes
... Secondes intercalaires ....
Les timezones sont stables
... NON ....
TZ Server = UTC
... Par convention oui mais ....
GMT = UTC
Non. UTC n'a pas de DST

zachholman.com
h24 & 7j/7
Quelle(s) infrastructure(s) pour y arriver ?

Docker
Production

Prototypage
python
python
container
container
import/export
h24 & 7j/7
Quelle(s) infrastructure(s) pour y arriver ?
VM vs Docker ?
- micro-services (1 container = 1 application)
- plus simple
- plus flexible
- consome moins de ressources
- facilite la reproductibilité
Dockerfile
docker-compose.yml
Image 1
organisation logique

h24 & 7j/7
Quelle(s) infrastructure(s) pour y arriver ?
FlightRadar
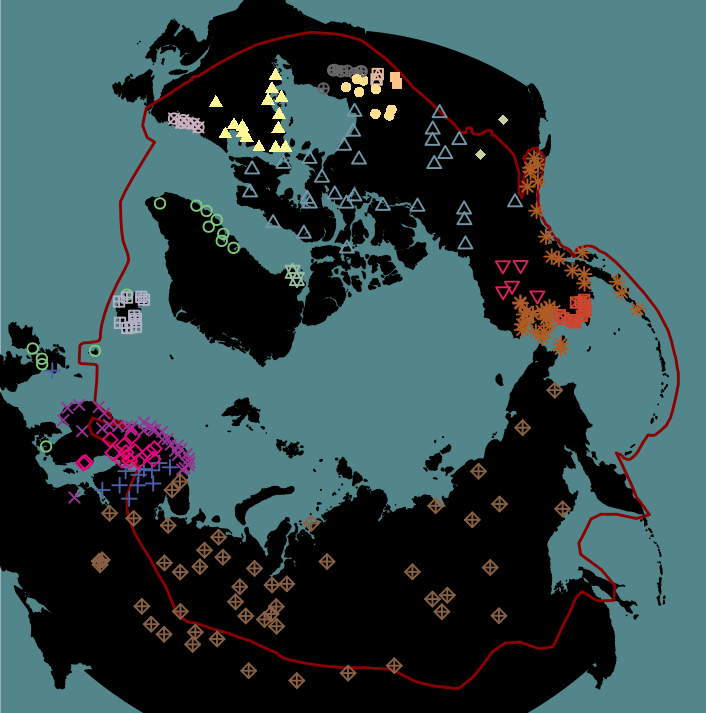
Clustering (louvain)
Vol vers la zone arctique
Arctique & système monde
ANR PUR (2016 - 2020) / Yvette Vaguet
Intégration des zones arctiques dans le système monde

Un des objectifs :
Analyser temporellement les flux affectant les zones arctiques, dont les flux touristiques.
Pourquoi ?
"Tourism is a powerful global force that is turning the north into a Global North—tied into the Global South by facing the same global problem" (Veijola and Strauss-Mazzullo, 2019)
Comment ?
En créant des réseaux à partir des données les plus appropriées et accessibles

https://news.airbnb.com/fast-facts/
Airbnb
Collecter des données permettant de former un réseau de flux touristiques vers l'Arctique
Site web : airbnb.com
Langage : R
Framework : rvest / httr
Type de récolte : Campagne
Format : Json
Caractéristiques :
- Accessible via code source
- (+) Plusieurs API officieuses & pas de token privé
- (-) 80 requêtes / min / IP ==> temps de collecte long
- Des extractions de zones (insideairbnb) mais que dans certaines villes
- Des codes sont disponibles (Tom Slee) python, mais pas sous R
Airbnb : Listing
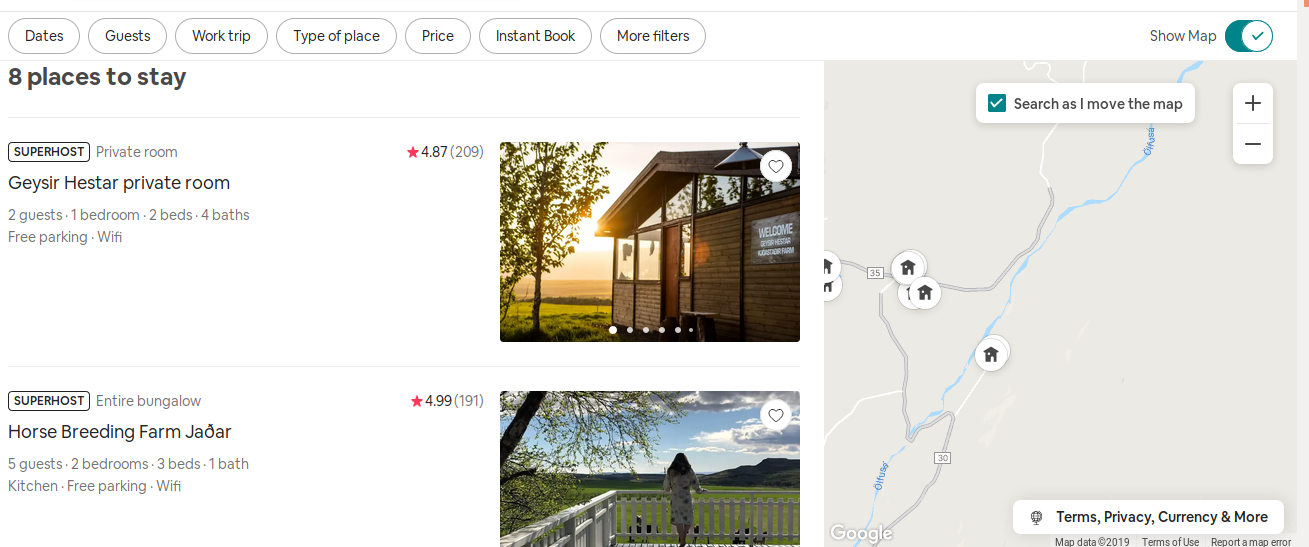
Liste de logements dans une fenêtre géographique donnée
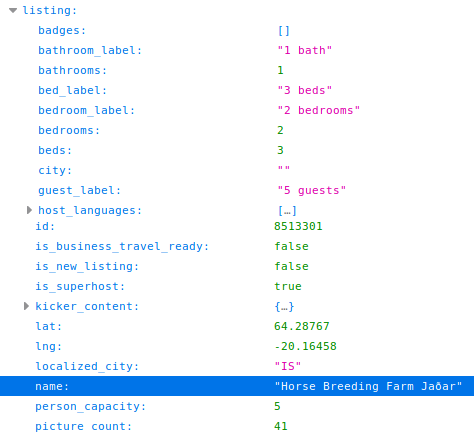
Via l'API :
=> Collecte des informations
ex : host id, place id, lon/lat, etc.
Airbnb
Protocole :
1. Collecter les logements (listing) dans notre zone d'étude (fenêtres mobiles)
==> identifiant du propriétaire et du logement + localisation
2. Liste des personnes ayant visité un de ces logements
==> liste des personnes ayant laissé un commentaire
==> localisation du domicile (déclaré)
3. Collecter tous les commentaires concernant ces personnes.
==> Liste des personnes accueillies ou hébergées (+ localisation)
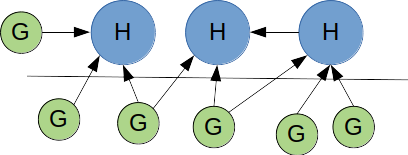
zone
d'étude
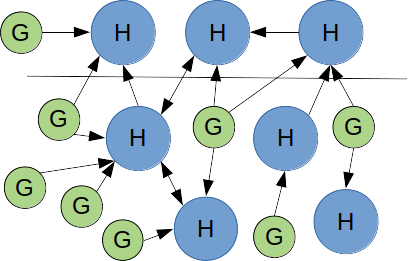
H= Host (hébergeur)
G : Guest (visiteur)
Airbnb : commentaires
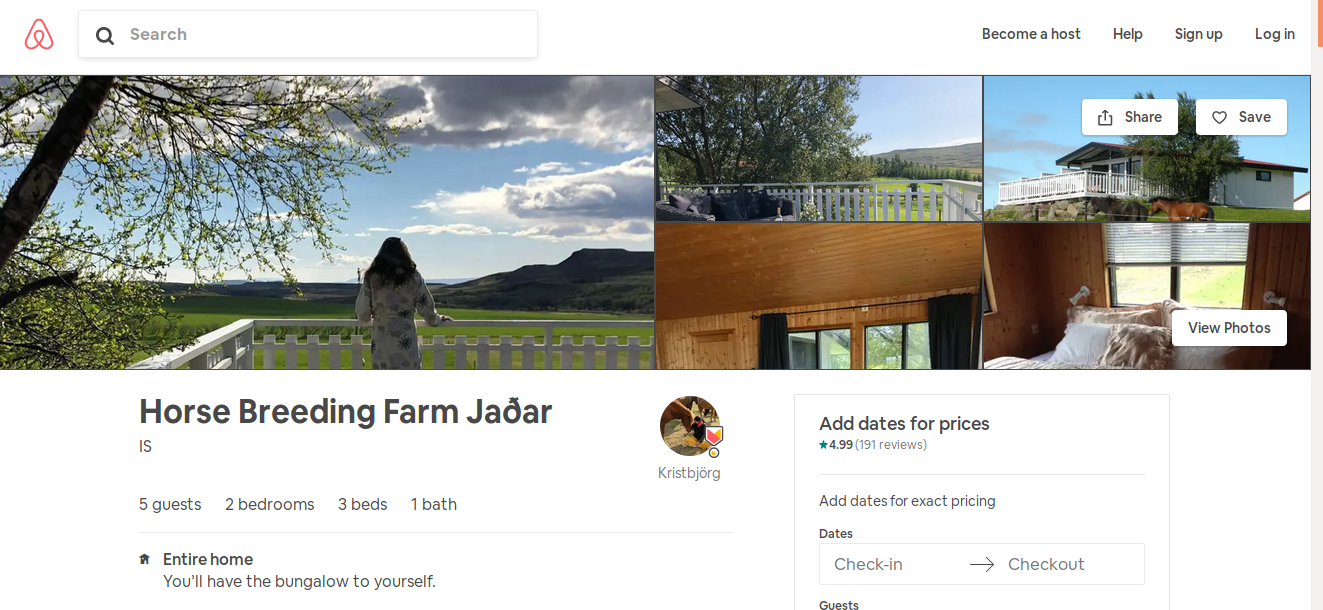
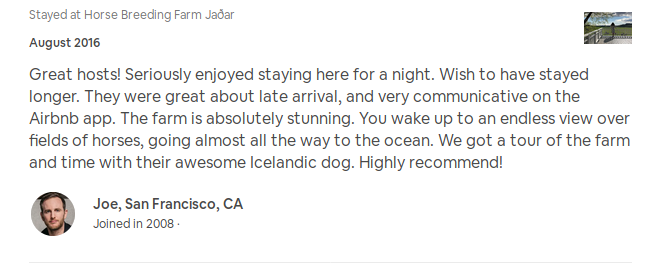
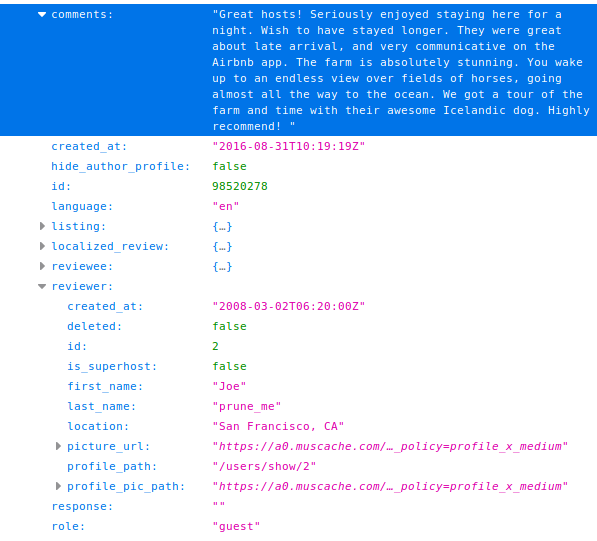
Page du logement
Commentaires :
Via l'API :
==> Date, identifiant, rôle, lieu déclaré, de toutes les personnes ayant commenté
https://www.airbnb.com/rooms/8513301
Idem pour la page de l'utilisateur : informations sur les visiteurs ou visités
Airbnb
Création de réseau :
- ~24K offres de locations (coordonnées précises)
- visitées par 537057 personnes (domicile déclaratif)
- qui ont laissé 4 millions de commentaires
- chez 634453 personnes (domicile déclaratif)
Durée de la collecte : plusieurs semaines
Airbnb



