
AWS at
Common Crawl
Stephen Merity
We're a non profit that makes
web data
accessible to anyone
Each crawl is billions of pages...
August crawl was
2.8 billion web pages
~200 terabytes uncompressed
Released
totally free
Lives on S3 (Public Data Sets)
Common Crawl Use Cases
Large scale web analysis:
-
WDC Hyperlink Graphs (128 bln edges)
-
Measuring the impact of Google Analytics
-
Web pages referencing / linking to Facebook
-
Wikipedia in-links & in-link text
Natural language processing:
-
Parallel text for machine translation
-
N-gram & language models (975 bln tokens)
- WDC "Collect ALL the web tables" (3.5 bln)
We're the largest public user of
Trivia Time
What major OSS project grew out of Nutch?
Trivia Time
What major OSS project grew out of Nutch?

Crawling Architecture Overview
Standard Hadoop Cluster:
On-demand: One master
Spot Instances: ~60 m2.2xlarge or ~110 m1.xlarge
Generate, Crawl, Export (raw + processed)
2-3 billion pages in 15-20 days
Hadoop is our hammer, handles all the nails
(even if that nail is more like a screw)
Crawling Architecture Overview
Why those instances?
m1.xlarge
- Best all round deal + usually cheap
(1Gbps network, 1.6TB disk, 15GB RAM, ...)
(1Gbps network, 1.6TB disk, 15GB RAM, ...)
m2.2xlarge
- Similar specs to m1.xlarge, less bang for the buck
(Note: ec2instances.info is insanely useful)
Topics for Advanced AWS
- Random access archives using S3
- Surviving & thriving w/ spot instances
- EMR - the good, the bad, the ugly
Random Access Archives
In an optimal world,
everything would be in RAM
For one dollar an hour...
-
EC2 RAM = 87 GB
-
EC2 Disk = 10,685 GB
-
S3 (standard) = 24,000 GB
-
S3 (reduced) = 31,000 GB
How do we get advantages of RAM w/ S3?
Random Access Archives
gzip spec allows for gzip files to be stuck together
gzip + gzip + ... + gzip + gzip
Why are we interested?
☑ Re-uses existing data format + tools
☑ Advantages of per object compression (10% larger than full gzip)
☑ Partition into optimal sized collections (Hadoop / S3)
☑ Allow random access to individual objects
URL index
Maps a URL to its location in the archive using
Prefix B-Tree + S3 byte range

5 billion unique URLs x [ len(URL) + len(pointer) ]
= 437 GB
= $13 per month
Topics for Advanced AWS
- Random access archives using S3
- Surviving & thriving w/ spot instances
- EMR - the good, the bad, the ugly
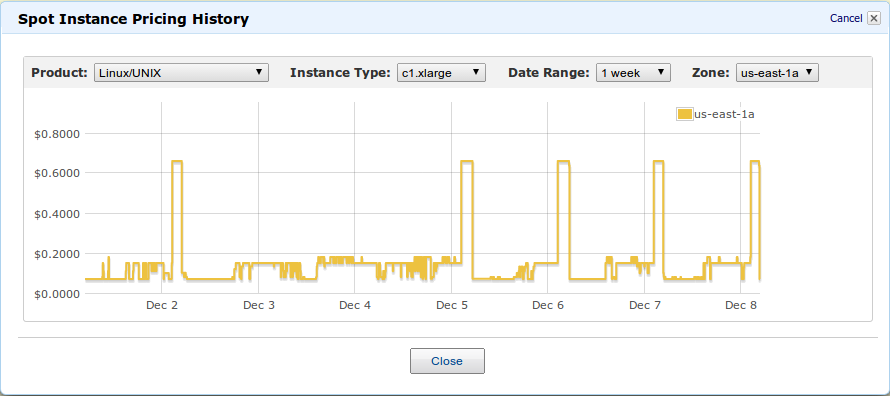
Spot Instances
Spot instances are vital but are problematic...
-
Availability issues
- Cost fluctuations
- Transient failure
Spot Instances
To survive transient failures trivially:
rely on S3 and not HDFS
HDFS is brilliant if disks fail rarely + independently
Solution:
Small jobs + push data to S3 on completion
Spot Instances
If you do need to keep state on HDFS,
rack awareness is vital
Segment your cluster's machines according to:
- Region (minimize transfer costs)
- On-demand versus spot instance
- Machine type (prices mostly independent)
- Spot prices
Topics for Advanced AWS
- Random access archives using S3
- Surviving & thriving w/ spot instances
- EMR - the good, the bad, the ugly
What good is data if it's not used?
Accessing & using it needs to be easy
Elastic MapReduce
= Trading money for simplicity
It's far cheaper to spin up your own cluster...
