
Getting Started with Apache Spark
Shagun Sodhani
Big Data Training Program, IIT Roorkee
Agenda
- Introduction to Spark.
- How is it different from MapReduce
- Components
- RDD
- Dataframes
- GraphX
- PySpark
- Sample Applications
What is Apache Spark?
- Apache Spark™ is a fast and general engine for large-scale data processing
- Originally developed in AMPLab at UC Berkely (2009), open-sourced in 2010, transferred to Apache 2013
- Claims to run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Advantages Over MapReduce
- Speed.
- Ease of Use - Scala, Java, Python, R.
- Generality - Not just Map and Reduce.
- Runs Everywhere - Hadoop, Mesos, standalone etc.
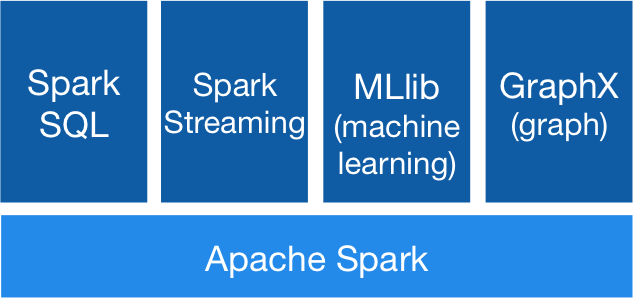
Spark Components
- Spark RDD
- Spark SQL and DataFrames
- Spark Machine Learning (MLlib)
- GraphX
- Spark Streaming
RDD
Resilient Distributed Dataset
- Immutable partitioned collections.
- Lazy and ephemeral
- Building block for other libraries
- Transformations Vs Actions
SQL And DataFames
- Structured data processing.
- Distributed SQL query engine.
- DataFrame is similar to table in RDBMS.
- No indexing.
GraphX and GraphFrame
-
Graphs and graph-parallel computation.
-
Property Graph Model (Directed multigraph).
-
Pregel API.
-
GraphFrame : DataFrame-based Graphs
- Very new - announced less than a month back.
PySpark
Sample Apps
Thank You
Getting Started with Apache Spark
By Shagun Sodhani
Getting Started with Apache Spark
For Big Data Training Program at IIT Roorkee