Airbnb
- Hey Joe!? Where are you going (...) ?
- I'm going downtown (...)
- Uh, hey Joe, I heard you (...)
Mobilités urbaines
FP7 DENFREE & ANR MO3 / Eric Daudé
Modéliser et simuler les épidémies de dengue

Un des objectifs :
Comprendre le rôle des mobilités quotidiennes dans la propagation des épidémies à Bangkok & Delhi
Moyen :
Créer un modèle de mobilité, individu centré, à base d'agents (couplé à d'autres modèles)
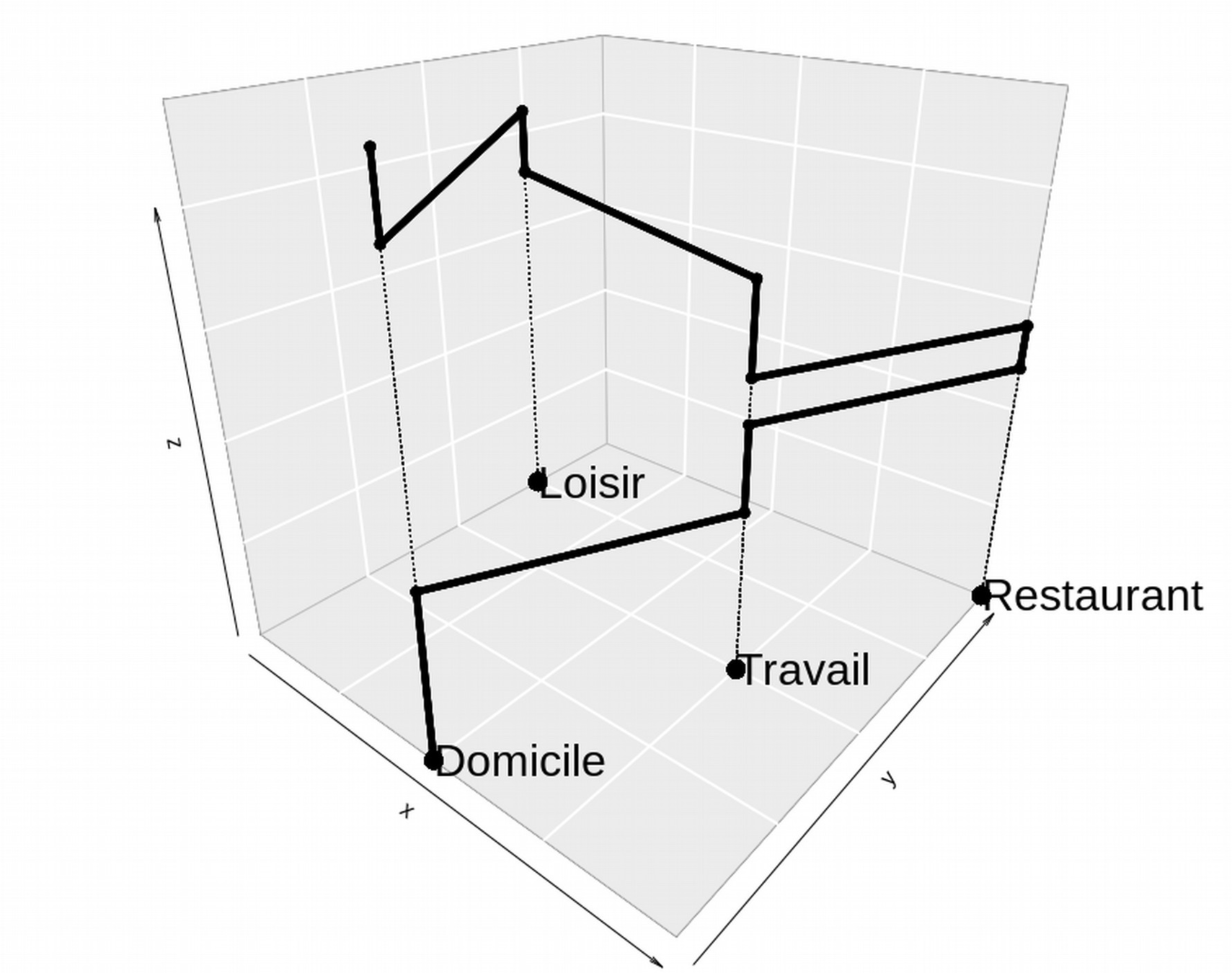
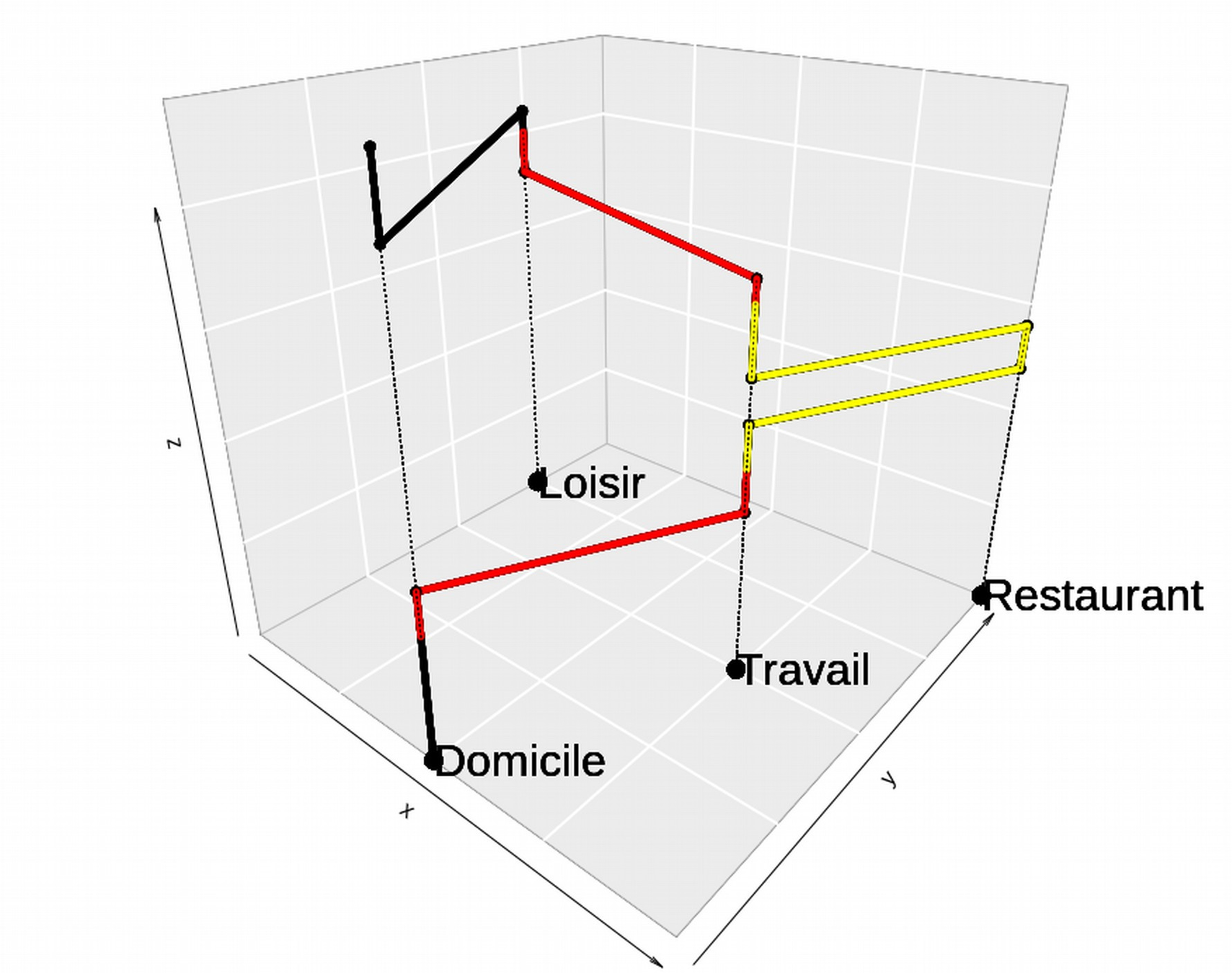
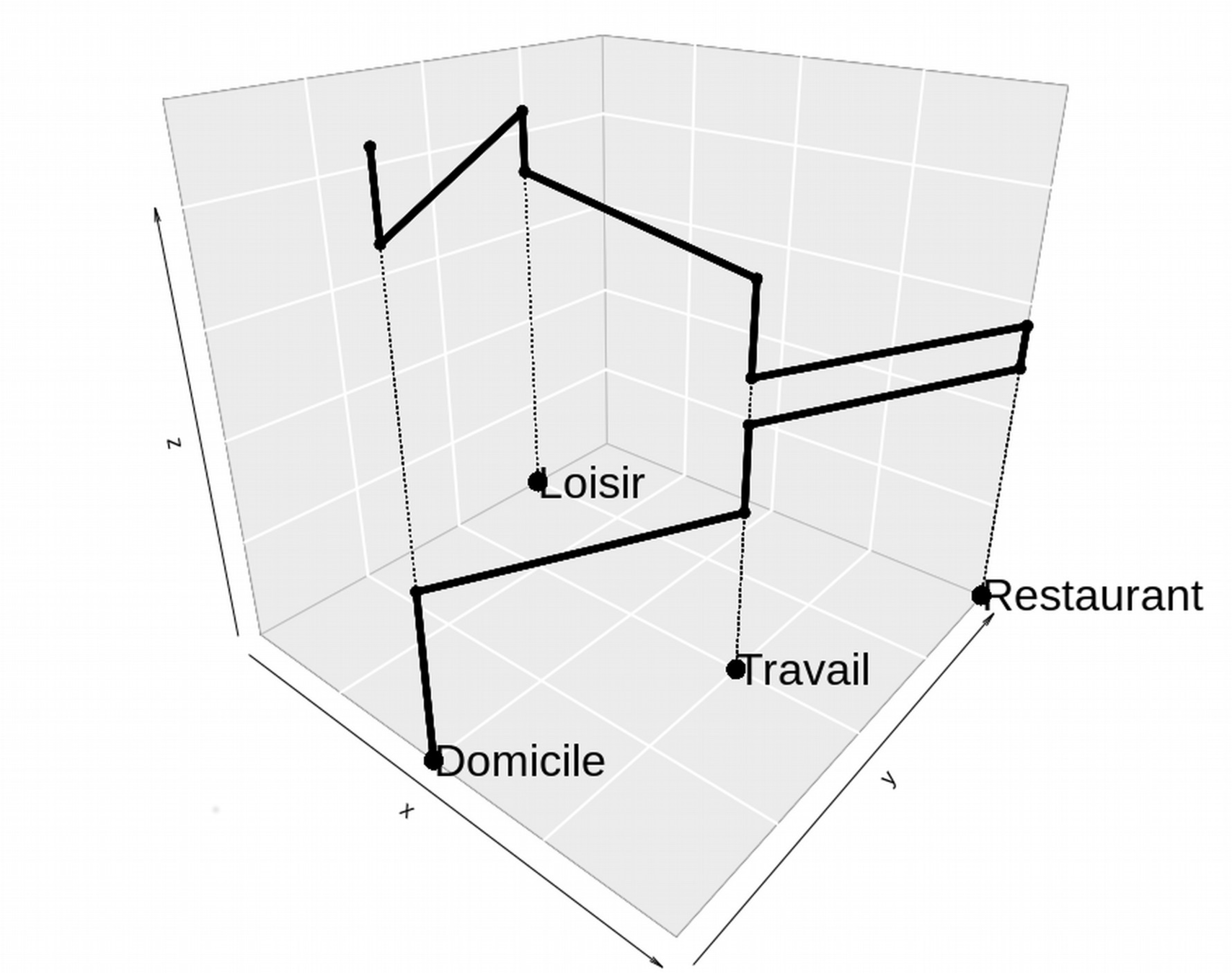
Concept d'espace d'activité
Un des enjeux :
Collecte de données de mobilité





