
The whole web as your dataset
July 20, 2015
It's a non-profit that makes
web data
freely accessible to anyone
Each crawl archive is billions of pages:
May crawl archive is
2.05 billion web pages
~159 terabytes uncompressed
Released
totally free
without additional
intellectual property restrictions
(lives on Amazon Public Data Sets)
Origins of Common Crawl
Common Crawl founded in 2007
by Gil Elbaz (Applied Semantics / Factual)
Google and Microsoft were the powerhouses
Data powers the algorithms in our field
Goal: Democratize and simplify access to
"the web as a dataset"
Benefits for start-ups & research
Performing your own large-scale crawling is
expensive and challenging
Innovation occurs by using the data,
rarely through novel collection methods
+ We provide raw data, metadata & extracted text
+ Lower the barrier of entry for new start-ups
+ Create a communal pool of knowledge & data
Web Data at Scale
Analytics
+ Usage of servers, libraries, and metadata
Machine Learning
+ Unannotated and semi-supervised methods
Filtering and Aggregation
+ Analyzing tables, phone numbers
Analytics at Scale
Imagine you are interested in ...
+ Javascript library usage
+ HTML / HTML5 usage
+ Web server types and age
With Common Crawl you can analyse
billions of pages in an afternoon!
Analyzing Web Domain Vulns

WDC Hyperlink Graph
Largest freely available real world graph dataset:
3.5 billion pages, 128 billion links
Fast and easy analysis using Dato GraphLab on a single EC2 r3.8xlarge instance
(under 10 minutes per PageRank iteration)
Web Data at Scale
Analytics
+ Usage of servers, libraries, and metadata
Machine Learning
+ Unannotated and semi-supervised methods
Filtering and Aggregation
+ Analyzing tables, phone numbers
N-gram Counts & Language Models from the Common Crawl
Christian Buck, Kenneth Heafield, Bas van Ooyen
Processed all the text of Common Crawl to produce 975 billion deduplicated tokens
(similar size to the Google N-gram Dataset)
Project data was released at
http://statmt.org/ngrams
-
Deduped text split by language
-
Resulting language models
GloVe: Global Vectors for Word Representation
Jeffrey Pennington, Richard Socher, Christopher D. Manning
Capture "meaning" of words in vector of floats
king - man + woman = queen
GloVe and word2vec (Google's word vector method) can scale to hundreds of billions of tokens
More data => better performance
king - man + woman = queen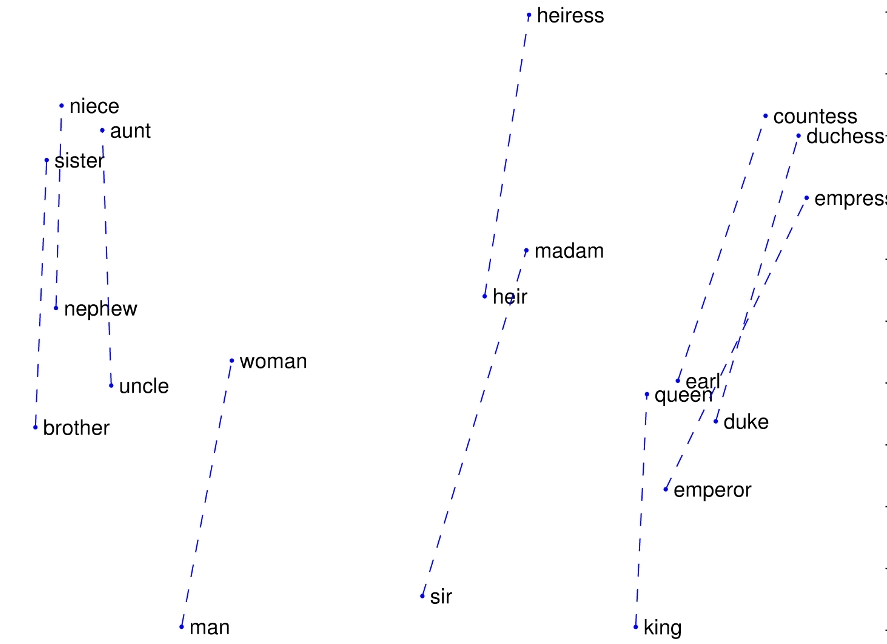
GloVe On Various Corpora
-
Semantic: "Athens is to Greece as Berlin is to _?"
-
Syntactic: "Dance is to dancing as fly is to _?"