(✖ 100-200% overhead on spot instances)
m1.xlarge = $0.088 for EMR + $0.040 for spot
For contributors, we're happy to pay however:
time & energy on task and not cluster
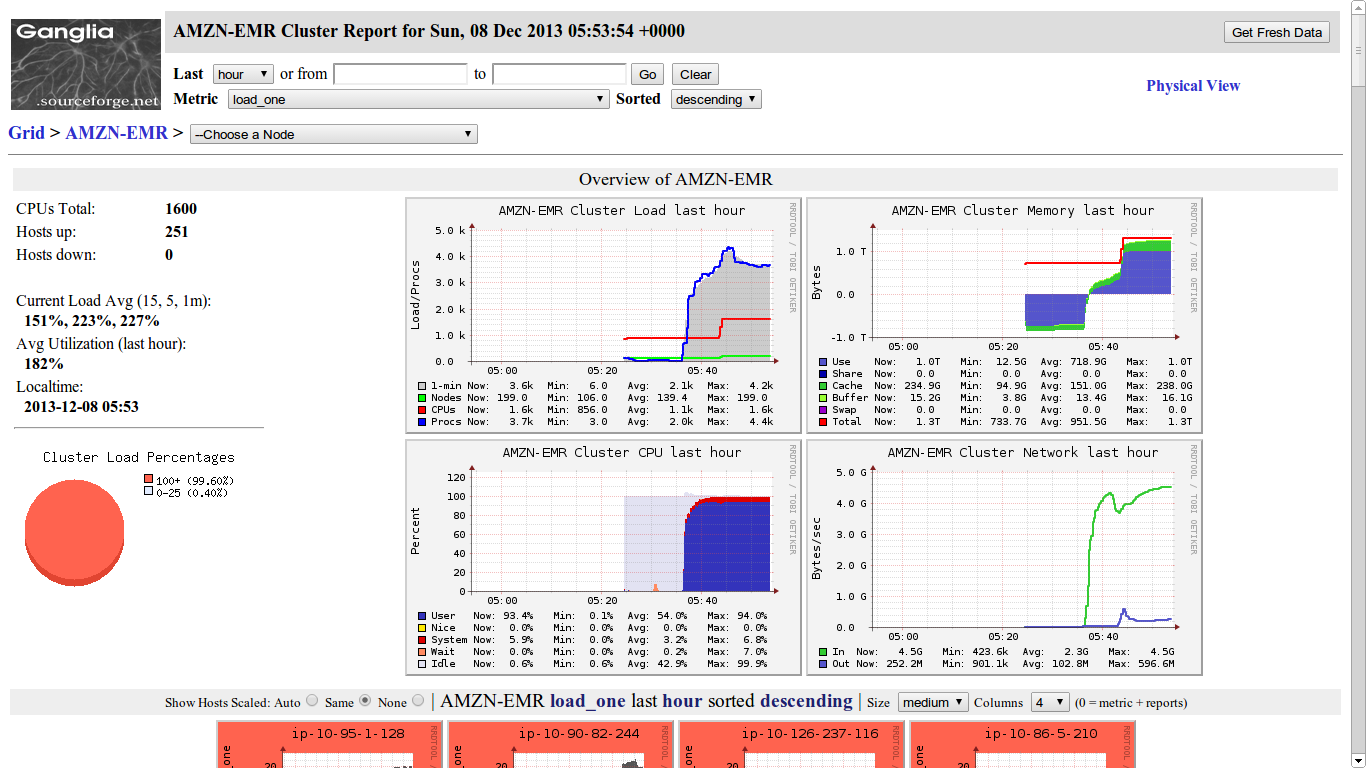
Ganglia
EMR in Education
Universities should teach big data courses with ...
big data
English Wikipedia
= 9.85 GB compressed
= 44 GB uncompressed
If "big data" isn't bigger than your phone's storage ...
Python + mrjob
https://github.com/commoncrawl/cc-mrjob
☑ Test and develop locally with minimal setup
(no Hadoop installation required)
☑ Only uses Python, not mixing other languages
(benefits of Hadoop ecosystem without touching it)
☑ Spin up a cluster in one click
(EMR integration = single click cluster)
Summary
- Random access archives using S3
Allows effective storage of enormous datasets
- Surviving & thriving w/ spot instances
S3 defends us against transient failures
- EMR - the good, the bad, the ugly
Simplifies and lowers barriers to entry
Allows effective storage of enormous datasets
S3 defends us against transient failures
Simplifies and lowers barriers to entry
Interested in helping out on something amazing?
Send me a message and/or visit
commoncrawl.org
Stephen Merity
Stephen Merity
Attributions
AWS at
Common Crawl
Stephen Merity
AWS at Common Crawl
By smerity