stream_tweets("location",token)
~300 millions d'utilisateurs
mensuels
Juin 2014 – Décembre 2015 : Bangkok (~10M Hab.)
Données brutes ~ 30M de tweets / ~300K utilisateurs
Données filtrées ⇒ 17M / ~76K utilisateurs
~1% des tweets
globaux
Twitter & géolocalisation
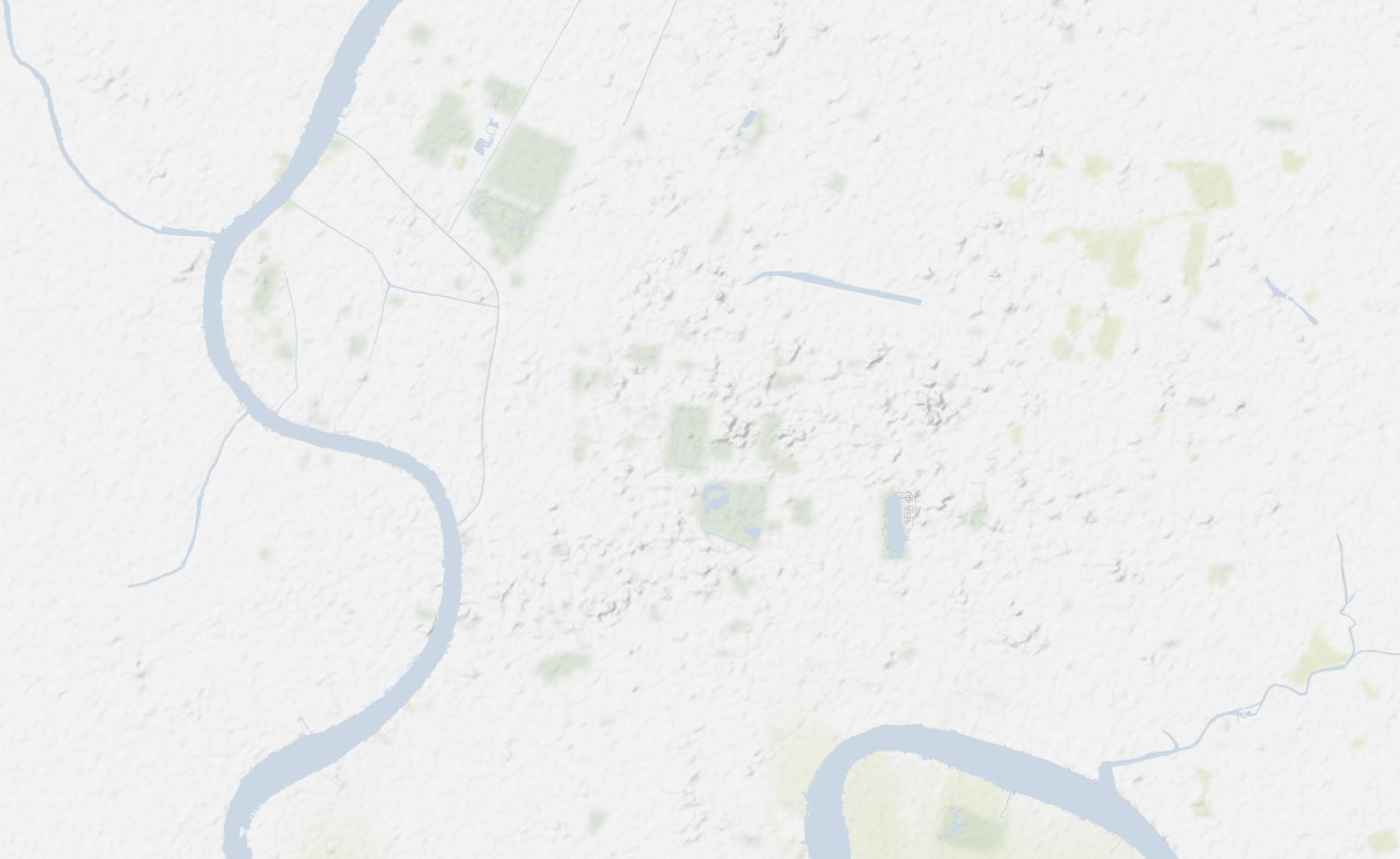

Majorité de tweets le soir
==> Domicile
Majorité de tweets en journée
==> Lieux de travail
?
?
Espace d'activité incomplet...
=> Couche d'utilisation du sol ? OSM ?
peu développé à Bangkok ...
Google maps
Site web : google maps
Langage : Python ou R
Framework : Scrapy / httr
Type de récolte : Campagne
Format : json
Difficultés :
- Nécessite un jeton (API)
- Requêtes gratuites limitées
- Zone d'étude importante : Bangkok
- hiérarchisation de l'information renvoyées
- Évolution des conditions d'utilisation de l'API