GloVe over Big Data
Google released a trained word2vec using 100 billion tokens from Google News
Not replicable
Stanford released a trained GloVe model using 42 billion & 840 billion tokens from Common Crawl
Replicable
Source code and pre-trained models at
http://www-nlp.stanford.edu/projects/glove/
Web-Scale Parallel Text
Dirt Cheap Web-Scale Parallel Text from the Common Crawl (Smith et al.)
Processed all text from URLs of the style:
website.com/[langcode]/
[w.com/en/tesla | w.com/fr/tesla]
"...nothing more than a set of common two-letter language codes ... [we] mined 32 terabytes ... in just under a day"
Web-Scale Parallel Text
Manual inspection across three languages:
80% of the data contained good translations

(source = foreign language, target = English)
Web Data at Scale
Analytics
+ Usage of servers, libraries, and metadata
Machine Learning
+ Unannotated and semi-supervised methods
Filtering and Aggregation
+ Analyzing tables, phone numbers
Web Data Commons Web Tables
11.2 billion tables => 147 million relational web tables
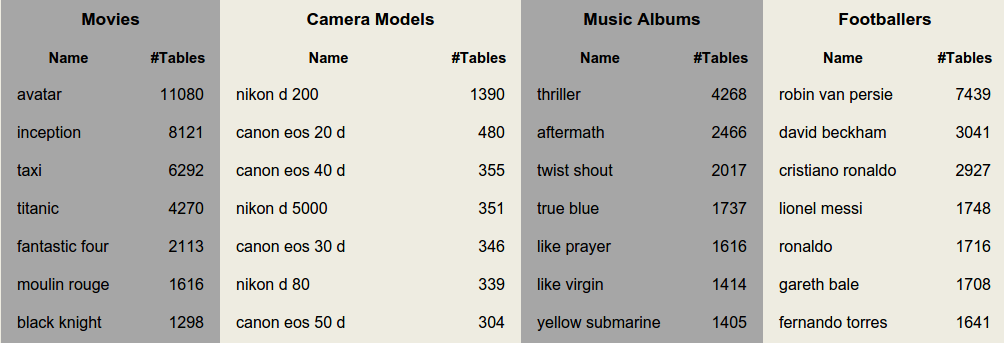
Popular column headers: name, title, artist, location, model, manufacturer, country ...
Released at webdatacommons.org/webtables/
Extracting US Phone Numbers
Task: Match businesses from Yelp's database to their homepages on the Internet using phone numbers.
Yelp extracted ~748 million US phone numbers from the Common Crawl December 2014 dataset
Regular expression over extracted text (WET files)
Extracting US Phone Numbers
Total complexity: 134 lines of Python
Total time: 1 hour (20 × c3.8xlarge)
Total cost: $10.60 USD (Python using EMR)
More details (and full code) on Yelp's blog post:
Analyzing the Web For the Price of a Sandwich
Why am I so excited..?
Open data is catching on!
Even playing field for academia and start-ups
-
Google Web 1T => Buck et al.'s N-grams
-
Google's Word2Vec => Stanford's GloVe
-
Google's Wikilinks => WikiReverse
-
Google's Sets => WDC Web Tables
Common Crawl releases their dataset
and brilliant people build on top of it
Read more at
commoncrawl.org
The whole web as your dataset
By smerity



