Dynamic memory networks for visual and textual question answering
Stephen Merity (@smerity)

Joint work with the MetaMind team:
Caiming Xiong, Richard Socher, and more
Classification

With good data, deep learning can give high accuracy in image and text classification
MetaMind even make it trivially easy to train your own classifier with zero ML knowledge
It's so easy that ...

6th and 7th grade high school students created a custom vision classifier for TrashCam
[Trash, Recycle, Compost] with 90% accuracy
Intracranial Hemorrhage

Work by MM colleagues: Caiming Xiong, Kai Sheng Tai, Ivo Mihov, ...
Beyond classification ...

VQA dataset: http://visualqa.org/
Beyond classification ...

* TIL Lassi = popular, traditional, yogurt based drink from the Indian Subcontinent
Question Answering

Visual Genome: http://visualgenome.org/
Question Answering

Visual Genome: http://visualgenome.org/
Question Answering
1 Mary moved to the bathroom. 2 John went to the hallway. 3 Where is Mary? bathroom 1 4 Daniel went back to the hallway. 5 Sandra moved to the garden. 6 Where is Daniel? hallway 4 7 John moved to the office. 8 Sandra journeyed to the bathroom. 9 Where is Daniel? hallway 4 10 Mary moved to the hallway. 11 Daniel travelled to the office. 12 Where is Daniel? office 11 13 John went back to the garden. 14 John moved to the bedroom. 15 Where is Sandra? bathroom 8 1 Sandra travelled to the office. 2 Sandra went to the bathroom. 3 Where is Sandra? bathroom 2
Extract from the Facebook bAbI Dataset
Human Question Answering
Imagine I gave you an article or an image, asked you to memorize it, took it away, then asked you various questions.
Even as intelligent as you are,
you're going to get a failing grade :(
Why?
- You can't store everything in working memory
- Without a question to direct your attention,
you waste focus on unimportant details
Optimal: give you the input data, give you the question, allow as many glances as possible
Think in terms of
Information Bottlenecks
Where is your model forced to use a compressed representation?
Most importantly,
is that a good thing?
Gated Recurrent Unit (GRU)
Cho et al. 2014
- A type of recurrent neural network (RNN), similar to the LSTM
- Consumes and/or generates sequences (chars, words, ...)
- The GRU updates an internal state h according to the:
- existing state h and the current input x
h_t = GRU(x_t, h_{t-1})
Figure from Chris Olah's Visualizing Representations
Gated Recurrent Unit (GRU)
u_i = \sigma\left(W^{(u)}x_{i} + U^{(u)} h_{i-1} + b^{(u)} \right)
r_i = \sigma\left(W^{(r)}x_{i} + U^{(r)} h_{i-1} + b^{(r)} \right)
\tilde{h}_i = \tanh\left(W^{(h)}x_{i} + r_i \circ U^{(h)} h_{i-1} + b^{(h)}\right)
h_i = u_i\circ \tilde{h}_i + (1-u_i) \circ h_{i-1}
Cho et al. 2014

Neural Machine Translation
Figure from Chris Olah's Visualizing Representations
Figure from Bahdanau et al's
Neural Machine Translation by Jointly Learning to Align and Translate

Neural Machine Translation


Results from Bahdanau et al's
Neural Machine Translation by Jointly Learning to Align and Translate
Related Attention/Memory Work
- Sequence to Sequence (Sutskever et al. 2014)
- Neural Turing Machines (Graves et al. 2014)
- Teaching Machines to Read and Comprehend
(Hermann et al. 2015) - Learning to Transduce with Unbounded Memory (Grefenstette 2015)
- Structured Memory for Neural Turing Machines
(Wei Zhang 2015)
- Memory Networks (Weston et al. 2015)
- End to end memory networks (Sukhbaatar et al. 2015)
QA for Dynamic Memory Networks
- A modular and flexible DL framework for QA
- Capable of tackling wide range of tasks and input formats
- Can even been used for general NLP tasks (i.e. non QA)
(PoS, NER, sentiment, translation, ...)
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing (Kumar et al., 2015)
Dynamic Memory Networks for Visual and Textual Question Answering (Xiong et al., 2016)
For full details:
QA for Dynamic Memory Networks
- A modular and flexible DL framework for QA
- Capable of tackling wide range of tasks and input formats
- Can even been used for general NLP tasks (i.e. non QA)
(PoS, NER, sentiment, translation, ...)