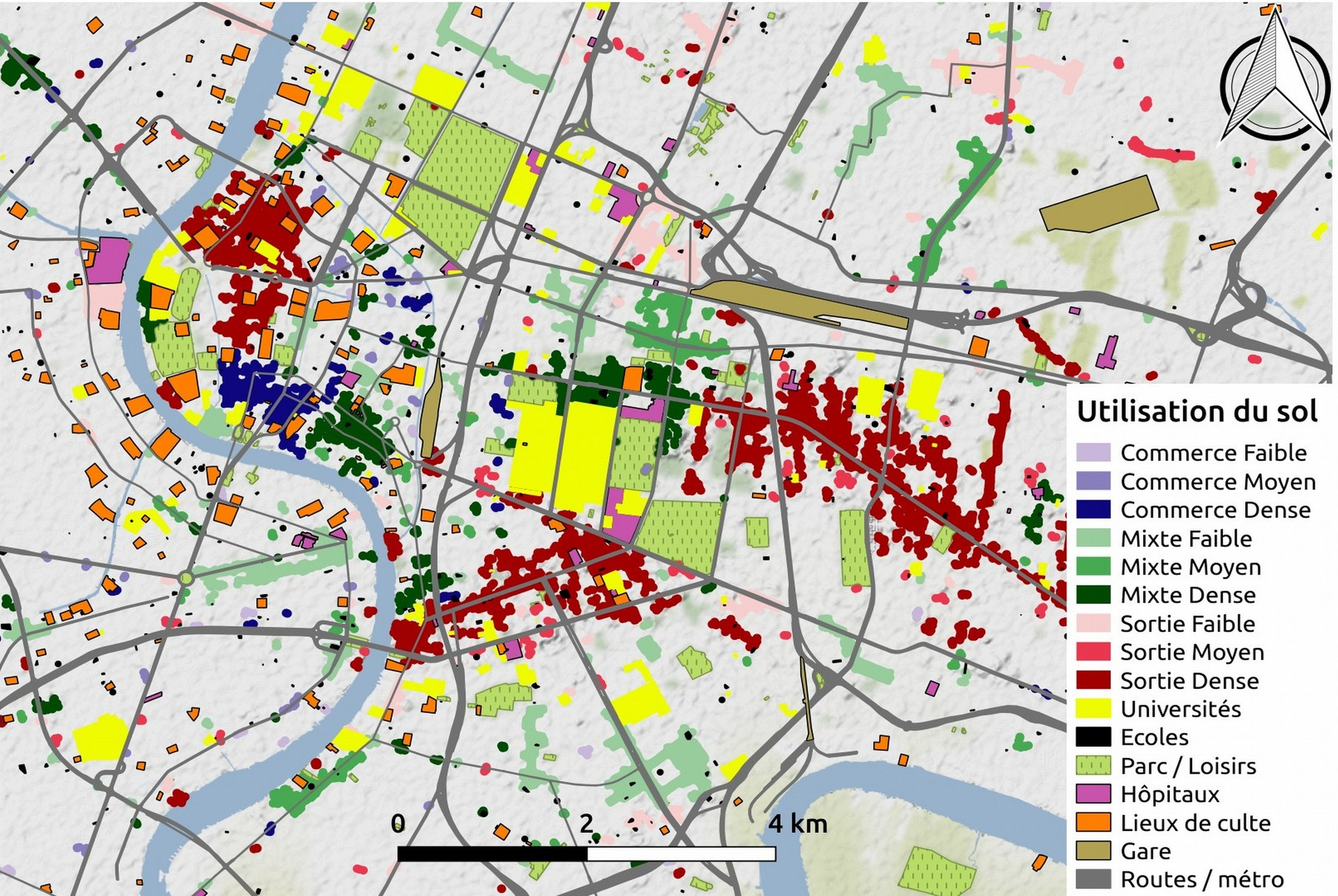
Collecter des informations sur l'utilisation du sol à Bangkok pour compléter l'espace d'activité Twitter
Google maps
- POI : Point of Interest ⇒ Localisation et catégorie des lieux de la base
Google maps
- POI : Point of Interest ⇒ Localisation et catégorie des lieux de la base
- Fonction « nearby search » de l’API Place
https://maps.googleapis.com/maps/api/place/nearbysearch/json?location=LAT,LON&types=*&radius=100&key=TOKEN
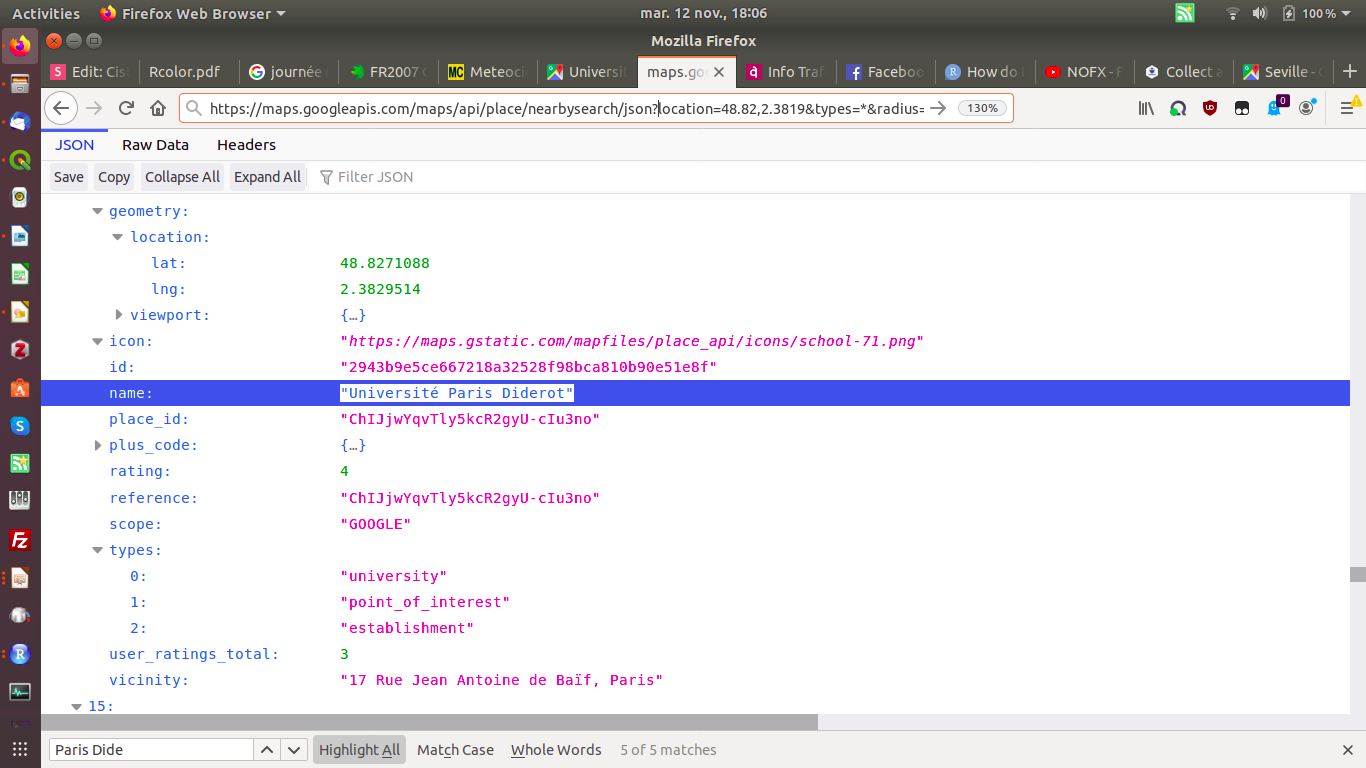
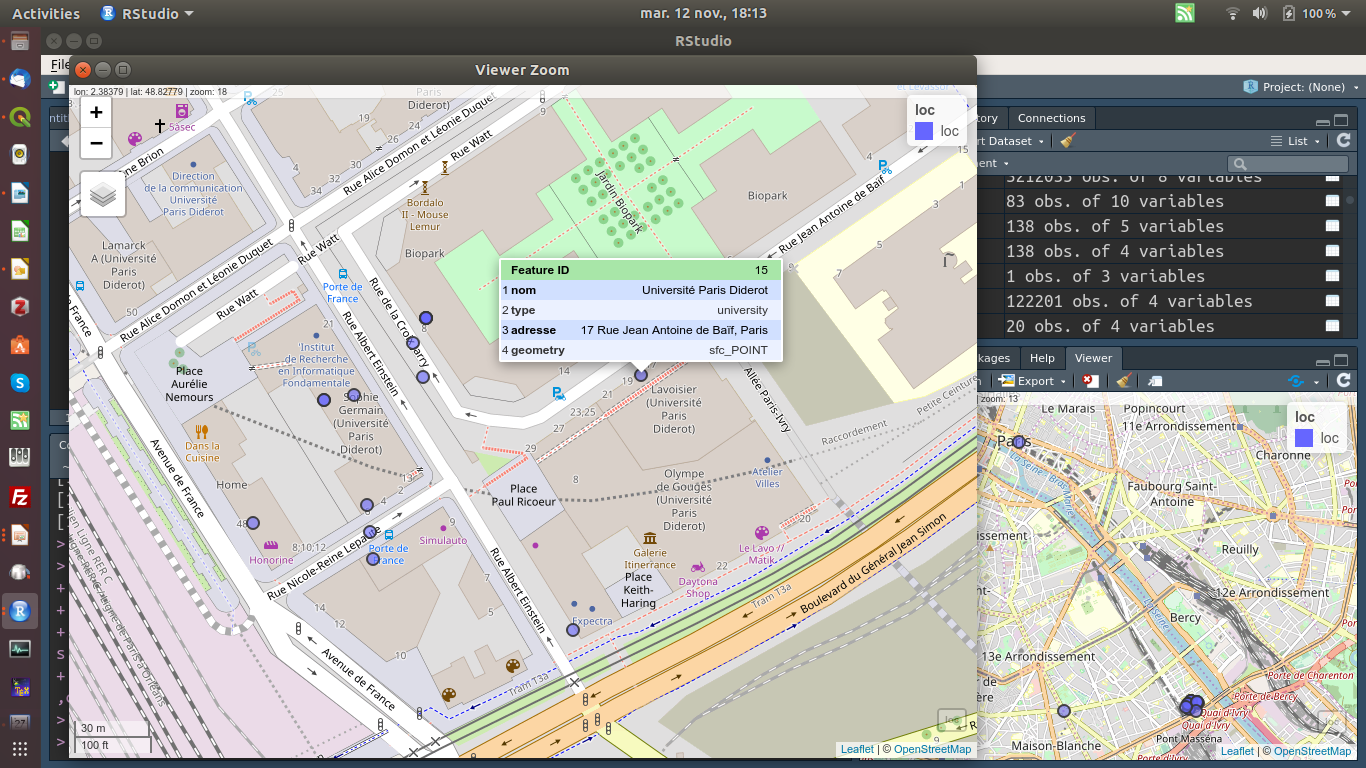
+ Fenêtre mobile
Google maps
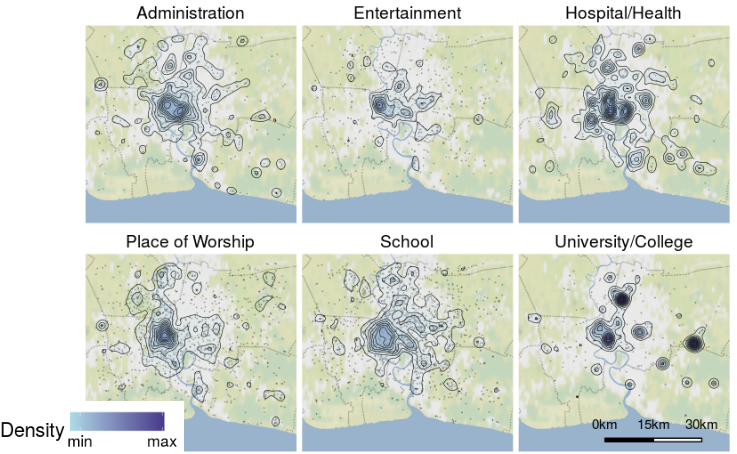
Bangkok :
~ 100K POI
~100 catégories
Nombre limite de requêtes quotidiennes gratuites :
~2000 jusqu'en juin 2018 ; 5 aujourd'hui
AOI: « Areas of Interest - places where there's a lot of activities and things to do (..) We determine areas of interest with an algorithmic process that allows us to highlight the areas with the highest concentration of restaurants, bars and shops »
API « Static Map »
⇒ Afficher le fond de carte (ggmap, R)
⇒ Enregistrer l’image
⇒ Extraire les pixels selon leur couleur
S’inspirer de la composition des AOI en POI
⇒ Générer de nouveaux AOI
⇒ Typologie
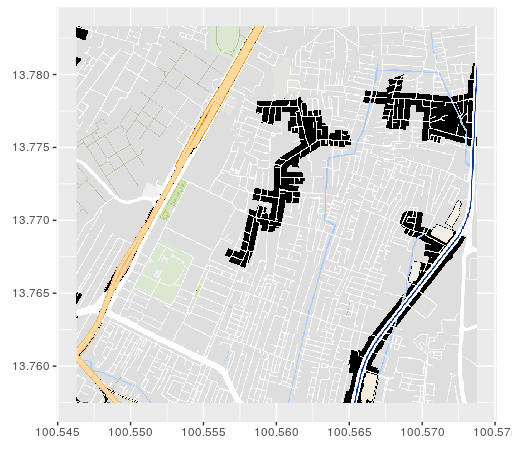
Twitter & Google maps
Twitter & Google
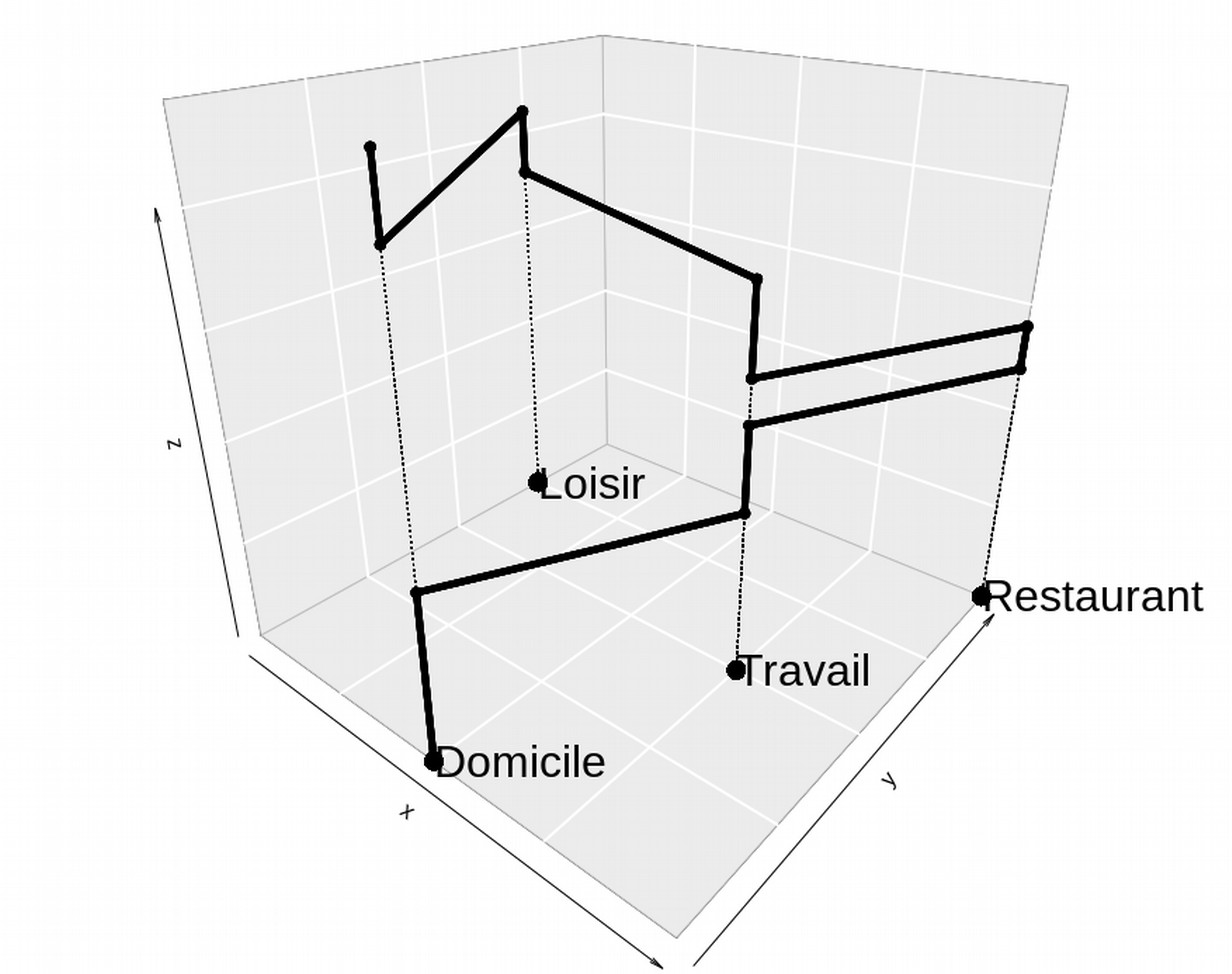
Pour chaque utilisateur de Twitter :
- Reconstruire des espaces d'activités hypothétiques
Coté modélisateur :
- utiliser les statistiques de visites pour générer des agents synthétiques mobiles
(Cebeillac & al, 2017,2018a,b)
Twitter & Google
Quelques précautions pour améliorer le niveau d'anonymat des personnes :
- Changement du nom de l'utilisateur
- Flou temporel :
- Mardi 10 juillet 2015 18h ==> Mardi 18h
- Séquences de visites ==> Fréquences de visites
- Flou spatial :
- Domicile agrégé au sous district (~arrondissement)
- Autre lieux dans des mailles (250m)
- Flou thématique :
- On ne sait pas exactement quelle activité réalisée ("lieu de sortie", "lieu d'éducation" etc.)
Sécurisation des données :
- Fichiers encryptés sur serveur protégé (Huma-num)
Printemps 2015 : Mise à jour de Twitter :
Désactivation automatique de la géolocalisation aprés l'envoi d'un message géolocalisé
Protocole