Input Modules

+ The module produces an ordered list of facts from the input
+ We can increase the number or dimensionality of these facts
+ Input fusion layer (bidirectional GRU) injects positional information and allows interactions between facts
Episodic Memory Module
Composed of three parts with potentially multiple passes:
- Computing attention gates
- Attention mechanism
- Memory update

Computing Attention Gates
Each fact receives an attention gate value from [0, 1]
The value is produced by analyzing [fact, query, episode memory]
Optionally enforce sparsity by using softmax over attention values

Soft Attention Mechanism
c = \sum^N_{i=1} g_i f_i
If the gate values were passed through softmax,
the context vector is a weighted summation of the input facts
Given the attention gates, we now want to extract a context vector from the input facts
Issue: summation loses positional and ordering information
Attention GRU Mechanism
If we modify the GRU, we can inject information from the attention gates.
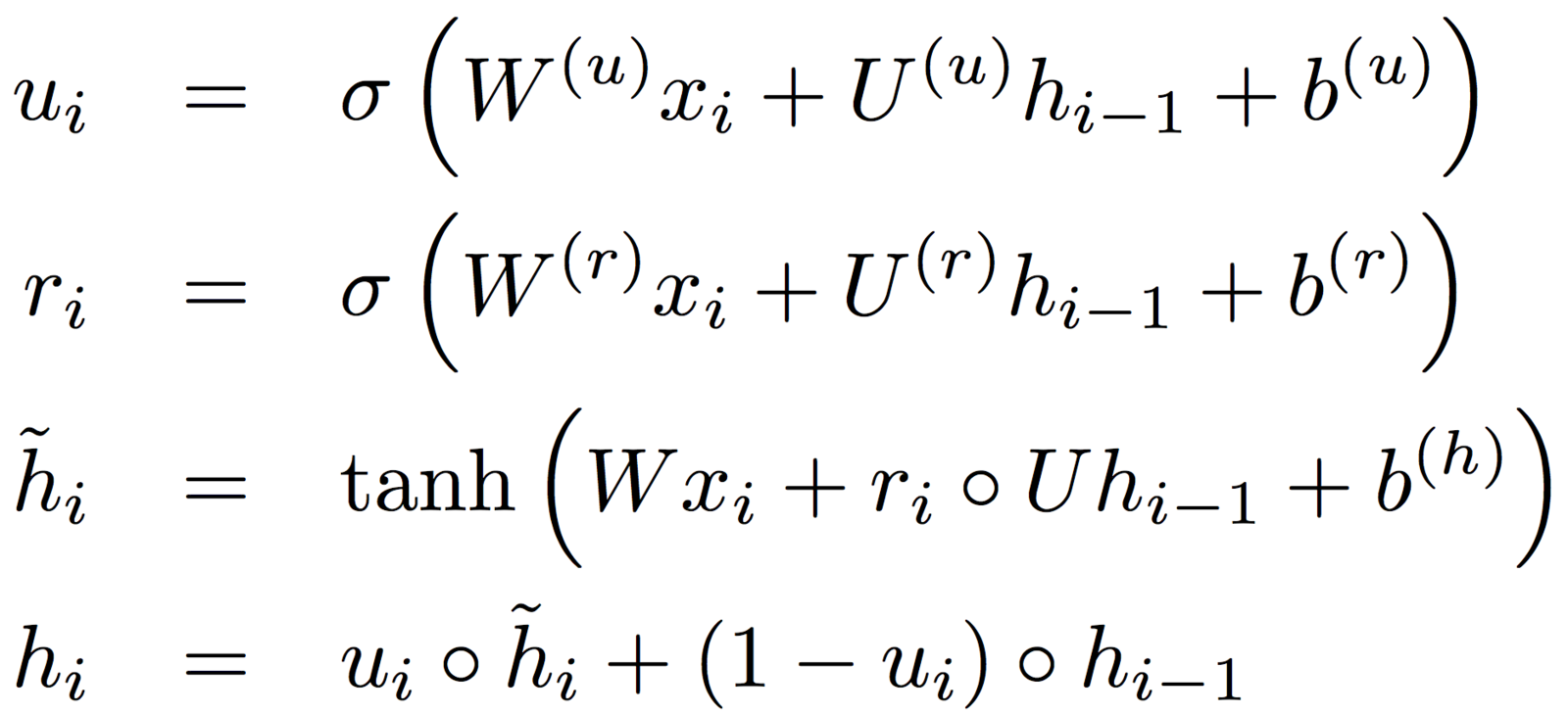
By replacing the update gate u with the activation gate g,
the update gate can make use of the question and memory

Attention GRU Mechanism
If we modify the GRU, we can inject information from the attention gates.
Results
Focus on three experiments:
Vision
Text
Attention visualization
DMN Overview

Accuracy: Text QA (bAbI 10k)

Accuracy: Visual Question Answering

Accuracy: Visual Question Answering

Accuracy: Visual Question Answering

Accuracy: Visual Question Answering

Summary
- Attention and memory can avoid the information bottleneck
- The DMN can provide a flexible framework for QA work
- Attention visualization can help in model interpretability
DMN for TQA and VQA - Strata + Hadoop World
By smerity