Zone de ~turbulence~


web asynchrone
protection anti-bot
WEB asynchrone
Javascript / AJAX

WEB asynchrone
Javascript + React
"What you see is not what you get"
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<link rel="stylesheet" href="css/style.css">
<script src="js/script.js"></script>
<title>Test</title>
</head>
<body>
<h1> Ma page web </h1>
<p> Hello World </p>
</body>
</html>div1
div2

??
??
Protection anti-bot
6.1.4.2
3.4.2.1
HTTP

Content Delivery Network (CDN)

(CloudFlare, Akamai, etc.)
Mise en cache du contenu
Requêtes DNS spatialisées
Protection anti-bot
Content Delivery Network (CDN)
Serveur http
(CloudFlare, Akamai, etc.)
Reverse-Proxy
détection de pattern
capcha
honey pot
filtrage ip
GeoCaching
GRR Trenum (2015 - 2019) / Philippe Vidal
Récupérer toutes les informations sur les ~ 13000 géocaches (1/page) de Normandie à un instant t
Site web : geocaching.com
Langage : Python
Framework : Scrapy
Type de récolte : Campagne
Format : Json
Difficultés :
- Pas d'API & limitation à 1000 résultats par recherche
- Mon premier scraping
- Login/Pwd pour accès à la donnée complète
- ASPX avec gestion des états précédents

GeoCaching
listes des urls
formulaire de selection
scraper 1
json

GeoCaching

navigation dans les pages & remplissage de formulaires

URL des 726 * 20 pages
<form method="post" action="./nearest.aspx" onsubmit="javascript:return WebForm_OnSubmit();" id="aspnetForm">
<div class="aspNetHidden">
<input type="hidden" name="__EVENTTARGET" id="__EVENTTARGET" value="" />
<input type="hidden" name="__EVENTARGUMENT" id="__EVENTARGUMENT" value="" />
<input type="hidden" name="__LASTFOCUS" id="__LASTFOCUS" value="" />
<input type="hidden" name="__VIEWSTATEFIELDCOUNT" id="__VIEWSTATEFIELDCOUNT" value="2" />
<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="wNwKV9Z" />
<input type="hidden" name="__VIEWSTATE1" id="__VIEWSTATE1" value="jFMBVQ" />
</div>
circulation token obligatoire
GeoCaching
listes des urls
page par cache
formulaire de selection
scraper 1
scraper 2
json
json
GeoCaching
N commentaires par cache ...
Analyse textuelle (work in progress)
Arctique & système monde
Intégration des zones arctiques dans le système monde
Flux maritime : Marine Traffic
Trafic maritime
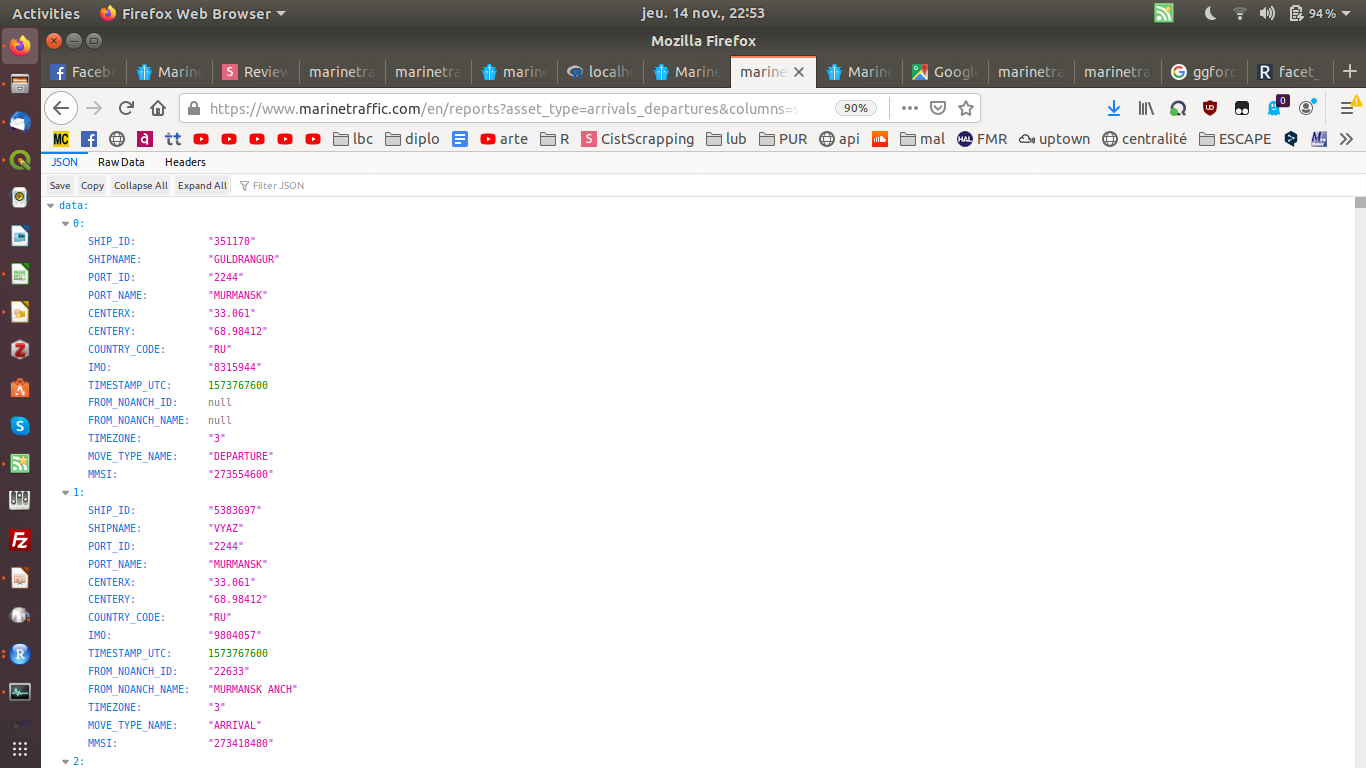
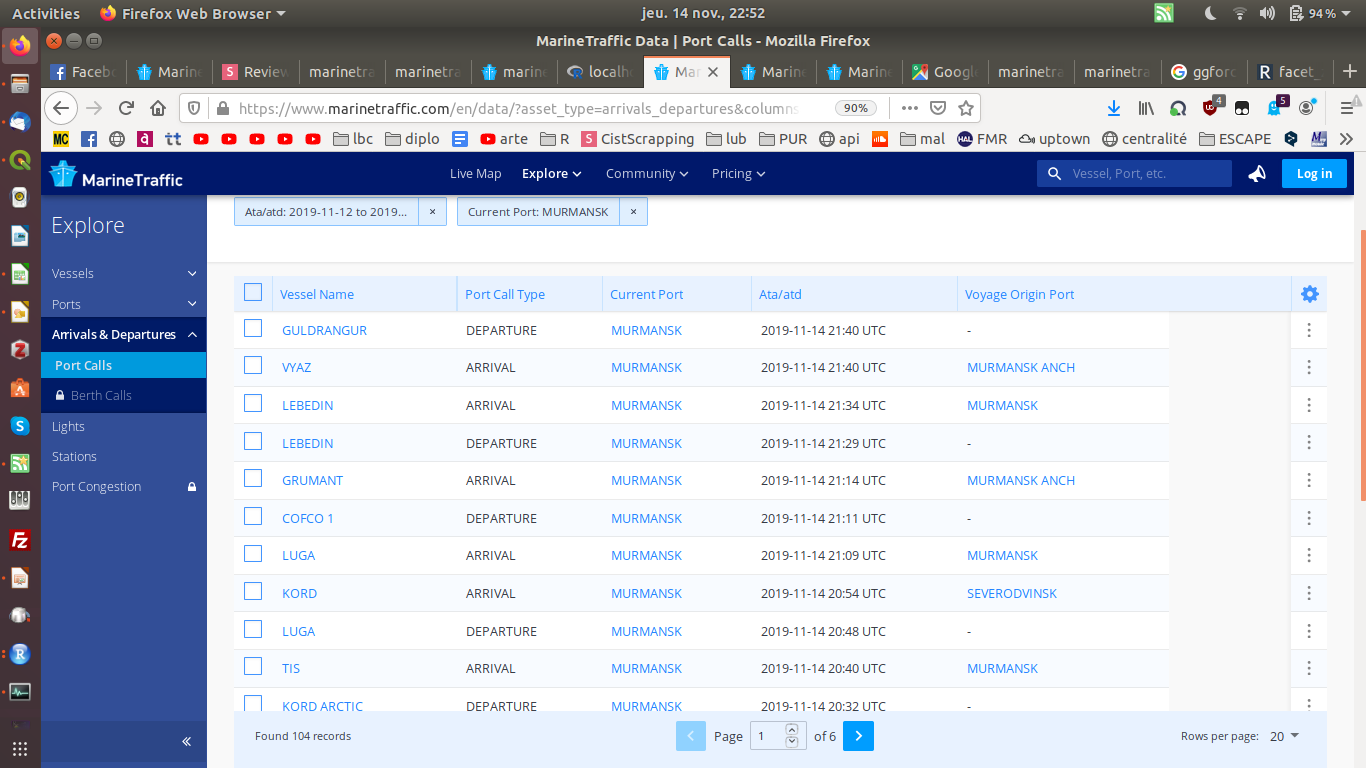

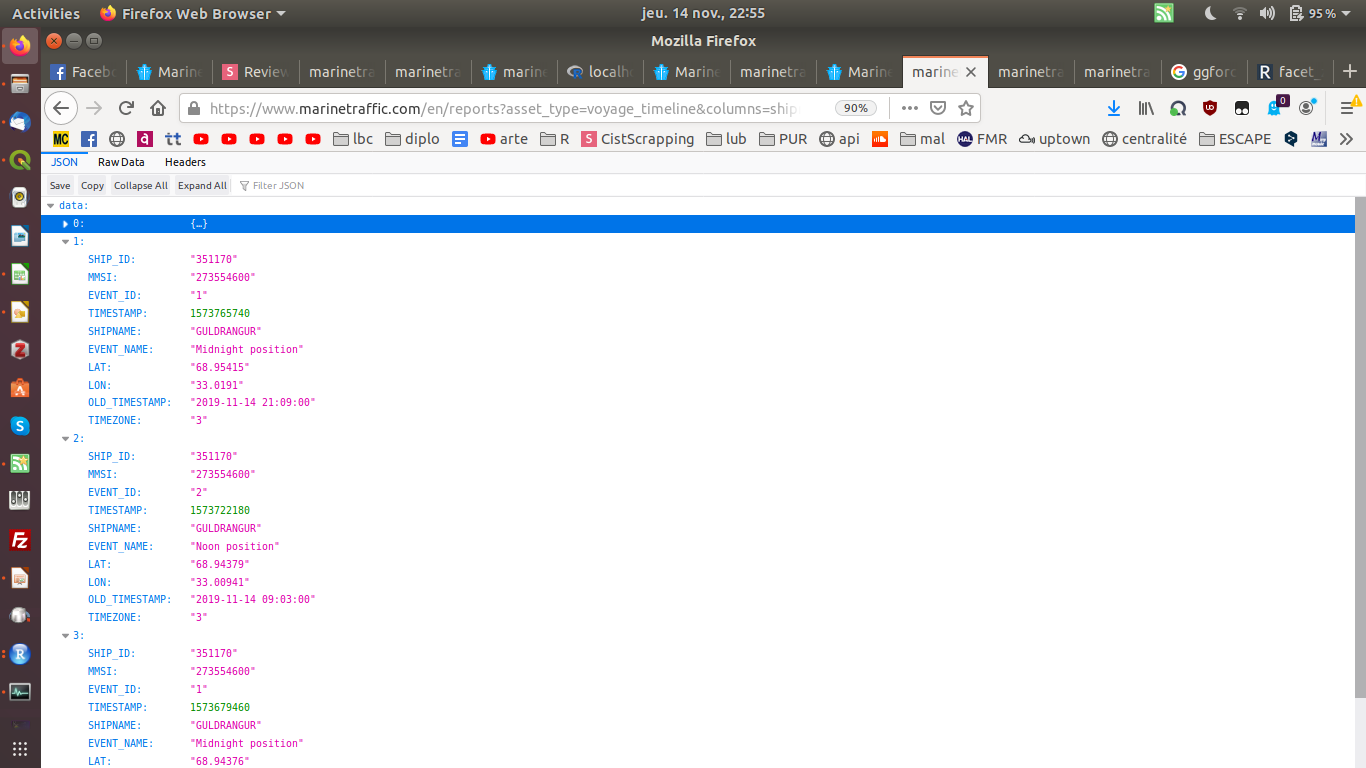
Liste des bateaux dans un port (Murmansk) :
Dernières positions d'un bateau (Guldrangur) :
Même approche que pour Flightradar ?
403 Forbidden
Mr Robot
Server
API générique, multi-langage (Java,Python, R, etc.) pour piloter (envoyer des commandes) à un navigateur sans utiliser l'interface graphique.
web-driver
R, Python, C#, etc.
Selenium tools
firefox
chrome
safari
etc.
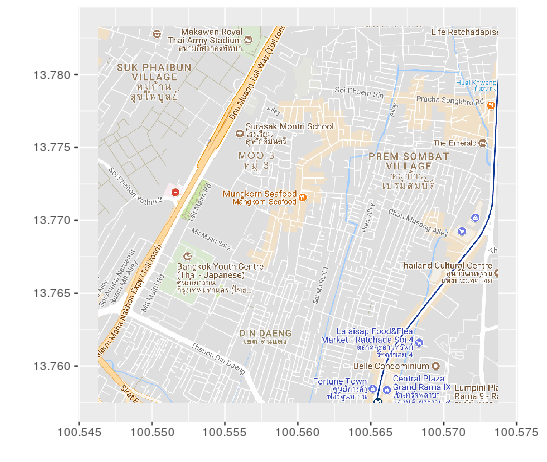
Marine Traffic
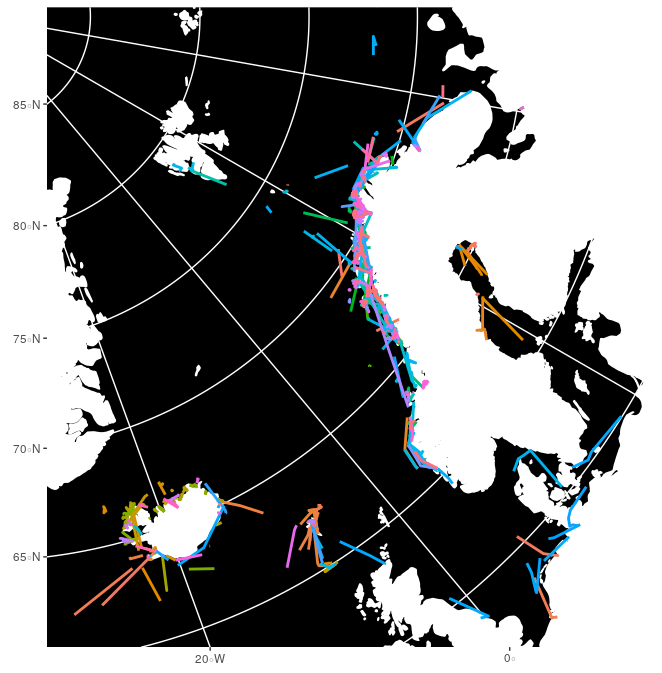
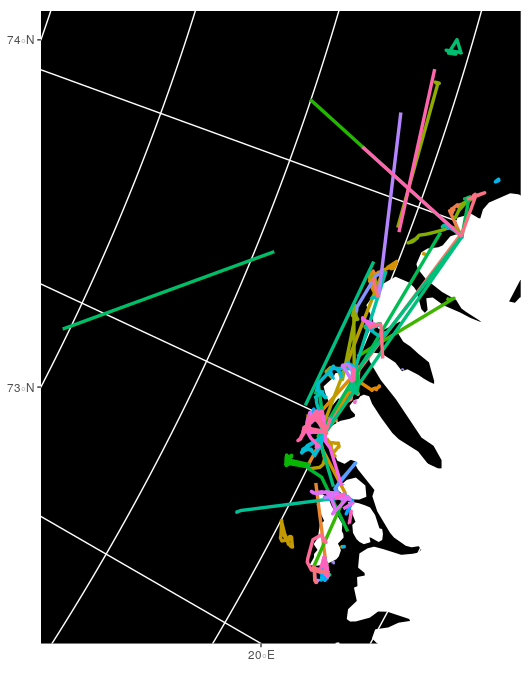
Trajectoire des bateaux sur 2 jours :
Ethique & Technique
pas de risque
complexe
risque elevé
simple
&
api
api
api
api XHR
api XHR
Impact sur la vie privée
VS
complexité de collecte
Enjeux
Méthodologique
Technique
- capture = script ad-hoc
- framework robustesse (h24/7j)
- intégration / structuration pour requetage
Théorique
- Objectif de la capture ?
- anonymisation
- dashboard / accès facile données
- reproductibilite données et scripts
- accessibilité vs sécurité données
- Qualité / Incertitude données
Un tryptique asymétrique
Propose des services & stock les données
(publicité)
Demande rarement
le consentement éclairé
Accède aux données consultable sur le site (webscrapping)
Vend ou donne des échantillons
contrôle l'utilisation (API)
Site Internet
Tiers
Entreprises privés ; Chercheurs ; (Etats?)
Utilisateur
Utilise ou contribue au service ==> participe à la création de données (+/- consciente)
(Schéma simpliste)
Traite des données
produit du contenu
Traite des données (échantillon)
produit du contenu
produit du contenu
Questions ?
le 13/11/2019
Merci de votre attention !
https://slides.com/sebastienreycoyrehourcq/cistscrapping
7juin-axeSMS
By sebastien rey coyrehourcq



